 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
Topic-Aware Multi-turn Dialogue Modeling
Sep 26, 2020

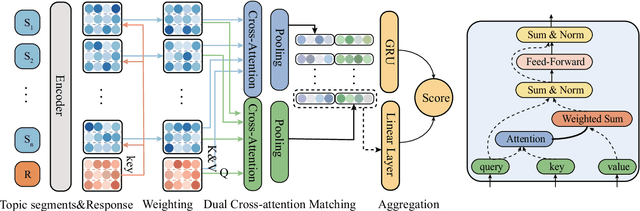
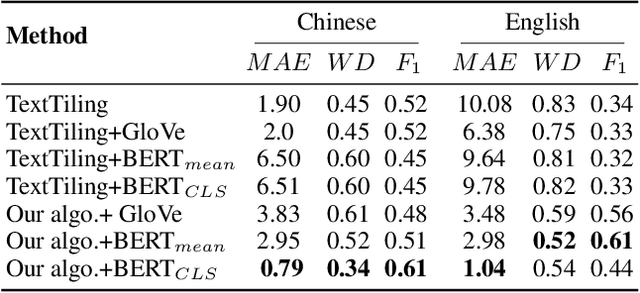
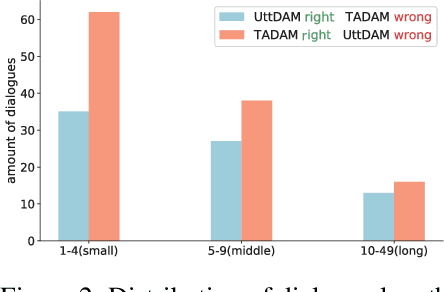
In the retrieval-based multi-turn dialogue modeling, it remains a challenge to select the most appropriate response according to extracting salient features in context utterances. As a conversation goes on, topic shift at discourse-level naturally happens through the continuous multi-turn dialogue context. However, all known retrieval-based systems are satisfied with exploiting local topic words for context utterance representation but fail to capture such essential global topic-aware clues at discourse-level. Instead of taking topic-agnostic n-gram utterance as processing unit for matching purpose in existing systems, this paper presents a novel topic-aware solution for multi-turn dialogue modeling, which segments and extracts topic-aware utterances in an unsupervised way, so that the resulted model is capable of capturing salient topic shift at discourse-level in need and thus effectively track topic flow during multi-turn conversation. Our topic-aware modeling is implemented by a newly proposed unsupervised topic-aware segmentation algorithm and Topic-Aware Dual-attention Matching (TADAM) Network, which matches each topic segment with the response in a dual cross-attention way. Experimental results on three public datasets show TADAM can outperform the state-of-the-art method by a large margin, especially by 3.4% on E-commerce dataset that has an obvious topic shift.
Learning Topic Models: Identifiability and Finite-Sample Analysis
Oct 08, 2021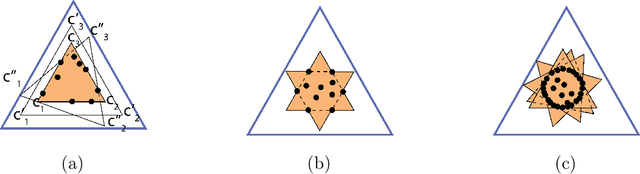

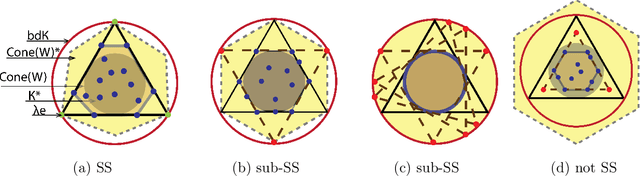
Topic models provide a useful text-mining tool for learning, extracting and discovering latent structures in large text corpora. Although a plethora of methods have been proposed for topic modeling, a formal theoretical investigation on the statistical identifiability and accuracy of latent topic estimation is lacking in the literature. In this paper, we propose a maximum likelihood estimator (MLE) of latent topics based on a specific integrated likelihood, which is naturally connected to the concept of volume minimization in computational geometry. Theoretically, we introduce a new set of geometric conditions for topic model identifiability, which are weaker than conventional separability conditions relying on the existence of anchor words or pure topic documents. We conduct finite-sample error analysis for the proposed estimator and discuss the connection of our results with existing ones. We conclude with empirical studies on both simulated and real datasets.
Private Topic Modeling
Nov 28, 2016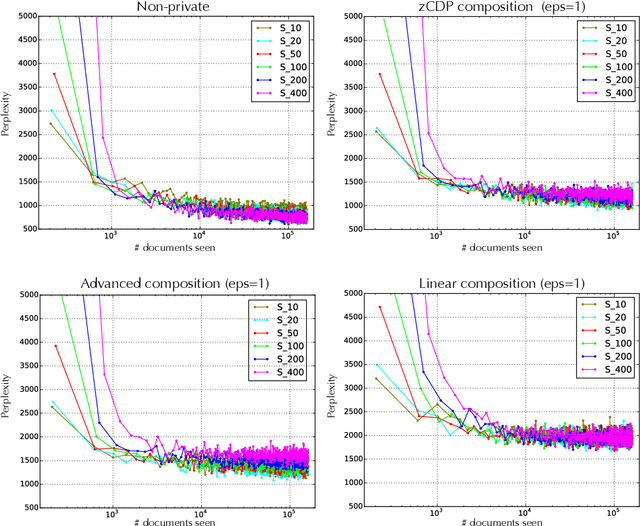
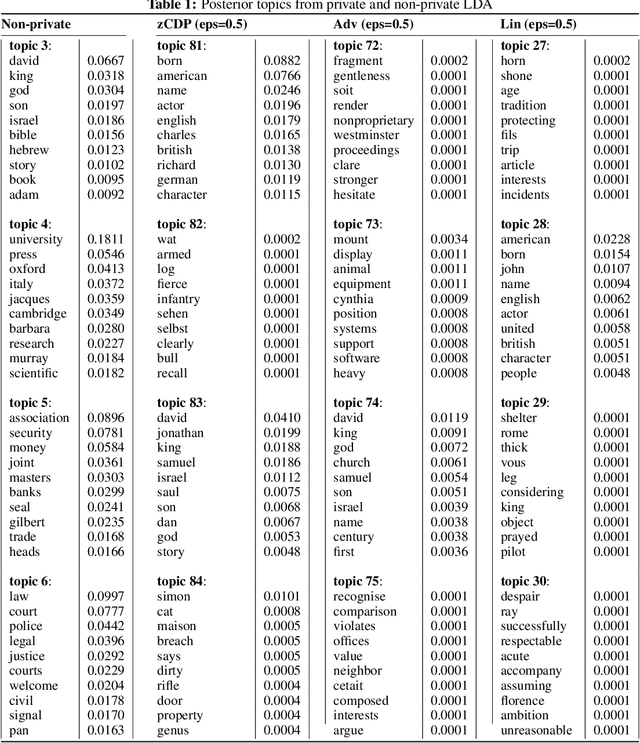
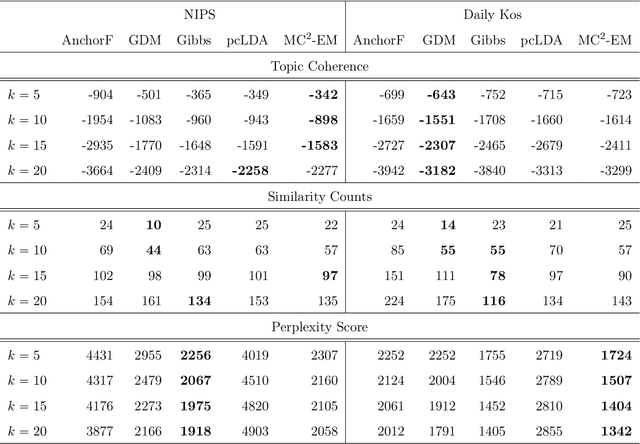
We develop a privatised stochastic variational inference method for Latent Dirichlet Allocation (LDA). The iterative nature of stochastic variational inference presents challenges: multiple iterations are required to obtain accurate posterior distributions, yet each iteration increases the amount of noise that must be added to achieve a reasonable degree of privacy. We propose a practical algorithm that overcomes this challenge by combining: (1) A relaxed notion of the differential privacy, called concentrated differential privacy, which provides high probability bounds for cumulative privacy loss, which is well suited for iterative algorithms, rather than focusing on single-query loss; and (2) Privacy amplification resulting from subsampling of large-scale data. Focusing on conjugate exponential family models, in our private variational inference, all the posterior distributions will be privatised by simply perturbing expected sufficient statistics. Using Wikipedia data, we illustrate the effectiveness of our algorithm for large-scale data.
Semi-supervised NMF Models for Topic Modeling in Learning Tasks
Oct 15, 2020
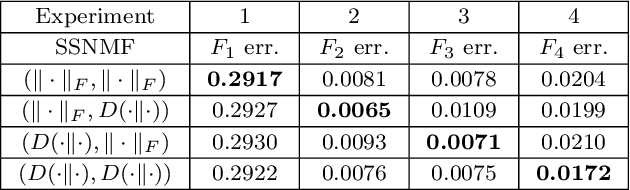


We propose several new models for semi-supervised nonnegative matrix factorization (SSNMF) and provide motivation for SSNMF models as maximum likelihood estimators given specific distributions of uncertainty. We present multiplicative updates training methods for each new model, and demonstrate the application of these models to classification, although they are flexible to other supervised learning tasks. We illustrate the promise of these models and training methods on both synthetic and real data, and achieve high classification accuracy on the 20 Newsgroups dataset.
Temporal Action Segmentation: An Analysis of Modern Technique
Oct 19, 2022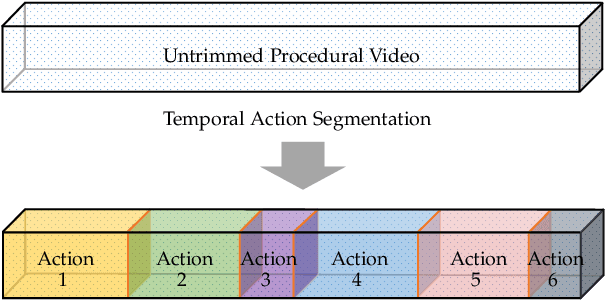
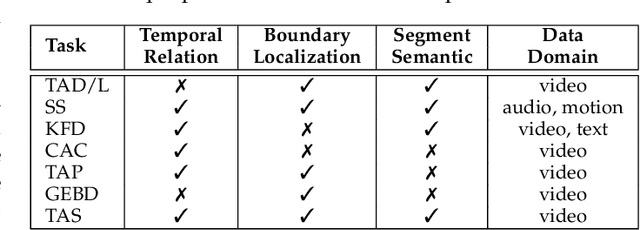

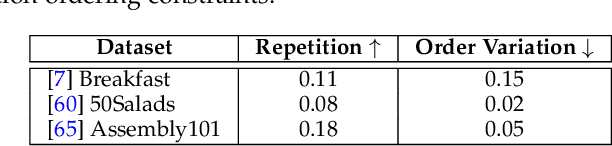
Temporal action segmentation from videos aims at the dense labeling of video frames with multiple action classes in minutes-long videos. Categorized as a long-range video understanding task, researchers have proposed an extended collection of methods and examined their performance using various benchmarks. Despite the rapid development of action segmentation techniques in recent years, there has been no systematic survey in such fields. To this end, in this survey, we analyze and summarize the main contributions and trends for this task. Specifically, we first examine the task definition, common benchmarks, types of supervision, and popular evaluation measures. Furthermore, we systematically investigate two fundamental aspects of this topic, i.e., frame representation and temporal modeling, which are widely and extensively studied in the literature. We then comprehensively review existing temporal action segmentation works, each categorized by their form of supervision. Finally, we conclude our survey by highlighting and identifying several open topics for research. In addition, we supplement our survey with a curated list of temporal action segmentation resources, which is available at https://github.com/atlas-eccv22/awesome-temporal-action-segmentation.
Extracting Major Topics of COVID-19 Related Tweets
Oct 05, 2021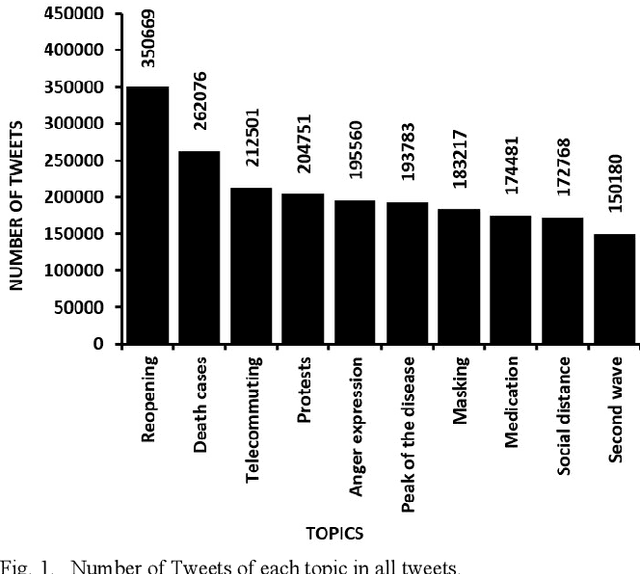
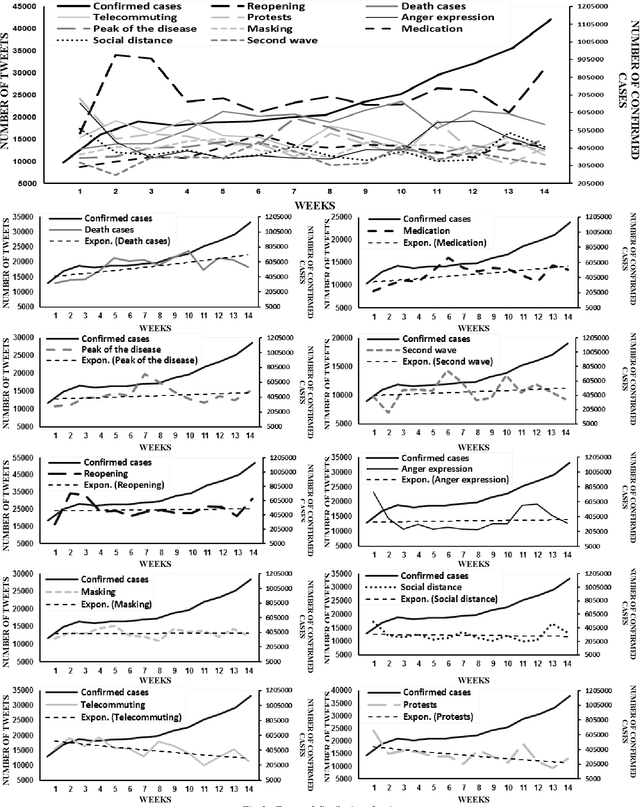
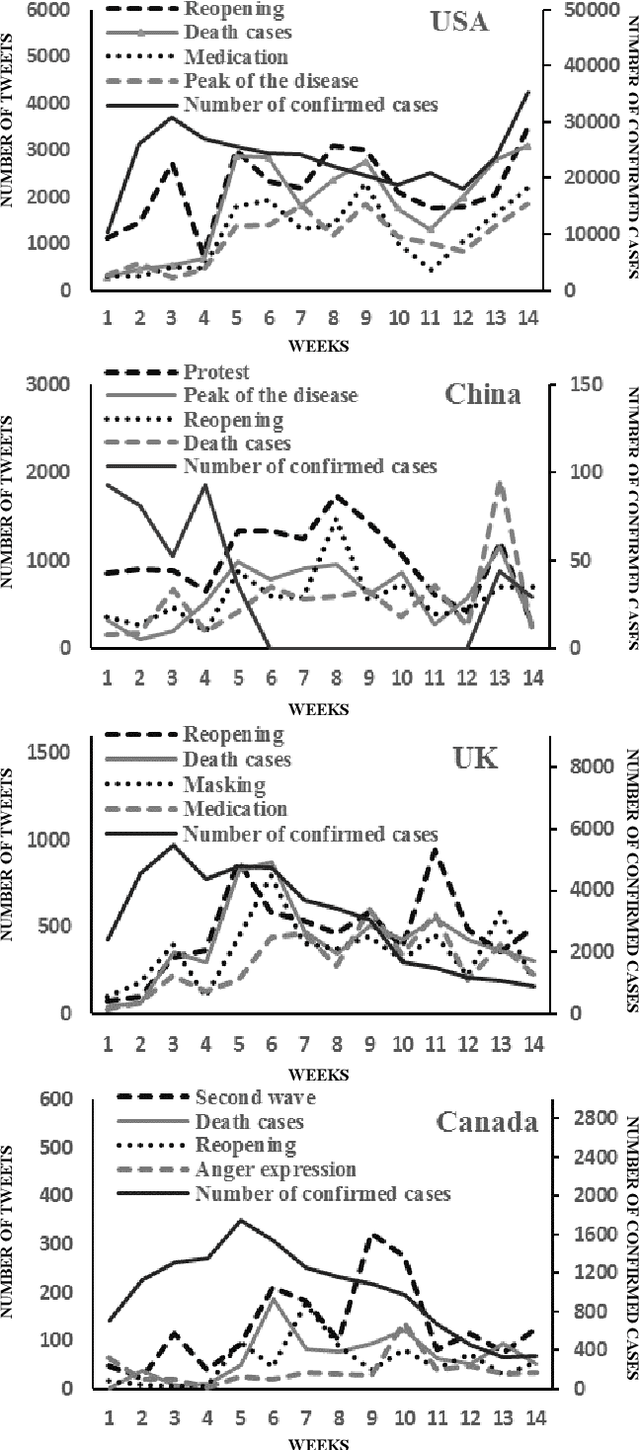
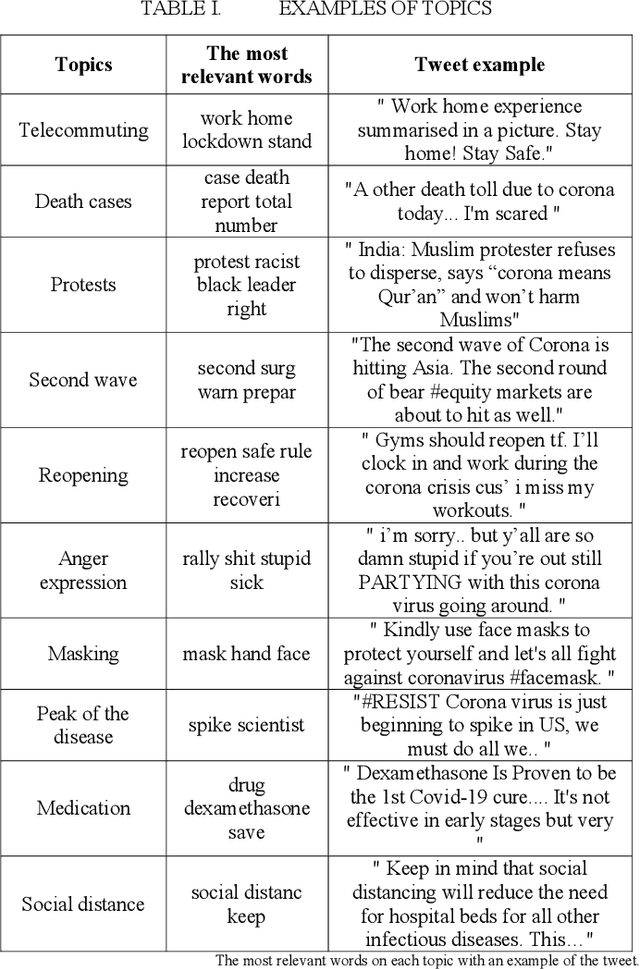
With the outbreak of the Covid-19 virus, the activity of users on Twitter has significantly increased. Some studies have investigated the hot topics of tweets in this period; however, little attention has been paid to presenting and analyzing the spatial and temporal trends of Covid-19 topics. In this study, we use the topic modeling method to extract global topics during the nationwide quarantine periods (March 23 to June 23, 2020) on Covid-19 tweets. We implement the Latent Dirichlet Allocation (LDA) algorithm to extract the topics and then name them with the "reopening", "death cases", "telecommuting", "protests", "anger expression", "masking", "medication", "social distance", "second wave", and "peak of the disease" titles. We additionally analyze temporal trends of the topics for the whole world and four countries. By analyzing the graphs, fascinating results are obtained from altering users' focus on topics over time.
A Paradigm Change for Formal Syntax: Computational Algorithms in the Grammar of English
May 24, 2022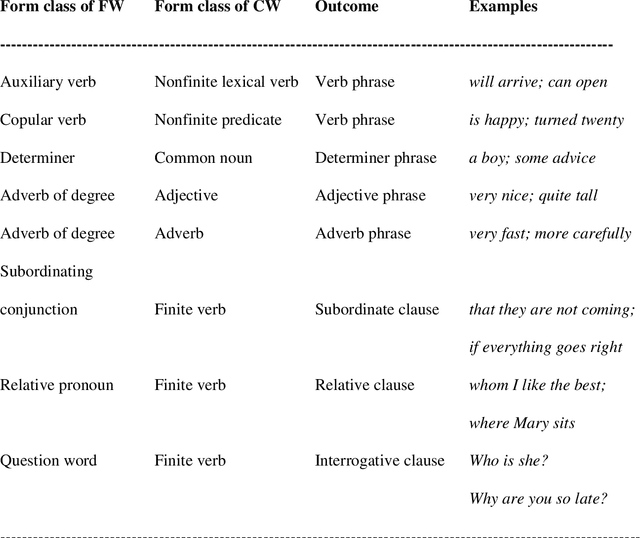
Language sciences rely less and less on formal syntax as their base. The reason is probably its lack of psychological reality, knowingly avoided. Philosophers of science call for a paradigm shift in which explanations are by mechanisms, as in biology. We turned to programming languages as heuristic models for a process-based syntax of English. The combination of a functional word and a content word was chosen as the topic of modeling. Such combinations are very frequent, and their output is the important immediate constituents of sentences. We found their parallel in Object Oriented Programming where an all-methods element serves as an interface, and the content-full element serves as its implementation, defining computational objects. The fit of the model was tested by deriving three functional characteristics crucial for the algorithm and checking their presence in English grammar. We tested the reality of the interface-implementation mechanism on psycholinguistic and neurolinguistic evidence concerning processing, development and loss of syntax. The close fit and psychological reality of the mechanism suggests that a paradigm shift to an algorithmic theory of syntax is a possibility.
Graph-based Trajectory Visualization for Text Mining of COVID-19 Biomedical Literature
Jun 07, 2021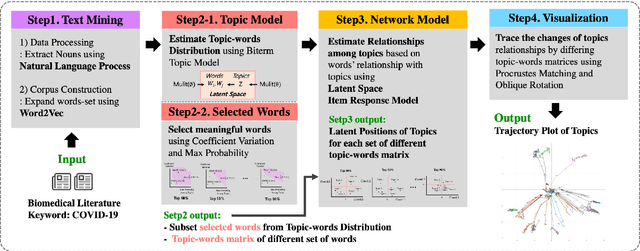


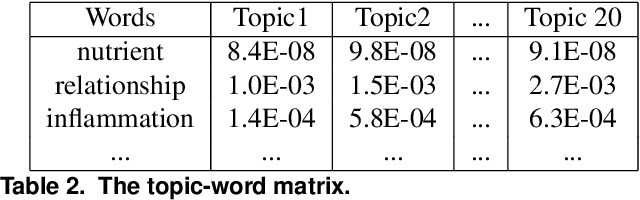
Since the emergence of the worldwide pandemic of COVID-19, relevant research has been published at a dazzling pace, which makes it hard to follow the research in this area without dedicated efforts. It is practically impossible to implement this task manually due to the high volume of the relevant literature. Text mining has been considered to be a powerful approach to address this challenge, especially the topic modeling, a well-known unsupervised method that aims to reveal latent topics from the literature. However, in spite of its potential utility, the results generated from this approach are often investigated manually. Hence, its application to the COVID-19 literature is not straightforward and expert knowledge is needed to make meaningful interpretations. In order to address these challenges, we propose a novel analytical framework for effective visualization and mining of topic modeling results. Here we assumed that topics constituting a paper can be positioned on an interaction map, which belongs to a high-dimensional Euclidean space. Based on this assumption, after summarizing topics with their topic-word distributions using the biterm topic model, we mapped these latent topics on networks to visualize relationships among the topics. Moreover, in the proposed approach, the change of relationships among topics can be traced using a trajectory plot generated with different levels of word richness. These results together provide a deeply mined and intuitive representation of relationships among topics related to a specific research area. The application of this proposed framework to the PubMed literature shows that our approach facilitates understanding of the topics constituting the COVID-19 knowledge.
Tired of Topic Models? Clusters of Pretrained Word Embeddings Make for Fast and Good Topics too!
Apr 30, 2020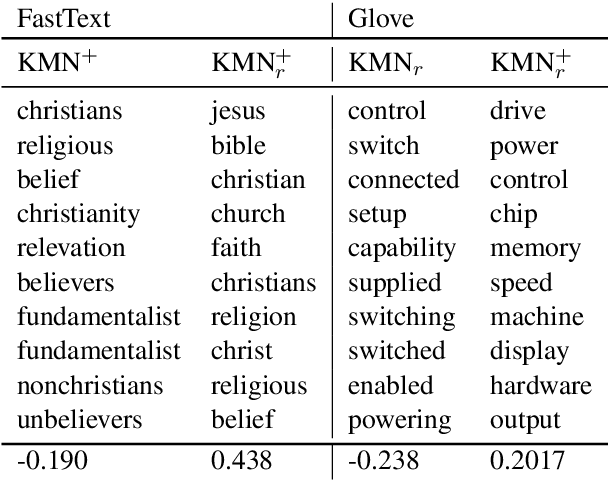
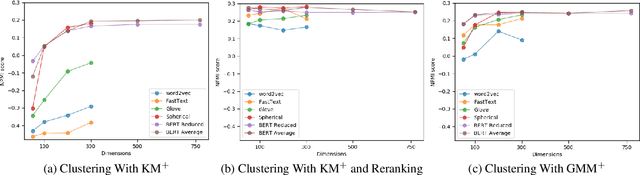
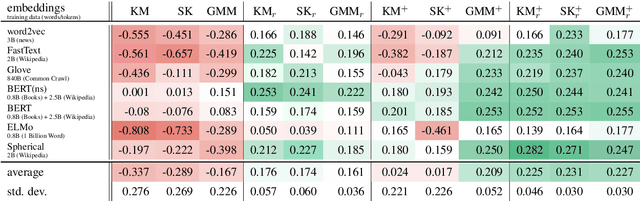
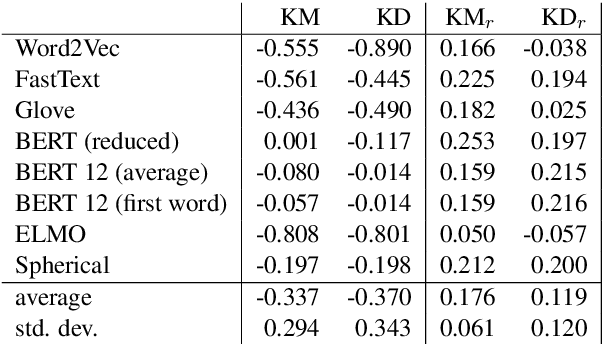
Topic models are a useful analysis tool to uncover the underlying themes within document collections. Probabilistic models which assume a generative story have been the dominant approach for topic modeling. We propose an alternative approach based on clustering readily available pre-trained word embeddings while incorporating document information for weighted clustering and reranking top words. We provide benchmarks for the combination of different word embeddings and clustering algorithms, and analyse their performance under dimensionality reduction with PCA. The best performing combination for our approach is comparable to classical models, and complexity analysis indicate that this is a practical alternative to traditional topic modeling.
Structure-Preserving 3D Garment Modeling with Neural Sewing Machines
Nov 12, 2022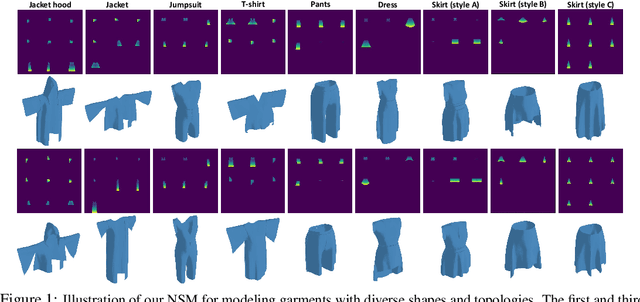

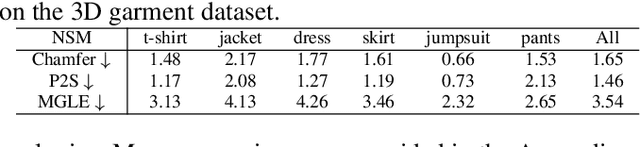
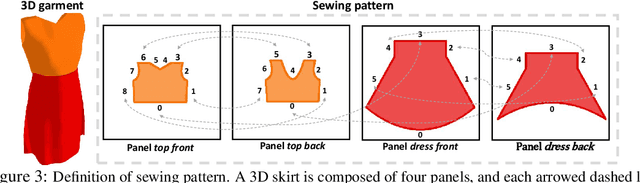
3D Garment modeling is a critical and challenging topic in the area of computer vision and graphics, with increasing attention focused on garment representation learning, garment reconstruction, and controllable garment manipulation, whereas existing methods were constrained to model garments under specific categories or with relatively simple topologies. In this paper, we propose a novel Neural Sewing Machine (NSM), a learning-based framework for structure-preserving 3D garment modeling, which is capable of learning representations for garments with diverse shapes and topologies and is successfully applied to 3D garment reconstruction and controllable manipulation. To model generic garments, we first obtain sewing pattern embedding via a unified sewing pattern encoding module, as the sewing pattern can accurately describe the intrinsic structure and the topology of the 3D garment. Then we use a 3D garment decoder to decode the sewing pattern embedding into a 3D garment using the UV-position maps with masks. To preserve the intrinsic structure of the predicted 3D garment, we introduce an inner-panel structure-preserving loss, an inter-panel structure-preserving loss, and a surface-normal loss in the learning process of our framework. We evaluate NSM on the public 3D garment dataset with sewing patterns with diverse garment shapes and categories. Extensive experiments demonstrate that the proposed NSM is capable of representing 3D garments under diverse garment shapes and topologies, realistically reconstructing 3D garments from 2D images with the preserved structure, and accurately manipulating the 3D garment categories, shapes, and topologies, outperforming the state-of-the-art methods by a clear margin.