 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
Nested Variational Autoencoder for Topic Modeling on Microtexts with Word Vectors
May 01, 2019

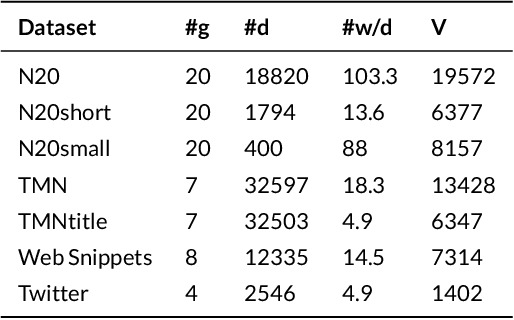
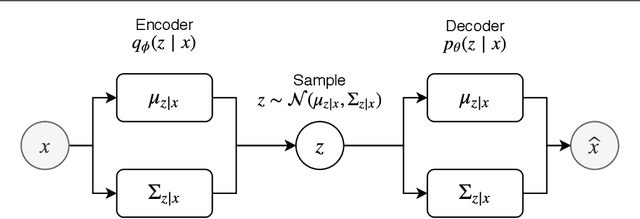
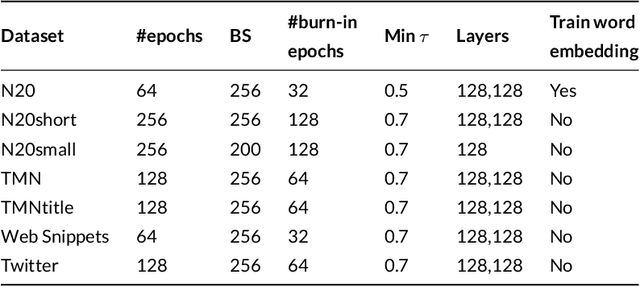
Most of the information on the Internet is represented in the form of microtexts, which are short text snippets like news headlines or tweets. These source of information is abundant and mining this data could uncover meaningful insights. Topic modeling is one of the popular methods to extract knowledge from a collection of documents, nevertheless conventional topic models such as Latent Dirichlet Allocation (LDA) is unable to perform well on short documents, mostly due to the scarcity of word co-occurrence statistics embedded in the data. The objective of our research is to create a topic model which can achieve great performances on microtexts while requiring a small runtime for scalability to large datasets. To solve the lack of information of microtexts, we allow our method to take advantage of word embeddings for additional knowledge of relationships between words. For speed and scalability, we apply Auto-Encoding Variational Bayes, an algorithm that can perform efficient black-box inference in probabilistic models. The result of our work is a novel topic model called Nested Variational Autoencoder which is a distribution that takes into account word vectors and is parameterized by a neural network architecture. For optimization, the model is trained to approximate the posterior distribution of the original LDA model. Experiments show the improvements of our model on microtexts as well as its runtime advantage.
Multi-dimensional Racism Classification during COVID-19: Stigmatization, Offensiveness, Blame, and Exclusion
Aug 29, 2022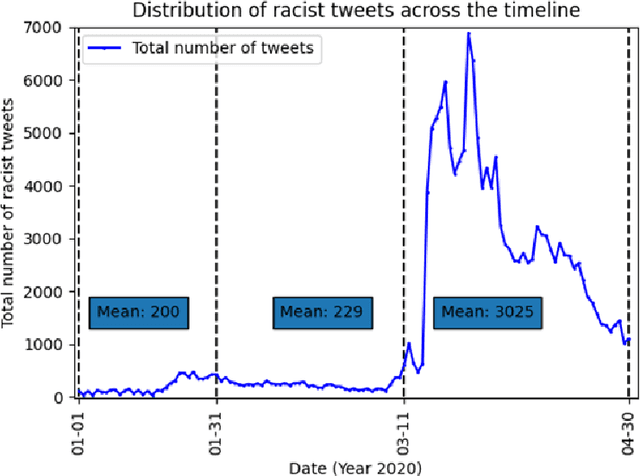
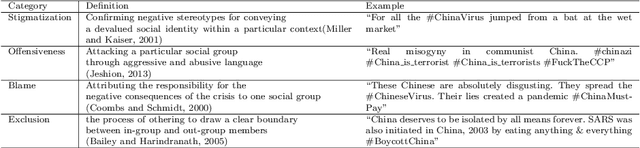
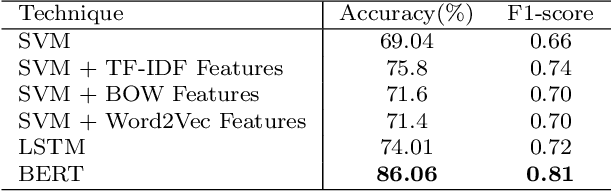
Transcending the binary categorization of racist texts, our study takes cues from social science theories to develop a multi-dimensional model for racism detection, namely stigmatization, offensiveness, blame, and exclusion. With the aid of BERT and topic modeling, this categorical detection enables insights into the underlying subtlety of racist discussion on digital platforms during COVID-19. Our study contributes to enriching the scholarly discussion on deviant racist behaviours on social media. First, a stage-wise analysis is applied to capture the dynamics of the topic changes across the early stages of COVID-19 which transformed from a domestic epidemic to an international public health emergency and later to a global pandemic. Furthermore, mapping this trend enables a more accurate prediction of public opinion evolvement concerning racism in the offline world, and meanwhile, the enactment of specified intervention strategies to combat the upsurge of racism during the global public health crisis like COVID-19. In addition, this interdisciplinary research also points out a direction for future studies on social network analysis and mining. Integration of social science perspectives into the development of computational methods provides insights into more accurate data detection and analytics.
Generalized Identifiability Bounds for Mixture Models with Grouped Samples
Jul 22, 2022
Recent work has shown that finite mixture models with $m$ components are identifiable, while making no assumptions on the mixture components, so long as one has access to groups of samples of size $2m-1$ which are known to come from the same mixture component. In this work we generalize that result and show that, if every subset of $k$ mixture components of a mixture model are linearly independent, then that mixture model is identifiable with only $(2m-1)/(k-1)$ samples per group. We further show that this value cannot be improved. We prove an analogous result for a stronger form of identifiability known as "determinedness" along with a corresponding lower bound. This independence assumption almost surely holds if mixture components are chosen randomly from a $k$-dimensional space. We describe some implications of our results for multinomial mixture models and topic modeling.
Using Variational Inference and MapReduce to Scale Topic Modeling
Jul 19, 2011
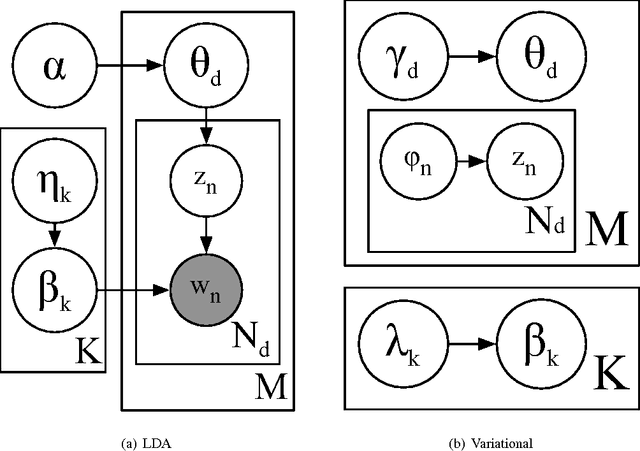
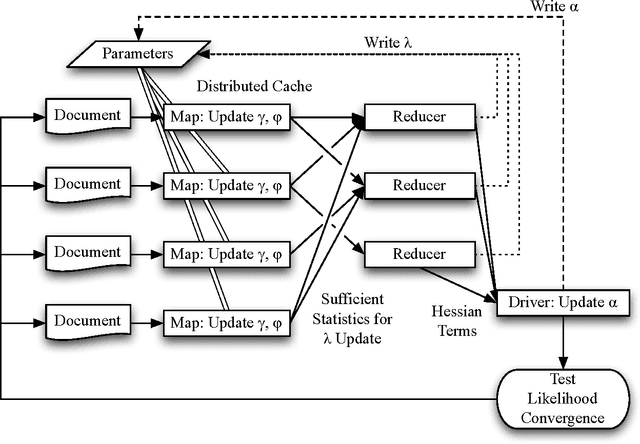
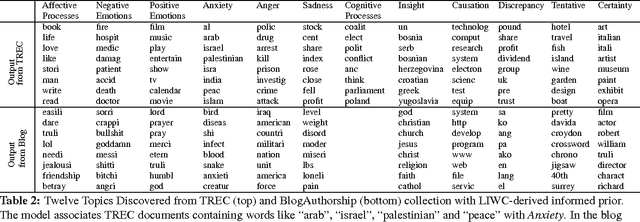
Latent Dirichlet Allocation (LDA) is a popular topic modeling technique for exploring document collections. Because of the increasing prevalence of large datasets, there is a need to improve the scalability of inference of LDA. In this paper, we propose a technique called ~\emph{MapReduce LDA} (Mr. LDA) to accommodate very large corpus collections in the MapReduce framework. In contrast to other techniques to scale inference for LDA, which use Gibbs sampling, we use variational inference. Our solution efficiently distributes computation and is relatively simple to implement. More importantly, this variational implementation, unlike highly tuned and specialized implementations, is easily extensible. We demonstrate two extensions of the model possible with this scalable framework: informed priors to guide topic discovery and modeling topics from a multilingual corpus.
Exploring the Political Agenda of the European Parliament Using a Dynamic Topic Modeling Approach
Jul 11, 2016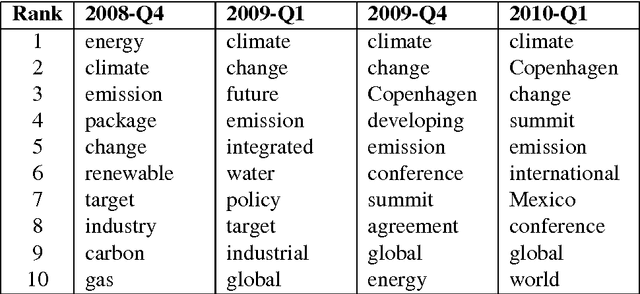
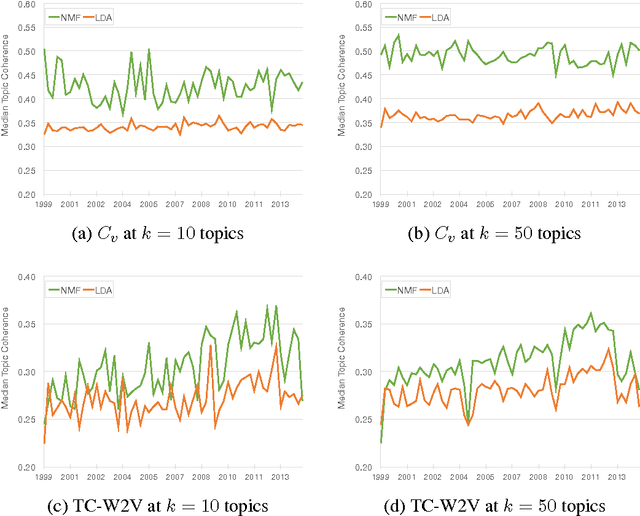
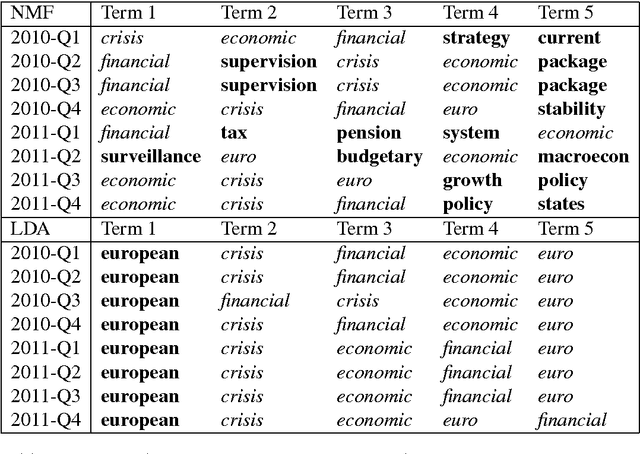
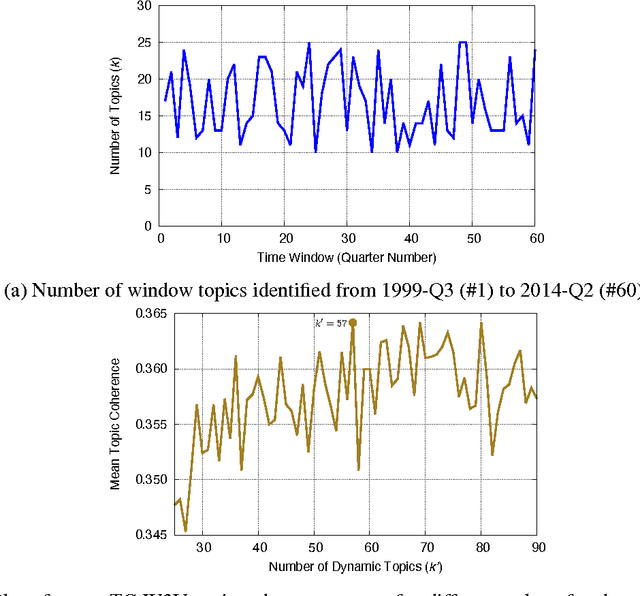
This study analyzes the political agenda of the European Parliament (EP) plenary, how it has evolved over time, and the manner in which Members of the European Parliament (MEPs) have reacted to external and internal stimuli when making plenary speeches. To unveil the plenary agenda and detect latent themes in legislative speeches over time, MEP speech content is analyzed using a new dynamic topic modeling method based on two layers of Non-negative Matrix Factorization (NMF). This method is applied to a new corpus of all English language legislative speeches in the EP plenary from the period 1999-2014. Our findings suggest that two-layer NMF is a valuable alternative to existing dynamic topic modeling approaches found in the literature, and can unveil niche topics and associated vocabularies not captured by existing methods. Substantively, our findings suggest that the political agenda of the EP evolves significantly over time and reacts to exogenous events such as EU Treaty referenda and the emergence of the Euro-crisis. MEP contributions to the plenary agenda are also found to be impacted upon by voting behaviour and the committee structure of the Parliament.
Assessing the trade-off between prediction accuracy and interpretability for topic modeling on energetic materials corpora
Jun 01, 2022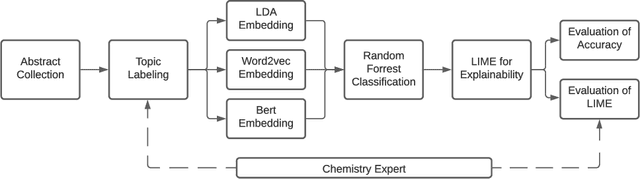
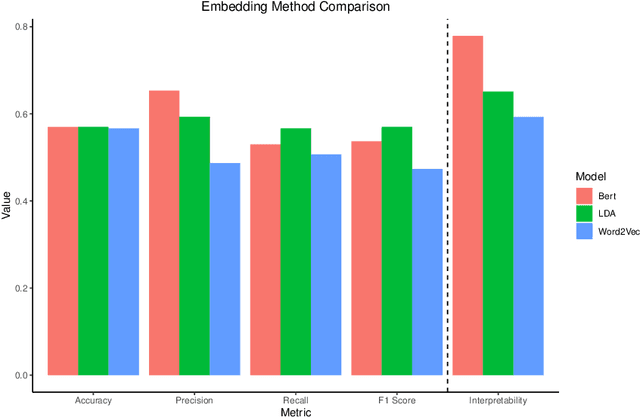

As the amount and variety of energetics research increases, machine aware topic identification is necessary to streamline future research pipelines. The makeup of an automatic topic identification process consists of creating document representations and performing classification. However, the implementation of these processes on energetics research imposes new challenges. Energetics datasets contain many scientific terms that are necessary to understand the context of a document but may require more complex document representations. Secondly, the predictions from classification must be understandable and trusted by the chemists within the pipeline. In this work, we study the trade-off between prediction accuracy and interpretability by implementing three document embedding methods that vary in computational complexity. With our accuracy results, we also introduce local interpretability model-agnostic explanations (LIME) of each prediction to provide a localized understanding of each prediction and to validate classifier decisions with our team of energetics experts. This study was carried out on a novel labeled energetics dataset created and validated by our team of energetics experts.
An Empirical Studies on How the Developers Discussed about Pandas Topics
Oct 07, 2022
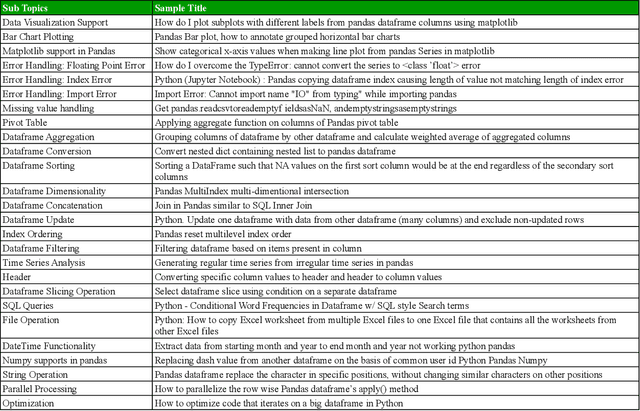
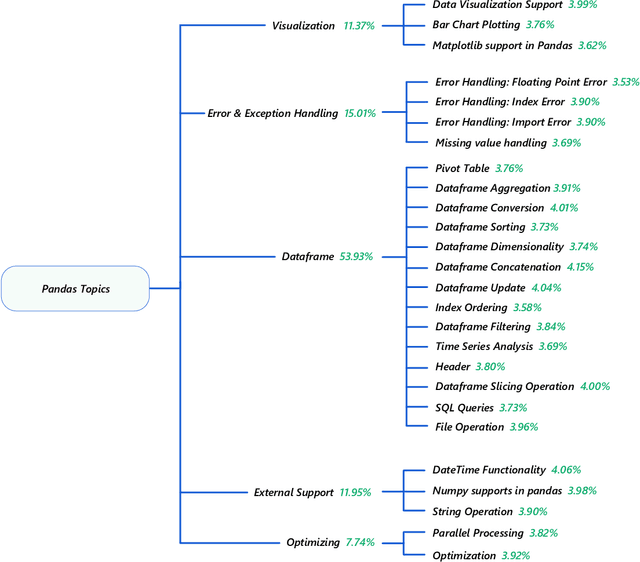
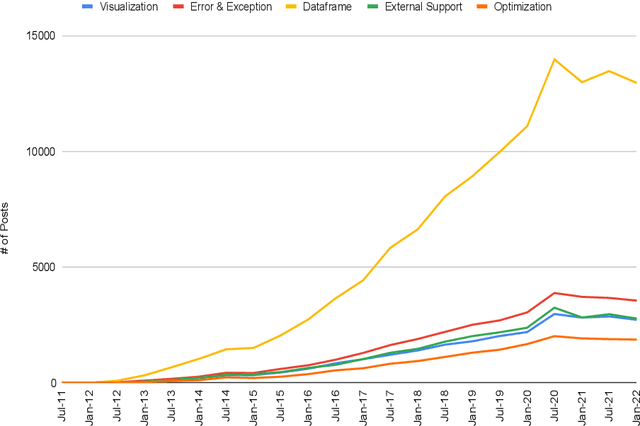
Pandas is defined as a software library which is used for data analysis in Python programming language. As pandas is a fast, easy and open source data analysis tool, it is rapidly used in different software engineering projects like software development, machine learning, computer vision, natural language processing, robotics, and others. So a huge interests are shown in software developers regarding pandas and a huge number of discussions are now becoming dominant in online developer forums, like Stack Overflow (SO). Such discussions can help to understand the popularity of pandas library and also can help to understand the importance, prevalence, difficulties of pandas topics. The main aim of this research paper is to find the popularity and difficulty of pandas topics. For this regard, SO posts are collected which are related to pandas topic discussions. Topic modeling are done on the textual contents of the posts. We found 26 topics which we further categorized into 5 board categories. We observed that developers discuss variety of pandas topics in SO related to error and excepting handling, visualization, External support, dataframe, and optimization. In addition, a trend chart is generated according to the discussion of topics in a predefined time series. The finding of this paper can provide a path to help the developers, educators and learners. For example, beginner developers can learn most important topics in pandas which are essential for develop any model. Educators can understand the topics which seem hard to learners and can build different tutorials which can make that pandas topic understandable. From this empirical study it is possible to understand the preferences of developers in pandas topic by processing their SO posts
Learning Object-Centric Neural Scattering Functions for Free-viewpoint Relighting and Scene Composition
Mar 10, 2023
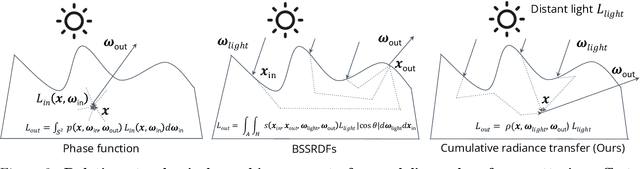
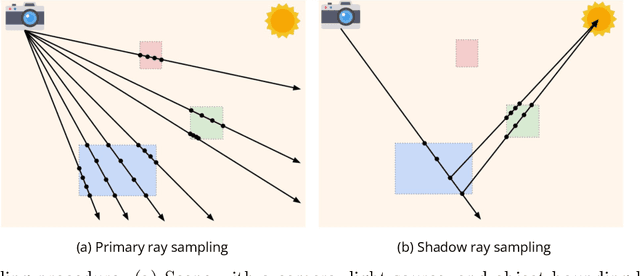

Photorealistic object appearance modeling from 2D images is a constant topic in vision and graphics. While neural implicit methods (such as Neural Radiance Fields) have shown high-fidelity view synthesis results, they cannot relight the captured objects. More recent neural inverse rendering approaches have enabled object relighting, but they represent surface properties as simple BRDFs, and therefore cannot handle translucent objects. We propose Object-Centric Neural Scattering Functions (OSFs) for learning to reconstruct object appearance from only images. OSFs not only support free-viewpoint object relighting, but also can model both opaque and translucent objects. While accurately modeling subsurface light transport for translucent objects can be highly complex and even intractable for neural methods, OSFs learn to approximate the radiance transfer from a distant light to an outgoing direction at any spatial location. This approximation avoids explicitly modeling complex subsurface scattering, making learning a neural implicit model tractable. Experiments on real and synthetic data show that OSFs accurately reconstruct appearances for both opaque and translucent objects, allowing faithful free-viewpoint relighting as well as scene composition.
Few-shot Learning for Topic Modeling
Apr 19, 2021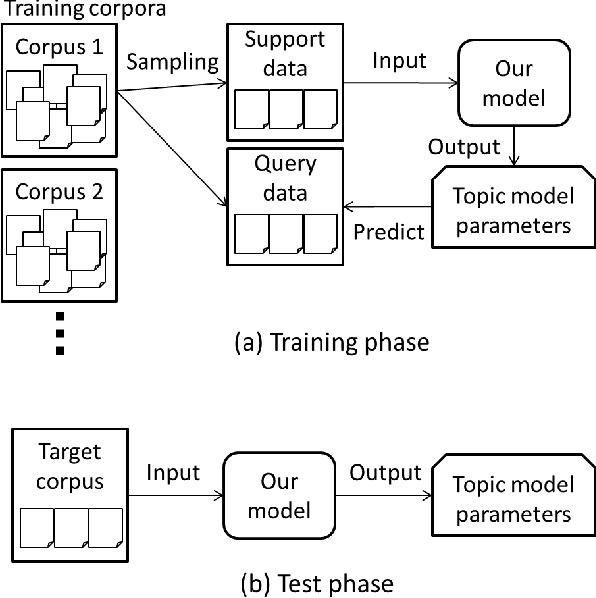

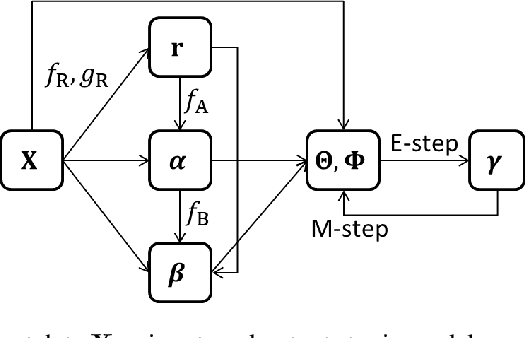
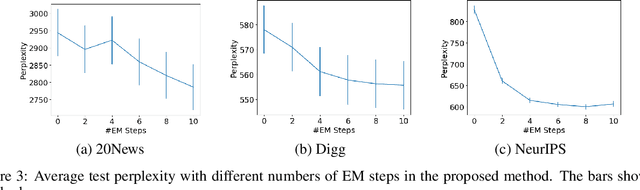
Topic models have been successfully used for analyzing text documents. However, with existing topic models, many documents are required for training. In this paper, we propose a neural network-based few-shot learning method that can learn a topic model from just a few documents. The neural networks in our model take a small number of documents as inputs, and output topic model priors. The proposed method trains the neural networks such that the expected test likelihood is improved when topic model parameters are estimated by maximizing the posterior probability using the priors based on the EM algorithm. Since each step in the EM algorithm is differentiable, the proposed method can backpropagate the loss through the EM algorithm to train the neural networks. The expected test likelihood is maximized by a stochastic gradient descent method using a set of multiple text corpora with an episodic training framework. In our experiments, we demonstrate that the proposed method achieves better perplexity than existing methods using three real-world text document sets.
Court Judgement Labeling on HKLII
Aug 03, 2022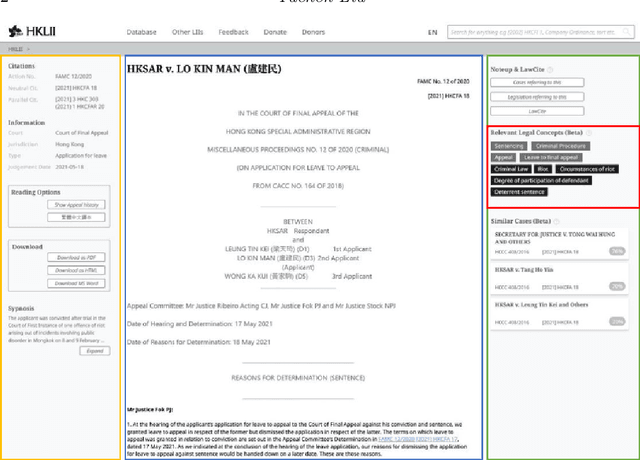
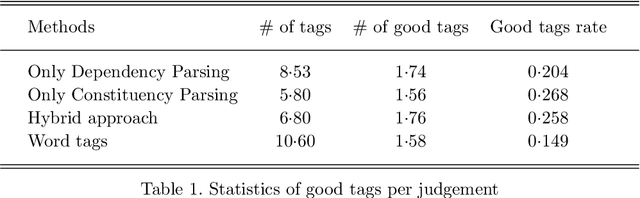
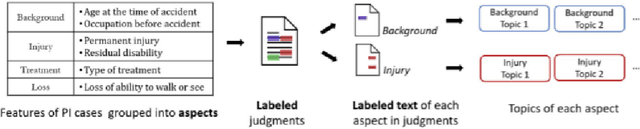
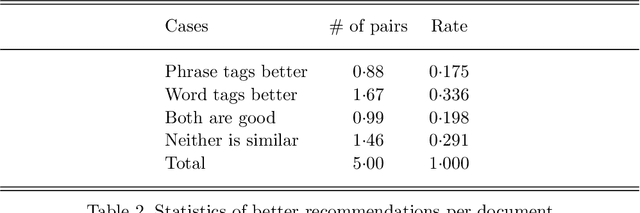
HKLII has served as the repository of legal documents in Hong Kong for a decade. Our team aims to incorporate NLP techniques into the website to make it more intelligent. To achieve this goal, this individual task is to label each court judgement by some tags. These tags are legally important to summarize the judgement and can guide the user to similar judgements. We introduce a heuristic system to solve the problem, which starts from Aspect-driven Topic Modeling and uses Dependency Parsing and Constituency Parsing for phrase generation. We also construct a legal term tree for Hong Kong and implemented a sentence simplification module to support the system. Finally, we propose a similar document recommendation algorithm based on the generated tags. It enables users to find similar documents based on a few selected aspects rather than the whole passage. Experiment results show that this system is the best approach for this specific task. It is better than simple term extraction method in terms of summarizing the document, and the recommendation algorithm is more effective than full-text comparison approaches. We believe that the system has huge potential in law as well as in other areas.