 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
A Scalable Asynchronous Distributed Algorithm for Topic Modeling
Dec 16, 2014
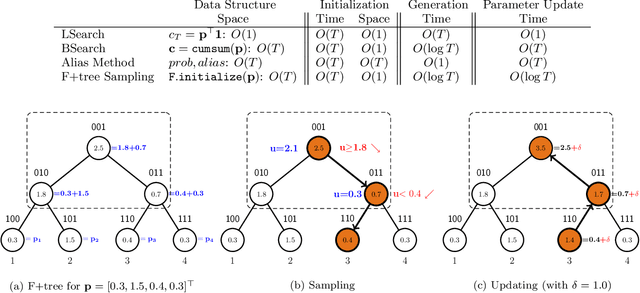


Learning meaningful topic models with massive document collections which contain millions of documents and billions of tokens is challenging because of two reasons: First, one needs to deal with a large number of topics (typically in the order of thousands). Second, one needs a scalable and efficient way of distributing the computation across multiple machines. In this paper we present a novel algorithm F+Nomad LDA which simultaneously tackles both these problems. In order to handle large number of topics we use an appropriately modified Fenwick tree. This data structure allows us to sample from a multinomial distribution over $T$ items in $O(\log T)$ time. Moreover, when topic counts change the data structure can be updated in $O(\log T)$ time. In order to distribute the computation across multiple processor we present a novel asynchronous framework inspired by the Nomad algorithm of \cite{YunYuHsietal13}. We show that F+Nomad LDA significantly outperform state-of-the-art on massive problems which involve millions of documents, billions of words, and thousands of topics.
A non-parametric mixture model for topic modeling over time
Aug 22, 2012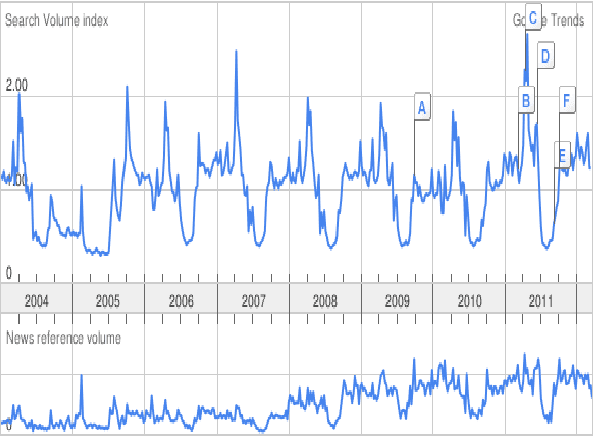
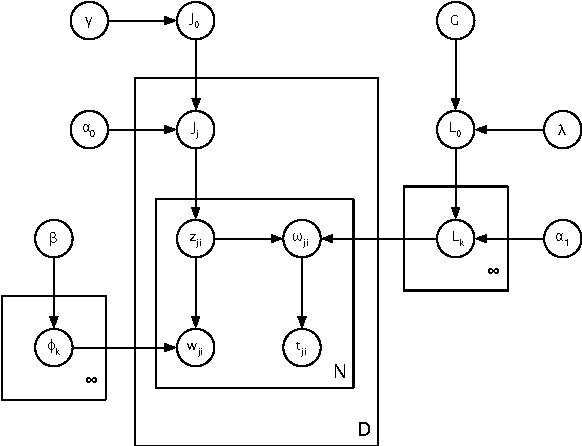
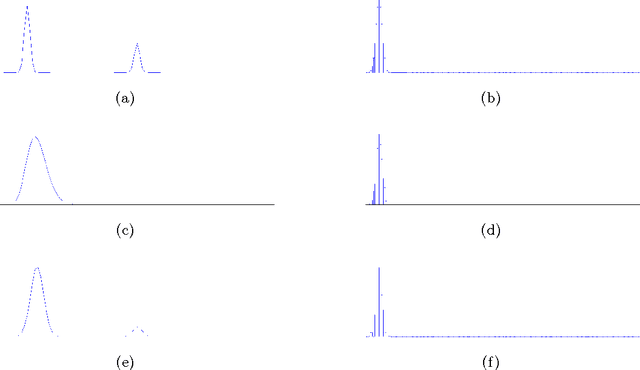

A single, stationary topic model such as latent Dirichlet allocation is inappropriate for modeling corpora that span long time periods, as the popularity of topics is likely to change over time. A number of models that incorporate time have been proposed, but in general they either exhibit limited forms of temporal variation, or require computationally expensive inference methods. In this paper we propose non-parametric Topics over Time (npTOT), a model for time-varying topics that allows an unbounded number of topics and exible distribution over the temporal variations in those topics' popularity. We develop a collapsed Gibbs sampler for the proposed model and compare against existing models on synthetic and real document sets.
Emerging App Issue Identification via Online Joint Sentiment-Topic Tracing
Aug 23, 2020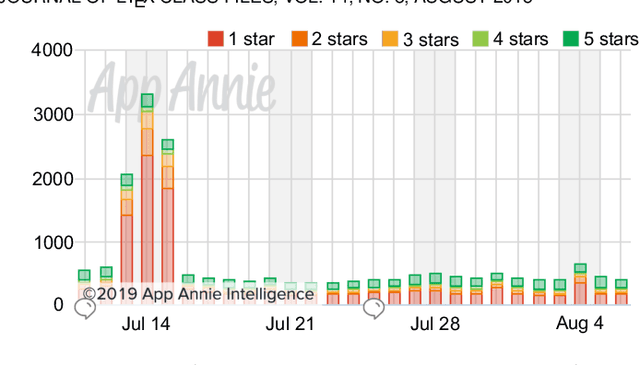
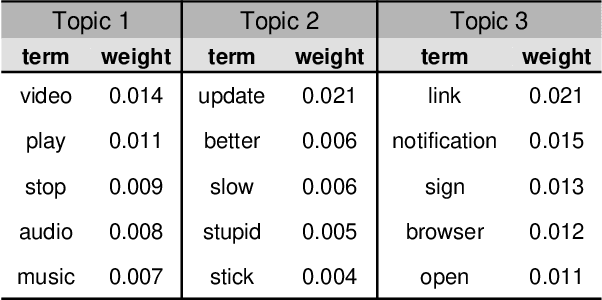
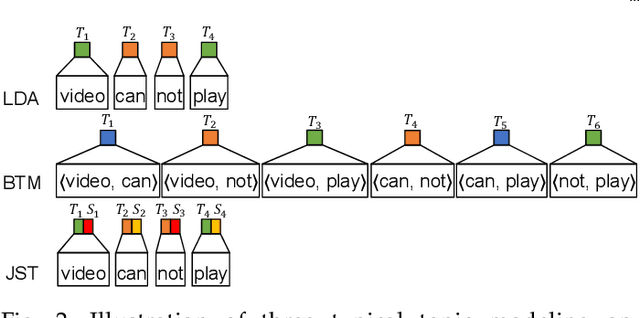
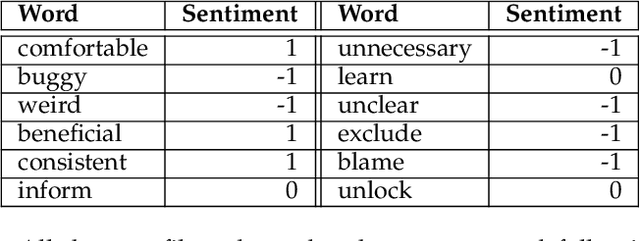
Millions of mobile apps are available in app stores, such as Apple's App Store and Google Play. For a mobile app, it would be increasingly challenging to stand out from the enormous competitors and become prevalent among users. Good user experience and well-designed functionalities are the keys to a successful app. To achieve this, popular apps usually schedule their updates frequently. If we can capture the critical app issues faced by users in a timely and accurate manner, developers can make timely updates, and good user experience can be ensured. There exist prior studies on analyzing reviews for detecting emerging app issues. These studies are usually based on topic modeling or clustering techniques. However, the short-length characteristics and sentiment of user reviews have not been considered. In this paper, we propose a novel emerging issue detection approach named MERIT to take into consideration the two aforementioned characteristics. Specifically, we propose an Adaptive Online Biterm Sentiment-Topic (AOBST) model for jointly modeling topics and corresponding sentiments that takes into consideration app versions. Based on the AOBST model, we infer the topics negatively reflected in user reviews for one app version, and automatically interpret the meaning of the topics with most relevant phrases and sentences. Experiments on popular apps from Google Play and Apple's App Store demonstrate the effectiveness of MERIT in identifying emerging app issues, improving the state-of-the-art method by 22.3% in terms of F1-score. In terms of efficiency, MERIT can return results within acceptable time.
Measuring Emotions in the COVID-19 Real World Worry Dataset
May 14, 2020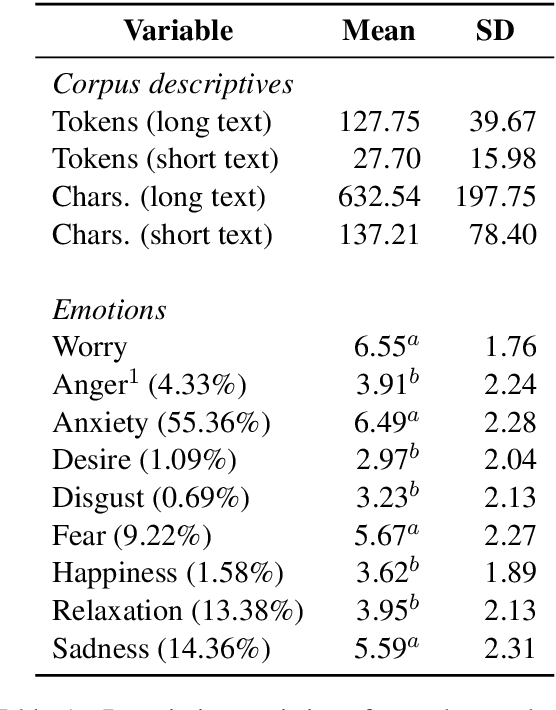
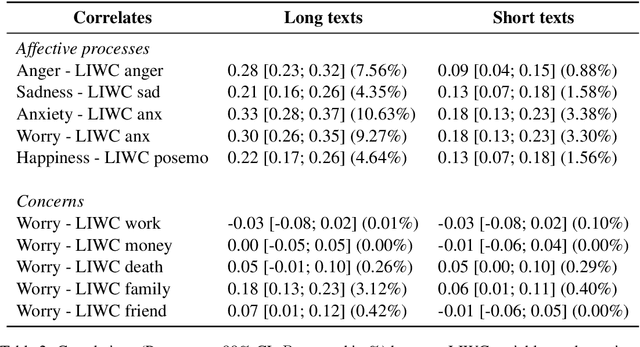

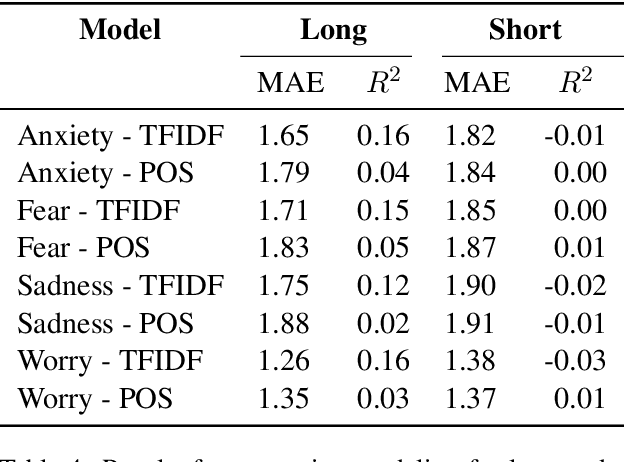
The COVID-19 pandemic is having a dramatic impact on societies and economies around the world. With various measures of lockdowns and social distancing in place, it becomes important to understand emotional responses on a large scale. In this paper, we present the first ground truth dataset of emotional responses to COVID-19. We asked participants to indicate their emotions and express these in text. This resulted in the Real World Worry Dataset of 5,000 texts (2,500 short + 2,500 long texts). Our analyses suggest that emotional responses correlated with linguistic measures. Topic modeling further revealed that people in the UK worry about their family and the economic situation. Tweet-sized texts functioned as a call for solidarity, while longer texts shed light on worries and concerns. Using predictive modeling approaches, we were able to approximate the emotional responses of participants from text within 14% of their actual value. We encourage others to use the dataset and improve how we can use automated methods to learn about emotional responses and worries about an urgent problem.
Fuzzy Approach Topic Discovery in Health and Medical Corpora
May 26, 2017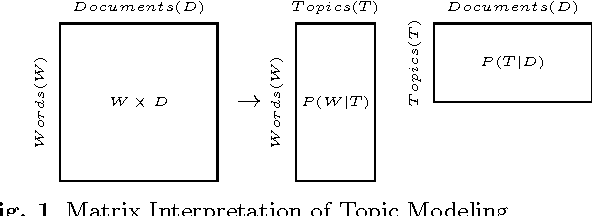
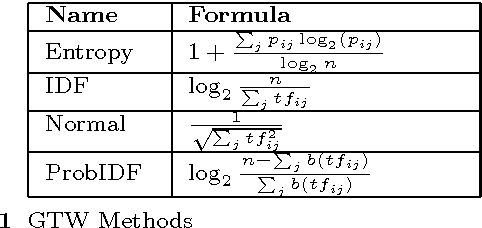
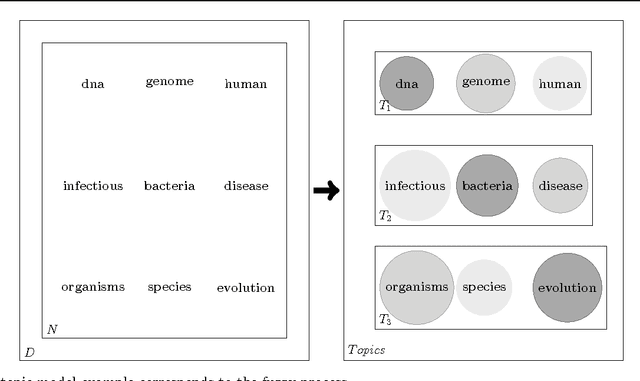
The majority of medical documents and electronic health records (EHRs) are in text format that poses a challenge for data processing and finding relevant documents. Looking for ways to automatically retrieve the enormous amount of health and medical knowledge has always been an intriguing topic. Powerful methods have been developed in recent years to make the text processing automatic. One of the popular approaches to retrieve information based on discovering the themes in health & medical corpora is topic modeling, however, this approach still needs new perspectives. In this research we describe fuzzy latent semantic analysis (FLSA), a novel approach in topic modeling using fuzzy perspective. FLSA can handle health & medical corpora redundancy issue and provides a new method to estimate the number of topics. The quantitative evaluations show that FLSA produces superior performance and features to latent Dirichlet allocation (LDA), the most popular topic model.
Indirect Identification of Psychosocial Risks from Natural Language
Apr 30, 2020
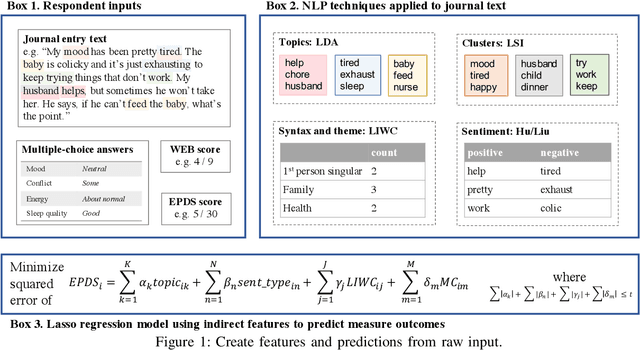
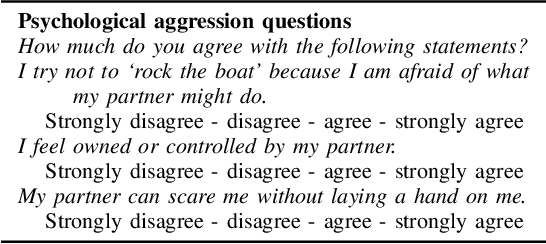
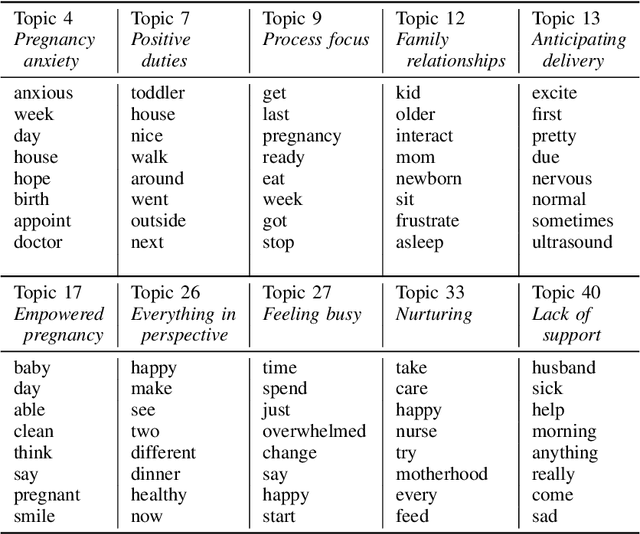
During the perinatal period, psychosocial health risks, including depression and intimate partner violence, are associated with serious adverse health outcomes for parents and children. To appropriately intervene, healthcare professionals must first identify those at risk, yet stigma often prevents people from directly disclosing the information needed to prompt an assessment. We examine indirect methods of eliciting and analyzing information that could indicate psychosocial risks. Short diary entries by peripartum women exhibit thematic patterns, extracted by topic modeling, and emotional perspective, drawn from dictionary-informed sentiment features. Using these features, we use regularized regression to predict screening measures of depression and psychological aggression by an intimate partner. Journal text entries quantified through topic models and sentiment features show promise for depression prediction, with performance almost as good as closed-form questions. Text-based features were less useful for prediction of intimate partner violence, but moderately indirect multiple-choice questioning allowed for detection without explicit disclosure. Both methods may serve as an initial or complementary screening approach to detecting stigmatized risks.
ProsoSpeech: Enhancing Prosody With Quantized Vector Pre-training in Text-to-Speech
Feb 16, 2022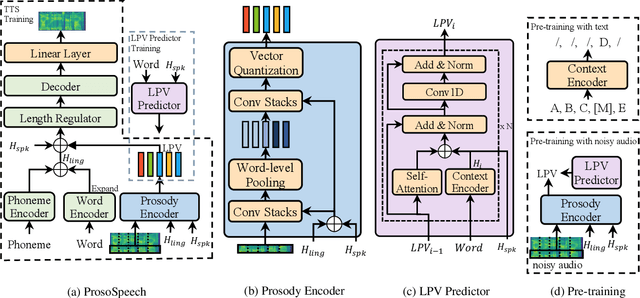
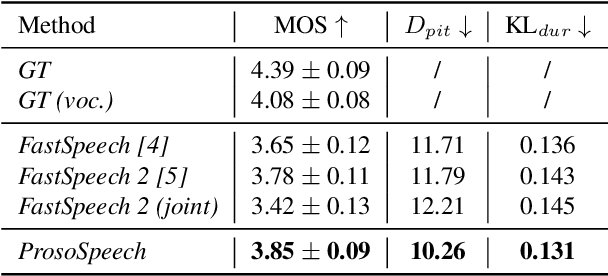
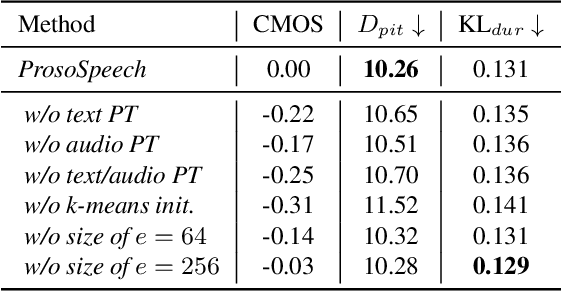
Expressive text-to-speech (TTS) has become a hot research topic recently, mainly focusing on modeling prosody in speech. Prosody modeling has several challenges: 1) the extracted pitch used in previous prosody modeling works have inevitable errors, which hurts the prosody modeling; 2) different attributes of prosody (e.g., pitch, duration and energy) are dependent on each other and produce the natural prosody together; and 3) due to high variability of prosody and the limited amount of high-quality data for TTS training, the distribution of prosody cannot be fully shaped. To tackle these issues, we propose ProsoSpeech, which enhances the prosody using quantized latent vectors pre-trained on large-scale unpaired and low-quality text and speech data. Specifically, we first introduce a word-level prosody encoder, which quantizes the low-frequency band of the speech and compresses prosody attributes in the latent prosody vector (LPV). Then we introduce an LPV predictor, which predicts LPV given word sequence. We pre-train the LPV predictor on large-scale text and low-quality speech data and fine-tune it on the high-quality TTS dataset. Finally, our model can generate expressive speech conditioned on the predicted LPV. Experimental results show that ProsoSpeech can generate speech with richer prosody compared with baseline methods.
Topic-Aware Abstractive Text Summarization
Oct 20, 2020
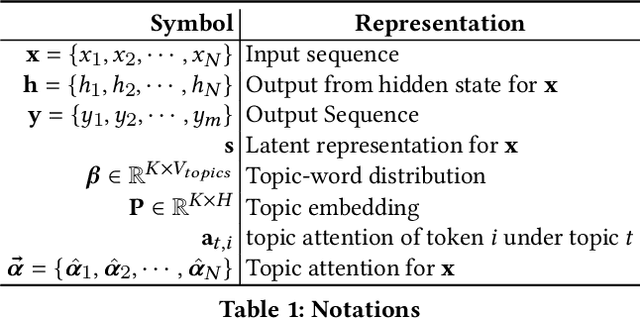
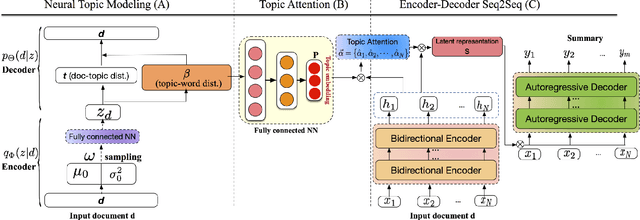
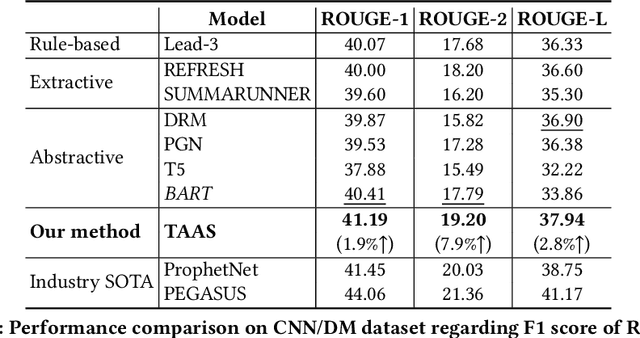
Automatic text summarization aims at condensing a document to a shorter version while preserving the key information. Different from extractive summarization which simply selects text fragments from the document, abstractive summarization generates the summary in a word-by-word manner. Most current state-of-the-art (SOTA) abstractive summarization methods are based on the Transformer-based encoder-decoder architecture and focus on novel self-supervised objectives in pre-training. While these models well capture the contextual information among words in documents, little attention has been paid to incorporating global semantics to better fine-tune for the downstream abstractive summarization task. In this study, we propose a topic-aware abstractive summarization (TAAS) framework by leveraging the underlying semantic structure of documents represented by their latent topics. Specifically, TAAS seamlessly incorporates a neural topic modeling into an encoder-decoder based sequence generation procedure via attention for summarization. This design is able to learn and preserve global semantics of documents and thus makes summarization effective, which has been proved by our experiments on real-world datasets. As compared to several cutting-edge baseline methods, we show that TAAS outperforms BART, a well-recognized SOTA model, by 2%, 8%, and 12% regarding the F measure of ROUGE-1, ROUGE-2, and ROUGE-L, respectively. TAAS also achieves comparable performance to PEGASUS and ProphetNet, which is difficult to accomplish given that training PEGASUS and ProphetNet requires enormous computing capacity beyond what we used in this study.
HybridCite: A Hybrid Model for Context-Aware Citation Recommendation
Feb 15, 2020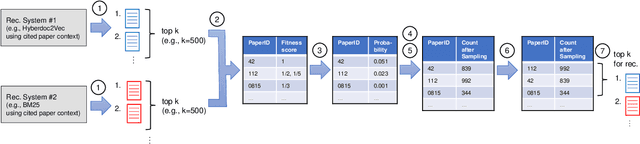
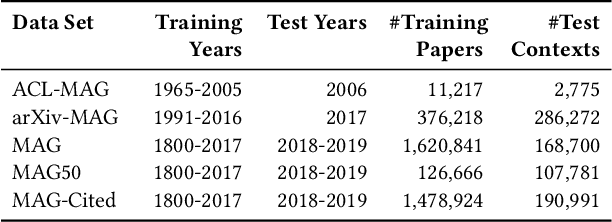
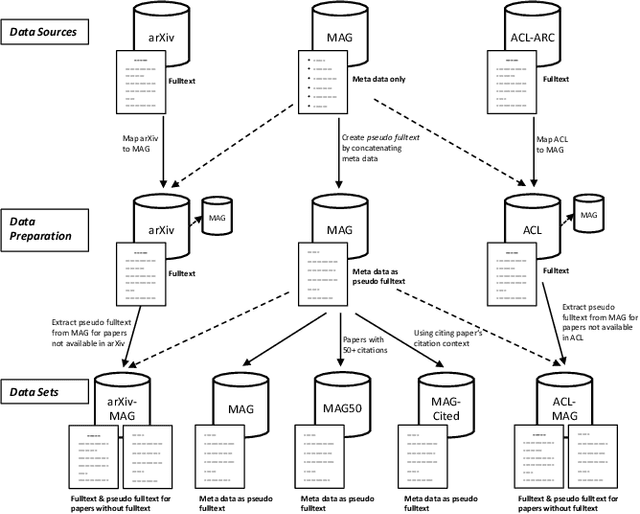
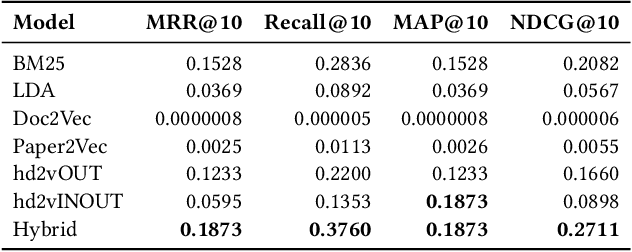
Citation recommendation systems aim to recommend citations for either a complete paper or a small portion of text called a citation context. The process of recommending citations for citation contexts is called local citation recommendation and is the focus of this paper. In this paper, firstly, we develop citation recommendation approaches based on embeddings, topic modeling, and information retrieval techniques. We combine, for the first time to the best of our knowledge, the best-performing algorithms into a semi-genetic hybrid recommender system for citation recommendation. We evaluate the single approaches and the hybrid approach offline based on several data sets, such as the Microsoft Academic Graph (MAG) and the MAG in combination with arXiv and ACL. We further conduct a user study for evaluating our approaches online. Our evaluation results show that a hybrid model containing embedding and information retrieval-based components outperforms its individual components and further algorithms by a large margin.
Two Huge Title and Keyword Generation Corpora of Research Articles
Feb 11, 2020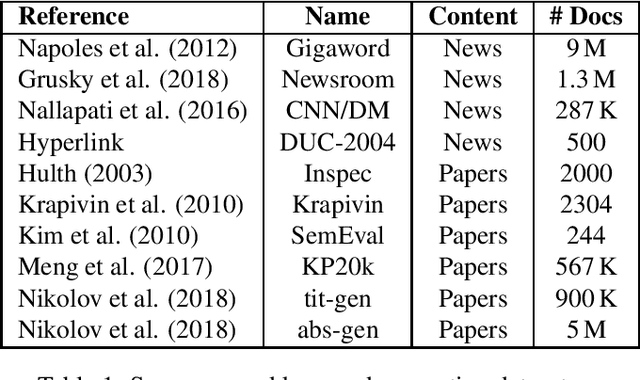
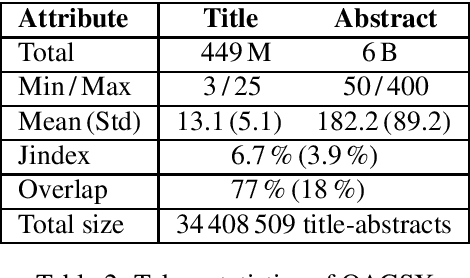
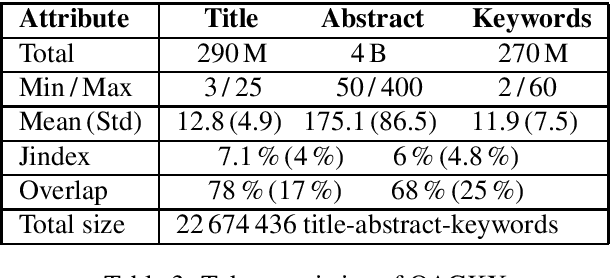
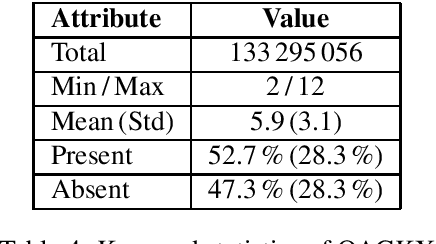
Recent developments in sequence-to-sequence learning with neural networks have considerably improved the quality of automatically generated text summaries and document keywords, stipulating the need for even bigger training corpora. Metadata of research articles are usually easy to find online and can be used to perform research on various tasks. In this paper, we introduce two huge datasets for text summarization (OAGSX) and keyword generation (OAGKX) research, containing 34 million and 23 million records, respectively. The data were retrieved from the Open Academic Graph which is a network of research profiles and publications. We carefully processed each record and also tried several extractive and abstractive methods of both tasks to create performance baselines for other researchers. We further illustrate the performance of those methods previewing their outputs. In the near future, we would like to apply topic modeling on the two sets to derive subsets of research articles from more specific disciplines.