 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
Evaluating Sensitivity to the Stick-Breaking Prior in Bayesian Nonparametrics
Jul 08, 2021
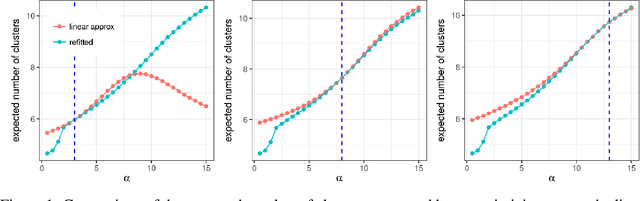
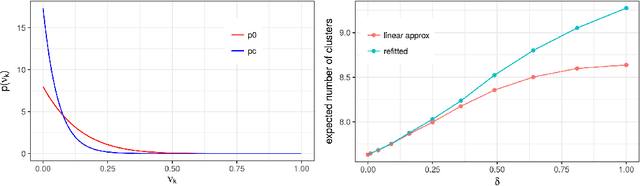
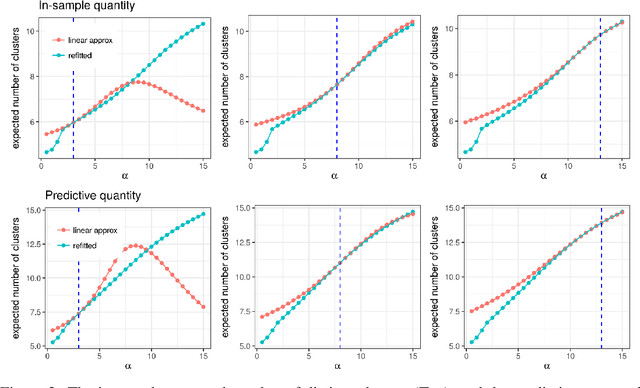
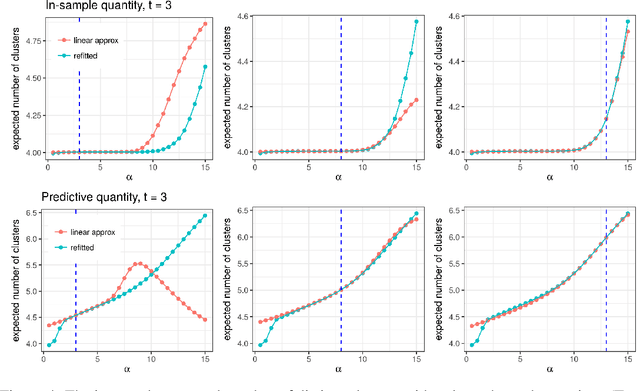
Bayesian models based on the Dirichlet process and other stick-breaking priors have been proposed as core ingredients for clustering, topic modeling, and other unsupervised learning tasks. Prior specification is, however, relatively difficult for such models, given that their flexibility implies that the consequences of prior choices are often relatively opaque. Moreover, these choices can have a substantial effect on posterior inferences. Thus, considerations of robustness need to go hand in hand with nonparametric modeling. In the current paper, we tackle this challenge by exploiting the fact that variational Bayesian methods, in addition to having computational advantages in fitting complex nonparametric models, also yield sensitivities with respect to parametric and nonparametric aspects of Bayesian models. In particular, we demonstrate how to assess the sensitivity of conclusions to the choice of concentration parameter and stick-breaking distribution for inferences under Dirichlet process mixtures and related mixture models. We provide both theoretical and empirical support for our variational approach to Bayesian sensitivity analysis.
Personalized, Health-Aware Recipe Recommendation: An Ensemble Topic Modeling Based Approach
Jul 31, 2019
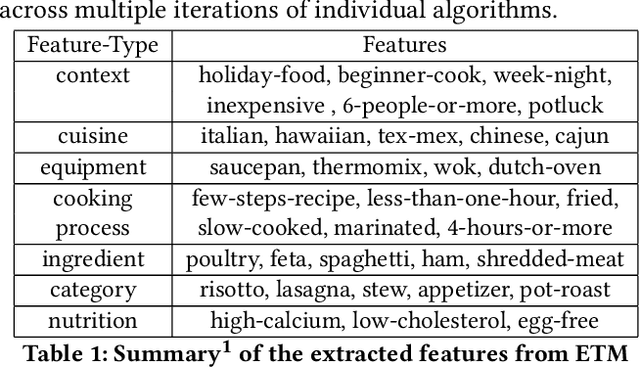
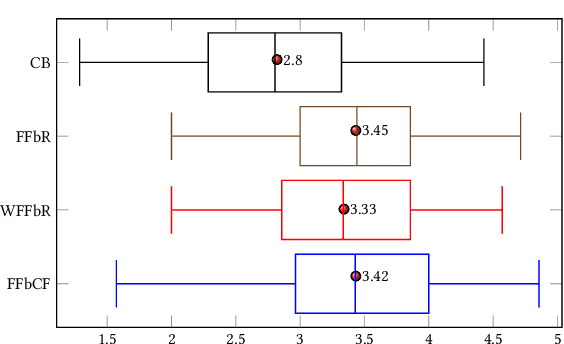
Food choices are personal and complex and have a significant impact on our long-term health and quality of life. By helping users to make informed and satisfying decisions, Recommender Systems (RS) have the potential to support users in making healthier food choices. Intelligent users-modeling is a key challenge in achieving this potential. This paper investigates Ensemble Topic Modelling (EnsTM) based Feature Identification techniques for efficient user-modeling and recipe recommendation. It builds on findings in EnsTM to propose a reduced data representation format and a smart user-modeling strategy that makes capturing user-preference fast, efficient and interactive. This approach enables personalization, even in a cold-start scenario. This paper proposes two different EnsTM based and one Hybrid EnsTM based recommenders. We compared all three EnsTM based variations through a user study with 48 participants, using a large-scale,real-world corpus of 230,876 recipes, and compare against a conventional Content Based (CB) approach. EnsTM based recommenders performed significantly better than the CB approach. Besides acknowledging multi-domain contents such as taste, demographics and cost, our proposed approach also considers user's nutritional preference and assists them finding recipes under diverse nutritional categories. Furthermore, it provides excellent coverage and enables implicit understanding of user's food practices. Subsequent analysis also exposed correlation between certain features and a healthier lifestyle.
FLATM: A Fuzzy Logic Approach Topic Model for Medical Documents
Nov 25, 2019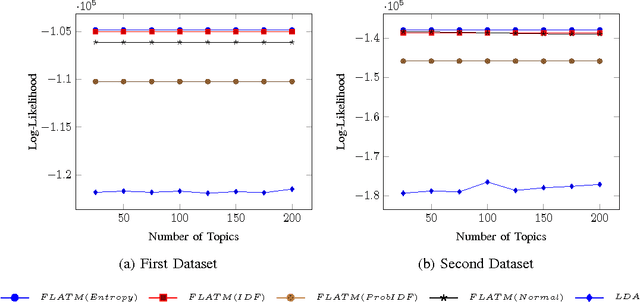
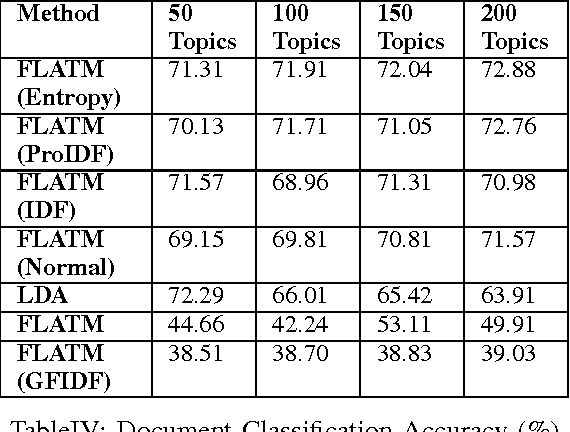
One of the challenges for text analysis in medical domains is analyzing large-scale medical documents. As a consequence, finding relevant documents has become more difficult. One of the popular methods to retrieve information based on discovering the themes in the documents is topic modeling. The themes in the documents help to retrieve documents on the same topic with and without a query. In this paper, we present a novel approach to topic modeling using fuzzy clustering. To evaluate our model, we experiment with two text datasets of medical documents. The evaluation metrics carried out through document classification and document modeling show that our model produces better performance than LDA, indicating that fuzzy set theory can improve the performance of topic models in medical domains.
Variational Gaussian Topic Model with Invertible Neural Projections
May 21, 2021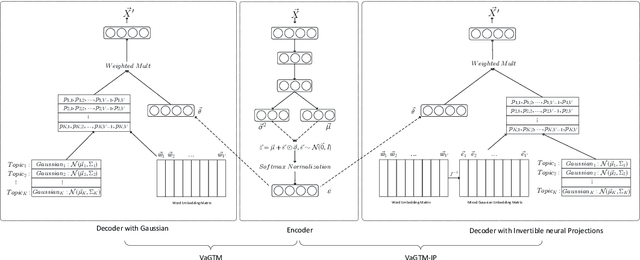
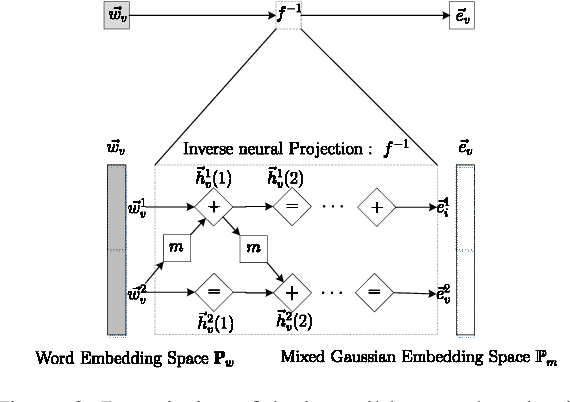
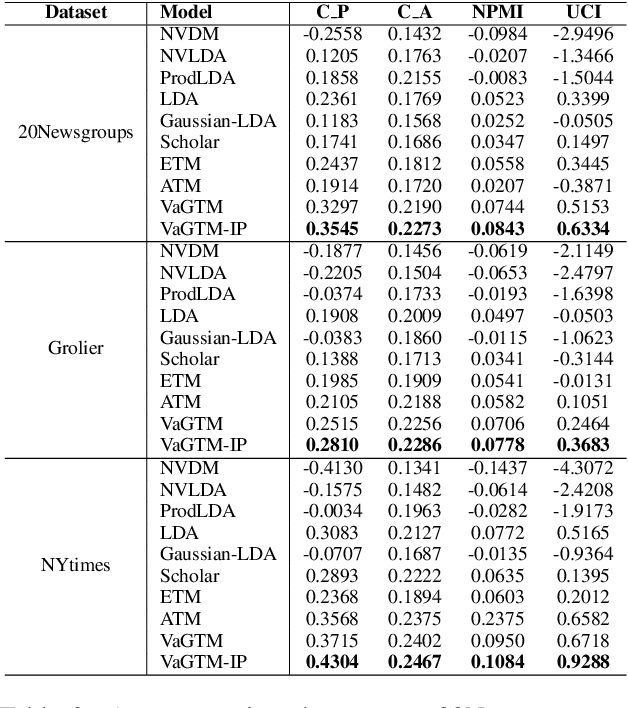
Neural topic models have triggered a surge of interest in extracting topics from text automatically since they avoid the sophisticated derivations in conventional topic models. However, scarce neural topic models incorporate the word relatedness information captured in word embedding into the modeling process. To address this issue, we propose a novel topic modeling approach, called Variational Gaussian Topic Model (VaGTM). Based on the variational auto-encoder, the proposed VaGTM models each topic with a multivariate Gaussian in decoder to incorporate word relatedness. Furthermore, to address the limitation that pre-trained word embeddings of topic-associated words do not follow a multivariate Gaussian, Variational Gaussian Topic Model with Invertible neural Projections (VaGTM-IP) is extended from VaGTM. Three benchmark text corpora are used in experiments to verify the effectiveness of VaGTM and VaGTM-IP. The experimental results show that VaGTM and VaGTM-IP outperform several competitive baselines and obtain more coherent topics.
Deep Learning for Choice Modeling
Aug 19, 2022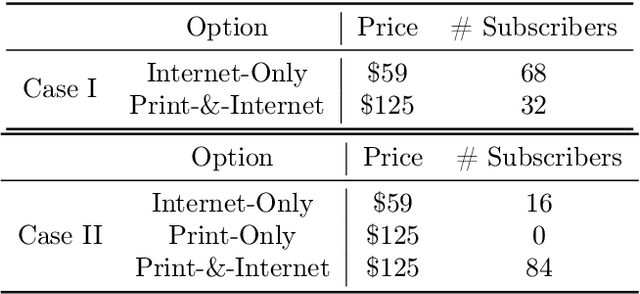
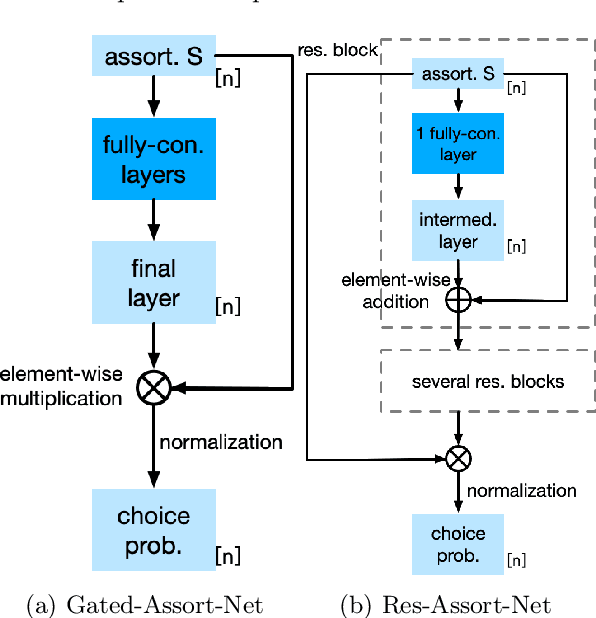
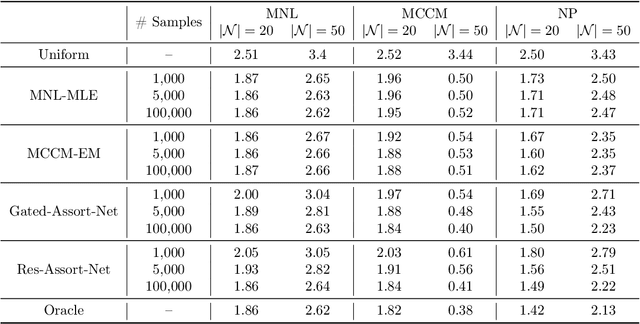
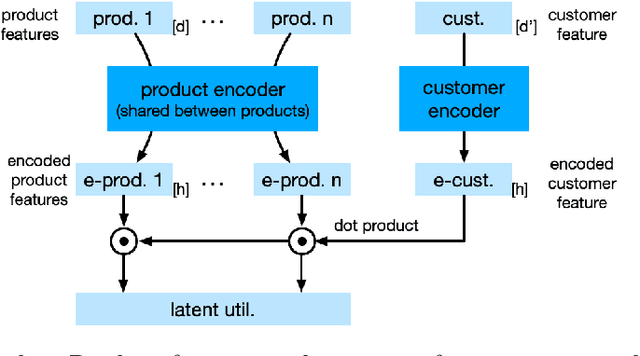
Choice modeling has been a central topic in the study of individual preference or utility across many fields including economics, marketing, operations research, and psychology. While the vast majority of the literature on choice models has been devoted to the analytical properties that lead to managerial and policy-making insights, the existing methods to learn a choice model from empirical data are often either computationally intractable or sample inefficient. In this paper, we develop deep learning-based choice models under two settings of choice modeling: (i) feature-free and (ii) feature-based. Our model captures both the intrinsic utility for each candidate choice and the effect that the assortment has on the choice probability. Synthetic and real data experiments demonstrate the performances of proposed models in terms of the recovery of the existing choice models, sample complexity, assortment effect, architecture design, and model interpretation.
Deep Sequence Models for Text Classification Tasks
Jul 18, 2022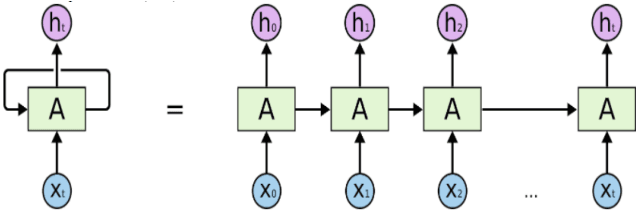
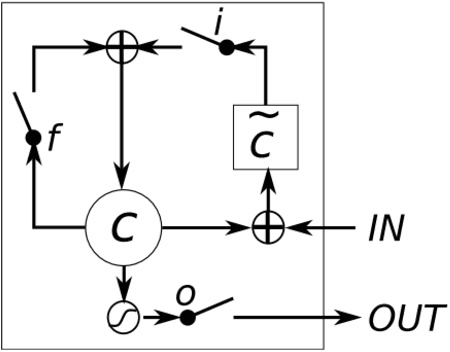
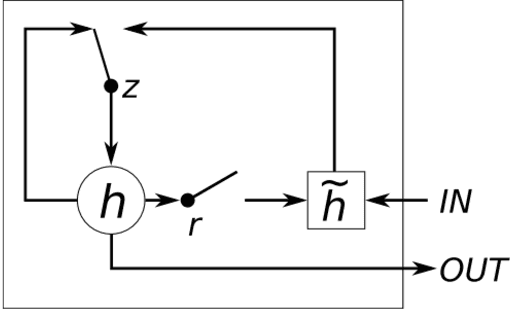
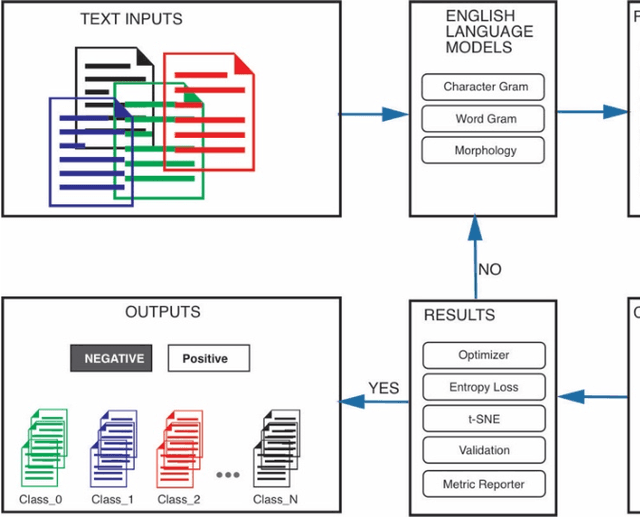
The exponential growth of data generated on the Internet in the current information age is a driving force for the digital economy. Extraction of information is the major value in an accumulated big data. Big data dependency on statistical analysis and hand-engineered rules machine learning algorithms are overwhelmed with vast complexities inherent in human languages. Natural Language Processing (NLP) is equipping machines to understand these human diverse and complicated languages. Text Classification is an NLP task which automatically identifies patterns based on predefined or undefined labeled sets. Common text classification application includes information retrieval, modeling news topic, theme extraction, sentiment analysis, and spam detection. In texts, some sequences of words depend on the previous or next word sequences to make full meaning; this is a challenging dependency task that requires the machine to be able to store some previous important information to impact future meaning. Sequence models such as RNN, GRU, and LSTM is a breakthrough for tasks with long-range dependencies. As such, we applied these models to Binary and Multi-class classification. Results generated were excellent with most of the models performing within the range of 80% and 94%. However, this result is not exhaustive as we believe there is room for improvement if machines are to compete with humans.
Investigating Health-Aware Smart-Nudging with Machine Learning to Help People Pursue Healthier Eating-Habits
Oct 05, 2021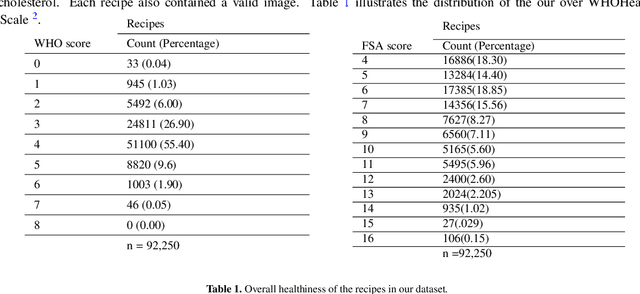

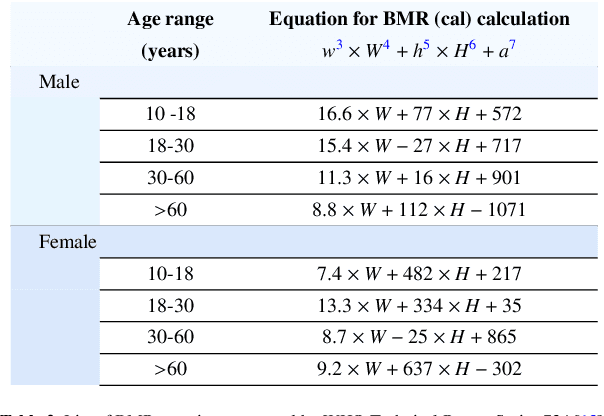

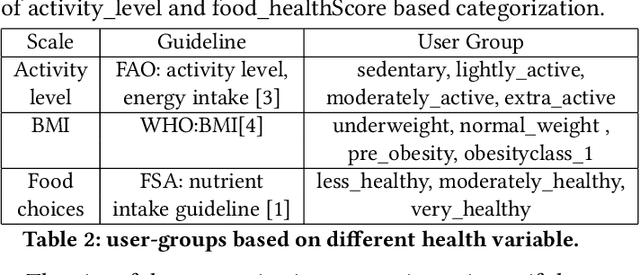
Food-choices and eating-habits directly contribute to our long-term health. This makes the food recommender system a potential tool to address the global crisis of obesity and malnutrition. Over the past decade, artificial-intelligence and medical researchers became more invested in researching tools that can guide and help people make healthy and thoughtful decisions around food and diet. In many typical (Recommender System) RS domains, smart nudges have been proven effective in shaping users' consumption patterns. In recent years, knowledgeable nudging and incentifying choices started getting attention in the food domain as well. To develop smart nudging for promoting healthier food choices, we combined Machine Learning and RS technology with food-healthiness guidelines from recognized health organizations, such as the World Health Organization, Food Standards Agency, and the National Health Service United Kingdom. In this paper, we discuss our research on, persuasive visualization for making users aware of the healthiness of the recommended recipes. Here, we propose three novel nudging technology, the WHO-BubbleSlider, the FSA-ColorCoading, and the DRCI-MLCP, that encourage users to choose healthier recipes. We also propose a Topic Modeling based portion-size recommendation algorithm. To evaluate our proposed smart-nudges, we conducted an online user study with 96 participants and 92250 recipes. Results showed that, during the food decision-making process, appropriate healthiness cues make users more likely to click, browse, and choose healthier recipes over less healthy ones.
MigrationsKB: A Knowledge Base of Public Attitudes towards Migrations and their Driving Factors
Aug 17, 2021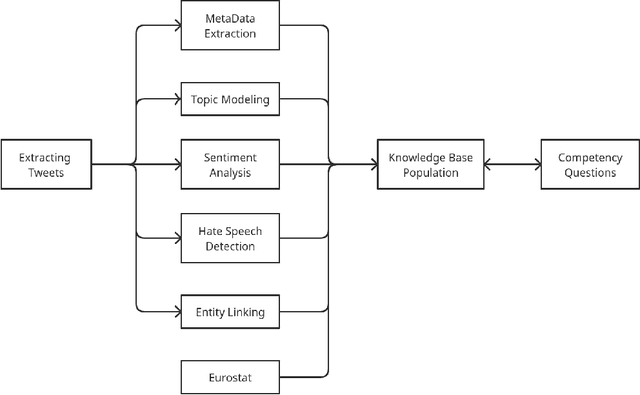
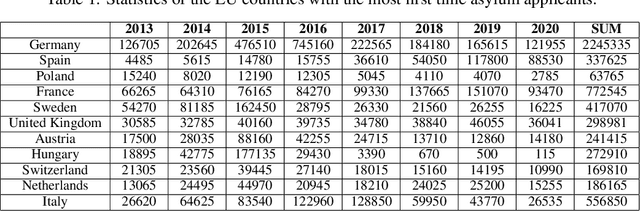

With the increasing trend in the topic of migration in Europe, the public is now more engaged in expressing their opinions through various platforms such as Twitter. Understanding the online discourses is therefore essential to capture the public opinion. The goal of this study is the analysis of social media platform to quantify public attitudes towards migrations and the identification of different factors causing these attitudes. The tweets spanning from 2013 to Jul-2021 in the European countries which are hosts to immigrants are collected, pre-processed, and filtered using advanced topic modeling technique. BERT-based entity linking and sentiment analysis, and attention-based hate speech detection are performed to annotate the curated tweets. Moreover, the external databases are used to identify the potential social and economic factors causing negative attitudes of the people about migration. To further promote research in the interdisciplinary fields of social science and computer science, the outcomes are integrated into a Knowledge Base (KB), i.e., MigrationsKB which significantly extends the existing models to take into account the public attitudes towards migrations and the economic indicators. This KB is made public using FAIR principles, which can be queried through SPARQL endpoint. Data dumps are made available on Zenodo.
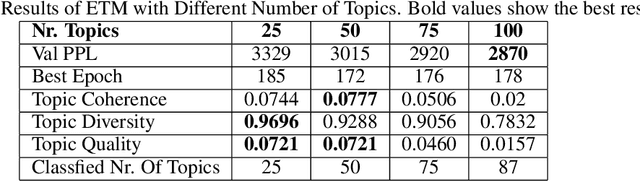
An Online Topic Modeling Framework with Topics Automatically Labeled
Jun 22, 2019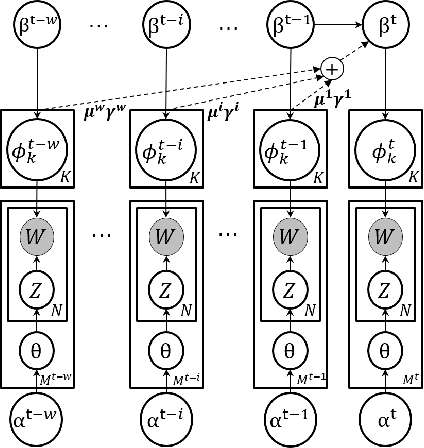
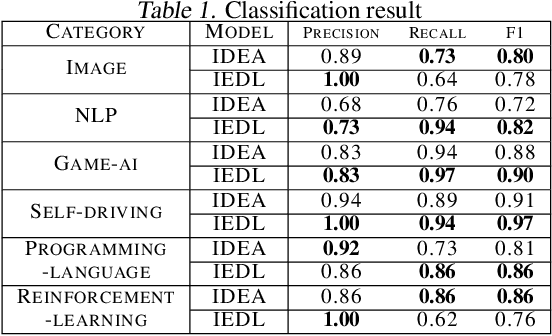
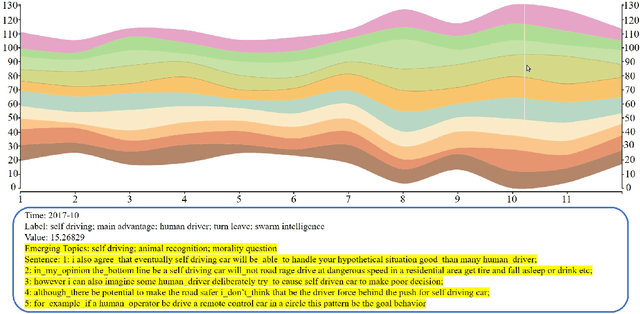
In this paper, we propose a novel online topic tracking framework, named IEDL, for tracking the topic changes related to deep learning techniques on Stack Exchange and automatically interpreting each identified topic. The proposed framework combines the prior topic distributions in a time window during inferring the topics in current time slice, and introduces a new ranking scheme to select most representative phrases and sentences for the inferred topics in each time slice. Experiments on 7,076 Stack Exchange posts show the effectiveness of IEDL in tracking topic changes and labeling topics.
Restoring and Mining the Records of the Joseon Dynasty via Neural Language Modeling and Machine Translation
May 07, 2021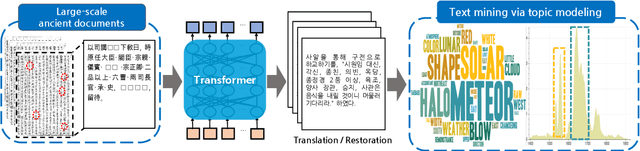
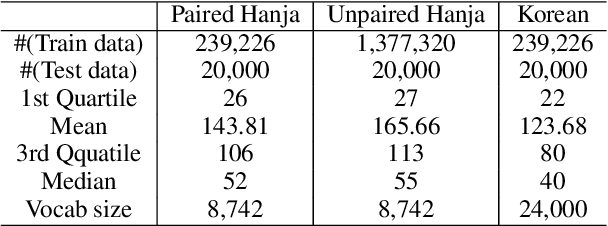


Understanding voluminous historical records provides clues on the past in various aspects, such as social and political issues and even natural science facts. However, it is generally difficult to fully utilize the historical records, since most of the documents are not written in a modern language and part of the contents are damaged over time. As a result, restoring the damaged or unrecognizable parts as well as translating the records into modern languages are crucial tasks. In response, we present a multi-task learning approach to restore and translate historical documents based on a self-attention mechanism, specifically utilizing two Korean historical records, ones of the most voluminous historical records in the world. Experimental results show that our approach significantly improves the accuracy of the translation task than baselines without multi-task learning. In addition, we present an in-depth exploratory analysis on our translated results via topic modeling, uncovering several significant historical events.