 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
A Joint Learning Approach for Semi-supervised Neural Topic Modeling
Apr 07, 2022
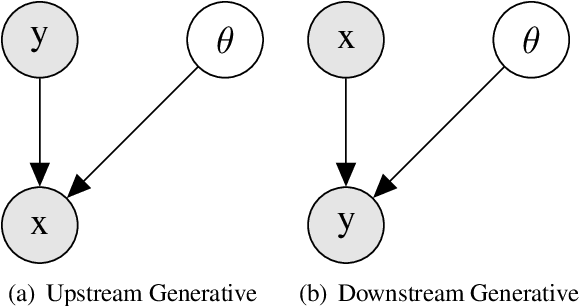

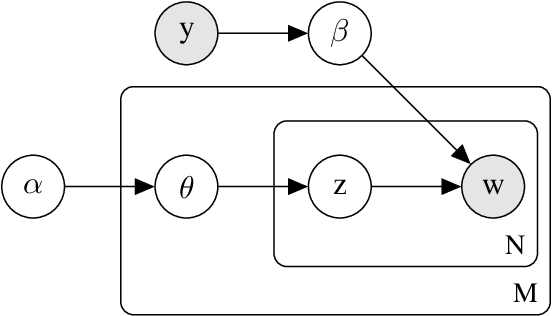

Topic models are some of the most popular ways to represent textual data in an interpret-able manner. Recently, advances in deep generative models, specifically auto-encoding variational Bayes (AEVB), have led to the introduction of unsupervised neural topic models, which leverage deep generative models as opposed to traditional statistics-based topic models. We extend upon these neural topic models by introducing the Label-Indexed Neural Topic Model (LI-NTM), which is, to the extent of our knowledge, the first effective upstream semi-supervised neural topic model. We find that LI-NTM outperforms existing neural topic models in document reconstruction benchmarks, with the most notable results in low labeled data regimes and for data-sets with informative labels; furthermore, our jointly learned classifier outperforms baseline classifiers in ablation studies.
Deep Belief Nets for Topic Modeling
Jan 18, 2015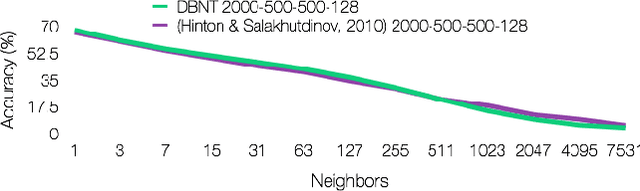
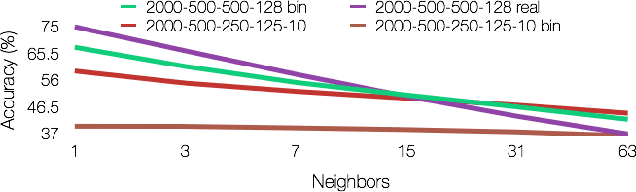
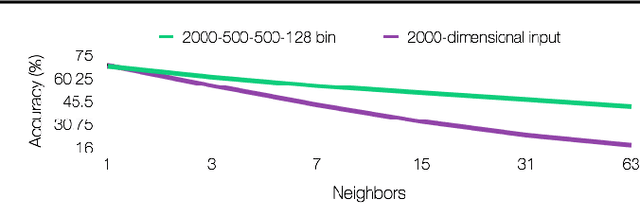
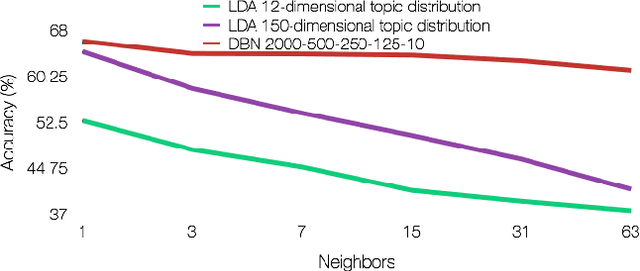
Applying traditional collaborative filtering to digital publishing is challenging because user data is very sparse due to the high volume of documents relative to the number of users. Content based approaches, on the other hand, is attractive because textual content is often very informative. In this paper we describe large-scale content based collaborative filtering for digital publishing. To solve the digital publishing recommender problem we compare two approaches: latent Dirichlet allocation (LDA) and deep belief nets (DBN) that both find low-dimensional latent representations for documents. Efficient retrieval can be carried out in the latent representation. We work both on public benchmarks and digital media content provided by Issuu, an online publishing platform. This article also comes with a newly developed deep belief nets toolbox for topic modeling tailored towards performance evaluation of the DBN model and comparisons to the LDA model.
Exploring COVID-19 Related Stressors Using Topic Modeling
Jan 12, 2022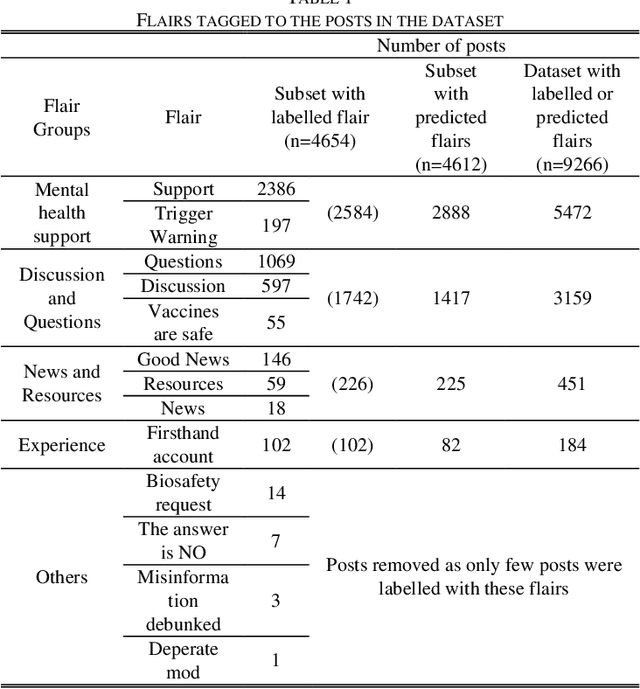
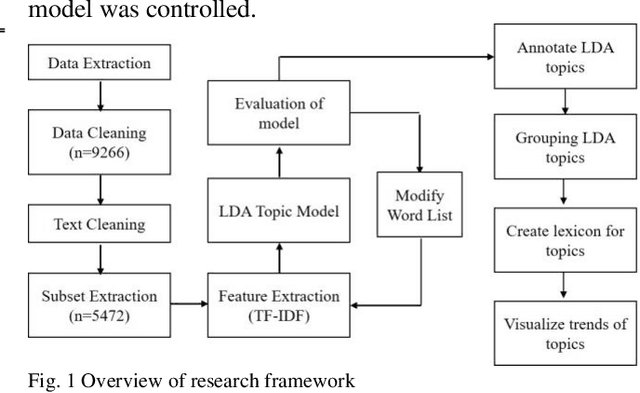


The COVID-19 pandemic has affected lives of people from different countries for almost two years. The changes on lifestyles due to the pandemic may cause psychosocial stressors for individuals, and have a potential to lead to mental health problems. To provide high quality mental health supports, healthcare organization need to identify the COVID-19 specific stressors, and notice the trends of prevalence of those stressors. This study aims to apply natural language processing (NLP) on social media data to identify the psychosocial stressors during COVID-19 pandemic, and to analyze the trend on prevalence of stressors at different stages of the pandemic. We obtained dataset of 9266 Reddit posts from subreddit \rCOVID19_support, from 14th Feb ,2020 to 19th July 2021. We used Latent Dirichlet Allocation (LDA) topic model and lexicon methods to identify the topics that were mentioned on the subreddit. Our result presented a dashboard to visualize the trend of prevalence of topics about covid-19 related stressors being discussed on social media platform. The result could provide insights about the prevalence of pandemic related stressors during different stages of COVID-19. The NLP techniques leveraged in this study could also be applied to analyze event specific stressors in the future.
Combining LSTM and Latent Topic Modeling for Mortality Prediction
Sep 08, 2017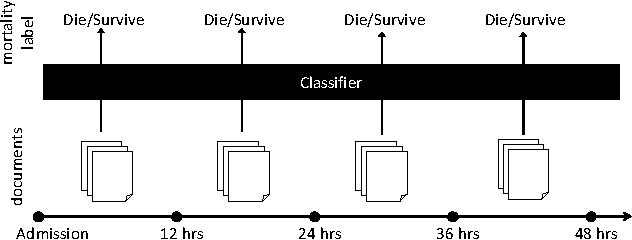

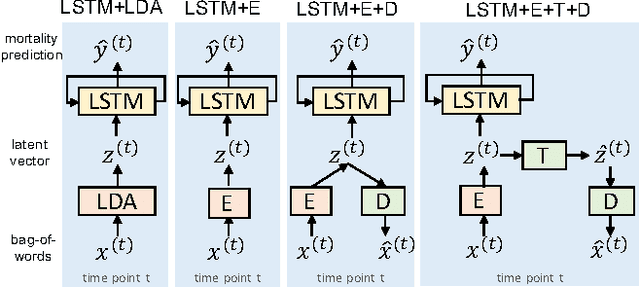

There is a great need for technologies that can predict the mortality of patients in intensive care units with both high accuracy and accountability. We present joint end-to-end neural network architectures that combine long short-term memory (LSTM) and a latent topic model to simultaneously train a classifier for mortality prediction and learn latent topics indicative of mortality from textual clinical notes. For topic interpretability, the topic modeling layer has been carefully designed as a single-layer network with constraints inspired by LDA. Experiments on the MIMIC-III dataset show that our models significantly outperform prior models that are based on LDA topics in mortality prediction. However, we achieve limited success with our method for interpreting topics from the trained models by looking at the neural network weights.
H2-Golden-Retriever: Methodology and Tool for an Evidence-Based Hydrogen Research Grantsmanship
Nov 16, 2022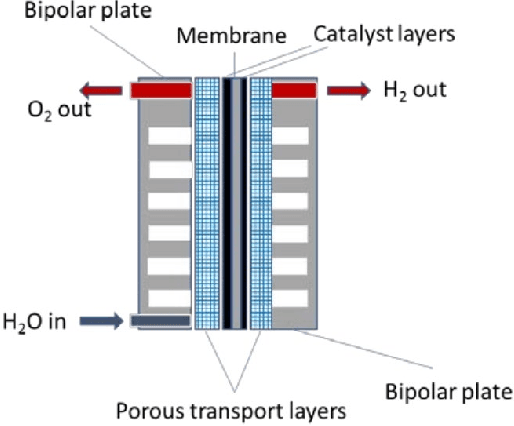



Hydrogen is poised to play a major role in decarbonizing the economy. The need to discover, develop, and understand low-cost, high-performance, durable materials that can help maximize the cost of electrolysis as well as the need for an intelligent tool to make evidence-based Hydrogen research funding decisions relatively easier warranted this study.In this work, we developed H2 Golden Retriever (H2GR) system for Hydrogen knowledge discovery and representation using Natural Language Processing (NLP), Knowledge Graph and Decision Intelligence. This system represents a novel methodology encapsulating state-of-the-art technique for evidence-based research grantmanship. Relevant Hydrogen papers were scraped and indexed from the web and preprocessing was done using noise and stop-words removal, language and spell check, stemming and lemmatization. The NLP tasks included Named Entity Recognition using Stanford and Spacy NER, topic modeling using Latent Dirichlet Allocation and TF-IDF. The Knowledge Graph module was used for the generation of meaningful entities and their relationships, trends and patterns in relevant H2 papers, thanks to an ontology of the hydrogen production domain. The Decision Intelligence component provides stakeholders with a simulation environment for cost and quantity dependencies. PageRank algorithm was used to rank papers of interest. Random searches were made on the proposed H2GR and the results included a list of papers ranked by relevancy score, entities, graphs of relationships between the entities, ontology of H2 production and Causal Decision Diagrams showing component interactivity. Qualitative assessment was done by the experts and H2GR is deemed to function to a satisfactory level.
Semi-Automatic Terminology Ontology Learning Based on Topic Modeling
Aug 05, 2017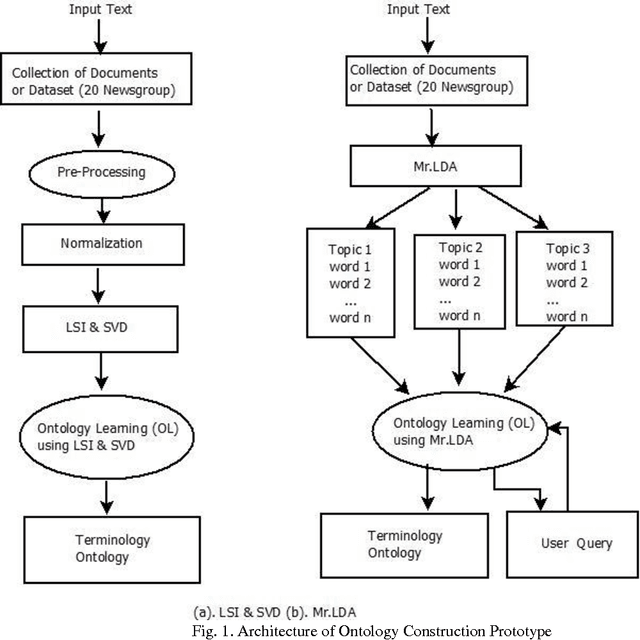


Ontologies provide features like a common vocabulary, reusability, machine-readable content, and also allows for semantic search, facilitate agent interaction and ordering & structuring of knowledge for the Semantic Web (Web 3.0) application. However, the challenge in ontology engineering is automatic learning, i.e., the there is still a lack of fully automatic approach from a text corpus or dataset of various topics to form ontology using machine learning techniques. In this paper, two topic modeling algorithms are explored, namely LSI & SVD and Mr.LDA for learning topic ontology. The objective is to determine the statistical relationship between document and terms to build a topic ontology and ontology graph with minimum human intervention. Experimental analysis on building a topic ontology and semantic retrieving corresponding topic ontology for the user's query demonstrating the effectiveness of the proposed approach.
Residual Belief Propagation for Topic Modeling
Apr 30, 2012
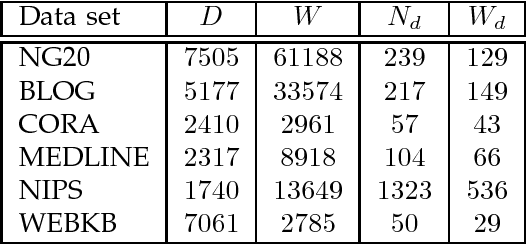
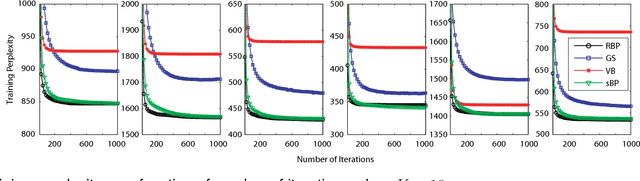
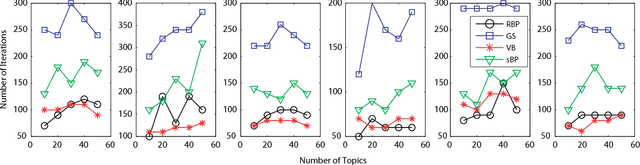
Fast convergence speed is a desired property for training latent Dirichlet allocation (LDA), especially in online and parallel topic modeling for massive data sets. This paper presents a novel residual belief propagation (RBP) algorithm to accelerate the convergence speed for training LDA. The proposed RBP uses an informed scheduling scheme for asynchronous message passing, which passes fast-convergent messages with a higher priority to influence those slow-convergent messages at each learning iteration. Extensive empirical studies confirm that RBP significantly reduces the training time until convergence while achieves a much lower predictive perplexity than other state-of-the-art training algorithms for LDA, including variational Bayes (VB), collapsed Gibbs sampling (GS), loopy belief propagation (BP), and residual VB (RVB).
* 6 pages, 8 figures
Unsupervised Learning under Latent Label Shift
Jul 26, 2022
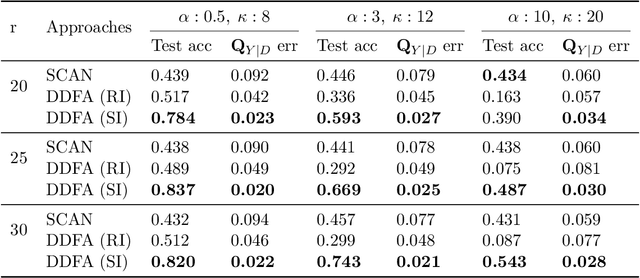

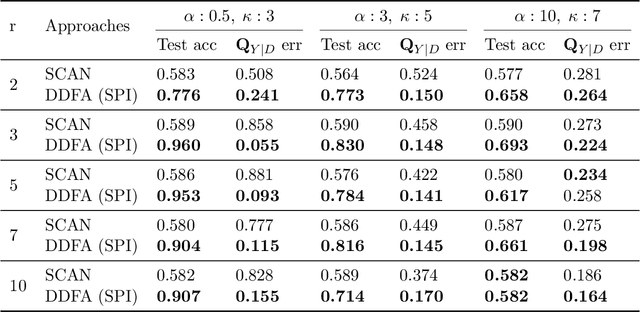
What sorts of structure might enable a learner to discover classes from unlabeled data? Traditional approaches rely on feature-space similarity and heroic assumptions on the data. In this paper, we introduce unsupervised learning under Latent Label Shift (LLS), where we have access to unlabeled data from multiple domains such that the label marginals $p_d(y)$ can shift across domains but the class conditionals $p(\mathbf{x}|y)$ do not. This work instantiates a new principle for identifying classes: elements that shift together group together. For finite input spaces, we establish an isomorphism between LLS and topic modeling: inputs correspond to words, domains to documents, and labels to topics. Addressing continuous data, we prove that when each label's support contains a separable region, analogous to an anchor word, oracle access to $p(d|\mathbf{x})$ suffices to identify $p_d(y)$ and $p_d(y|\mathbf{x})$ up to permutation. Thus motivated, we introduce a practical algorithm that leverages domain-discriminative models as follows: (i) push examples through domain discriminator $p(d|\mathbf{x})$; (ii) discretize the data by clustering examples in $p(d|\mathbf{x})$ space; (iii) perform non-negative matrix factorization on the discrete data; (iv) combine the recovered $p(y|d)$ with the discriminator outputs $p(d|\mathbf{x})$ to compute $p_d(y|x) \; \forall d$. With semi-synthetic experiments, we show that our algorithm can leverage domain information to improve state of the art unsupervised classification methods. We reveal a failure mode of standard unsupervised classification methods when feature-space similarity does not indicate true groupings, and show empirically that our method better handles this case. Our results establish a deep connection between distribution shift and topic modeling, opening promising lines for future work.
Bayesian Nonparametrics in Topic Modeling: A Brief Tutorial
Jan 16, 2015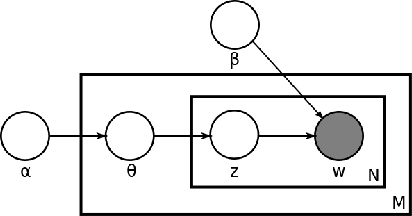
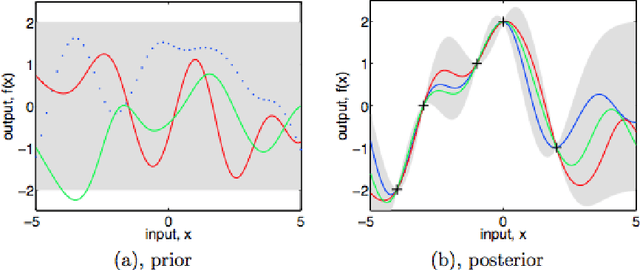
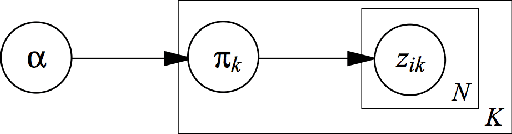
Using nonparametric methods has been increasingly explored in Bayesian hierarchical modeling as a way to increase model flexibility. Although the field shows a lot of promise, inference in many models, including Hierachical Dirichlet Processes (HDP), remain prohibitively slow. One promising path forward is to exploit the submodularity inherent in Indian Buffet Process (IBP) to derive near-optimal solutions in polynomial time. In this work, I will present a brief tutorial on Bayesian nonparametric methods, especially as they are applied to topic modeling. I will show a comparison between different non-parametric models and the current state-of-the-art parametric model, Latent Dirichlet Allocation (LDA).
Exploratory Analysis of Covid-19 Tweets using Topic Modeling, UMAP, and DiGraphs
May 06, 2020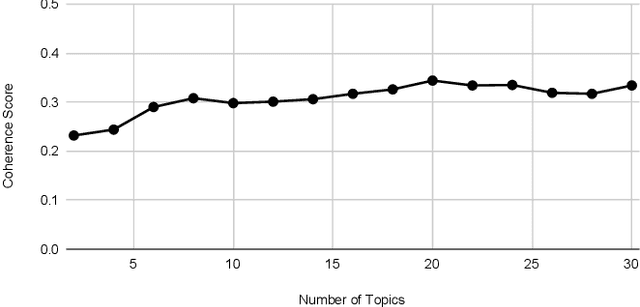
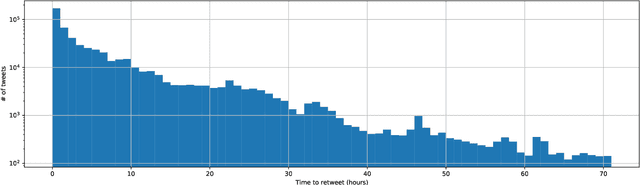
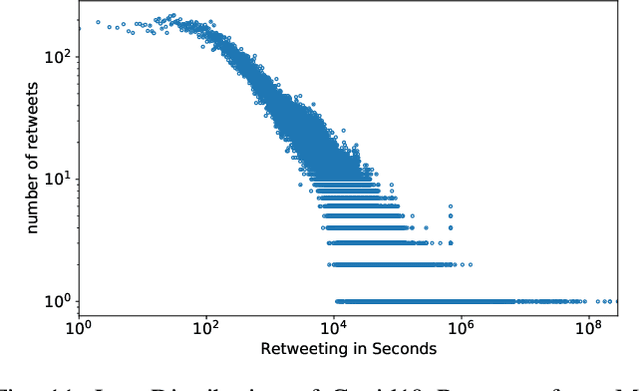
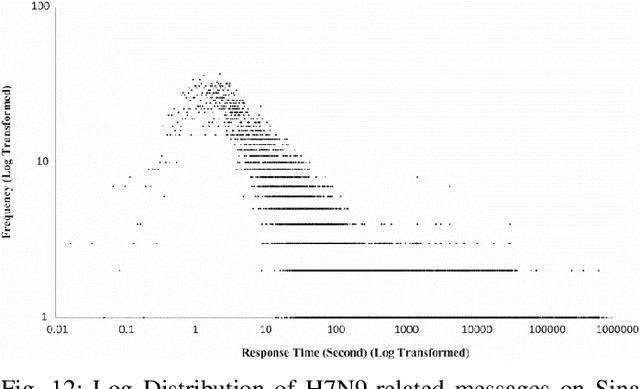
This paper illustrates five different techniques to assess the distinctiveness of topics, key terms and features, speed of information dissemination, and network behaviors for Covid19 tweets. First, we use pattern matching and second, topic modeling through Latent Dirichlet Allocation (LDA) to generate twenty different topics that discuss case spread, healthcare workers, and personal protective equipment (PPE). One topic specific to U.S. cases would start to uptick immediately after live White House Coronavirus Task Force briefings, implying that many Twitter users are paying attention to government announcements. We contribute machine learning methods not previously reported in the Covid19 Twitter literature. This includes our third method, Uniform Manifold Approximation and Projection (UMAP), that identifies unique clustering-behavior of distinct topics to improve our understanding of important themes in the corpus and help assess the quality of generated topics. Fourth, we calculated retweeting times to understand how fast information about Covid19 propagates on Twitter. Our analysis indicates that the median retweeting time of Covid19 for a sample corpus in March 2020 was 2.87 hours, approximately 50 minutes faster than repostings from Chinese social media about H7N9 in March 2013. Lastly, we sought to understand retweet cascades, by visualizing the connections of users over time from fast to slow retweeting. As the time to retweet increases, the density of connections also increase where in our sample, we found distinct users dominating the attention of Covid19 retweeters. One of the simplest highlights of this analysis is that early-stage descriptive methods like regular expressions can successfully identify high-level themes which were consistently verified as important through every subsequent analysis.