 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
The Ordered Matrix Dirichlet for Modeling Ordinal Dynamics
Dec 08, 2022
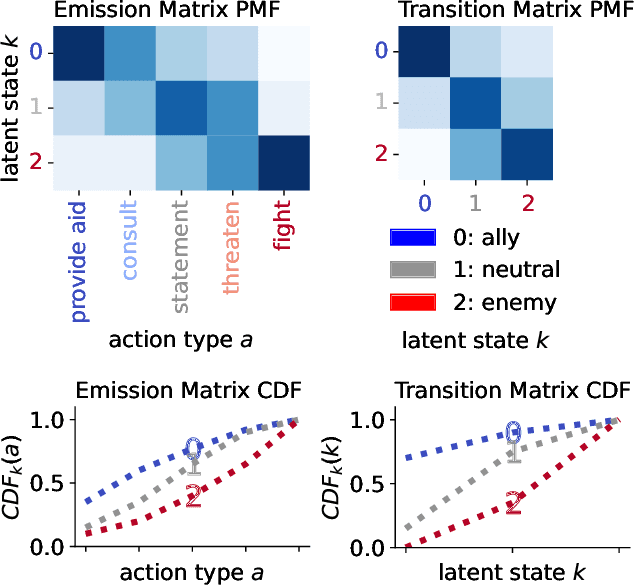
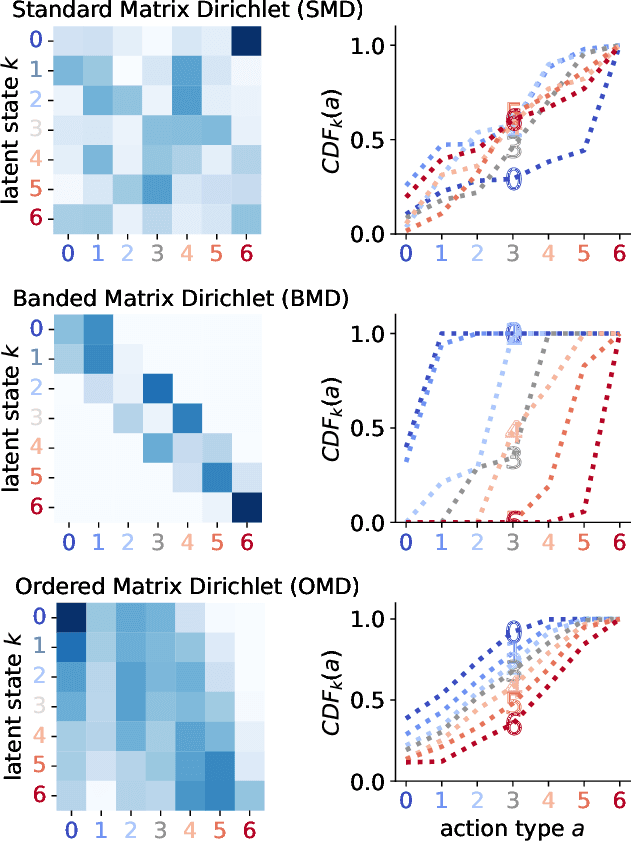

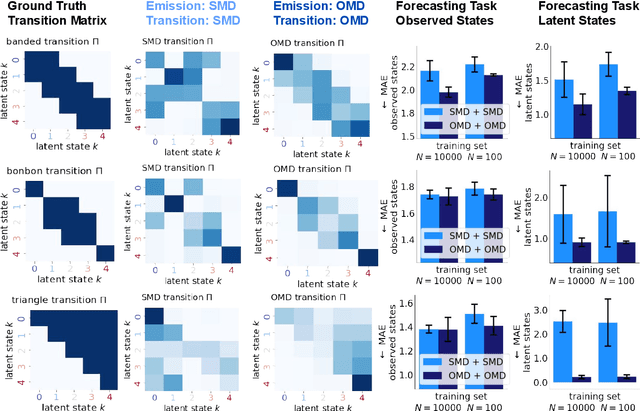
Many dynamical systems exhibit latent states with intrinsic orderings such as "ally", "neutral" and "enemy" relationships in international relations. Such latent states are evidenced through entities' cooperative versus conflictual interactions which are similarly ordered. Models of such systems often involve state-to-action emission and state-to-state transition matrices. It is common practice to assume that the rows of these stochastic matrices are independently sampled from a Dirichlet distribution. However, this assumption discards ordinal information and treats states and actions falsely as order-invariant categoricals, which hinders interpretation and evaluation. To address this problem, we propose the Ordered Matrix Dirichlet (OMD): rows are sampled conditionally dependent such that probability mass is shifted to the right of the matrix as we move down rows. This results in a well-ordered mapping between latent states and observed action types. We evaluate the OMD in two settings: a Hidden Markov Model and a novel Bayesian Dynamic Poisson Tucker Model tailored to political event data. Models built on the OMD recover interpretable latent states and show superior forecasting performance in few-shot settings. We detail the wide applicability of the OMD to other domains where models with Dirichlet-sampled matrices are popular (e.g. topic modeling) and publish user-friendly code.
Combining Topic Modeling with Grounded Theory: Case Studies of Project Collaboration
Jun 28, 2022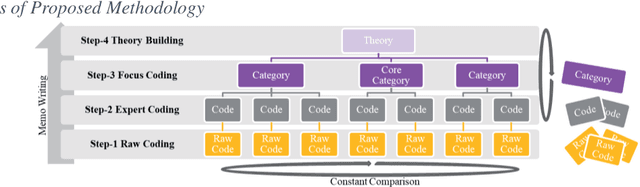
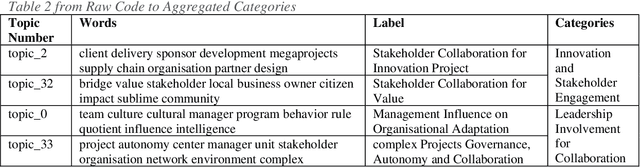
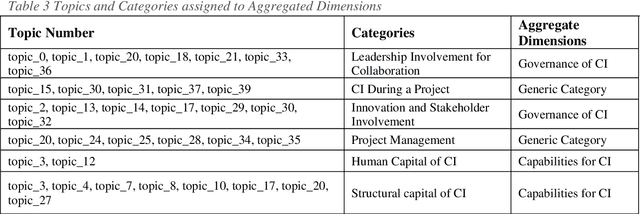
This paper proposes an Artificial Intelligence (AI) Grounded Theory for management studies. We argue that this novel and rigorous approach that embeds topic modelling will lead to the latent knowledge to be found. We illustrate this abductive method using 51 case studies of collaborative innovation published by Project Management Institute (PMI). Initial results are presented and discussed that include 40 topics, 6 categories, 4 of which are core categories, and two new theories of project collaboration.
Political and Economic Patterns in COVID-19 News: From Lockdown to Vaccination
Dec 15, 2022
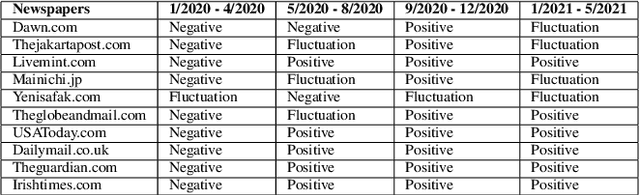
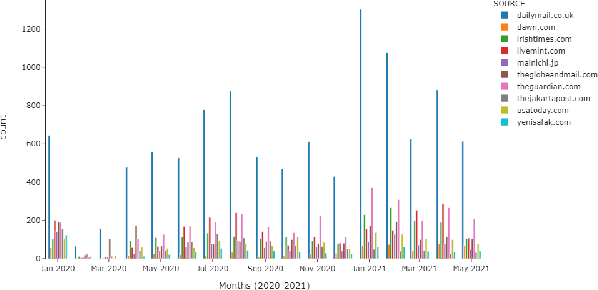
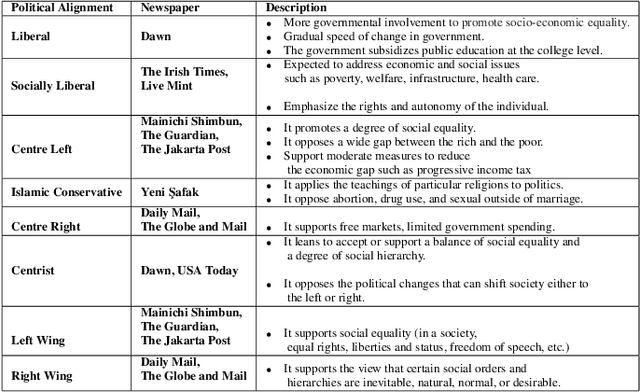
The purpose of this study is to analyse COVID-19 related news published across different geographical places, in order to gain insights in reporting differences. The COVID-19 pandemic had a major outbreak in January 2020 and was followed by different preventive measures, lockdown, and finally by the process of vaccination. To date, more comprehensive analysis of news related to COVID-19 pandemic are missing, especially those which explain what aspects of this pandemic are being reported by newspapers inserted in different economies and belonging to different political alignments. Since LDA is often less coherent when there are news articles published across the world about an event and you look answers for specific queries. It is because of having semantically different content. To address this challenge, we performed pooling of news articles based on information retrieval using TF-IDF score in a data processing step and topic modeling using LDA with combination of 1 to 6 ngrams. We used VADER sentiment analyzer to analyze the differences in sentiments in news articles reported across different geographical places. The novelty of this study is to look at how COVID-19 pandemic was reported by the media, providing a comparison among countries in different political and economic contexts. Our findings suggest that the news reporting by newspapers with different political alignment support the reported content. Also, economic issues reported by newspapers depend on economy of the place where a newspaper resides.
Analysis of Morphology in Topic Modeling
Aug 13, 2016

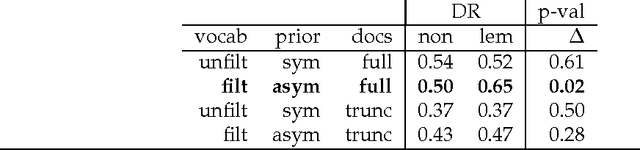
Topic models make strong assumptions about their data. In particular, different words are implicitly assumed to have different meanings: topic models are often used as human-interpretable dimensionality reductions and a proliferation of words with identical meanings would undermine the utility of the top-$m$ word list representation of a topic. Though a number of authors have added preprocessing steps such as lemmatization to better accommodate these assumptions, the effects of such data massaging have not been publicly studied. We make first steps toward elucidating the role of morphology in topic modeling by testing the effect of lemmatization on the interpretability of a latent Dirichlet allocation (LDA) model. Using a word intrusion evaluation, we quantitatively demonstrate that lemmatization provides a significant benefit to the interpretability of a model learned on Wikipedia articles in a morphologically rich language.
Conic Scan-and-Cover algorithms for nonparametric topic modeling
Oct 09, 2017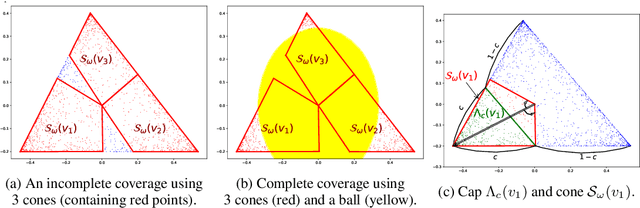
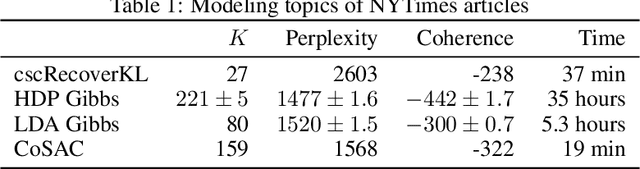
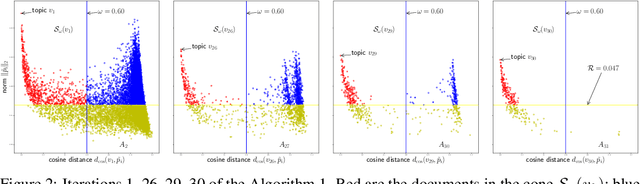
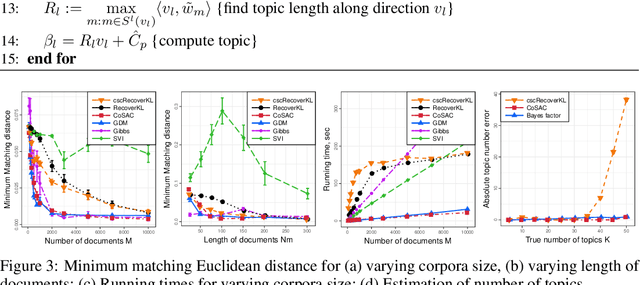
We propose new algorithms for topic modeling when the number of topics is unknown. Our approach relies on an analysis of the concentration of mass and angular geometry of the topic simplex, a convex polytope constructed by taking the convex hull of vertices representing the latent topics. Our algorithms are shown in practice to have accuracy comparable to a Gibbs sampler in terms of topic estimation, which requires the number of topics be given. Moreover, they are one of the fastest among several state of the art parametric techniques. Statistical consistency of our estimator is established under some conditions.
Combining Temporal Information and Topic Modeling for Cross-Document Event Ordering
Jun 10, 2015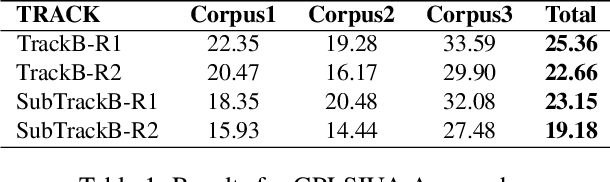
Building unified timelines from a collection of written news articles requires cross-document event coreference resolution and temporal relation extraction. In this paper we present an approach event coreference resolution according to: a) similar temporal information, and b) similar semantic arguments. Temporal information is detected using an automatic temporal information system (TIPSem), while semantic information is represented by means of LDA Topic Modeling. The evaluation of our approach shows that it obtains the highest Micro-average F-score results in the SemEval2015 Task 4: TimeLine: Cross-Document Event Ordering (25.36\% for TrackB, 23.15\% for SubtrackB), with an improvement of up to 6\% in comparison to the other systems. However, our experiment also showed some draw-backs in the Topic Modeling approach that degrades performance of the system.
* 5 pages
Climate Policy Tracker: Pipeline for automated analysis of public climate policies
Nov 10, 2022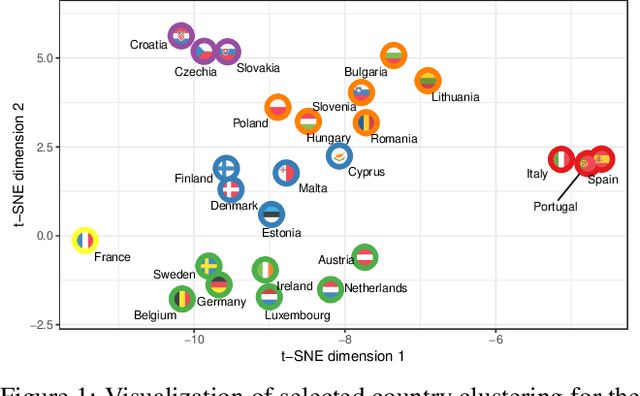

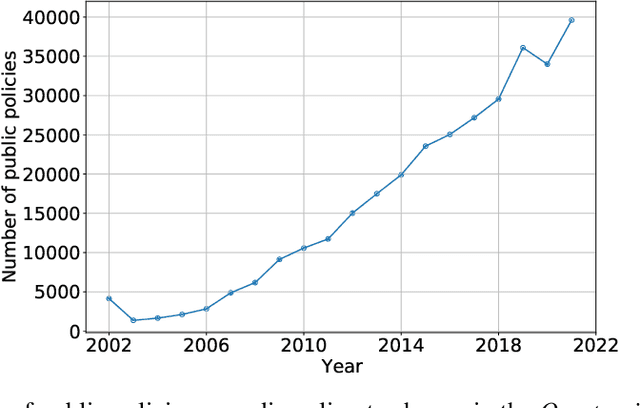
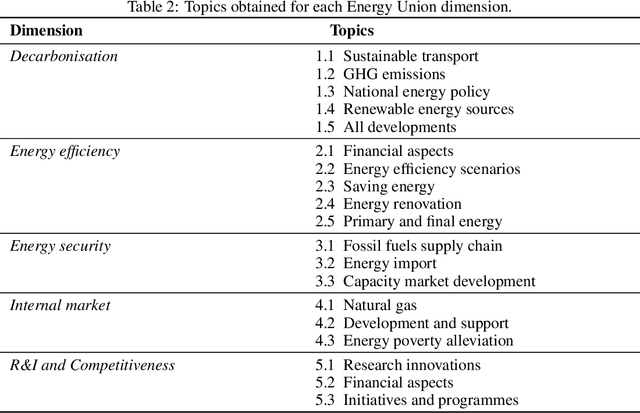
The number of standardized policy documents regarding climate policy and their publication frequency is significantly increasing. The documents are long and tedious for manual analysis, especially for policy experts, lawmakers, and citizens who lack access or domain expertise to utilize data analytics tools. Potential consequences of such a situation include reduced citizen governance and involvement in climate policies and an overall surge in analytics costs, rendering less accessibility for the public. In this work, we use a Latent Dirichlet Allocation-based pipeline for the automatic summarization and analysis of 10-years of national energy and climate plans (NECPs) for the period from 2021 to 2030, established by 27 Member States of the European Union. We focus on analyzing policy framing, the language used to describe specific issues, to detect essential nuances in the way governments frame their climate policies and achieve climate goals. The methods leverage topic modeling and clustering for the comparative analysis of policy documents across different countries. It allows for easier integration in potential user-friendly applications for the development of theories and processes of climate policy. This would further lead to better citizen governance and engagement over climate policies and public policy research.
Familia: A Configurable Topic Modeling Framework for Industrial Text Engineering
Aug 14, 2018
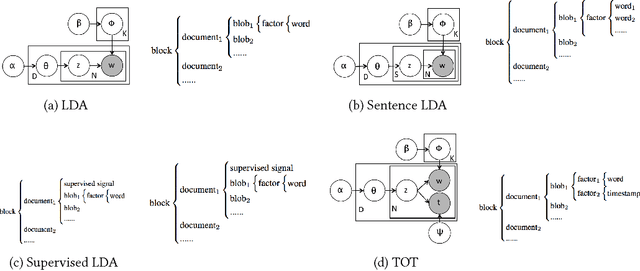
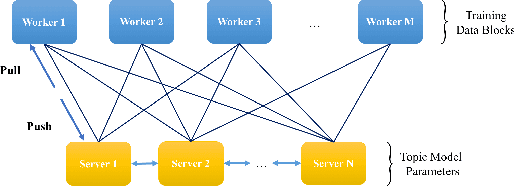
In the last decade, a variety of topic models have been proposed for text engineering. However, except Probabilistic Latent Semantic Analysis (PLSA) and Latent Dirichlet Allocation (LDA), most of existing topic models are seldom applied or considered in industrial scenarios. This phenomenon is caused by the fact that there are very few convenient tools to support these topic models so far. Intimidated by the demanding expertise and labor of designing and implementing parameter inference algorithms, software engineers are prone to simply resort to PLSA/LDA, without considering whether it is proper for their problem at hand or not. In this paper, we propose a configurable topic modeling framework named Familia, in order to bridge the huge gap between academic research fruits and current industrial practice. Familia supports an important line of topic models that are widely applicable in text engineering scenarios. In order to relieve burdens of software engineers without knowledge of Bayesian networks, Familia is able to conduct automatic parameter inference for a variety of topic models. Simply through changing the data organization of Familia, software engineers are able to easily explore a broad spectrum of existing topic models or even design their own topic models, and find the one that best suits the problem at hand. With its superior extendability, Familia has a novel sampling mechanism that strikes balance between effectiveness and efficiency of parameter inference. Furthermore, Familia is essentially a big topic modeling framework that supports parallel parameter inference and distributed parameter storage. The utilities and necessity of Familia are demonstrated in real-life industrial applications. Familia would significantly enlarge software engineers' arsenal of topic models and pave the way for utilizing highly customized topic models in real-life problems.
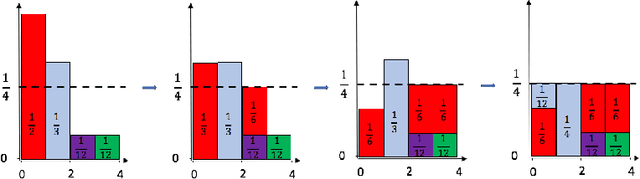
Topic Grouper: An Agglomerative Clustering Approach to Topic Modeling
Apr 13, 2019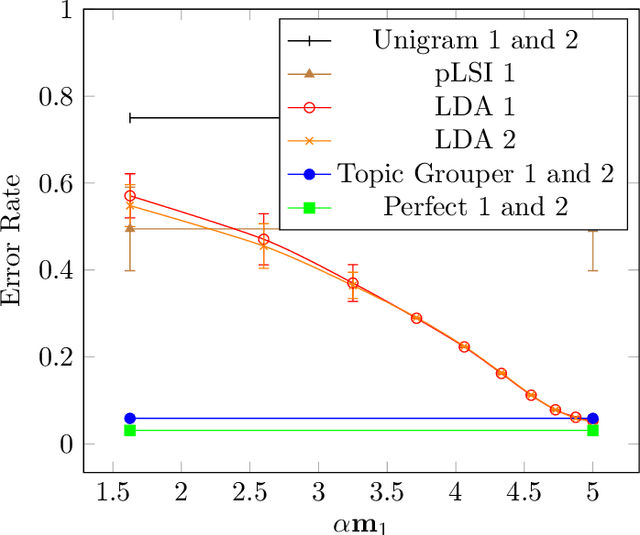
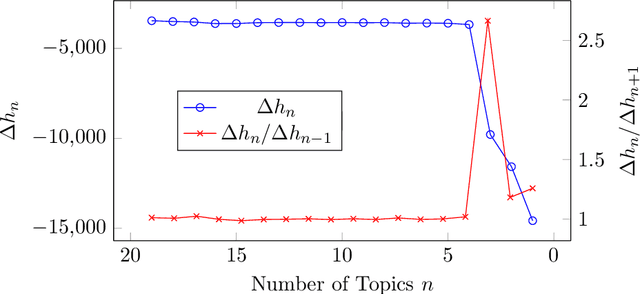
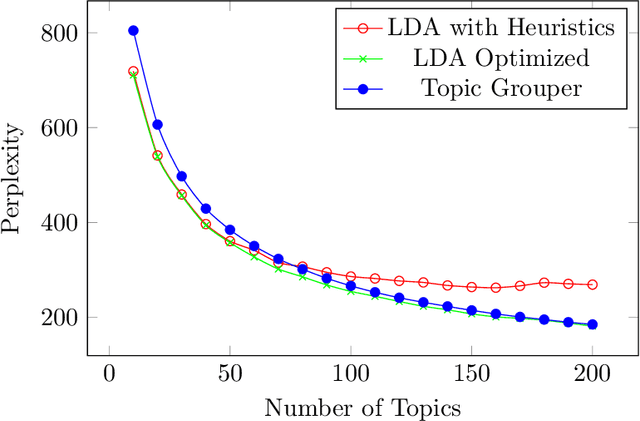
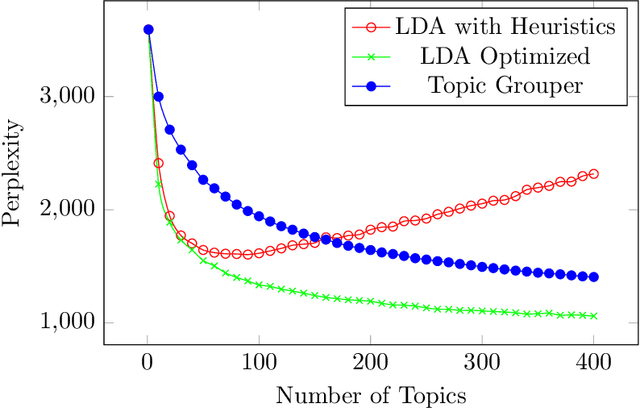
We introduce Topic Grouper as a complementary approach in the field of probabilistic topic modeling. Topic Grouper creates a disjunctive partitioning of the training vocabulary in a stepwise manner such that resulting partitions represent topics. It is governed by a simple generative model, where the likelihood to generate the training documents via topics is optimized. The algorithm starts with one-word topics and joins two topics at every step. It therefore generates a solution for every desired number of topics ranging between the size of the training vocabulary and one. The process represents an agglomerative clustering that corresponds to a binary tree of topics. A resulting tree may act as a containment hierarchy, typically with more general topics towards the root of tree and more specific topics towards the leaves. Topic Grouper is not governed by a background distribution such as the Dirichlet and avoids hyper parameter optimizations. We show that Topic Grouper has reasonable predictive power and also a reasonable theoretical and practical complexity. Topic Grouper can deal well with stop words and function words and tends to push them into their own topics. Also, it can handle topic distributions, where some topics are more frequent than others. We present typical examples of computed topics from evaluation datasets, where topics appear conclusive and coherent. In this context, the fact that each word belongs to exactly one topic is not a major limitation; in some scenarios this can even be a genuine advantage, e.g.~a related shopping basket analysis may aid in optimizing groupings of articles in sales catalogs.
Knowledge-Aware Bayesian Deep Topic Model
Sep 20, 2022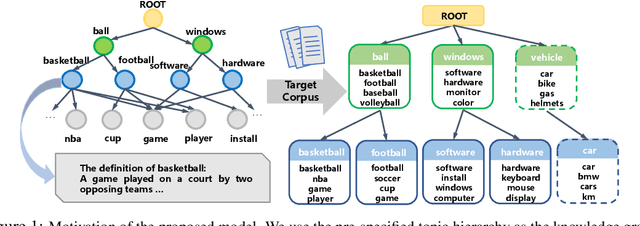
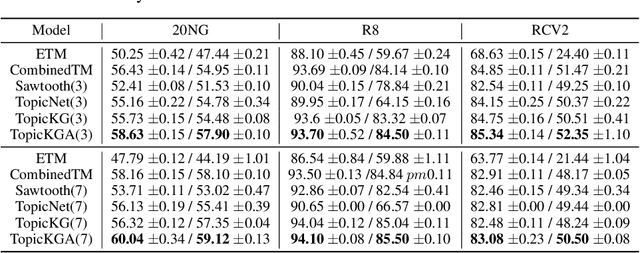
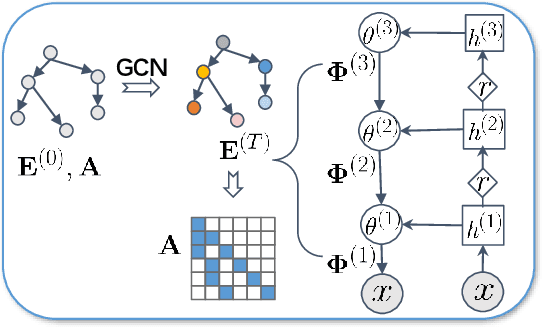

We propose a Bayesian generative model for incorporating prior domain knowledge into hierarchical topic modeling. Although embedded topic models (ETMs) and its variants have gained promising performance in text analysis, they mainly focus on mining word co-occurrence patterns, ignoring potentially easy-to-obtain prior topic hierarchies that could help enhance topic coherence. While several knowledge-based topic models have recently been proposed, they are either only applicable to shallow hierarchies or sensitive to the quality of the provided prior knowledge. To this end, we develop a novel deep ETM that jointly models the documents and the given prior knowledge by embedding the words and topics into the same space. Guided by the provided knowledge, the proposed model tends to discover topic hierarchies that are organized into interpretable taxonomies. Besides, with a technique for adapting a given graph, our extended version allows the provided prior topic structure to be finetuned to match the target corpus. Extensive experiments show that our proposed model efficiently integrates the prior knowledge and improves both hierarchical topic discovery and document representation.