 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
Exploring Topic-Metadata Relationships with the STM: A Bayesian Approach
Apr 06, 2021
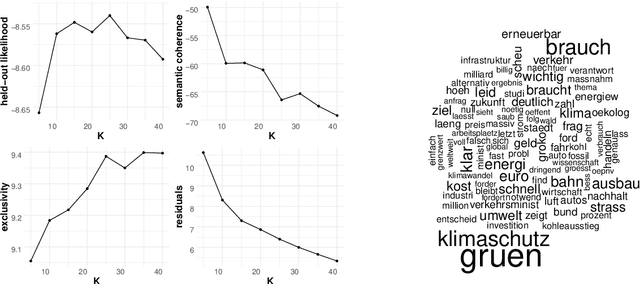
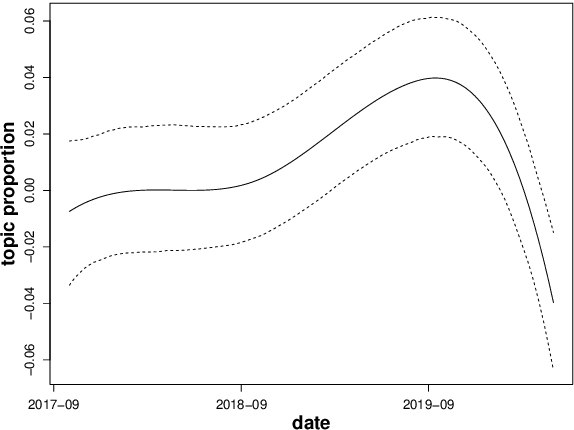
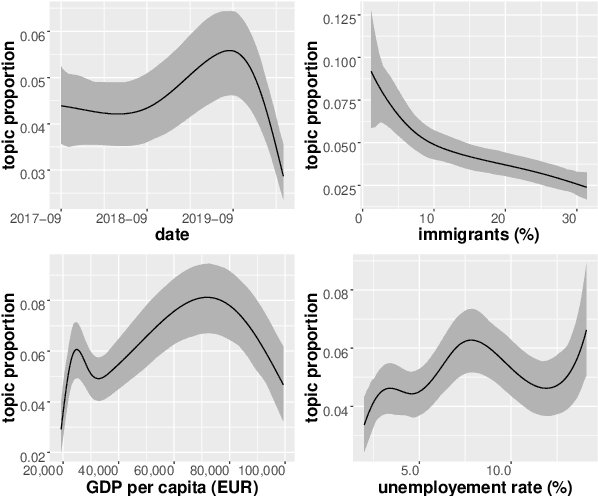
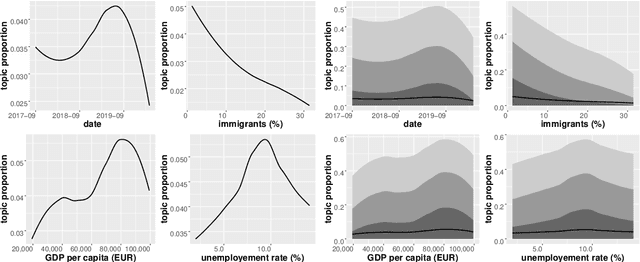
Topic models such as the Structural Topic Model (STM) estimate latent topical clusters within text. An important step in many topic modeling applications is to explore relationships between the discovered topical structure and metadata associated with the text documents. Methods used to estimate such relationships must take into account that the topical structure is not directly observed, but instead being estimated itself. The authors of the STM, for instance, perform repeated OLS regressions of sampled topic proportions on metadata covariates by using a Monte Carlo sampling technique known as the method of composition. In this paper, we propose two improvements: first, we replace OLS with more appropriate Beta regression. Second, we suggest a fully Bayesian approach instead of the current blending of frequentist and Bayesian methods. We demonstrate our improved methodology by exploring relationships between Twitter posts by German members of parliament (MPs) and different metadata covariates.
Helping users discover perspectives: Enhancing opinion mining with joint topic models
Oct 23, 2020

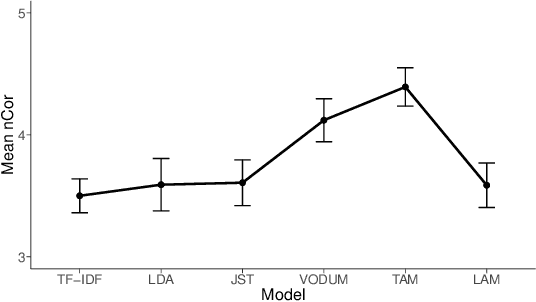
Support or opposition concerning a debated claim such as abortion should be legal can have different underlying reasons, which we call perspectives. This paper explores how opinion mining can be enhanced with joint topic modeling, to identify distinct perspectives within the topic, providing an informative overview from unstructured text. We evaluate four joint topic models (TAM, JST, VODUM, and LAM) in a user study assessing human understandability of the extracted perspectives. Based on the results, we conclude that joint topic models such as TAM can discover perspectives that align with human judgments. Moreover, our results suggest that users are not influenced by their pre-existing stance on the topic of abortion when interpreting the output of topic models.
Restoring and Mining the Records of the Joseon Dynasty via Neural Language Modeling and Machine Translation
Apr 14, 2021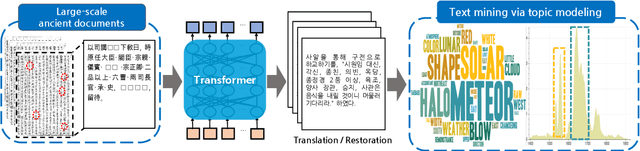
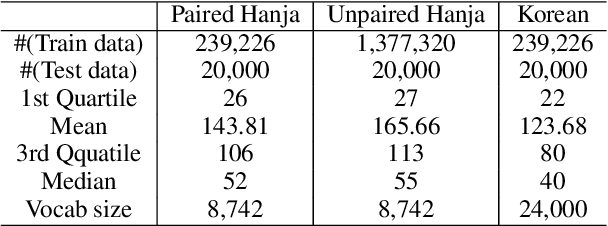


Understanding voluminous historical records provides clues on the past in various aspects, such as social and political issues and even natural science facts. However, it is generally difficult to fully utilize the historical records, since most of the documents are not written in a modern language and part of the contents are damaged over time. As a result, restoring the damaged or unrecognizable parts as well as translating the records into modern languages are crucial tasks. In response, we present a multi-task learning approach to restore and translate historical documents based on a self-attention mechanism, specifically utilizing two Korean historical records, ones of the most voluminous historical records in the world. Experimental results show that our approach significantly improves the accuracy of the translation task than baselines without multi-task learning. In addition, we present an in-depth exploratory analysis on our translated results via topic modeling, uncovering several significant historical events.
Topic Modeling based on Keywords and Context
Feb 03, 2018Current topic models often suffer from discovering topics not matching human intuition, unnatural switching of topics within documents and high computational demands. We address these concerns by proposing a topic model and an inference algorithm based on automatically identifying characteristic keywords for topics. Keywords influence topic-assignments of nearby words. Our algorithm learns (key)word-topic scores and it self-regulates the number of topics. Inference is simple and easily parallelizable. Qualitative analysis yields comparable results to state-of-the-art models (eg. LDA), but with different strengths and weaknesses. Quantitative analysis using 9 datasets shows gains in terms of classification accuracy, PMI score, computational performance and consistency of topic assignments within documents, while most often using less topics.
Improving Reliability of Latent Dirichlet Allocation by Assessing Its Stability Using Clustering Techniques on Replicated Runs
Feb 14, 2020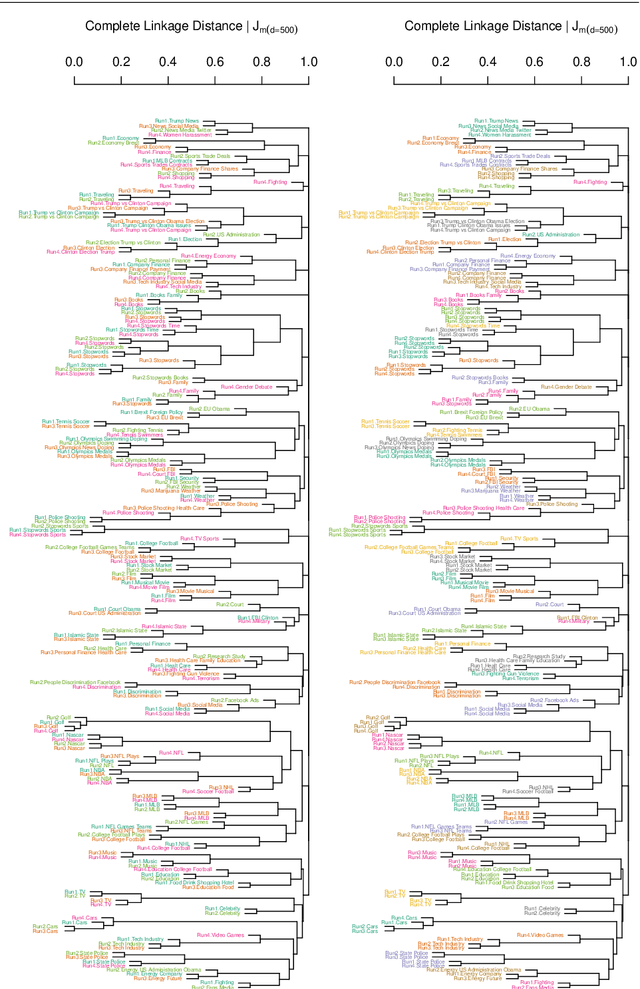
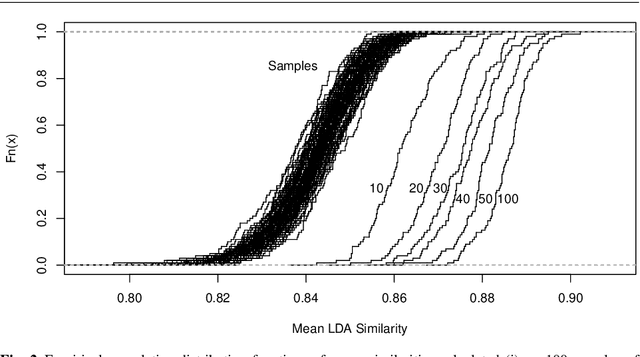
For organizing large text corpora topic modeling provides useful tools. A widely used method is Latent Dirichlet Allocation (LDA), a generative probabilistic model which models single texts in a collection of texts as mixtures of latent topics. The assignments of words to topics rely on initial values such that generally the outcome of LDA is not fully reproducible. In addition, the reassignment via Gibbs Sampling is based on conditional distributions, leading to different results in replicated runs on the same text data. This fact is often neglected in everyday practice. We aim to improve the reliability of LDA results. Therefore, we study the stability of LDA by comparing assignments from replicated runs. We propose to quantify the similarity of two generated topics by a modified Jaccard coefficient. Using such similarities, topics can be clustered. A new pruning algorithm for hierarchical clustering results based on the idea that two LDA runs create pairs of similar topics is proposed. This approach leads to the new measure S-CLOP ({\bf S}imilarity of multiple sets by {\bf C}lustering with {\bf LO}cal {\bf P}runing) for quantifying the stability of LDA models. We discuss some characteristics of this measure and illustrate it with an application to real data consisting of newspaper articles from \textit{USA Today}. Our results show that the measure S-CLOP is useful for assessing the stability of LDA models or any other topic modeling procedure that characterize its topics by word distributions. Based on the newly proposed measure for LDA stability, we propose a method to increase the reliability and hence to improve the reproducibility of empirical findings based on topic modeling. This increase in reliability is obtained by running the LDA several times and taking as prototype the most representative run, that is the LDA run with highest average similarity to all other runs.
Towards Better Understanding with Uniformity and Explicit Regularization of Embeddings in Embedding-based Neural Topic Models
Jun 16, 2022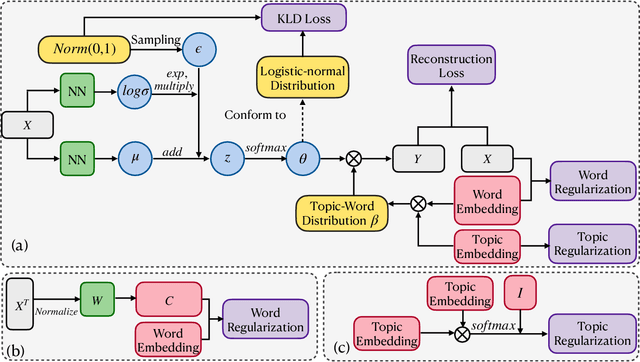
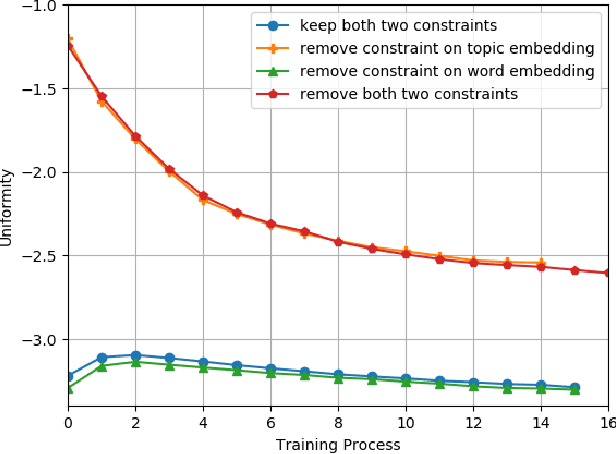
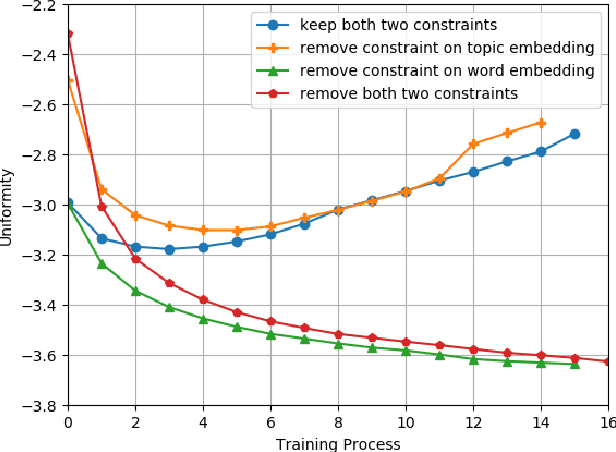
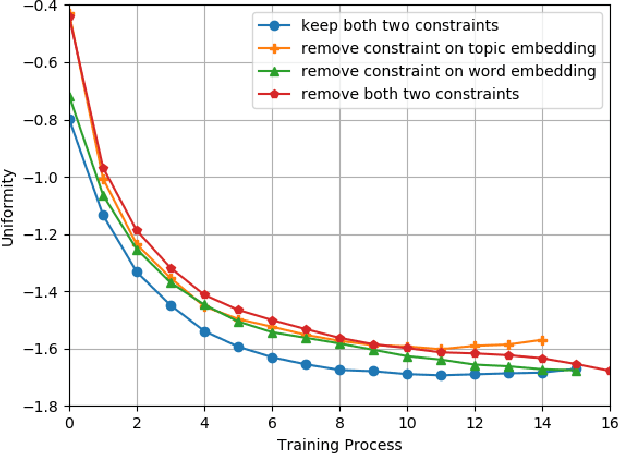
Embedding-based neural topic models could explicitly represent words and topics by embedding them to a homogeneous feature space, which shows higher interpretability. However, there are no explicit constraints for the training of embeddings, leading to a larger optimization space. Also, a clear description of the changes in embeddings and the impact on model performance is still lacking. In this paper, we propose an embedding regularized neural topic model, which applies the specially designed training constraints on word embedding and topic embedding to reduce the optimization space of parameters. To reveal the changes and roles of embeddings, we introduce \textbf{uniformity} into the embedding-based neural topic model as the evaluation metric of embedding space. On this basis, we describe how embeddings tend to change during training via the changes in the uniformity of embeddings. Furthermore, we demonstrate the impact of changes in embeddings in embedding-based neural topic models through ablation studies. The results of experiments on two mainstream datasets indicate that our model significantly outperforms baseline models in terms of the harmony between topic quality and document modeling. This work is the first attempt to exploit uniformity to explore changes in embeddings of embedding-based neural topic models and their impact on model performance to the best of our knowledge.
Exploring the social influence of Kaggle virtual community on the M5 competition
Feb 28, 2021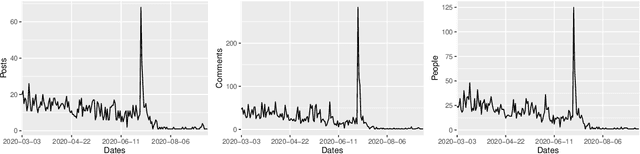
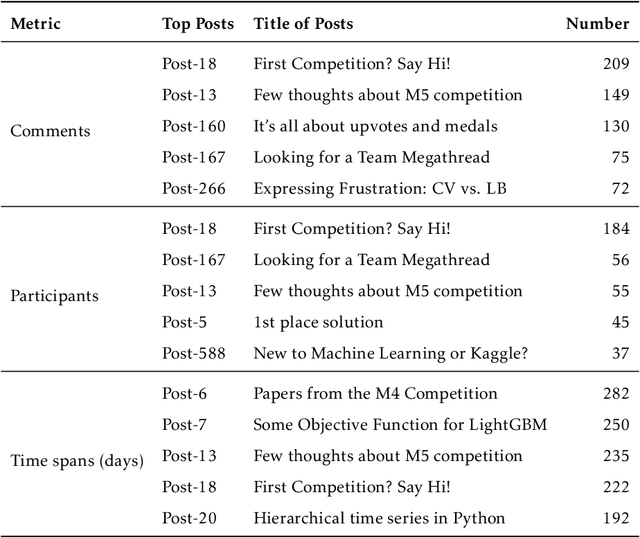

One of the most significant differences of M5 over previous forecasting competitions is that it was held on Kaggle, an online community of data scientists and machine learning practitioners. On the Kaggle platform, people can form virtual communities such as online notebooks and discussions to discuss their models, choice of features, loss functions, etc. This paper aims to study the social influence of virtual communities on the competition. We first study the content of the M5 virtual community by topic modeling and trend analysis. Further, we perform social media analysis to identify the potential relationship network of the virtual community. We find some key roles in the network and study their roles in spreading the LightGBM related information within the network. Overall, this study provides in-depth insights into the dynamic mechanism of the virtual community influence on the participants and has potential implications for future online competitions.
SCAT: Second Chance Autoencoder for Textual Data
May 11, 2020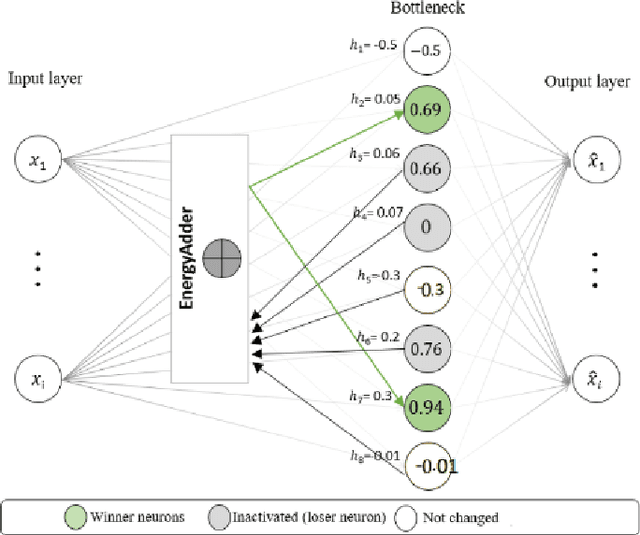
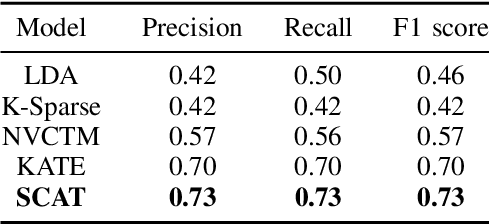
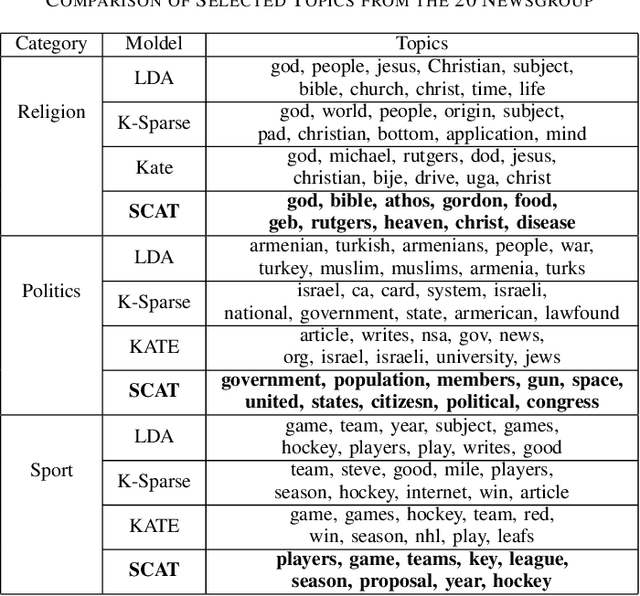
We present a k-competitive learning approach for textual autoencoders named Second Chance Autoencoder (SCAT). SCAT selects the $k$ largest and smallest positive activations as the winner neurons, which gain the activation values of the loser neurons during the learning process, and thus focus on retrieving well-representative features for topics. Our experiments show that SCAT achieves outstanding performance in classification, topic modeling, and document visualization compared to LDA, K-Sparse, NVCTM, and KATE.
Covid-19 Discourse on Twitter: How the Topics, Sentiments, Subjectivity, and Figurative Frames Changed Over Time
Mar 16, 2021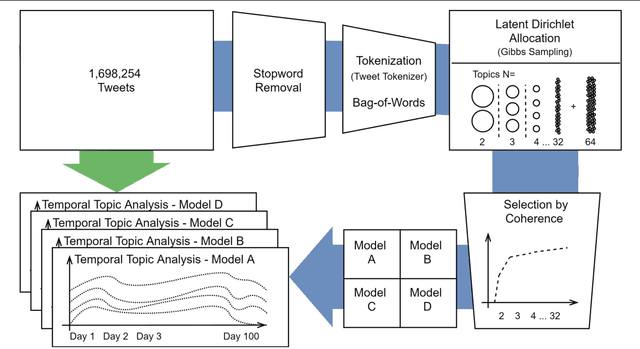

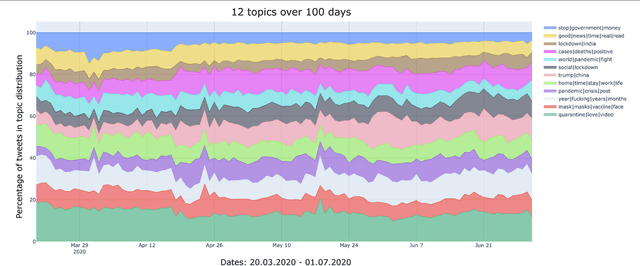
The words we use to talk about the current epidemiological crisis on social media can inform us on how we are conceptualizing the pandemic and how we are reacting to its development. This paper provides an extensive explorative analysis of how the discourse about Covid-19 reported on Twitter changes through time, focusing on the first wave of this pandemic. Based on an extensive corpus of tweets (produced between 20th March and 1st July 2020) first we show how the topics associated with the development of the pandemic changed through time, using topic modeling. Second, we show how the sentiment polarity of the language used in the tweets changed from a relatively positive valence during the first lockdown, toward a more negative valence in correspondence with the reopening. Third we show how the average subjectivity of the tweets increased linearly and fourth, how the popular and frequently used figurative frame of WAR changed when real riots and fights entered the discourse.