 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
COMPASS: Computational Mapping of Patient-Therapist Alliance Strategies with Language Modeling
Feb 22, 2024
The therapeutic working alliance is a critical factor in predicting the success of psychotherapy treatment. Traditionally, working alliance assessment relies on questionnaires completed by both therapists and patients. In this paper, we present COMPASS, a novel framework to directly infer the therapeutic working alliance from the natural language used in psychotherapy sessions. Our approach utilizes advanced large language models to analyze transcripts of psychotherapy sessions and compare them with distributed representations of statements in the working alliance inventory. Analyzing a dataset of over 950 sessions covering diverse psychiatric conditions, we demonstrate the effectiveness of our method in microscopically mapping patient-therapist alignment trajectories and providing interpretability for clinical psychiatry and in identifying emerging patterns related to the condition being treated. By employing various neural topic modeling techniques in combination with generative language prompting, we analyze the topical characteristics of different psychiatric conditions and incorporate temporal modeling to capture the evolution of topics at a turn-level resolution. This combined framework enhances the understanding of therapeutic interactions, enabling timely feedback for therapists regarding conversation quality and providing interpretable insights to improve the effectiveness of psychotherapy.
Analyzing Public Reactions, Perceptions, and Attitudes during the MPox Outbreak: Findings from Topic Modeling of Tweets
Dec 19, 2023The recent outbreak of the MPox virus has resulted in a tremendous increase in the usage of Twitter. Prior works in this area of research have primarily focused on the sentiment analysis and content analysis of these Tweets, and the few works that have focused on topic modeling have multiple limitations. This paper aims to address this research gap and makes two scientific contributions to this field. First, it presents the results of performing Topic Modeling on 601,432 Tweets about the 2022 Mpox outbreak that were posted on Twitter between 7 May 2022 and 3 March 2023. The results indicate that the conversations on Twitter related to Mpox during this time range may be broadly categorized into four distinct themes - Views and Perspectives about Mpox, Updates on Cases and Investigations about Mpox, Mpox and the LGBTQIA+ Community, and Mpox and COVID-19. Second, the paper presents the findings from the analysis of these Tweets. The results show that the theme that was most popular on Twitter (in terms of the number of Tweets posted) during this time range was Views and Perspectives about Mpox. This was followed by the theme of Mpox and the LGBTQIA+ Community, which was followed by the themes of Mpox and COVID-19 and Updates on Cases and Investigations about Mpox, respectively. Finally, a comparison with related studies in this area of research is also presented to highlight the novelty and significance of this research work.
TopicGPT: A Prompt-based Topic Modeling Framework
Nov 02, 2023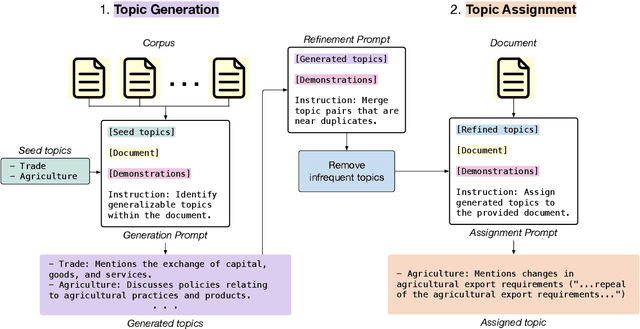
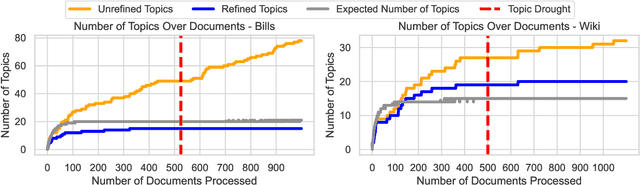
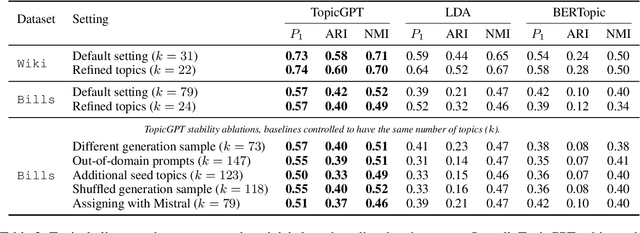
Topic modeling is a well-established technique for exploring text corpora. Conventional topic models (e.g., LDA) represent topics as bags of words that often require "reading the tea leaves" to interpret; additionally, they offer users minimal semantic control over topics. To tackle these issues, we introduce TopicGPT, a prompt-based framework that uses large language models (LLMs) to uncover latent topics within a provided text collection. TopicGPT produces topics that align better with human categorizations compared to competing methods: for example, it achieves a harmonic mean purity of 0.74 against human-annotated Wikipedia topics compared to 0.64 for the strongest baseline. Its topics are also more interpretable, dispensing with ambiguous bags of words in favor of topics with natural language labels and associated free-form descriptions. Moreover, the framework is highly adaptable, allowing users to specify constraints and modify topics without the need for model retraining. TopicGPT can be further extended to hierarchical topical modeling, enabling users to explore topics at various levels of granularity. By streamlining access to high-quality and interpretable topics, TopicGPT represents a compelling, human-centered approach to topic modeling.
CFTM: Continuous time fractional topic model
Feb 07, 2024In this paper, we propose the Continuous Time Fractional Topic Model (cFTM), a new method for dynamic topic modeling. This approach incorporates fractional Brownian motion~(fBm) to effectively identify positive or negative correlations in topic and word distribution over time, revealing long-term dependency or roughness. Our theoretical analysis shows that the cFTM can capture these long-term dependency or roughness in both topic and word distributions, mirroring the main characteristics of fBm. Moreover, we prove that the parameter estimation process for the cFTM is on par with that of LDA, traditional topic models. To demonstrate the cFTM's property, we conduct empirical study using economic news articles. The results from these tests support the model's ability to identify and track long-term dependency or roughness in topics over time.
Longitudinal Sentiment Topic Modelling of Reddit Posts
Jan 24, 2024In this study, we analyze texts of Reddit posts written by students of four major Canadian universities. We gauge the emotional tone and uncover prevailing themes and discussions through longitudinal topic modeling of posts textual data. Our study focuses on four years, 2020-2023, covering COVID-19 pandemic and after pandemic years. Our results highlight a gradual uptick in discussions related to mental health.
Identifying Reasons for Contraceptive Switching from Real-World Data Using Large Language Models
Feb 06, 2024Prescription contraceptives play a critical role in supporting women's reproductive health. With nearly 50 million women in the United States using contraceptives, understanding the factors that drive contraceptives selection and switching is of significant interest. However, many factors related to medication switching are often only captured in unstructured clinical notes and can be difficult to extract. Here, we evaluate the zero-shot abilities of a recently developed large language model, GPT-4 (via HIPAA-compliant Microsoft Azure API), to identify reasons for switching between classes of contraceptives from the UCSF Information Commons clinical notes dataset. We demonstrate that GPT-4 can accurately extract reasons for contraceptive switching, outperforming baseline BERT-based models with microF1 scores of 0.849 and 0.881 for contraceptive start and stop extraction, respectively. Human evaluation of GPT-4-extracted reasons for switching showed 91.4% accuracy, with minimal hallucinations. Using extracted reasons, we identified patient preference, adverse events, and insurance as key reasons for switching using unsupervised topic modeling approaches. Notably, we also showed using our approach that "weight gain/mood change" and "insurance coverage" are disproportionately found as reasons for contraceptive switching in specific demographic populations. Our code and supplemental data are available at https://github.com/BMiao10/contraceptive-switching.
Statistical Agnostic Regression: a machine learning method to validate regression models
Feb 23, 2024Regression analysis is a central topic in statistical modeling, aiming to estimate the relationships between a dependent variable, commonly referred to as the response variable, and one or more independent variables, i.e., explanatory variables. Linear regression is by far the most popular method for performing this task in several fields of research, such as prediction, forecasting, or causal inference. Beyond various classical methods to solve linear regression problems, such as Ordinary Least Squares, Ridge, or Lasso regressions - which are often the foundation for more advanced machine learning (ML) techniques - the latter have been successfully applied in this scenario without a formal definition of statistical significance. At most, permutation or classical analyses based on empirical measures (e.g., residuals or accuracy) have been conducted to reflect the greater ability of ML estimations for detection. In this paper, we introduce a method, named Statistical Agnostic Regression (SAR), for evaluating the statistical significance of an ML-based linear regression based on concentration inequalities of the actual risk using the analysis of the worst case. To achieve this goal, similar to the classification problem, we define a threshold to establish that there is sufficient evidence with a probability of at least 1-eta to conclude that there is a linear relationship in the population between the explanatory (feature) and the response (label) variables. Simulations in only two dimensions demonstrate the ability of the proposed agnostic test to provide a similar analysis of variance given by the classical $F$ test for the slope parameter.
Let the Pretrained Language Models "Imagine" for Short Texts Topic Modeling
Oct 24, 2023

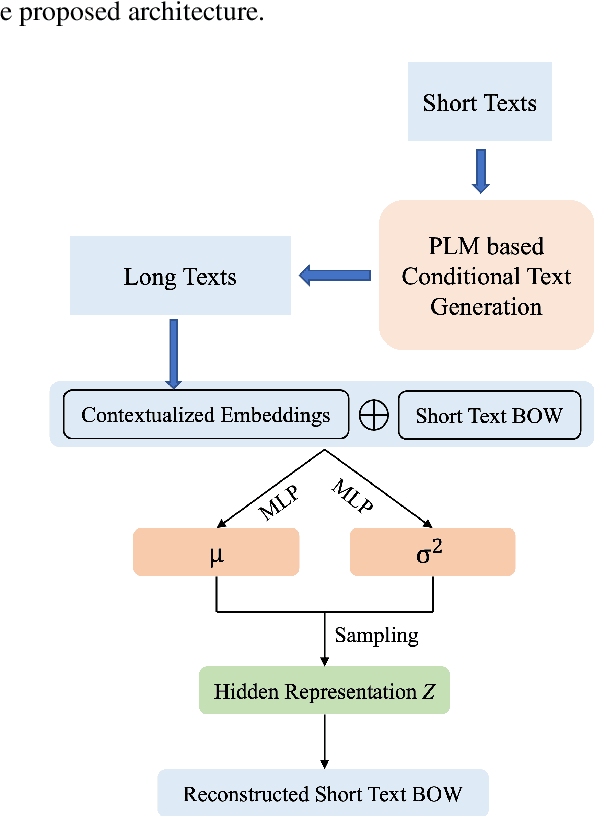
Topic models are one of the compelling methods for discovering latent semantics in a document collection. However, it assumes that a document has sufficient co-occurrence information to be effective. However, in short texts, co-occurrence information is minimal, which results in feature sparsity in document representation. Therefore, existing topic models (probabilistic or neural) mostly fail to mine patterns from them to generate coherent topics. In this paper, we take a new approach to short-text topic modeling to address the data-sparsity issue by extending short text into longer sequences using existing pre-trained language models (PLMs). Besides, we provide a simple solution extending a neural topic model to reduce the effect of noisy out-of-topics text generation from PLMs. We observe that our model can substantially improve the performance of short-text topic modeling. Extensive experiments on multiple real-world datasets under extreme data sparsity scenarios show that our models can generate high-quality topics outperforming state-of-the-art models.
From PARIS to LE-PARIS: Toward Patent Response Automation with Recommender Systems and Collaborative Large Language Models
Feb 01, 2024In patent prosecution, timely and effective responses to Office Actions (OAs) are crucial for acquiring patents, yet past automation and AI research have scarcely addressed this aspect. To address this gap, our study introduces the Patent Office Action Response Intelligence System (PARIS) and its advanced version, the Large Language Model Enhanced PARIS (LE-PARIS). These systems are designed to expedite the efficiency of patent attorneys in collaboratively handling OA responses. The systems' key features include the construction of an OA Topics Database, development of Response Templates, and implementation of Recommender Systems and LLM-based Response Generation. Our validation involves a multi-paradigmatic analysis using the USPTO Office Action database and longitudinal data of attorney interactions with our systems over six years. Through five studies, we examine the constructiveness of OA topics (studies 1 and 2) using topic modeling and the proposed Delphi process, the efficacy of our proposed hybrid recommender system tailored for OA (both LLM-based and non-LLM-based) (study 3), the quality of response generation (study 4), and the practical value of the systems in real-world scenarios via user studies (study 5). Results demonstrate that both PARIS and LE-PARIS significantly meet key metrics and positively impact attorney performance.