 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
Model Fusion with Kullback--Leibler Divergence
Jul 13, 2020


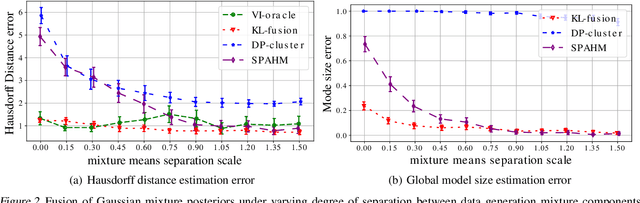
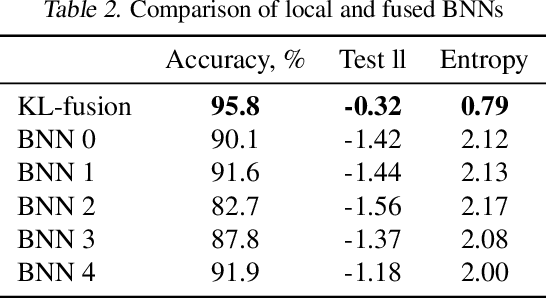
We propose a method to fuse posterior distributions learned from heterogeneous datasets. Our algorithm relies on a mean field assumption for both the fused model and the individual dataset posteriors and proceeds using a simple assign-and-average approach. The components of the dataset posteriors are assigned to the proposed global model components by solving a regularized variant of the assignment problem. The global components are then updated based on these assignments by their mean under a KL divergence. For exponential family variational distributions, our formulation leads to an efficient non-parametric algorithm for computing the fused model. Our algorithm is easy to describe and implement, efficient, and competitive with state-of-the-art on motion capture analysis, topic modeling, and federated learning of Bayesian neural networks.
On Cross-Dataset Generalization in Automatic Detection of Online Abuse
Nov 03, 2020
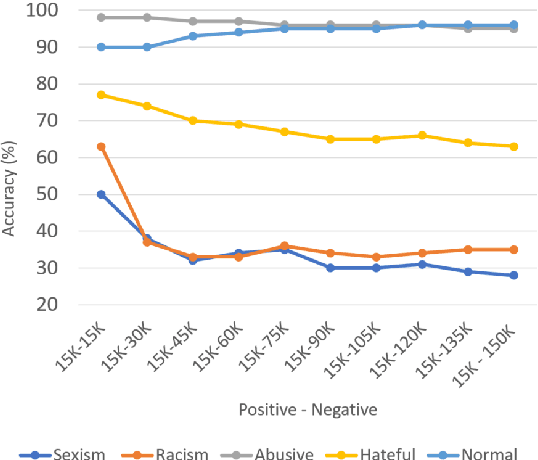
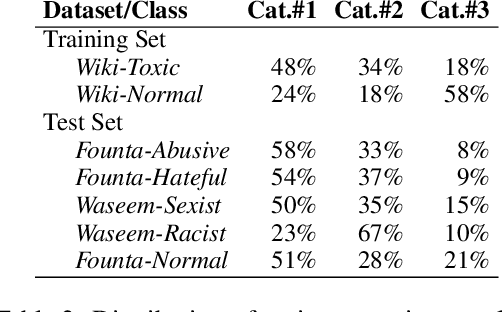
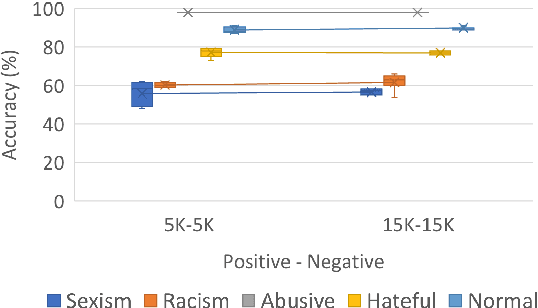
NLP research has attained high performances in abusive language detection as a supervised classification task. While in research settings, training and test datasets are usually obtained from similar data samples, in practice systems are often applied on data that are different from the training set in topic and class distributions. Also, the ambiguity in class definitions inherited in this task aggravates the discrepancies between source and target datasets. We explore the topic bias and the task formulation bias in cross-dataset generalization. We show that the benign examples in the Wikipedia Detox dataset are biased towards platform-specific topics. We identify these examples using unsupervised topic modeling and manual inspection of topics' keywords. Removing these topics increases cross-dataset generalization, without reducing in-domain classification performance. For a robust dataset design, we suggest applying inexpensive unsupervised methods to inspect the collected data and downsize the non-generalizable content before manually annotating for class labels.
Unsupervised Learning on 3D Point Clouds by Clustering and Contrasting
Feb 05, 2022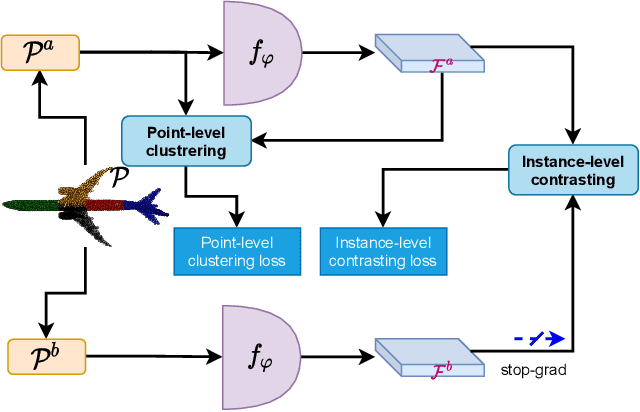
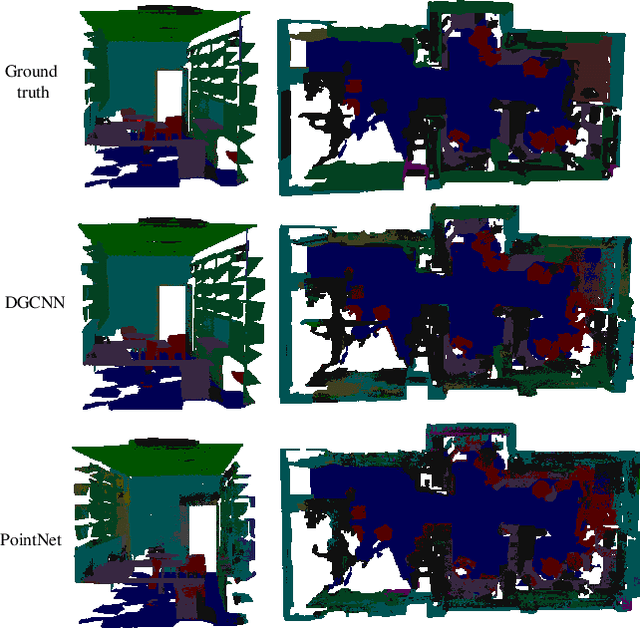
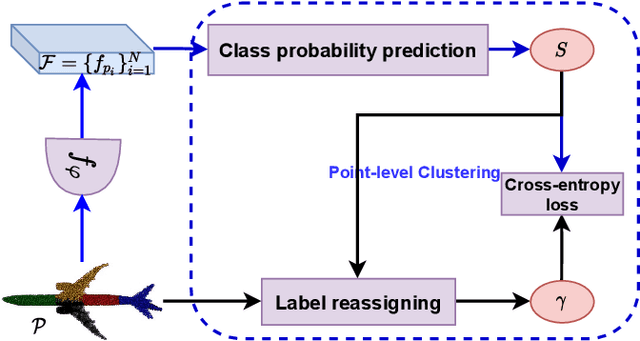
Learning from unlabeled or partially labeled data to alleviate human labeling remains a challenging research topic in 3D modeling. Along this line, unsupervised representation learning is a promising direction to auto-extract features without human intervention. This paper proposes a general unsupervised approach, named \textbf{ConClu}, to perform the learning of point-wise and global features by jointly leveraging point-level clustering and instance-level contrasting. Specifically, for one thing, we design an Expectation-Maximization (EM) like soft clustering algorithm that provides local supervision to extract discriminating local features based on optimal transport. We show that this criterion extends standard cross-entropy minimization to an optimal transport problem, which we solve efficiently using a fast variant of the Sinkhorn-Knopp algorithm. For another, we provide an instance-level contrasting method to learn the global geometry, which is formulated by maximizing the similarity between two augmentations of one point cloud. Experimental evaluations on downstream applications such as 3D object classification and semantic segmentation demonstrate the effectiveness of our framework and show that it can outperform state-of-the-art techniques.
Analysis and tuning of hierarchical topic models based on Renyi entropy approach
Jan 19, 2021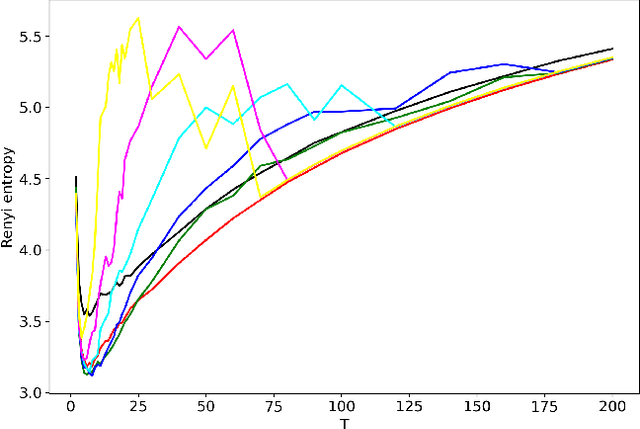
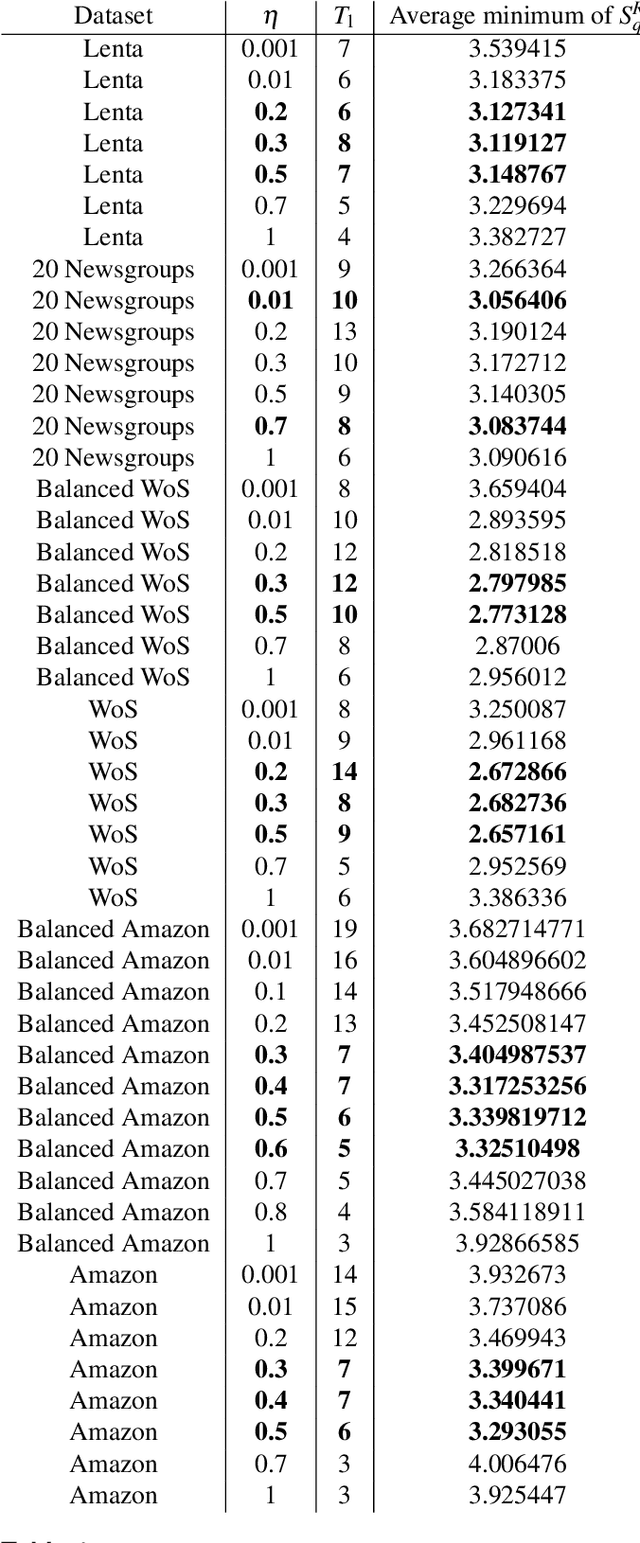
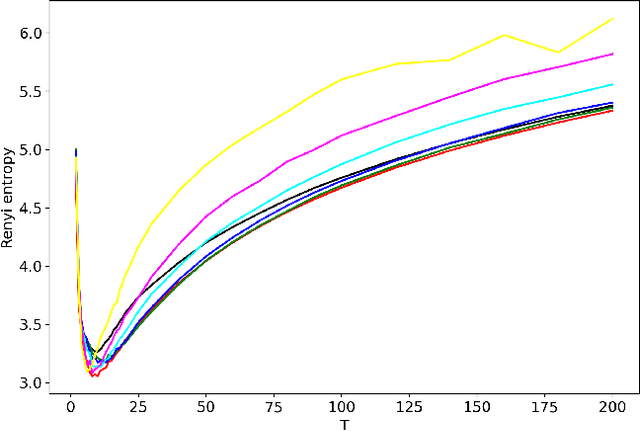
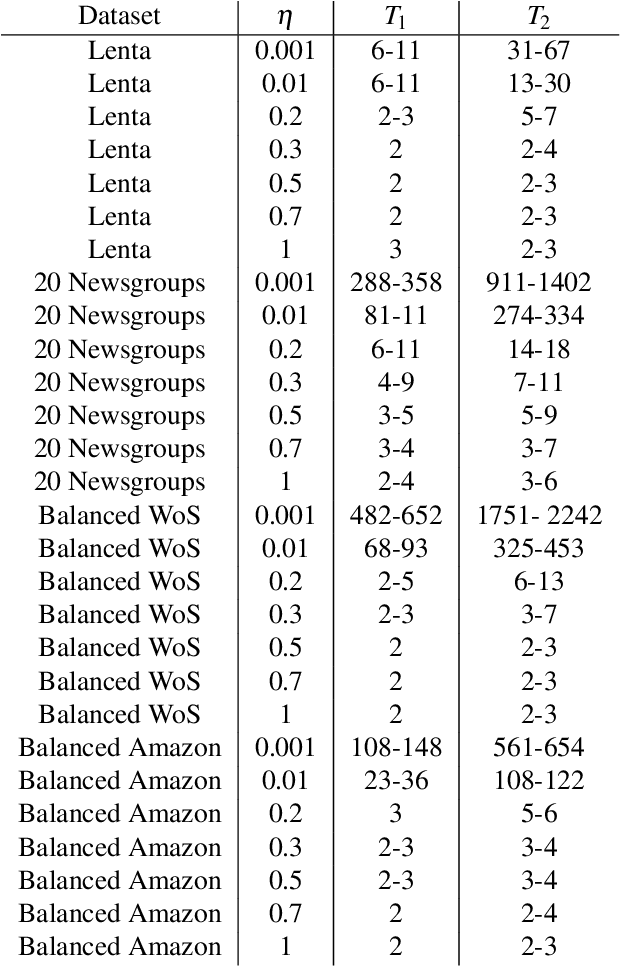
Hierarchical topic modeling is a potentially powerful instrument for determining the topical structure of text collections that allows constructing a topical hierarchy representing levels of topical abstraction. However, tuning of parameters of hierarchical models, including the number of topics on each hierarchical level, remains a challenging task and an open issue. In this paper, we propose a Renyi entropy-based approach for a partial solution to the above problem. First, we propose a Renyi entropy-based metric of quality for hierarchical models. Second, we propose a practical concept of hierarchical topic model tuning tested on datasets with human mark-up. In the numerical experiments, we consider three different hierarchical models, namely, hierarchical latent Dirichlet allocation (hLDA) model, hierarchical Pachinko allocation model (hPAM), and hierarchical additive regularization of topic models (hARTM). We demonstrate that hLDA model possesses a significant level of instability and, moreover, the derived numbers of topics are far away from the true numbers for labeled datasets. For hPAM model, the Renyi entropy approach allows us to determine only one level of the data structure. For hARTM model, the proposed approach allows us to estimate the number of topics for two hierarchical levels.
Nonparametric Spherical Topic Modeling with Word Embeddings
Apr 01, 2016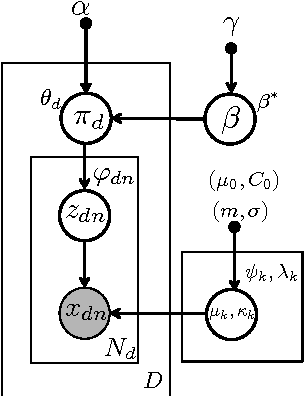


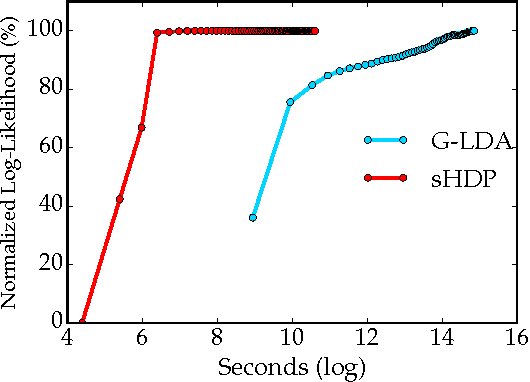
Traditional topic models do not account for semantic regularities in language. Recent distributional representations of words exhibit semantic consistency over directional metrics such as cosine similarity. However, neither categorical nor Gaussian observational distributions used in existing topic models are appropriate to leverage such correlations. In this paper, we propose to use the von Mises-Fisher distribution to model the density of words over a unit sphere. Such a representation is well-suited for directional data. We use a Hierarchical Dirichlet Process for our base topic model and propose an efficient inference algorithm based on Stochastic Variational Inference. This model enables us to naturally exploit the semantic structures of word embeddings while flexibly discovering the number of topics. Experiments demonstrate that our method outperforms competitive approaches in terms of topic coherence on two different text corpora while offering efficient inference.
Adapting CRISP-DM for Idea Mining: A Data Mining Process for Generating Ideas Using a Textual Dataset
May 02, 2021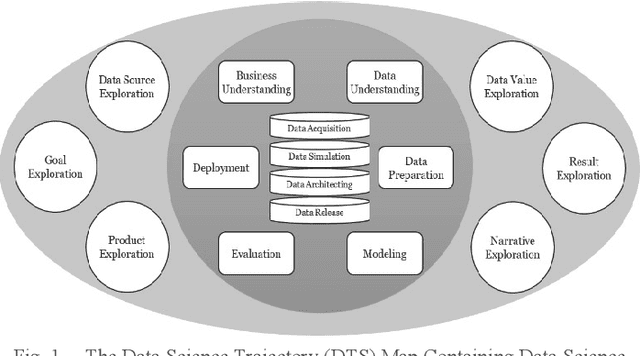
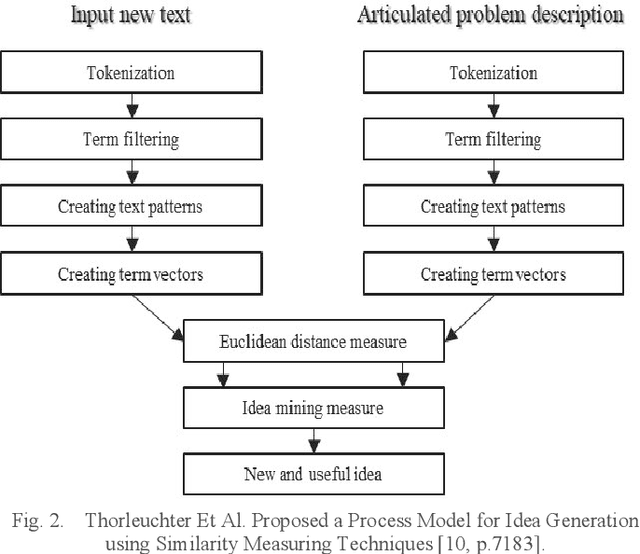
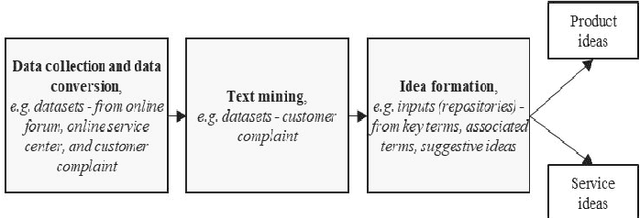
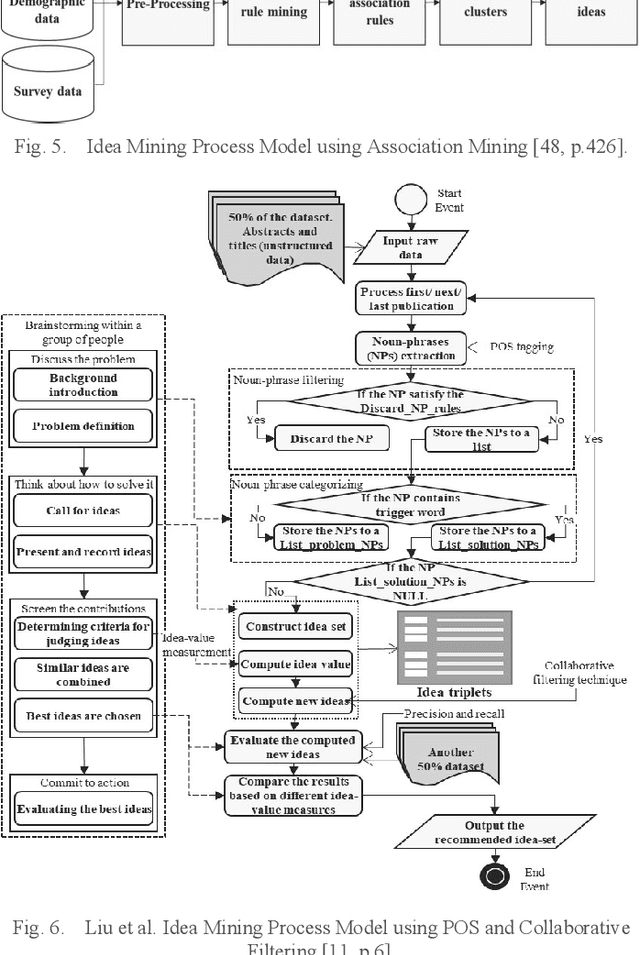
Data mining project managers can benefit from using standard data mining process models. The benefits of using standard process models for data mining, such as the de facto and the most popular, Cross-Industry-Standard-Process model for Data Mining (CRISP-DM) are reduced cost and time. Also, standard models facilitate knowledge transfer, reuse of best practices, and minimize knowledge requirements. On the other hand, to unlock the potential of ever-growing textual data such as publications, patents, social media data, and documents of various forms, digital innovation is increasingly needed. Furthermore, the introduction of cutting-edge machine learning tools and techniques enable the elicitation of ideas. The processing of unstructured textual data to generate new and useful ideas is referred to as idea mining. Existing literature about idea mining merely overlooks the utilization of standard data mining process models. Therefore, the purpose of this paper is to propose a reusable model to generate ideas, CRISP-DM, for Idea Mining (CRISP-IM). The design and development of the CRISP-IM are done following the design science approach. The CRISP-IM facilitates idea generation, through the use of Dynamic Topic Modeling (DTM), unsupervised machine learning, and subsequent statistical analysis on a dataset of scholarly articles. The adapted CRISP-IM can be used to guide the process of identifying trends using scholarly literature datasets or temporally organized patent or any other textual dataset of any domain to elicit ideas. The ex-post evaluation of the CRISP-IM is left for future study.
Biomedical Named Entity Recognition at Scale
Nov 12, 2020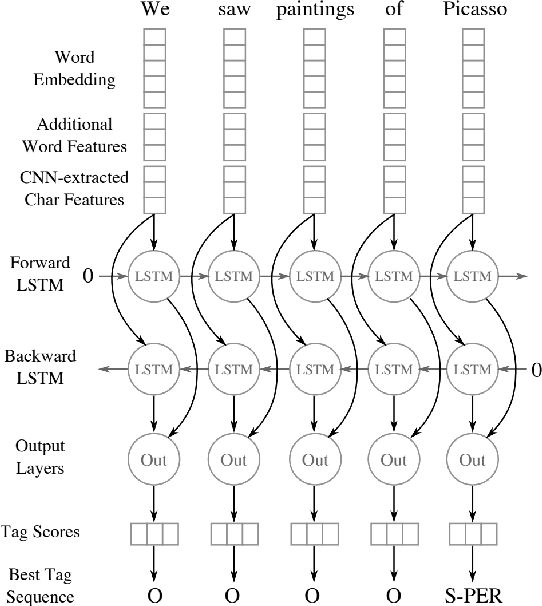
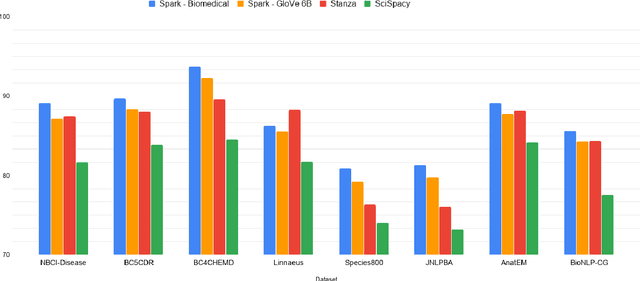
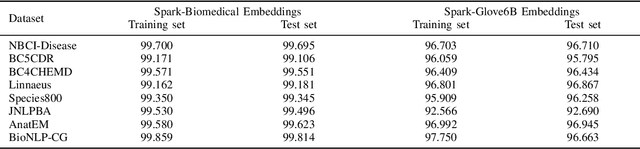
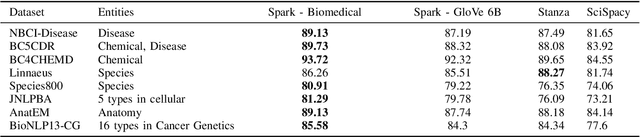
Named entity recognition (NER) is a widely applicable natural language processing task and building block of question answering, topic modeling, information retrieval, etc. In the medical domain, NER plays a crucial role by extracting meaningful chunks from clinical notes and reports, which are then fed to downstream tasks like assertion status detection, entity resolution, relation extraction, and de-identification. Reimplementing a Bi-LSTM-CNN-Char deep learning architecture on top of Apache Spark, we present a single trainable NER model that obtains new state-of-the-art results on seven public biomedical benchmarks without using heavy contextual embeddings like BERT. This includes improving BC4CHEMD to 93.72% (4.1% gain), Species800 to 80.91% (4.6% gain), and JNLPBA to 81.29% (5.2% gain). In addition, this model is freely available within a production-grade code base as part of the open-source Spark NLP library; can scale up for training and inference in any Spark cluster; has GPU support and libraries for popular programming languages such as Python, R, Scala and Java; and can be extended to support other human languages with no code changes.
Review of Probability Distributions for Modeling Count Data
Jan 10, 2020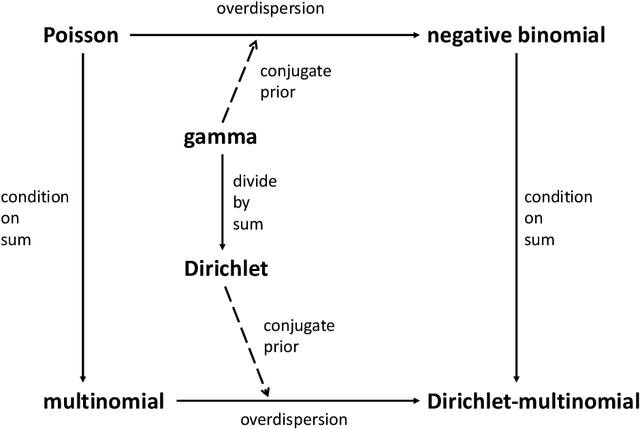
Count data take on non-negative integer values and are challenging to properly analyze using standard linear-Gaussian methods such as linear regression and principal components analysis. Generalized linear models enable direct modeling of counts in a regression context using distributions such as the Poisson and negative binomial. When counts contain only relative information, multinomial or Dirichlet-multinomial models can be more appropriate. We review some of the fundamental connections between multinomial and count models from probability theory, providing detailed proofs. These relationships are useful for methods development in applications such as topic modeling of text data and genomics.
Unsupervised Terminological Ontology Learning based on Hierarchical Topic Modeling
Aug 29, 2017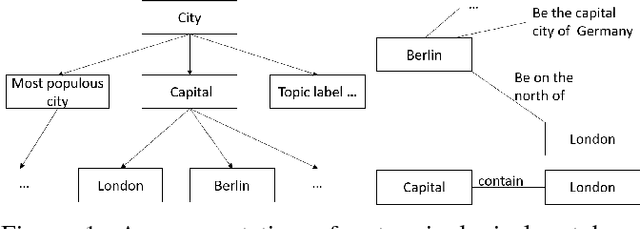
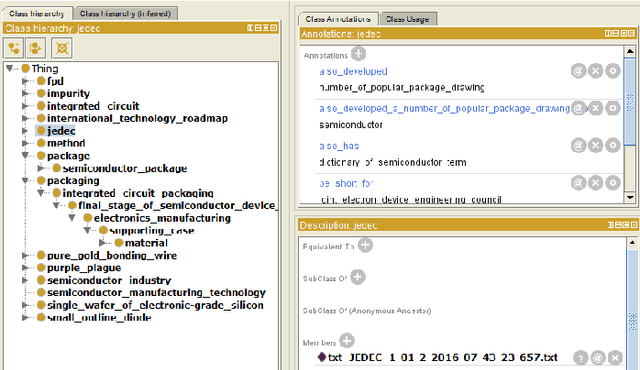
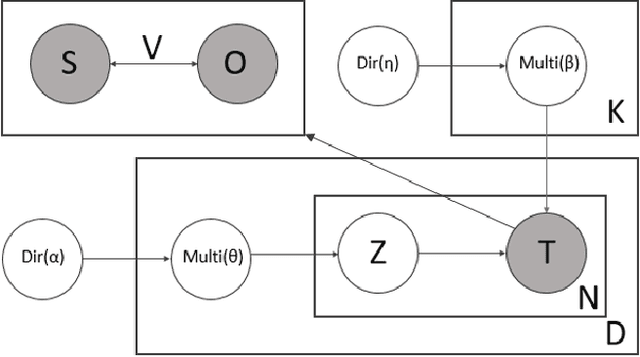
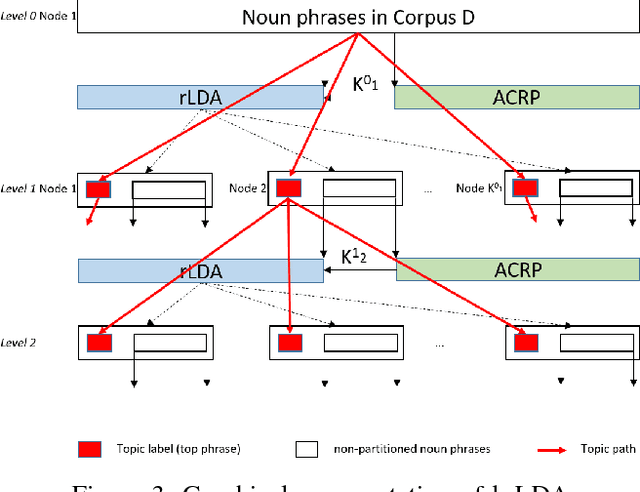
In this paper, we present hierarchical relationbased latent Dirichlet allocation (hrLDA), a data-driven hierarchical topic model for extracting terminological ontologies from a large number of heterogeneous documents. In contrast to traditional topic models, hrLDA relies on noun phrases instead of unigrams, considers syntax and document structures, and enriches topic hierarchies with topic relations. Through a series of experiments, we demonstrate the superiority of hrLDA over existing topic models, especially for building hierarchies. Furthermore, we illustrate the robustness of hrLDA in the settings of noisy data sets, which are likely to occur in many practical scenarios. Our ontology evaluation results show that ontologies extracted from hrLDA are very competitive with the ontologies created by domain experts.