 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
Combinatorial Topic Models using Small-Variance Asymptotics
May 27, 2016

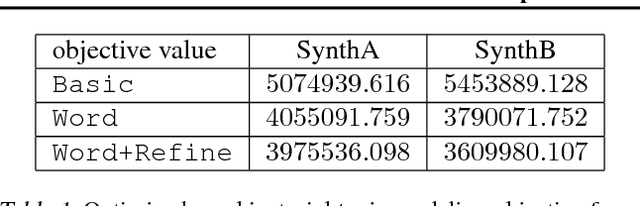
Topic models have emerged as fundamental tools in unsupervised machine learning. Most modern topic modeling algorithms take a probabilistic view and derive inference algorithms based on Latent Dirichlet Allocation (LDA) or its variants. In contrast, we study topic modeling as a combinatorial optimization problem, and propose a new objective function derived from LDA by passing to the small-variance limit. We minimize the derived objective by using ideas from combinatorial optimization, which results in a new, fast, and high-quality topic modeling algorithm. In particular, we show that our results are competitive with popular LDA-based topic modeling approaches, and also discuss the (dis)similarities between our approach and its probabilistic counterparts.
ReviewViz: Assisting Developers Perform Empirical Study on Energy Consumption Related Reviews for Mobile Applications
Sep 13, 2020
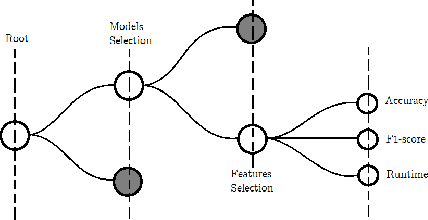
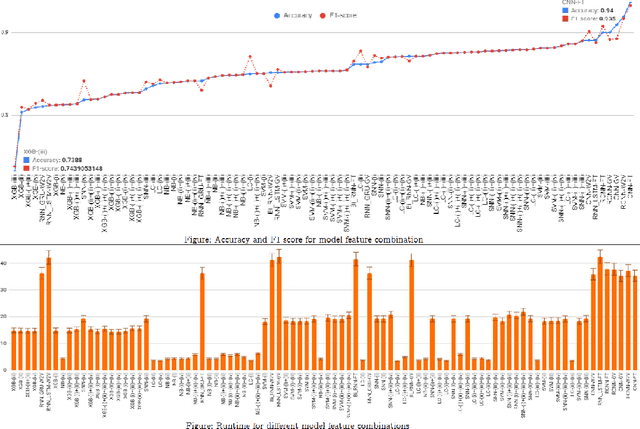
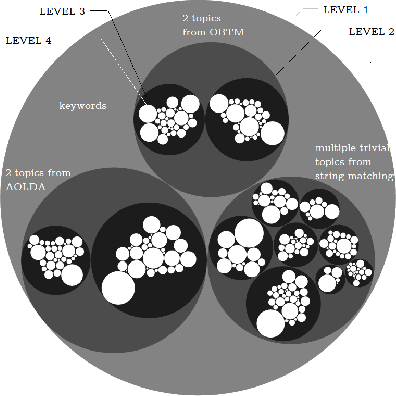
Improving the energy efficiency of mobile applications is a topic that has gained a lot of attention recently. It has been addressed in a number of ways such as identifying energy bugs and developing a catalog of energy patterns. Previous work shows that users discuss the battery-related issues (energy inefficiency or energy consumption) of the apps in their reviews. However, there is no work that addresses the automatic extraction of battery-related issues from users' feedback. In this paper, we report on a visualization tool that is developed to empirically study machine learning algorithms and text features to automatically identify the energy consumption specific reviews with the highest accuracy. Other than the common machine learning algorithms, we utilize deep learning models with different word embeddings to compare the results. Furthermore, to help the developers extract the main topics that are discussed in the reviews, two states of the art topic modeling algorithms are applied. The visualizations of the topics represent the keywords that are extracted for each topic along with a comparison with the results of string matching. The developed web-browser based interactive visualization tool is a novel framework developed with the intention of giving the app developers insights about running time and accuracy of machine learning and deep learning models as well as extracted topics. The tool makes it easier for the developers to traverse through the extensive result set generated by the text classification and topic modeling algorithms. The dynamic-data structure used for the tool stores the baseline-results of the discussed approaches and is updated when applied on new datasets. The tool is open-sourced to replicate the research results.
Topic Community Based Temporal Expertise for Question Routing
Jul 05, 2022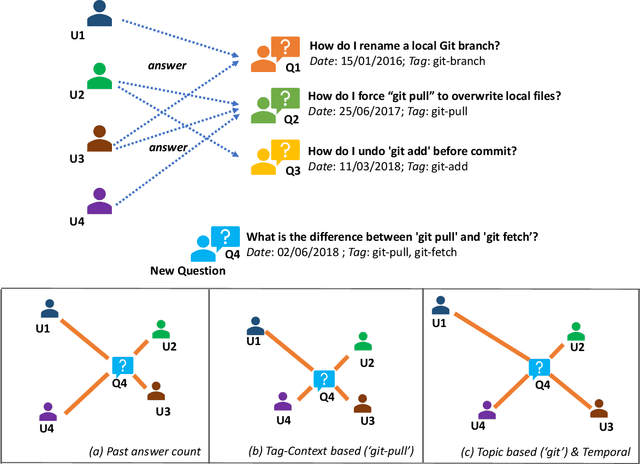
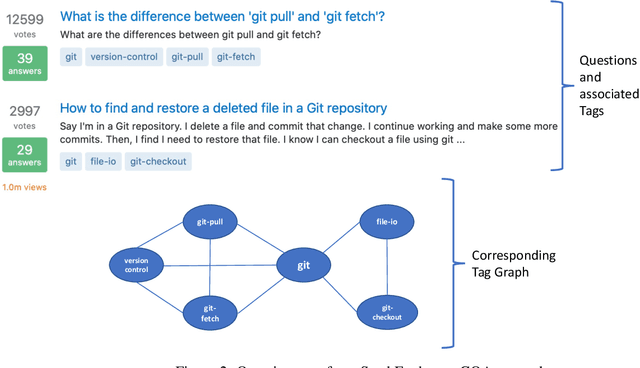
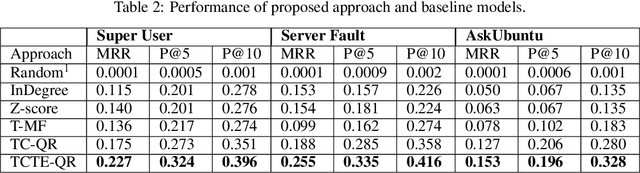
Question Routing in Community-based Question Answering websites aims at recommending newly posted questions to potential users who are most likely to provide "accepted answers". Most of the existing approaches predict users' expertise based on their past question answering behavior and the content of new questions. However, these approaches suffer from challenges in three aspects: 1) sparsity of users' past records results in lack of personalized recommendation that at times does not match users' interest or domain expertise, 2) modeling based on all questions and answers content makes periodic updates computationally expensive, and 3) while CQA sites are highly dynamic, they are mostly considered as static. This paper proposes a novel approach to QR that addresses the above challenges. It is based on dynamic modeling of users' activity on topic communities. Experimental results on three real-world datasets demonstrate that the proposed model significantly outperforms competitive baseline models
Semantics of European poetry is shaped by conservative forces: The relationship between poetic meter and meaning in accentual-syllabic verse
Sep 15, 2021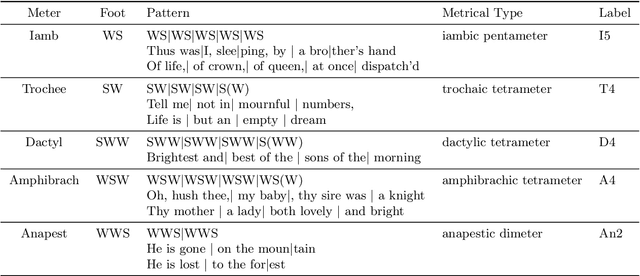

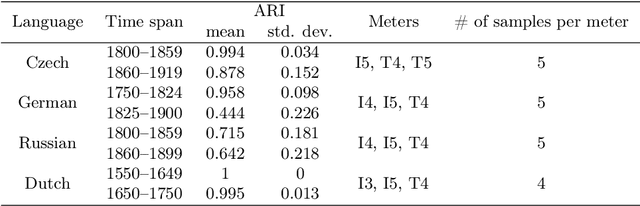
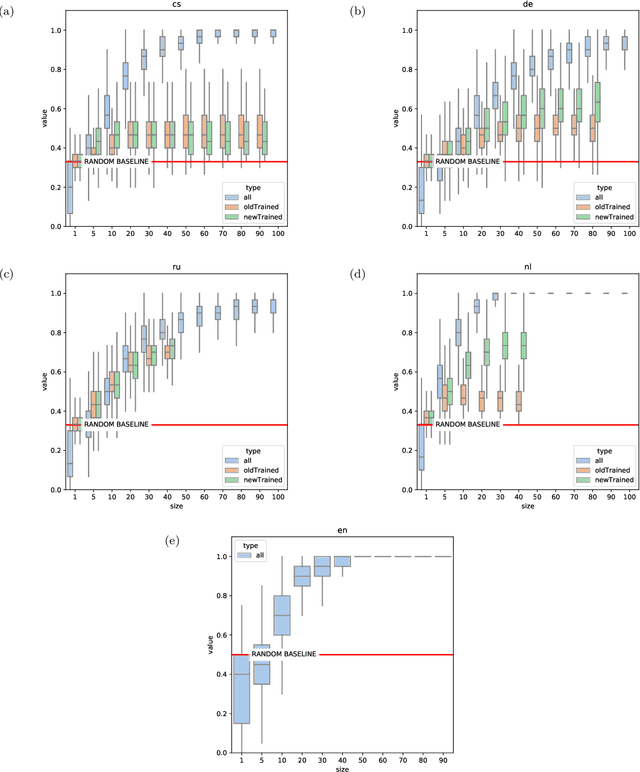
Recent advances in cultural analytics and large-scale computational studies of art, literature and film often show that long-term change in the features of artistic works happens gradually. These findings suggest that conservative forces that shape creative domains might be underestimated. To this end, we provide the first large-scale formal evidence of the persistent association between poetic meter and semantics in 18-19th European literatures, using Czech, German and Russian collections with additional data from English poetry and early modern Dutch songs. Our study traces this association through a series of clustering experiments using the abstracted semantic features of 150,000 poems. With the aid of topic modeling we infer semantic features for individual poems. Texts were also lexically simplified across collections to increase generalizability and decrease the sparseness of word frequency distributions. Topics alone enable recognition of the meters in each observed language, as may be seen from highly robust clustering of same-meter samples (median Adjusted Rand Index between 0.48 and 1). In addition, this study shows that the strength of the association between form and meaning tends to decrease over time. This may reflect a shift in aesthetic conventions between the 18th and 19th centuries as individual innovation was increasingly favored in literature. Despite this decline, it remains possible to recognize semantics of the meters from past or future, which suggests the continuity of semantic traditions while also revealing the historical variability of conditions across languages. This paper argues that distinct metrical forms, which are often copied in a language over centuries, also maintain long-term semantic inertia in poetry. Our findings, thus, highlight the role of the formal features of cultural items in influencing the pace and shape of cultural evolution.
Distilled Wasserstein Learning for Word Embedding and Topic Modeling
Sep 12, 2018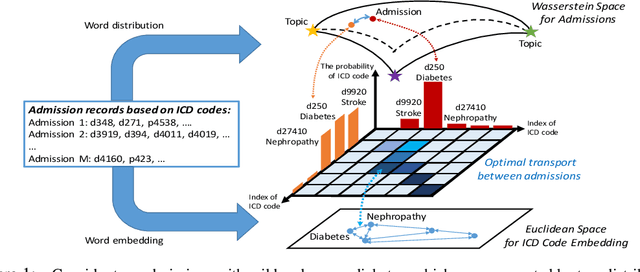
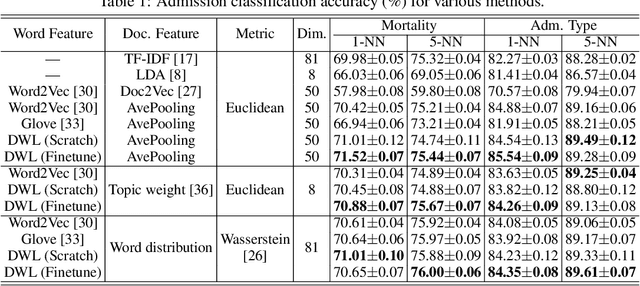
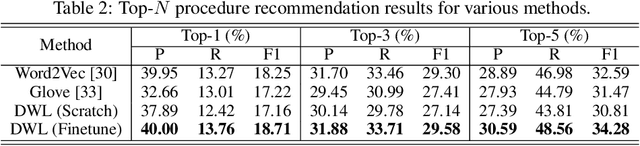
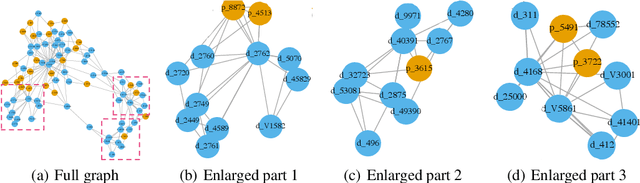
We propose a novel Wasserstein method with a distillation mechanism, yielding joint learning of word embeddings and topics. The proposed method is based on the fact that the Euclidean distance between word embeddings may be employed as the underlying distance in the Wasserstein topic model. The word distributions of topics, their optimal transports to the word distributions of documents, and the embeddings of words are learned in a unified framework. When learning the topic model, we leverage a distilled underlying distance matrix to update the topic distributions and smoothly calculate the corresponding optimal transports. Such a strategy provides the updating of word embeddings with robust guidance, improving the algorithmic convergence. As an application, we focus on patient admission records, in which the proposed method embeds the codes of diseases and procedures and learns the topics of admissions, obtaining superior performance on clinically-meaningful disease network construction, mortality prediction as a function of admission codes, and procedure recommendation.
COVID-19 Vaccines: Characterizing Misinformation Campaigns and Vaccine Hesitancy on Twitter
Jun 15, 2021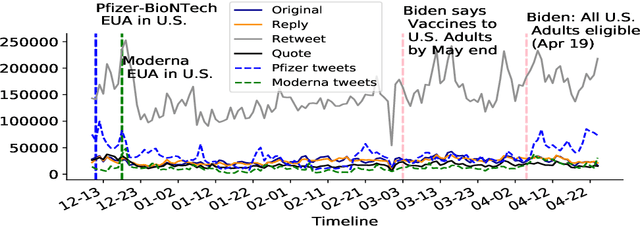
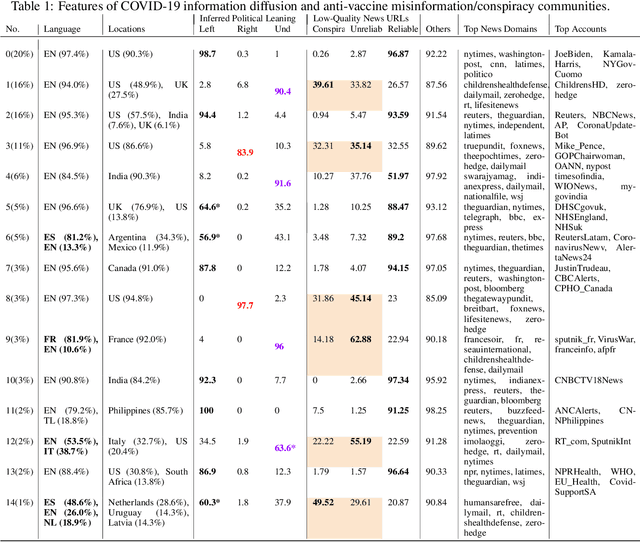
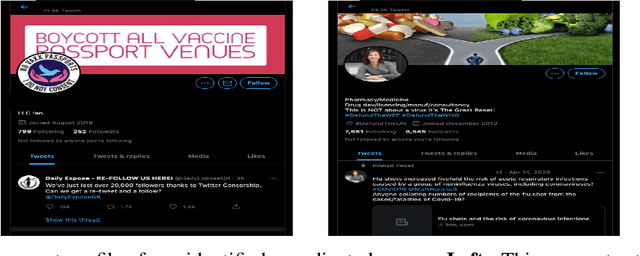
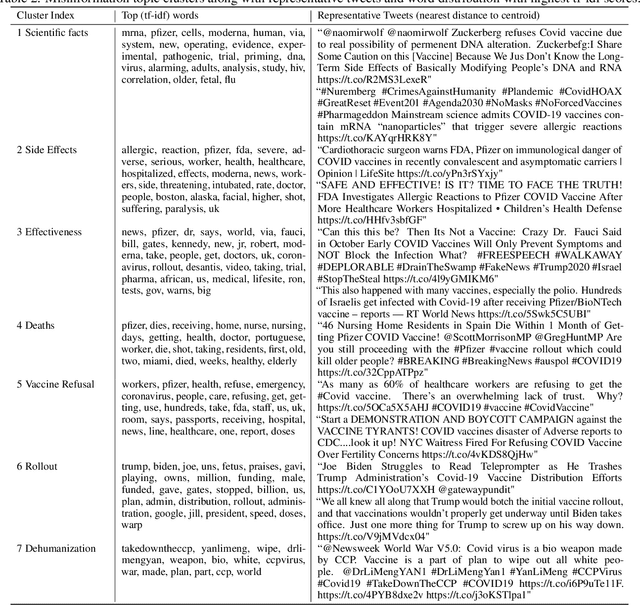
Vaccine hesitancy and misinformation on social media has increased concerns about COVID-19 vaccine uptake required to achieve herd immunity and overcome the pandemic. However anti-science and political misinformation and conspiracies have been rampant throughout the pandemic. For COVID-19 vaccines, we investigate misinformation and conspiracy campaigns and their characteristic behaviours. We identify whether coordinated efforts are used to promote misinformation in vaccine related discussions, and find accounts coordinately promoting a `Great Reset' conspiracy group promoting vaccine related misinformation and strong anti-vaccine and anti-social messages such as boycott vaccine passports, no lock-downs and masks. We characterize other misinformation communities from the information diffusion structure, and study the large anti-vaccine misinformation community and smaller anti-vaccine communities, including a far-right anti-vaccine conspiracy group. In comparison with the mainstream and health news, left-leaning group, which are more pro-vaccine, the right-leaning group is influenced more by the anti-vaccine and far-right misinformation/conspiracy communities. The misinformation communities are more vocal either specific to the vaccine discussion or political discussion, and we find other differences in the characteristic behaviours of different communities. Lastly, we investigate misinformation narratives and tactics of information distortion that can increase vaccine hesitancy, using topic modeling and comparison with reported vaccine side-effects (VAERS) finding rarer side-effects are more frequently discussed on social media.
Cultural Convergence: Insights into the behavior of misinformation networks on Twitter
Jul 07, 2020
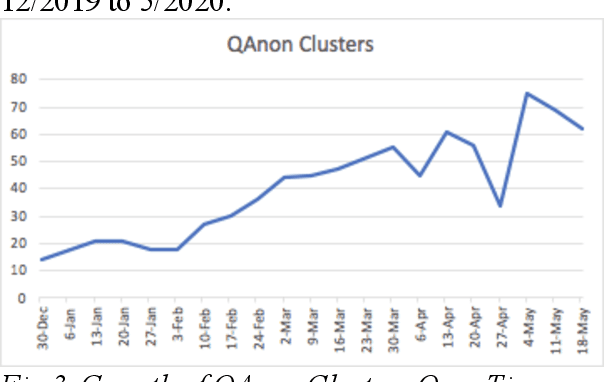
How can the birth and evolution of ideas and communities in a network be studied over time? We use a multimodal pipeline, consisting of network mapping, topic modeling, bridging centrality, and divergence to analyze Twitter data surrounding the COVID-19 pandemic. We use network mapping to detect accounts creating content surrounding COVID-19, then Latent Dirichlet Allocation to extract topics, and bridging centrality to identify topical and non-topical bridges, before examining the distribution of each topic and bridge over time and applying Jensen-Shannon divergence of topic distributions to show communities that are converging in their topical narratives.
Topical Language Generation using Transformers
Mar 11, 2021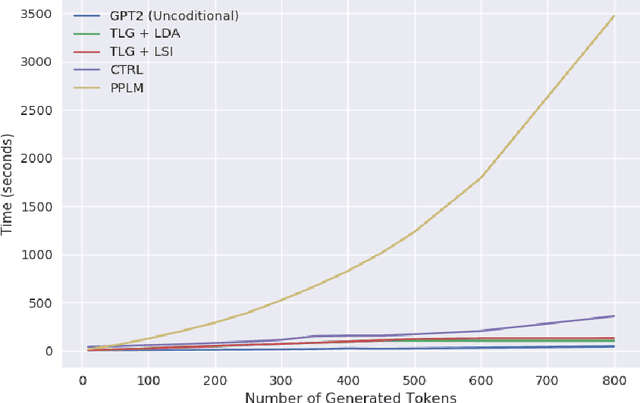

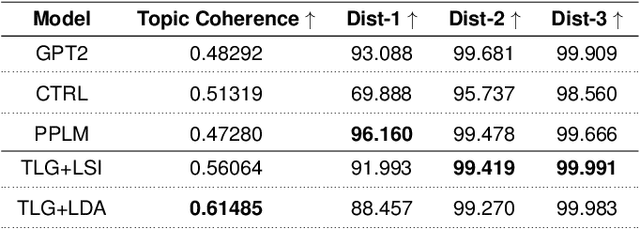

Large-scale transformer-based language models (LMs) demonstrate impressive capabilities in open text generation. However, controlling the generated text's properties such as the topic, style, and sentiment is challenging and often requires significant changes to the model architecture or retraining and fine-tuning the model on new supervised data. This paper presents a novel approach for Topical Language Generation (TLG) by combining a pre-trained LM with topic modeling information. We cast the problem using Bayesian probability formulation with topic probabilities as a prior, LM probabilities as the likelihood, and topical language generation probability as the posterior. In learning the model, we derive the topic probability distribution from the user-provided document's natural structure. Furthermore, we extend our model by introducing new parameters and functions to influence the quantity of the topical features presented in the generated text. This feature would allow us to easily control the topical properties of the generated text. Our experimental results demonstrate that our model outperforms the state-of-the-art results on coherency, diversity, and fluency while being faster in decoding.
Surveillance of COVID-19 Pandemic using Social Media: A Reddit Study in North Carolina
Jun 10, 2021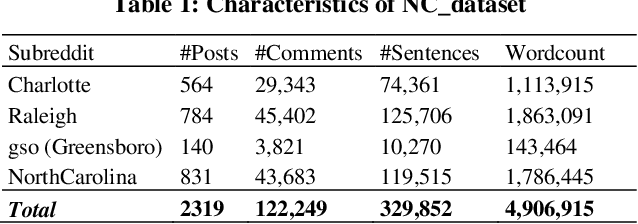
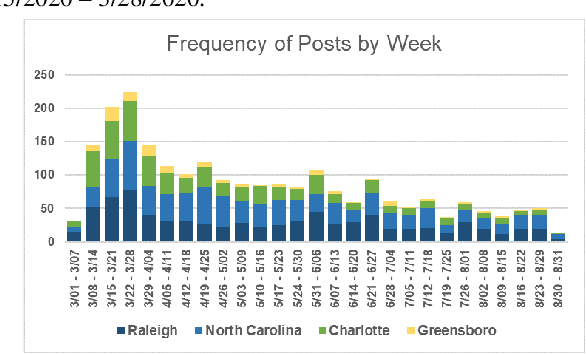
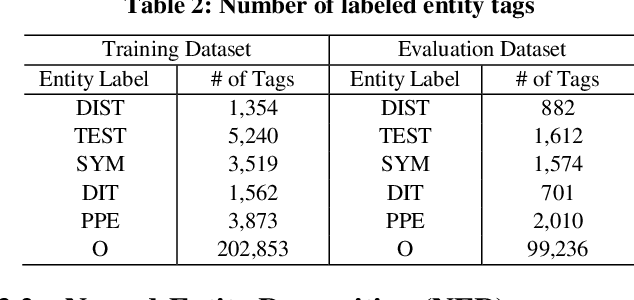
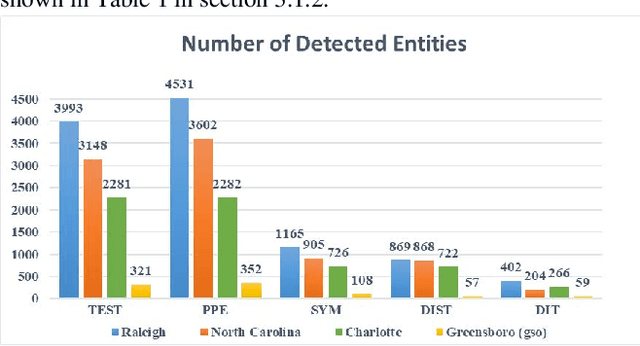
Coronavirus disease (COVID-19) pandemic has changed various aspects of people's lives and behaviors. At this stage, there are no other ways to control the natural progression of the disease than adopting mitigation strategies such as wearing masks, watching distance, and washing hands. Moreover, at this time of social distancing, social media plays a key role in connecting people and providing a platform for expressing their feelings. In this study, we tap into social media to surveil the uptake of mitigation and detection strategies, and capture issues and concerns about the pandemic. In particular, we explore the research question, "how much can be learned regarding the public uptake of mitigation strategies and concerns about COVID-19 pandemic by using natural language processing on Reddit posts?" After extracting COVID-related posts from the four largest subreddit communities of North Carolina over six months, we performed NLP-based preprocessing to clean the noisy data. We employed a custom Named-entity Recognition (NER) system and a Latent Dirichlet Allocation (LDA) method for topic modeling on a Reddit corpus. We observed that 'mask', 'flu', and 'testing' are the most prevalent named-entities for "Personal Protective Equipment", "symptoms", and "testing" categories, respectively. We also observed that the most discussed topics are related to testing, masks, and employment. The mitigation measures are the most prevalent theme of discussion across all subreddits.
Modeling Fuzzy Cluster Transitions for Topic Tracing
Apr 16, 2021
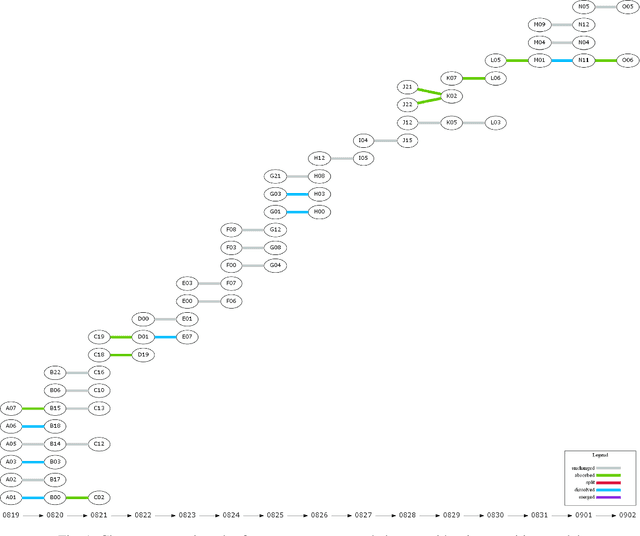

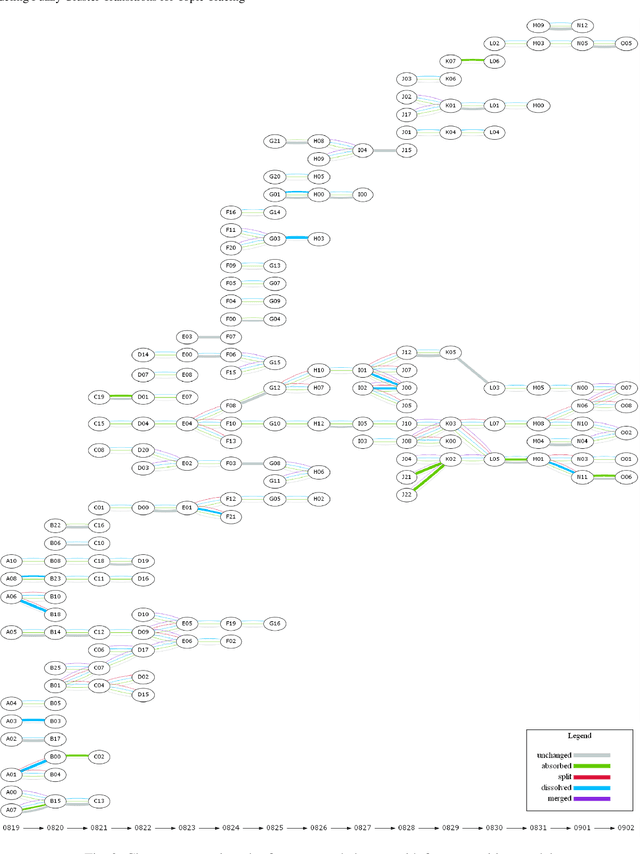
Twitter can be viewed as a data source for Natural Language Processing (NLP) tasks. The continuously updating data streams on Twitter make it challenging to trace real-time topic evolution. In this paper, we propose a framework for modeling fuzzy transitions of topic clusters. We extend our previous work on crisp cluster transitions by incorporating fuzzy logic in order to enrich the underlying structures identified by the framework. We apply the methodology to both computer generated clusters of nouns from tweets and human tweet annotations. The obtained fuzzy transitions are compared with the crisp transitions, on both computer generated clusters and human labeled topic sets.