 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
Efficient Clustering from Distributions over Topics
Dec 15, 2020
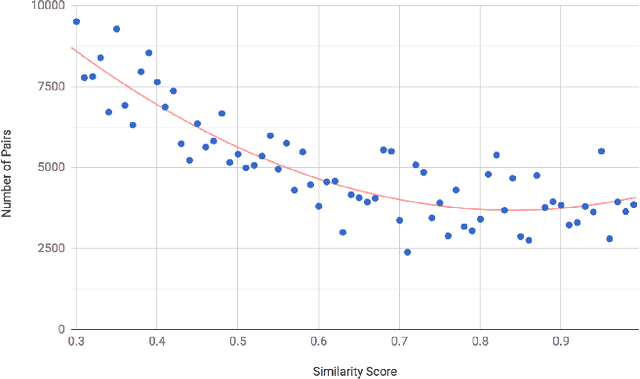
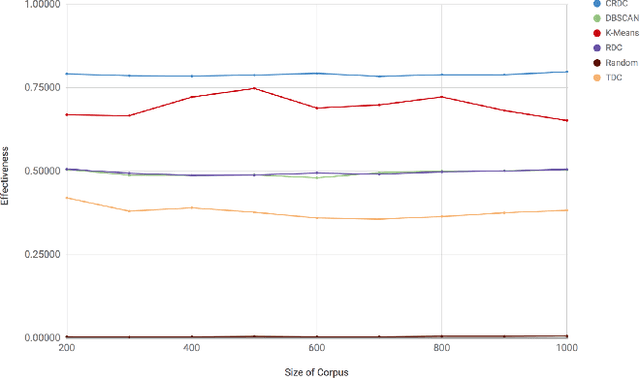
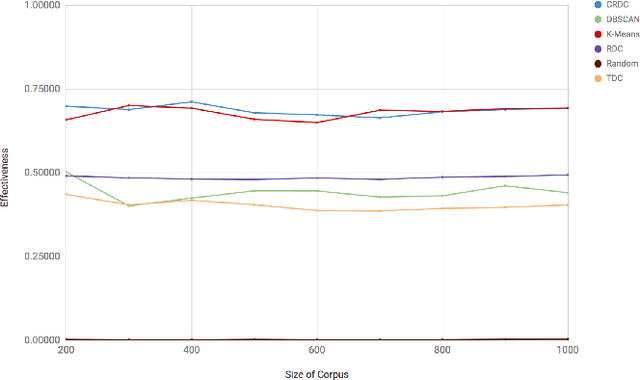
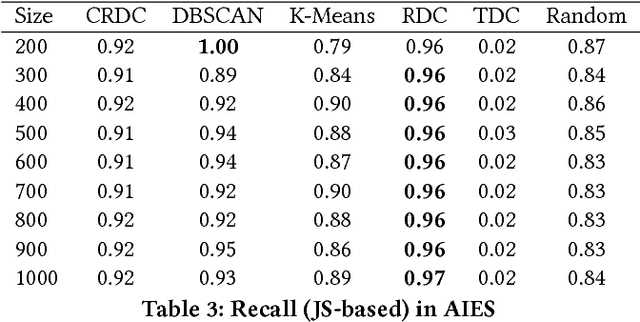
There are many scenarios where we may want to find pairs of textually similar documents in a large corpus (e.g. a researcher doing literature review, or an R&D project manager analyzing project proposals). To programmatically discover those connections can help experts to achieve those goals, but brute-force pairwise comparisons are not computationally adequate when the size of the document corpus is too large. Some algorithms in the literature divide the search space into regions containing potentially similar documents, which are later processed separately from the rest in order to reduce the number of pairs compared. However, this kind of unsupervised methods still incur in high temporal costs. In this paper, we present an approach that relies on the results of a topic modeling algorithm over the documents in a collection, as a means to identify smaller subsets of documents where the similarity function can then be computed. This approach has proved to obtain promising results when identifying similar documents in the domain of scientific publications. We have compared our approach against state of the art clustering techniques and with different configurations for the topic modeling algorithm. Results suggest that our approach outperforms (> 0.5) the other analyzed techniques in terms of efficiency.
* Accepted at the 9th International Conference on Knowledge Capture (K-CAP 2017)
Topic subject creation using unsupervised learning for topic modeling
Dec 18, 2019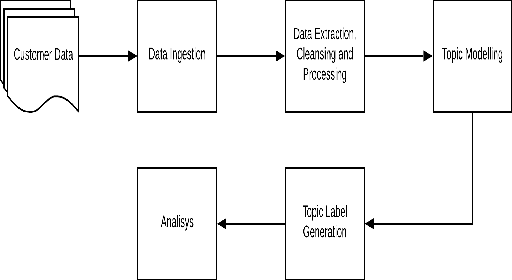
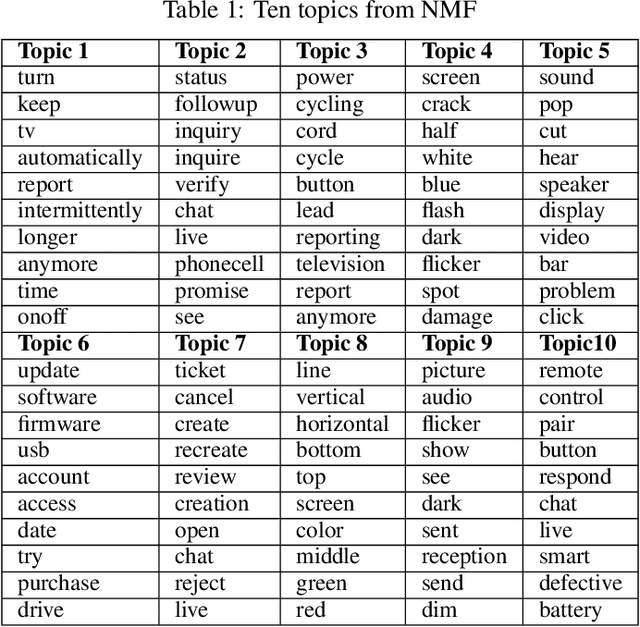
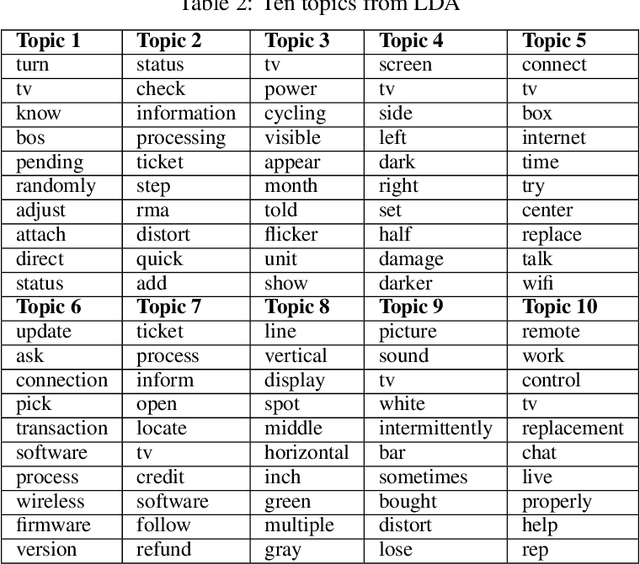
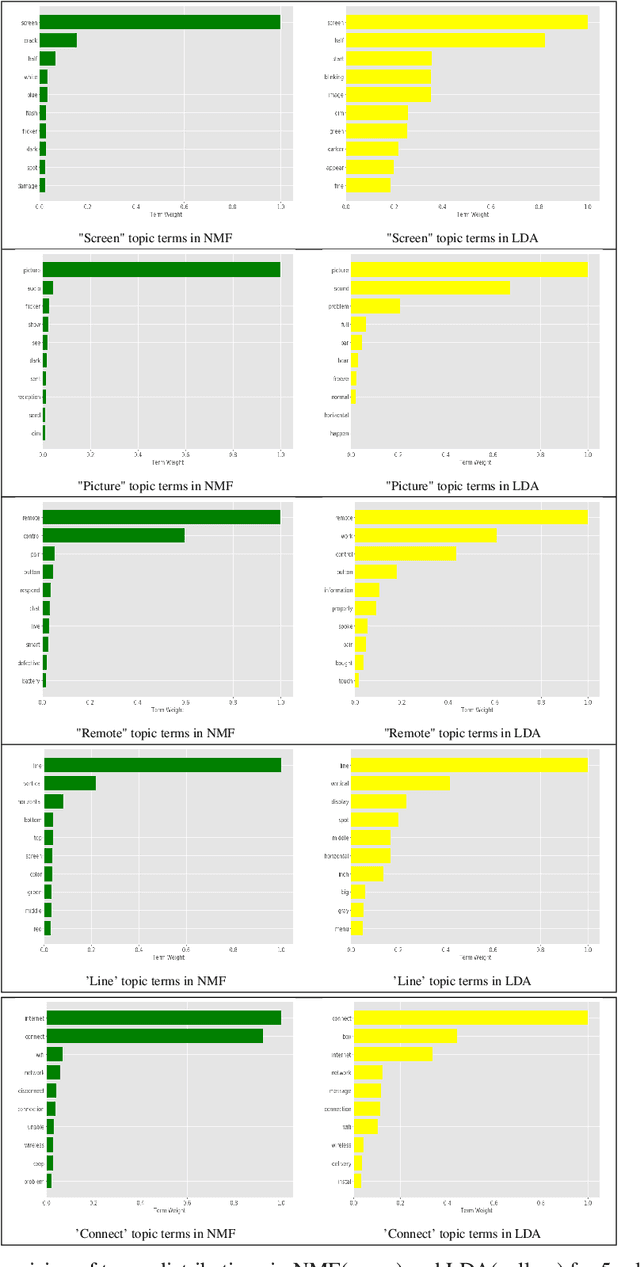
We describe the use of Non-Negative Matrix Factorization (NMF) and Latent Dirichlet Allocation (LDA) algorithms to perform topic mining and labelling applied to retail customer communications in attempt to characterize the subject of customers inquiries. In this paper we compare both algorithms in the topic mining performance and propose methods to assign topic subject labels in an automated way.
Nonparametric Topic Modeling with Neural Inference
Jun 18, 2018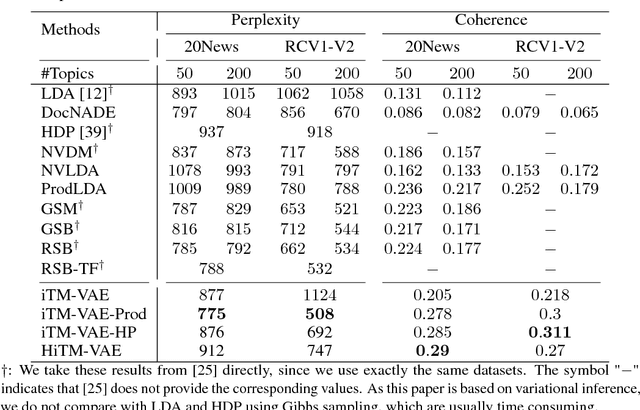

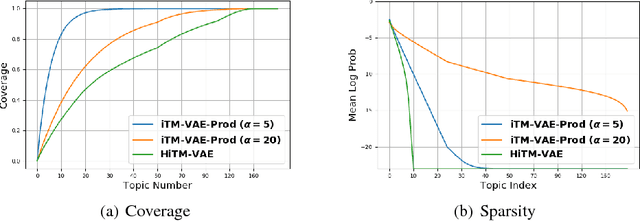
This work focuses on combining nonparametric topic models with Auto-Encoding Variational Bayes (AEVB). Specifically, we first propose iTM-VAE, where the topics are treated as trainable parameters and the document-specific topic proportions are obtained by a stick-breaking construction. The inference of iTM-VAE is modeled by neural networks such that it can be computed in a simple feed-forward manner. We also describe how to introduce a hyper-prior into iTM-VAE so as to model the uncertainty of the prior parameter. Actually, the hyper-prior technique is quite general and we show that it can be applied to other AEVB based models to alleviate the {\it collapse-to-prior} problem elegantly. Moreover, we also propose HiTM-VAE, where the document-specific topic distributions are generated in a hierarchical manner. HiTM-VAE is even more flexible and can generate topic distributions with better variability. Experimental results on 20News and Reuters RCV1-V2 datasets show that the proposed models outperform the state-of-the-art baselines significantly. The advantages of the hyper-prior technique and the hierarchical model construction are also confirmed by experiments.
Towards Rich, Portable, and Large-Scale Pedestrian Data Collection
Mar 03, 2022


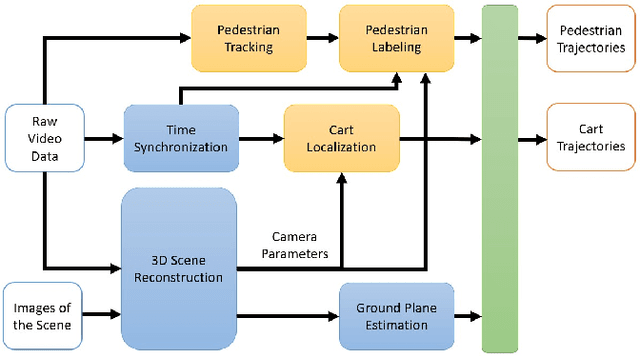
Recently, pedestrian behavior research has shifted towards machine learning based methods and converged on the topic of modeling pedestrian interactions. For this, a large-scale dataset that contains rich information is needed. We propose a data collection system that is portable, which facilitates accessible large-scale data collection in diverse environments. We also couple the system with a semi-autonomous labeling pipeline for fast trajectory label production. We demonstrate the effectiveness of our system by further introducing a dataset we have collected -- the TBD pedestrian dataset. Compared with existing pedestrian datasets, our dataset contains three components: human verified labels grounded in the metric space, a combination of top-down and perspective views, and naturalistic human behavior in the presence of a socially appropriate "robot". In addition, the TBD pedestrian dataset is larger in quantity compared to similar existing datasets and contains unique pedestrian behavior.
Large Scale Analysis of Open MOOC Reviews to Support Learners' Course Selection
Jan 11, 2022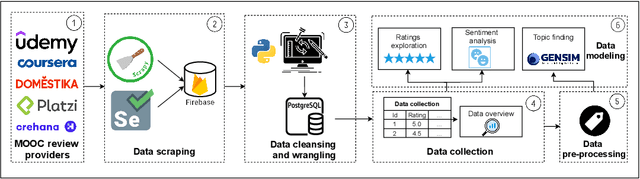
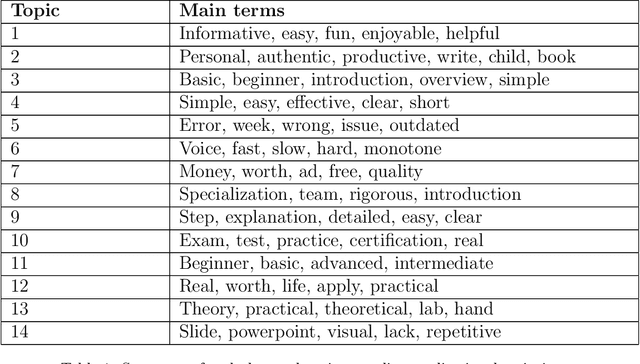
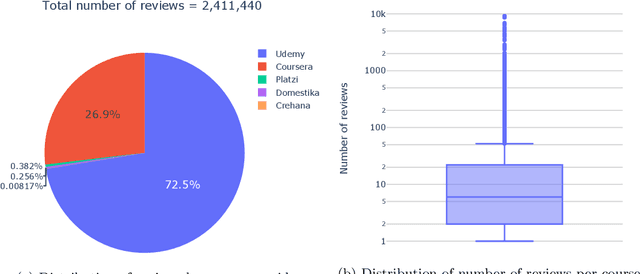
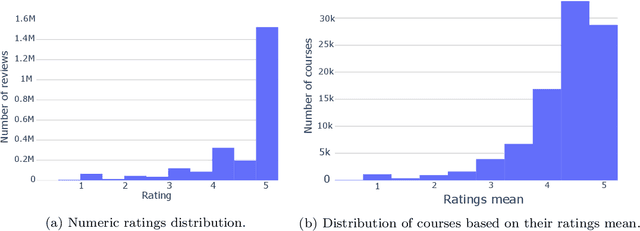
The recent pandemic has changed the way we see education. It is not surprising that children and college students are not the only ones using online education. Millions of adults have signed up for online classes and courses during last years, and MOOC providers, such as Coursera or edX, are reporting millions of new users signing up in their platforms. However, students do face some challenges when choosing courses. Though online review systems are standard among many verticals, no standardized or fully decentralized review systems exist in the MOOC ecosystem. In this vein, we believe that there is an opportunity to leverage available open MOOC reviews in order to build simpler and more transparent reviewing systems, allowing users to really identify the best courses out there. Specifically, in our research we analyze 2.4 million reviews (which is the largest MOOC reviews dataset used until now) from five different platforms in order to determine the following: (1) if the numeric ratings provide discriminant information to learners, (2) if NLP-driven sentiment analysis on textual reviews could provide valuable information to learners, (3) if we can leverage NLP-driven topic finding techniques to infer themes that could be important for learners, and (4) if we can use these models to effectively characterize MOOCs based on the open reviews. Results show that numeric ratings are clearly biased (63\% of them are 5-star ratings), and the topic modeling reveals some interesting topics related with course advertisements, the real applicability, or the difficulty of the different courses. We expect our study to shed some light on the area and promote a more transparent approach in online education reviews, which are becoming more and more popular as we enter the post-pandemic era.
Hotel Preference Rank based on Online Customer Review
Oct 10, 2021
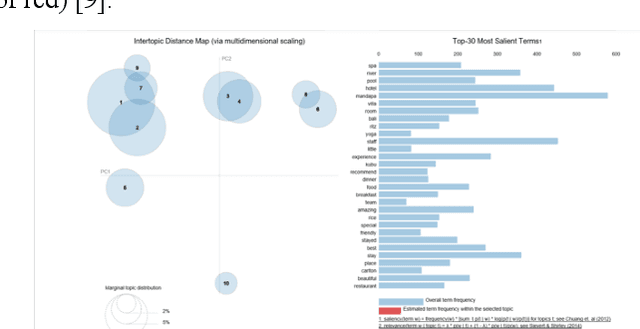
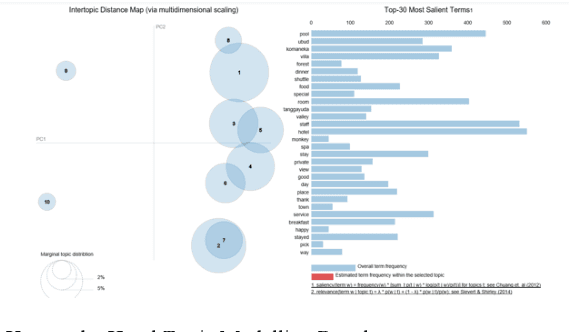
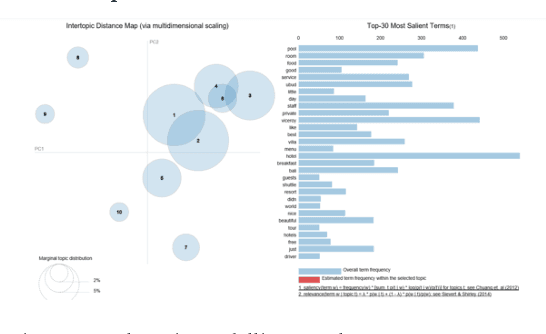
Topline hotels are now shifting into the digital way in how they understand their customers to maintain and ensuring satisfaction. Rather than the conventional way which uses written reviews or interviews, the hotel is now heavily investing in Artificial Intelligence particularly Machine Learning solutions. Analysis of online customer reviews changes the way companies make decisions in a more effective way than using conventional analysis. The purpose of this research is to measure hotel service quality. The proposed approach emphasizes service quality dimensions reviews of the top-5 luxury hotel in Indonesia that appear on the online travel site TripAdvisor based on section Best of 2018. In this research, we use a model based on a simple Bayesian classifier to classify each customer review into one of the service quality dimensions. Our model was able to separate each classification properly by accuracy, kappa, recall, precision, and F-measure measurements. To uncover latent topics in the customer's opinion we use Topic Modeling. We found that the common issue that occurs is about responsiveness as it got the lowest percentage compared to others. Our research provides a faster outlook of hotel rank based on service quality to end customers based on a summary of the previous online review.
* 5 pages, 6 figures, 5 tables
Evaluating Sensitivity to the Stick-Breaking Prior in Bayesian Nonparametrics
Jul 12, 2021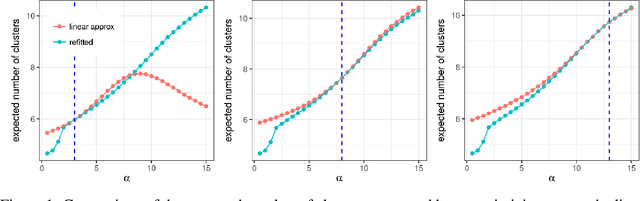
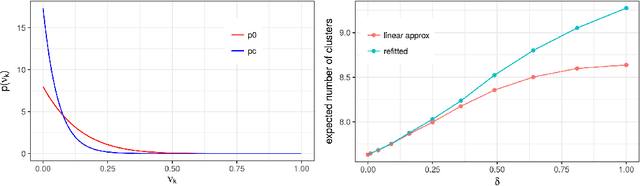
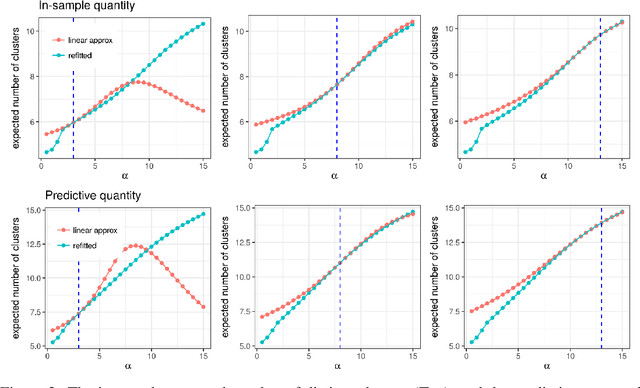
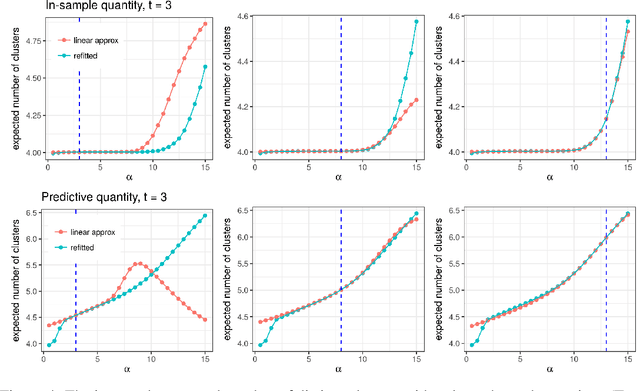
Bayesian models based on the Dirichlet process and other stick-breaking priors have been proposed as core ingredients for clustering, topic modeling, and other unsupervised learning tasks. Prior specification is, however, relatively difficult for such models, given that their flexibility implies that the consequences of prior choices are often relatively opaque. Moreover, these choices can have a substantial effect on posterior inferences. Thus, considerations of robustness need to go hand in hand with nonparametric modeling. In the current paper, we tackle this challenge by exploiting the fact that variational Bayesian methods, in addition to having computational advantages in fitting complex nonparametric models, also yield sensitivities with respect to parametric and nonparametric aspects of Bayesian models. In particular, we demonstrate how to assess the sensitivity of conclusions to the choice of concentration parameter and stick-breaking distribution for inferences under Dirichlet process mixtures and related mixture models. We provide both theoretical and empirical support for our variational approach to Bayesian sensitivity analysis.
A Comprehensive Attempt to Research Statement Generation
Apr 25, 2021
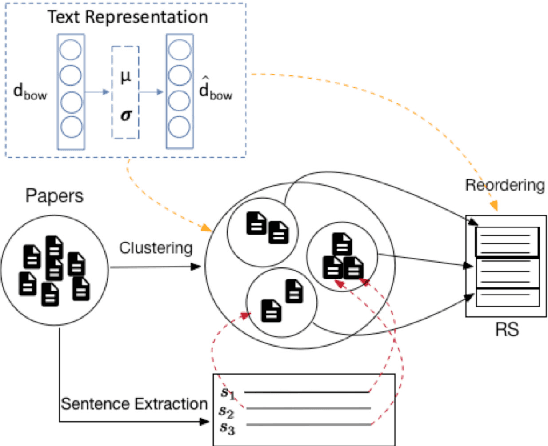
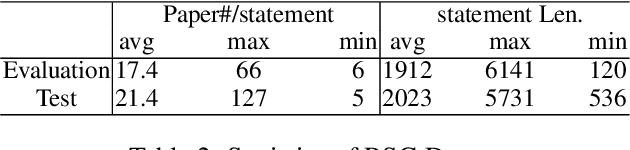
For a researcher, writing a good research statement is crucial but costs a lot of time and effort. To help researchers, in this paper, we propose the research statement generation (RSG) task which aims to summarize one's research achievements and help prepare a formal research statement. For this task, we conduct a comprehensive attempt including corpus construction, method design, and performance evaluation. First, we construct an RSG dataset with 62 research statements and the corresponding 1,203 publications. Due to the limitation of our resources, we propose a practical RSG method which identifies a researcher's research directions by topic modeling and clustering techniques and extracts salient sentences by a neural text summarizer. Finally, experiments show that our method outperforms all the baselines with better content coverage and coherence.
Personalized, Health-Aware Recipe Recommendation: An Ensemble Topic Modeling Based Approach
Jul 31, 2019
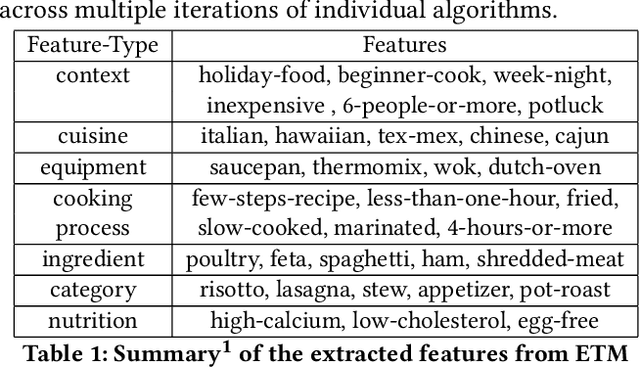
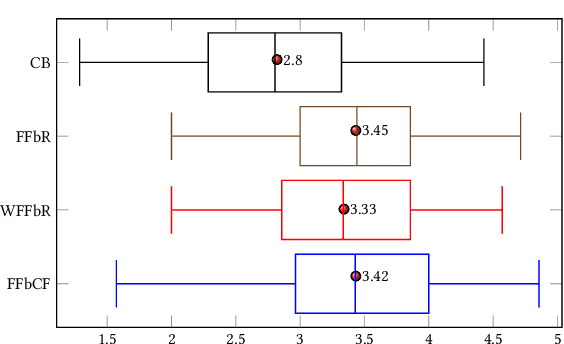
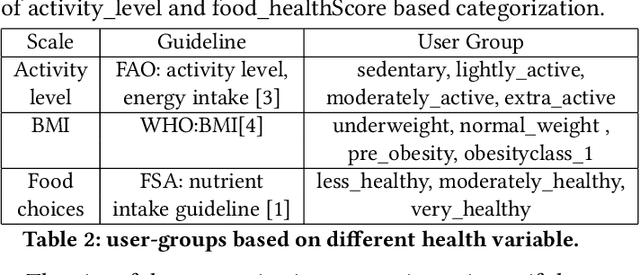
Food choices are personal and complex and have a significant impact on our long-term health and quality of life. By helping users to make informed and satisfying decisions, Recommender Systems (RS) have the potential to support users in making healthier food choices. Intelligent users-modeling is a key challenge in achieving this potential. This paper investigates Ensemble Topic Modelling (EnsTM) based Feature Identification techniques for efficient user-modeling and recipe recommendation. It builds on findings in EnsTM to propose a reduced data representation format and a smart user-modeling strategy that makes capturing user-preference fast, efficient and interactive. This approach enables personalization, even in a cold-start scenario. This paper proposes two different EnsTM based and one Hybrid EnsTM based recommenders. We compared all three EnsTM based variations through a user study with 48 participants, using a large-scale,real-world corpus of 230,876 recipes, and compare against a conventional Content Based (CB) approach. EnsTM based recommenders performed significantly better than the CB approach. Besides acknowledging multi-domain contents such as taste, demographics and cost, our proposed approach also considers user's nutritional preference and assists them finding recipes under diverse nutritional categories. Furthermore, it provides excellent coverage and enables implicit understanding of user's food practices. Subsequent analysis also exposed correlation between certain features and a healthier lifestyle.