 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
SocialVisTUM: An Interactive Visualization Toolkit for Correlated Neural Topic Models on Social Media Opinion Mining
Oct 20, 2021
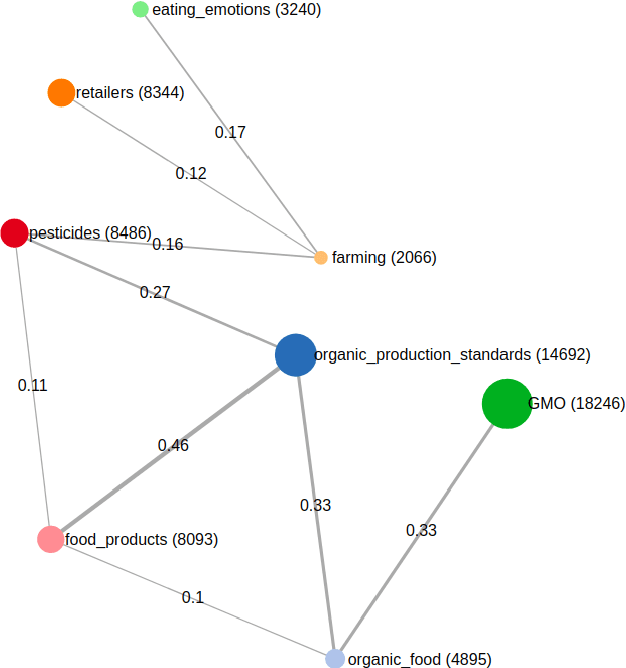

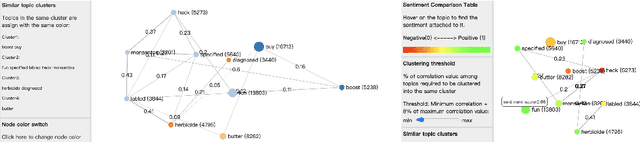
Recent research in opinion mining proposed word embedding-based topic modeling methods that provide superior coherence compared to traditional topic modeling. In this paper, we demonstrate how these methods can be used to display correlated topic models on social media texts using SocialVisTUM, our proposed interactive visualization toolkit. It displays a graph with topics as nodes and their correlations as edges. Further details are displayed interactively to support the exploration of large text collections, e.g., representative words and sentences of topics, topic and sentiment distributions, hierarchical topic clustering, and customizable, predefined topic labels. The toolkit optimizes automatically on custom data for optimal coherence. We show a working instance of the toolkit on data crawled from English social media discussions about organic food consumption. The visualization confirms findings of a qualitative consumer research study. SocialVisTUM and its training procedures are accessible online.
* Demo paper accepted for publication on RANLP 2021; 8 pages, 5 figures, 1 table
Crosslingual Topic Modeling with WikiPDA
Sep 23, 2020
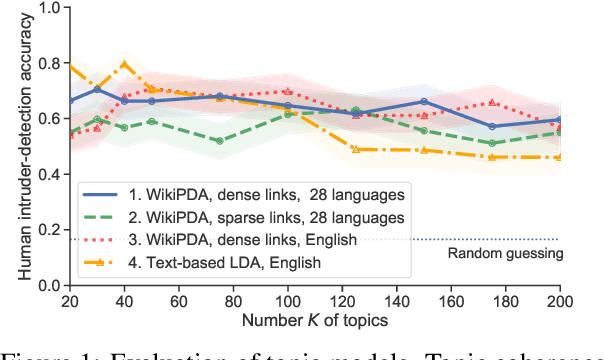
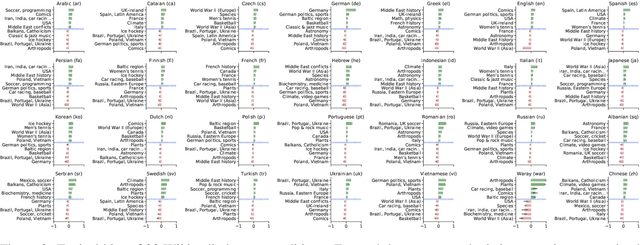
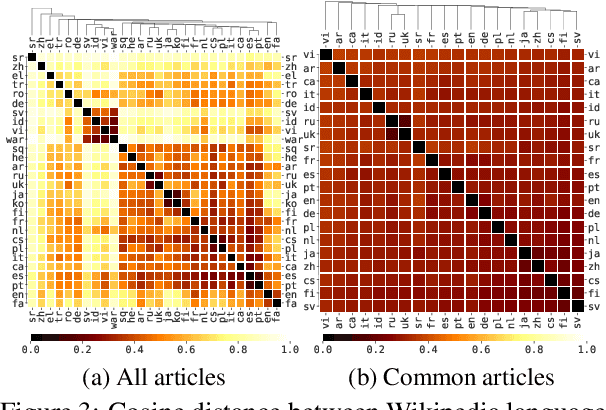
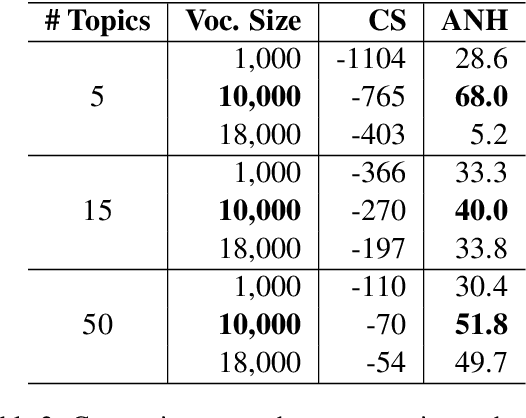
We present Wikipedia-based Polyglot Dirichlet Allocation (WikiPDA), a crosslingual topic model that learns to represent Wikipedia articles written in any language as distributions over a common set of language-independent topics. It leverages the fact that Wikipedia articles link to each other and are mapped to concepts in the Wikidata knowledge base, such that, when represented as bags of links, articles are inherently language-independent. WikiPDA works in two steps, by first densifying bags of links using matrix completion and then training a standard monolingual topic model. A human evaluation shows that WikiPDA produces more coherent topics than monolingual text-based LDA, thus offering crosslinguality at no cost. We demonstrate WikiPDA's utility in two applications: a study of topical biases in 28 Wikipedia editions, and crosslingual supervised classification. Finally, we highlight WikiPDA's capacity for zero-shot language transfer, where a model is reused for new languages without any fine-tuning.
One Configuration to Rule Them All? Towards Hyperparameter Transfer in Topic Models using Multi-Objective Bayesian Optimization
Feb 15, 2022
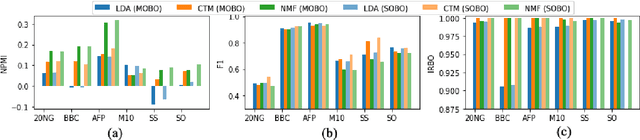
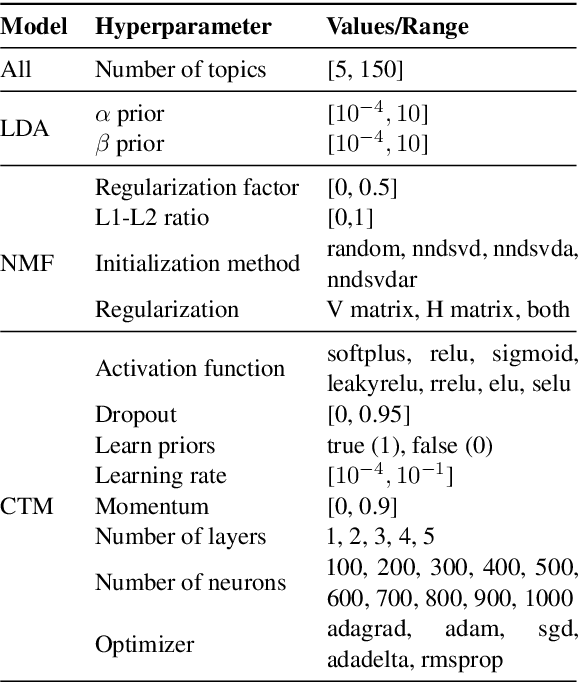
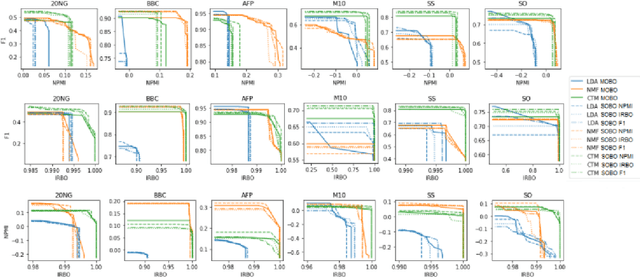
Topic models are statistical methods that extract underlying topics from document collections. When performing topic modeling, a user usually desires topics that are coherent, diverse between each other, and that constitute good document representations for downstream tasks (e.g. document classification). In this paper, we conduct a multi-objective hyperparameter optimization of three well-known topic models. The obtained results reveal the conflicting nature of different objectives and that the training corpus characteristics are crucial for the hyperparameter selection, suggesting that it is possible to transfer the optimal hyperparameter configurations between datasets.
Gene Expression based Survival Prediction for Cancer Patients: A Topic Modeling Approach
Mar 25, 2019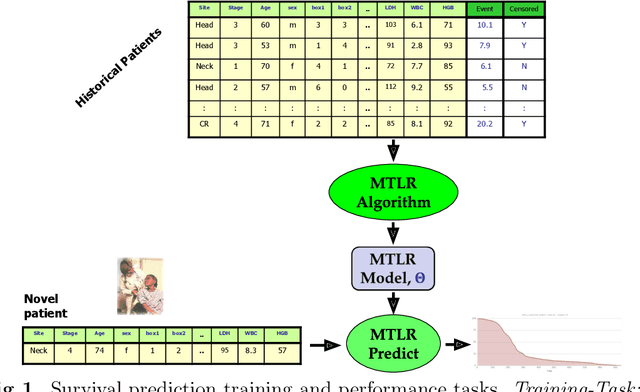
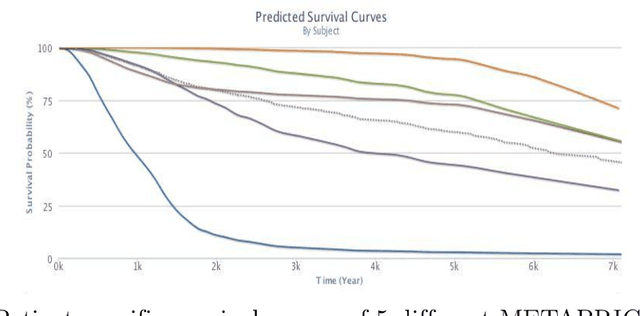
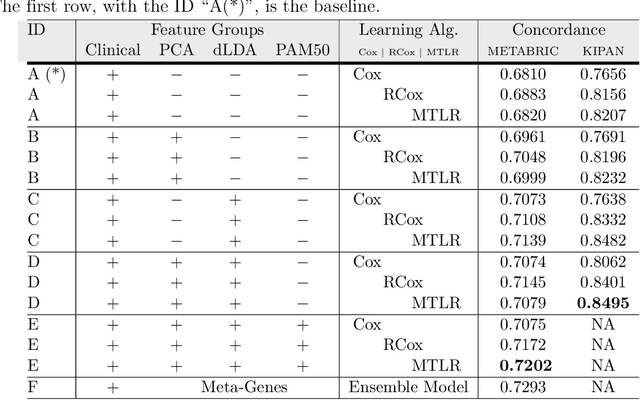
Cancer is one of the leading cause of death, worldwide. Many believe that genomic data will enable us to better predict the survival time of these patients, which will lead to better, more personalized treatment options and patient care. As standard survival prediction models have a hard time coping with the high-dimensionality of such gene expression (GE) data, many projects use some dimensionality reduction techniques to overcome this hurdle. We introduce a novel methodology, inspired by topic modeling from the natural language domain, to derive expressive features from the high-dimensional GE data. There, a document is represented as a mixture over a relatively small number of topics, where each topic corresponds to a distribution over the words; here, to accommodate the heterogeneity of a patient's cancer, we represent each patient (~document) as a mixture over cancer-topics, where each cancer-topic is a mixture over GE values (~words). This required some extensions to the standard LDA model eg: to accommodate the "real-valued" expression values - leading to our novel "discretized" Latent Dirichlet Allocation (dLDA) procedure. We initially focus on the METABRIC dataset, which describes breast cancer patients using the r=49,576 GE values, from microarrays. Our results show that our approach provides survival estimates that are more accurate than standard models, in terms of the standard Concordance measure. We then validate this approach by running it on the Pan-kidney (KIPAN) dataset, over r=15,529 GE values - here using the mRNAseq modality - and find that it again achieves excellent results. In both cases, we also show that the resulting model is calibrated, using the recent "D-calibrated" measure. These successes, in two different cancer types and expression modalities, demonstrates the generality, and the effectiveness, of this approach.
Jointly Dynamic Topic Model for Recognition of Lead-lag Relationship in Two Text Corpora
Nov 21, 2021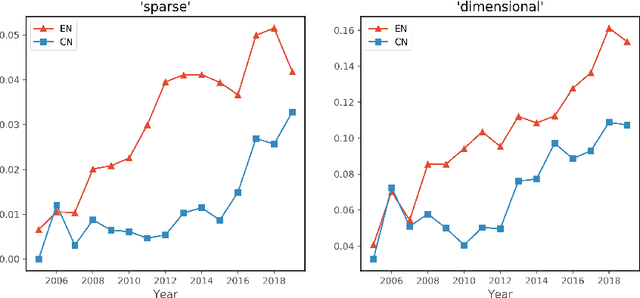
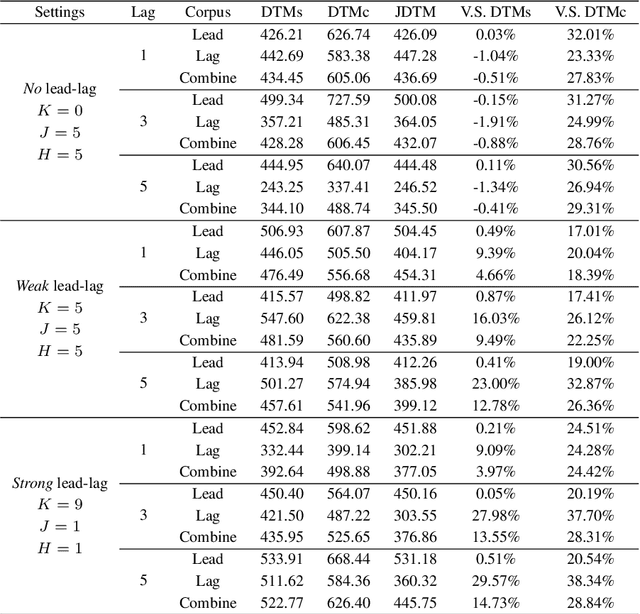
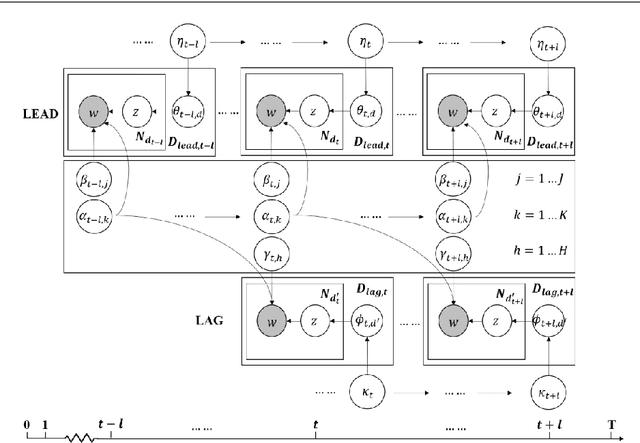
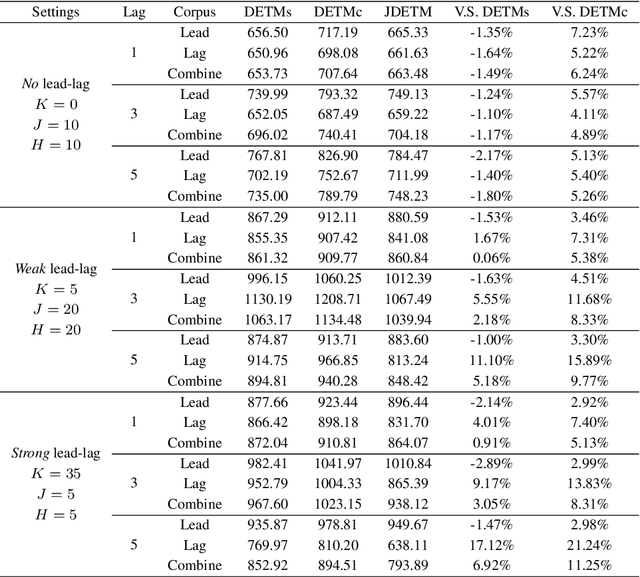
Topic evolution modeling has received significant attentions in recent decades. Although various topic evolution models have been proposed, most studies focus on the single document corpus. However in practice, we can easily access data from multiple sources and also observe relationships between them. Then it is of great interest to recognize the relationship between multiple text corpora and further utilize this relationship to improve topic modeling. In this work, we focus on a special type of relationship between two text corpora, which we define as the "lead-lag relationship". This relationship characterizes the phenomenon that one text corpus would influence the topics to be discussed in the other text corpus in the future. To discover the lead-lag relationship, we propose a jointly dynamic topic model and also develop an embedding extension to address the modeling problem of large-scale text corpus. With the recognized lead-lag relationship, the similarities of the two text corpora can be figured out and the quality of topic learning in both corpora can be improved. We numerically investigate the performance of the jointly dynamic topic modeling approach using synthetic data. Finally, we apply the proposed model on two text corpora consisting of statistical papers and the graduation theses. Results show the proposed model can well recognize the lead-lag relationship between the two corpora, and the specific and shared topic patterns in the two corpora are also discovered.
Unsupervised Graph-based Topic Modeling from Video Transcriptions
May 04, 2021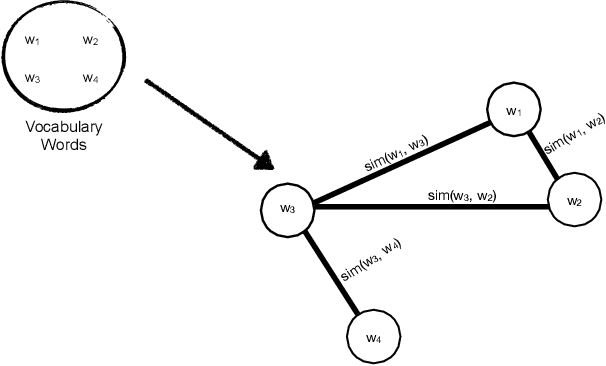



To unfold the tremendous amount of audiovisual data uploaded daily to social media platforms, effective topic modelling techniques are needed. Existing work tends to apply variants of topic models on text data sets. In this paper, we aim at developing a topic extractor on video transcriptions. The model improves coherence by exploiting neural word embeddings through a graph-based clustering method. Unlike typical topic models, this approach works without knowing the true number of topics. Experimental results on the real-life multimodal data set MuSe-CaR demonstrates that our approach extracts coherent and meaningful topics, outperforming baseline methods. Furthermore, we successfully demonstrate the generalisability of our approach on a pure text review data set.
A Novel Perspective to Look At Attention: Bi-level Attention-based Explainable Topic Modeling for News Classification
Mar 14, 2022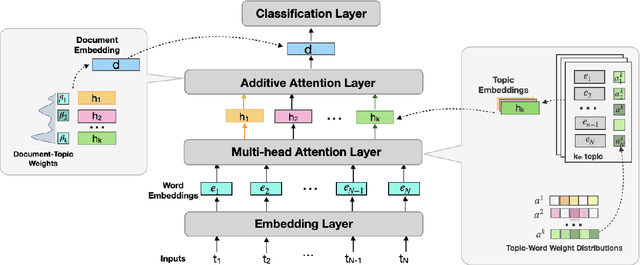

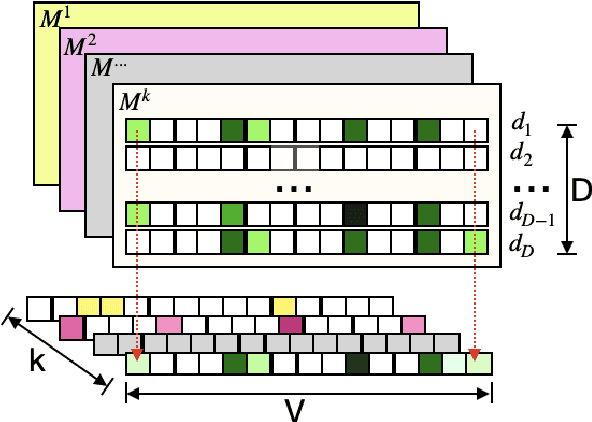
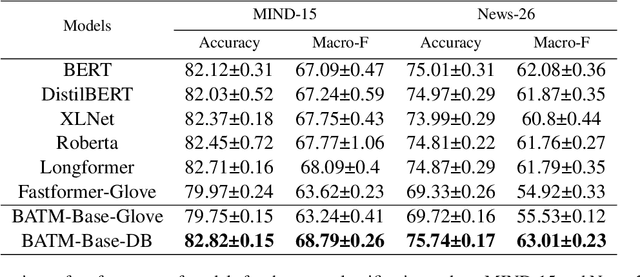
Many recent deep learning-based solutions have widely adopted the attention-based mechanism in various tasks of the NLP discipline. However, the inherent characteristics of deep learning models and the flexibility of the attention mechanism increase the models' complexity, thus leading to challenges in model explainability. In this paper, to address this challenge, we propose a novel practical framework by utilizing a two-tier attention architecture to decouple the complexity of explanation and the decision-making process. We apply it in the context of a news article classification task. The experiments on two large-scaled news corpora demonstrate that the proposed model can achieve competitive performance with many state-of-the-art alternatives and illustrate its appropriateness from an explainability perspective.
Evaluation of Non-Negative Matrix Factorization and n-stage Latent Dirichlet Allocation for Emotion Analysis in Turkish Tweets
Sep 27, 2021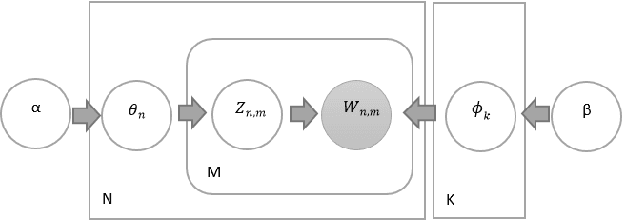
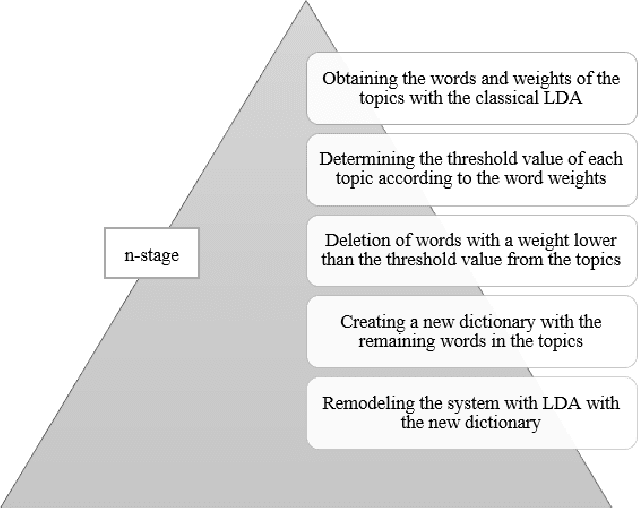


With the development of technology, the use of social media has become quite common. Analyzing comments on social media in areas such as media and advertising plays an important role today. For this reason, new and traditional natural language processing methods are used to detect the emotion of these shares. In this paper, the Latent Dirichlet Allocation, namely LDA, and Non-Negative Matrix Factorization methods in topic modeling were used to determine which emotion the Turkish tweets posted via Twitter. In addition, the accuracy of a proposed n-level method based on LDA was analyzed. Dataset consists of 5 emotions, namely angry, fear, happy, sad and confused. NMF was the most successful method among all topic modeling methods in this study. Then, the F1-measure of Random Forest, Naive Bayes and Support Vector Machine methods was analyzed by obtaining a file suitable for Weka by using the word weights and class labels of the topics. Among the Weka results, the most successful method was n-stage LDA, and the most successful algorithm was Random Forest.
* Published in: 2019 Innovations in Intelligent Systems and Applications Conference (ASYU). This paper is extension version of Comparison Method for Emotion Detection of Twitter Users (http://dx.doi.org/10.1109/ASYU48272.2019.8946435). Please citation this IEEE paper
Neural Contrastive Clustering: Fully Unsupervised Bias Reduction for Sentiment Classification
Apr 22, 2022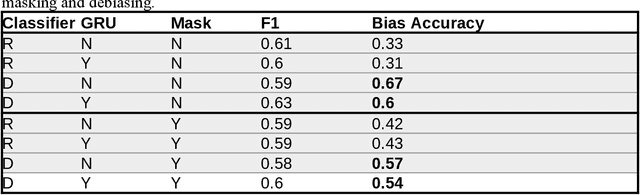
Background: Neural networks produce biased classification results due to correlation bias (they learn correlations between their inputs and outputs to classify samples, even when those correlations do not represent cause-and-effect relationships). Objective: This study introduces a fully unsupervised method of mitigating correlation bias, demonstrated with sentiment classification on COVID-19 social media data. Methods: Correlation bias in sentiment classification often arises in conversations about controversial topics. Therefore, this study uses adversarial learning to contrast clusters based on sentiment classification labels, with clusters produced by unsupervised topic modeling. This discourages the neural network from learning topic-related features that produce biased classification results. Results: Compared to a baseline classifier, neural contrastive clustering approximately doubles accuracy on bias-prone sentences for human-labeled COVID-19 social media data, without adversely affecting the classifier's overall F1 score. Despite being a fully unsupervised approach, neural contrastive clustering achieves a larger improvement in accuracy on bias-prone sentences than a supervised masking approach. Conclusions: Neural contrastive clustering reduces correlation bias in sentiment text classification. Further research is needed to explore generalizing this technique to other neural network architectures and application domains.
Hate speech, Censorship, and Freedom of Speech: The Changing Policies of Reddit
Mar 18, 2022



This paper examines the shift in focus on content policies and user attitudes on the social media platform Reddit. We do this by focusing on comments from general Reddit users from five posts made by admins (moderators) on updates to Reddit Content Policy. All five concern the nature of what kind of content is allowed to be posted on Reddit, and which measures will be taken against content that violates these policies. We use topic modeling to probe how the general discourse for Redditors has changed around limitations on content, and later, limitations on hate speech, or speech that incites violence against a particular group. We show that there is a clear shift in both the contents and the user attitudes that can be linked to contemporary societal upheaval as well as newly passed laws and regulations, and contribute to the wider discussion on hate speech moderation.