 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
Memory-Efficient Topic Modeling
Jun 08, 2012
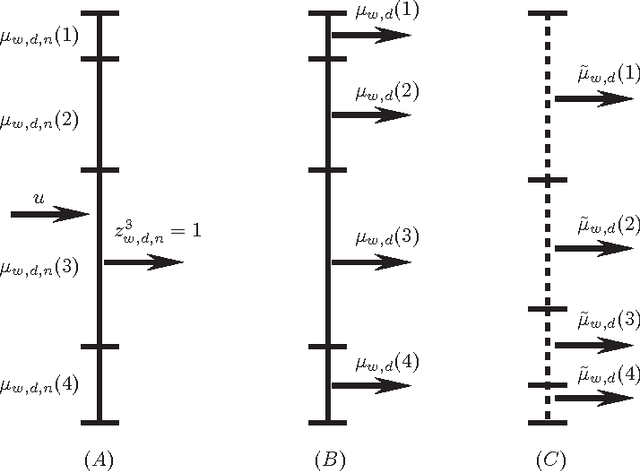

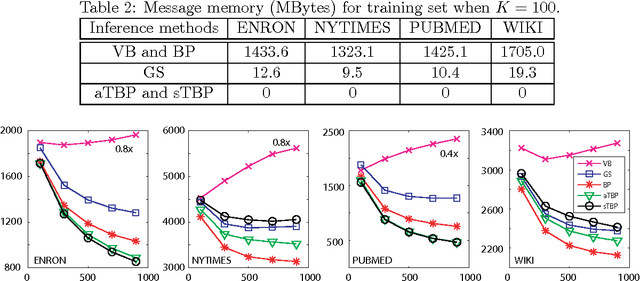
As one of the simplest probabilistic topic modeling techniques, latent Dirichlet allocation (LDA) has found many important applications in text mining, computer vision and computational biology. Recent training algorithms for LDA can be interpreted within a unified message passing framework. However, message passing requires storing previous messages with a large amount of memory space, increasing linearly with the number of documents or the number of topics. Therefore, the high memory usage is often a major problem for topic modeling of massive corpora containing a large number of topics. To reduce the space complexity, we propose a novel algorithm without storing previous messages for training LDA: tiny belief propagation (TBP). The basic idea of TBP relates the message passing algorithms with the non-negative matrix factorization (NMF) algorithms, which absorb the message updating into the message passing process, and thus avoid storing previous messages. Experimental results on four large data sets confirm that TBP performs comparably well or even better than current state-of-the-art training algorithms for LDA but with a much less memory consumption. TBP can do topic modeling when massive corpora cannot fit in the computer memory, for example, extracting thematic topics from 7 GB PUBMED corpora on a common desktop computer with 2GB memory.
Coherence-Aware Neural Topic Modeling
Sep 07, 2018
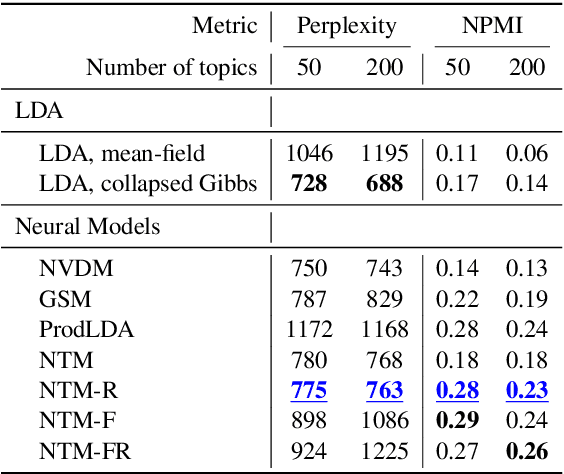
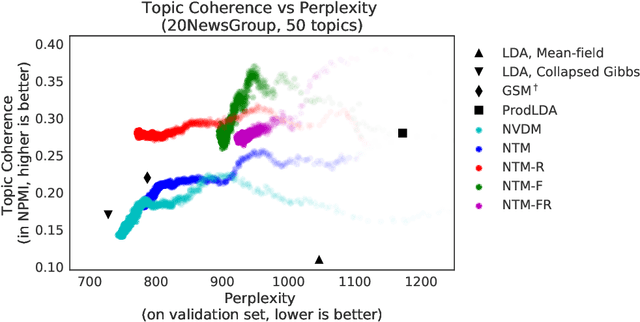
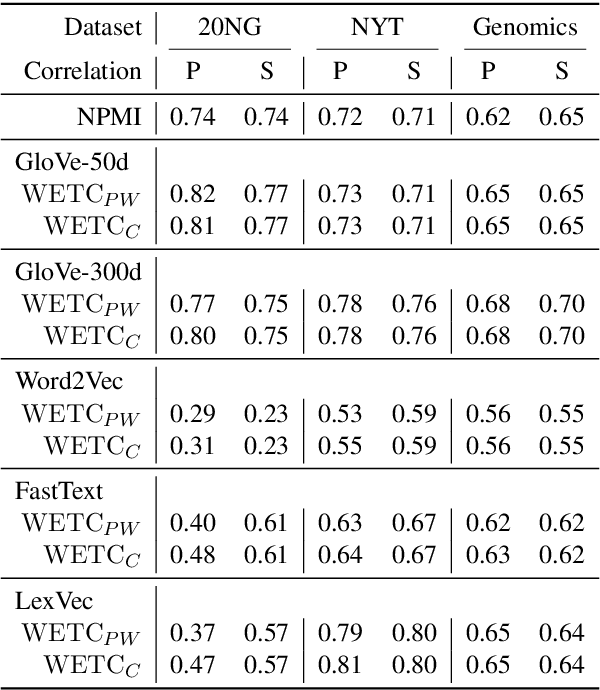
Topic models are evaluated based on their ability to describe documents well (i.e. low perplexity) and to produce topics that carry coherent semantic meaning. In topic modeling so far, perplexity is a direct optimization target. However, topic coherence, owing to its challenging computation, is not optimized for and is only evaluated after training. In this work, under a neural variational inference framework, we propose methods to incorporate a topic coherence objective into the training process. We demonstrate that such a coherence-aware topic model exhibits a similar level of perplexity as baseline models but achieves substantially higher topic coherence.
Context Reinforced Neural Topic Modeling over Short Texts
Aug 11, 2020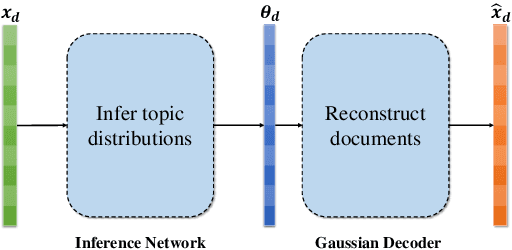

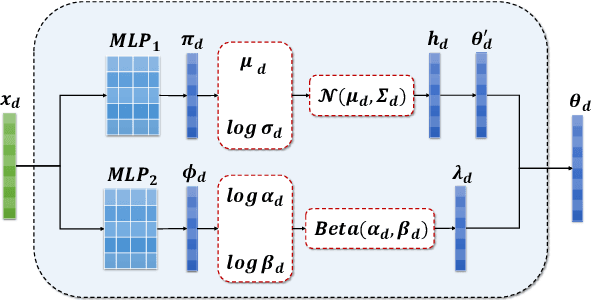
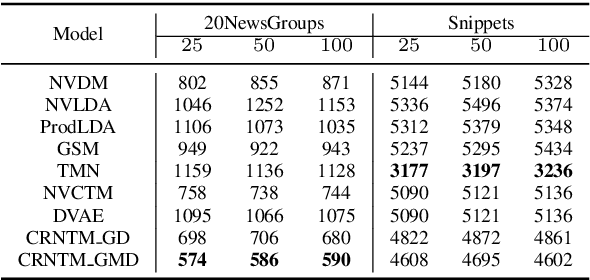
As one of the prevalent topic mining tools, neural topic modeling has attracted a lot of interests for the advantages of high efficiency in training and strong generalisation abilities. However, due to the lack of context in each short text, the existing neural topic models may suffer from feature sparsity on such documents. To alleviate this issue, we propose a Context Reinforced Neural Topic Model (CRNTM), whose characteristics can be summarized as follows. Firstly, by assuming that each short text covers only a few salient topics, CRNTM infers the topic for each word in a narrow range. Secondly, our model exploits pre-trained word embeddings by treating topics as multivariate Gaussian distributions or Gaussian mixture distributions in the embedding space. Extensive experiments on two benchmark datasets validate the effectiveness of the proposed model on both topic discovery and text classification.
Fast Online EM for Big Topic Modeling
Dec 07, 2015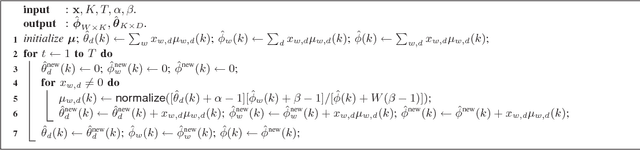
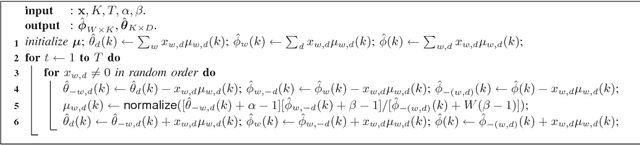

The expectation-maximization (EM) algorithm can compute the maximum-likelihood (ML) or maximum a posterior (MAP) point estimate of the mixture models or latent variable models such as latent Dirichlet allocation (LDA), which has been one of the most popular probabilistic topic modeling methods in the past decade. However, batch EM has high time and space complexities to learn big LDA models from big data streams. In this paper, we present a fast online EM (FOEM) algorithm that infers the topic distribution from the previously unseen documents incrementally with constant memory requirements. Within the stochastic approximation framework, we show that FOEM can converge to the local stationary point of the LDA's likelihood function. By dynamic scheduling for the fast speed and parameter streaming for the low memory usage, FOEM is more efficient for some lifelong topic modeling tasks than the state-of-the-art online LDA algorithms to handle both big data and big models (aka, big topic modeling) on just a PC.
Very Large Language Model as a Unified Methodology of Text Mining
Dec 20, 2022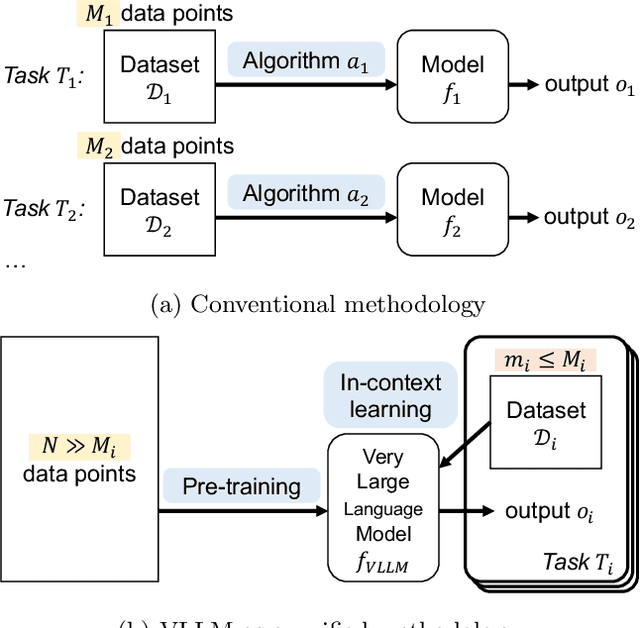
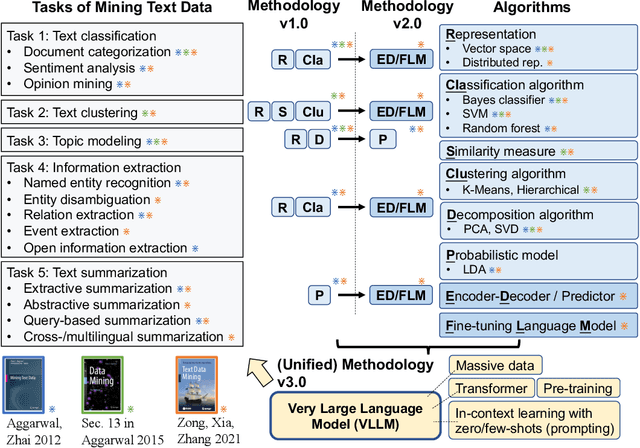
Text data mining is the process of deriving essential information from language text. Typical text mining tasks include text categorization, text clustering, topic modeling, information extraction, and text summarization. Various data sets are collected and various algorithms are designed for the different types of tasks. In this paper, I present a blue sky idea that very large language model (VLLM) will become an effective unified methodology of text mining. I discuss at least three advantages of this new methodology against conventional methods. Finally I discuss the challenges in the design and development of VLLM techniques for text mining.
BATS: A Spectral Biclustering Approach to Single Document Topic Modeling and Segmentation
Aug 05, 2020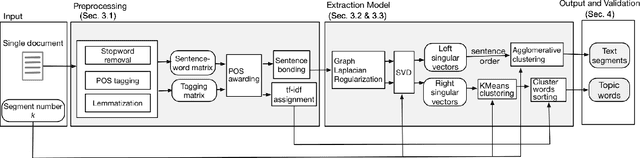

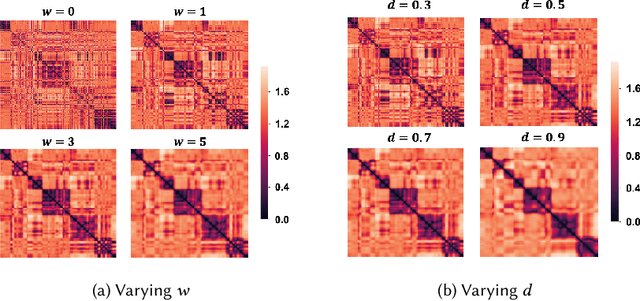
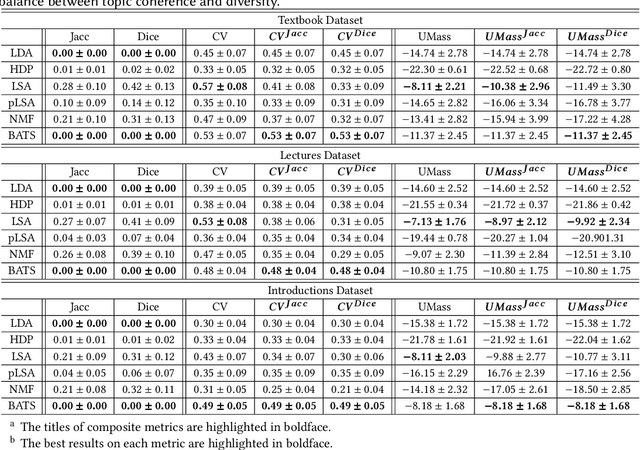
Existing topic modeling and text segmentation methodologies generally require large datasets for training, limiting their capabilities when only small collections of text are available. In this work, we reexamine the inter-related problems of "topic identification" and "text segmentation" for sparse document learning, when there is a single new text of interest. In developing a methodology to handle single documents, we face two major challenges. First is sparse information: with access to only one document, we cannot train traditional topic models or deep learning algorithms. Second is significant noise: a considerable portion of words in any single document will produce only noise and not help discern topics or segments. To tackle these issues, we design an unsupervised, computationally efficient methodology called BATS: Biclustering Approach to Topic modeling and Segmentation. BATS leverages three key ideas to simultaneously identify topics and segment text: (i) a new mechanism that uses word order information to reduce sample complexity, (ii) a statistically sound graph-based biclustering technique that identifies latent structures of words and sentences, and (iii) a collection of effective heuristics that remove noise words and award important words to further improve performance. Experiments on four datasets show that our approach outperforms several state-of-the-art baselines when considering topic coherence, topic diversity, segmentation, and runtime comparison metrics.
Integrating Document Clustering and Topic Modeling
Sep 26, 2013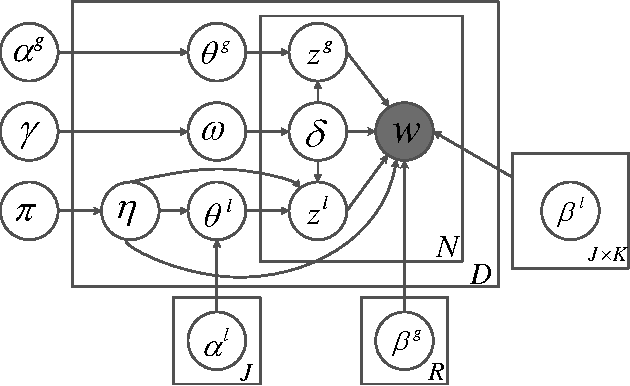
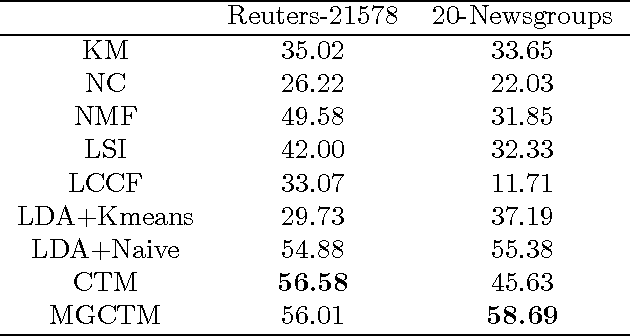
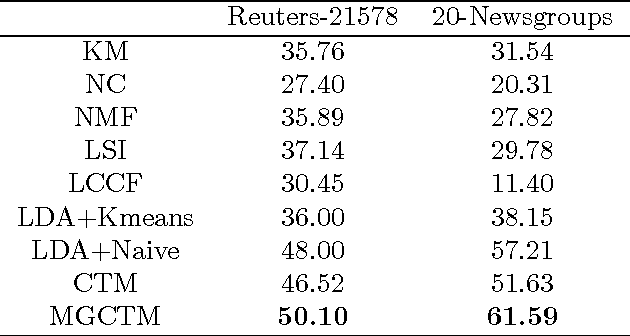

Document clustering and topic modeling are two closely related tasks which can mutually benefit each other. Topic modeling can project documents into a topic space which facilitates effective document clustering. Cluster labels discovered by document clustering can be incorporated into topic models to extract local topics specific to each cluster and global topics shared by all clusters. In this paper, we propose a multi-grain clustering topic model (MGCTM) which integrates document clustering and topic modeling into a unified framework and jointly performs the two tasks to achieve the overall best performance. Our model tightly couples two components: a mixture component used for discovering latent groups in document collection and a topic model component used for mining multi-grain topics including local topics specific to each cluster and global topics shared across clusters.We employ variational inference to approximate the posterior of hidden variables and learn model parameters. Experiments on two datasets demonstrate the effectiveness of our model.
Crime Topic Modeling
Aug 06, 2018
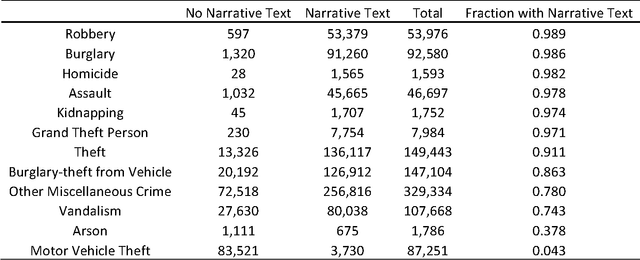
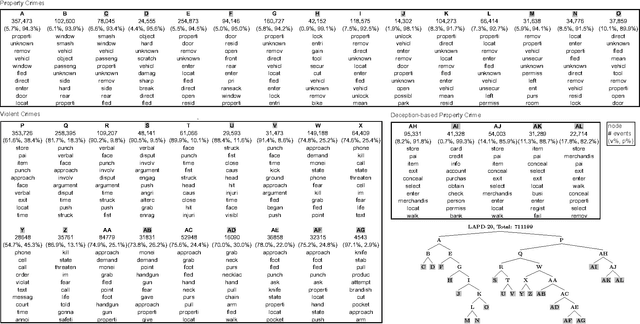
The classification of crime into discrete categories entails a massive loss of information. Crimes emerge out of a complex mix of behaviors and situations, yet most of these details cannot be captured by singular crime type labels. This information loss impacts our ability to not only understand the causes of crime, but also how to develop optimal crime prevention strategies. We apply machine learning methods to short narrative text descriptions accompanying crime records with the goal of discovering ecologically more meaningful latent crime classes. We term these latent classes "crime topics" in reference to text-based topic modeling methods that produce them. We use topic distributions to measure clustering among formally recognized crime types. Crime topics replicate broad distinctions between violent and property crime, but also reveal nuances linked to target characteristics, situational conditions and the tools and methods of attack. Formal crime types are not discrete in topic space. Rather, crime types are distributed across a range of crime topics. Similarly, individual crime topics are distributed across a range of formal crime types. Key ecological groups include identity theft, shoplifting, burglary and theft, car crimes and vandalism, criminal threats and confidence crimes, and violent crimes. Though not a replacement for formal legal crime classifications, crime topics provide a unique window into the heterogeneous causal processes underlying crime.
* 47 pages, 4 tables, 7 figures
Sensemaking About Contraceptive Methods Across Online Platforms
Jan 23, 2023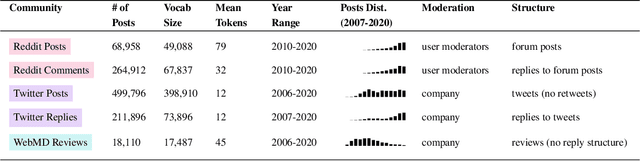
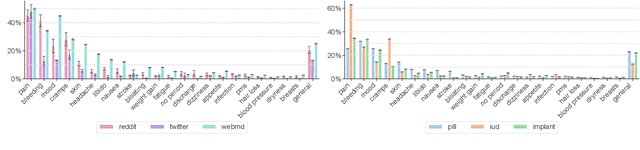
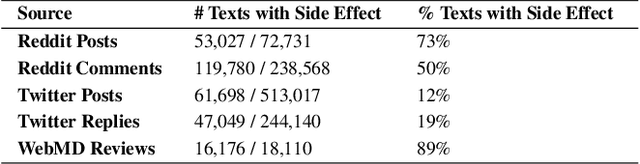
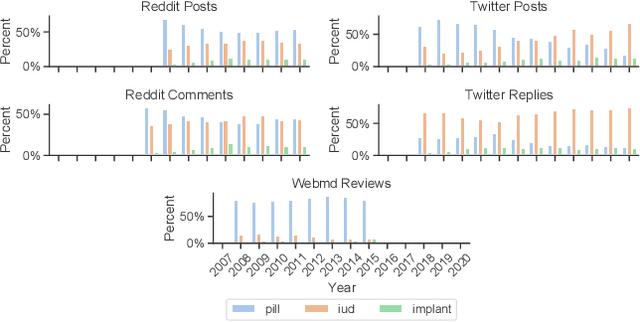
Selecting a birth control method is a complex healthcare decision. While birth control methods provide important benefits, they can also cause unpredictable side effects and be stigmatized, leading many people to seek additional information online, where they can find reviews, advice, hypotheses, and experiences of other birth control users. However, the relationships between their healthcare concerns, sensemaking activities, and online settings are not well understood. We gather texts about birth control shared on Twitter, Reddit, and WebMD -- platforms with different affordances, moderation, and audiences -- to study where and how birth control is discussed online. Using a combination of topic modeling and hand annotation, we identify and characterize the dominant sensemaking practices across these platforms, and we create lexicons to draw comparisons across birth control methods and side effects. We use these to measure variations from survey reports of side effect experiences and method usage. Our findings characterize how online platforms are used to make sense of difficult healthcare choices and highlight unmet needs of birth control users.
Multi-view and Multi-source Transfers in Neural Topic Modeling with Pretrained Topic and Word Embeddings
Sep 17, 2019
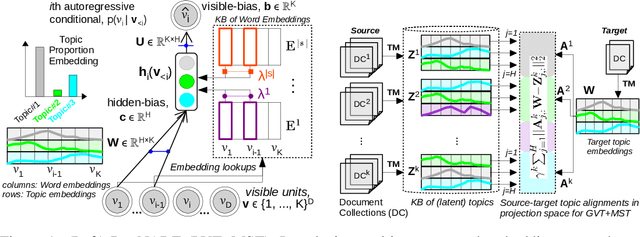
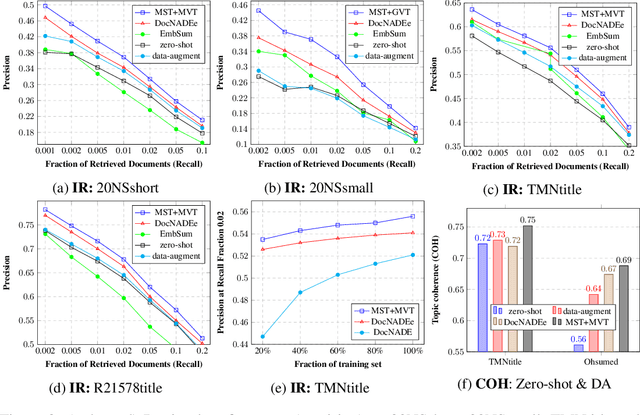
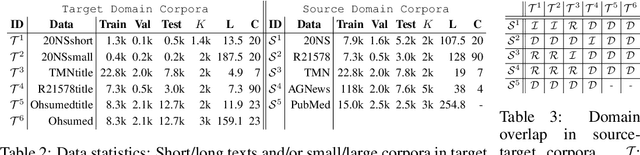
Though word embeddings and topics are complementary representations, several past works have only used pre-trained word embeddings in (neural) topic modeling to address data sparsity problem in short text or small collection of documents. However, no prior work has employed (pre-trained latent) topics in transfer learning paradigm. In this paper, we propose an approach to (1) perform knowledge transfer using latent topics obtained from a large source corpus, and (2) jointly transfer knowledge via the two representations (or views) in neural topic modeling to improve topic quality, better deal with polysemy and data sparsity issues in a target corpus. In doing so, we first accumulate topics and word representations from one or many source corpora to build a pool of topics and word vectors. Then, we identify one or multiple relevant source domain(s) and take advantage of corresponding topics and word features via the respective pools to guide meaningful learning in the sparse target domain. We quantify the quality of topic and document representations via generalization (perplexity), interpretability (topic coherence) and information retrieval (IR) using short-text, long-text, small and large document collections from news and medical domains. We have demonstrated the state-of-the-art results on topic modeling with the proposed framework.