 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
JST-RR Model: Joint Modeling of Ratings and Reviews in Sentiment-Topic Prediction
Feb 18, 2021

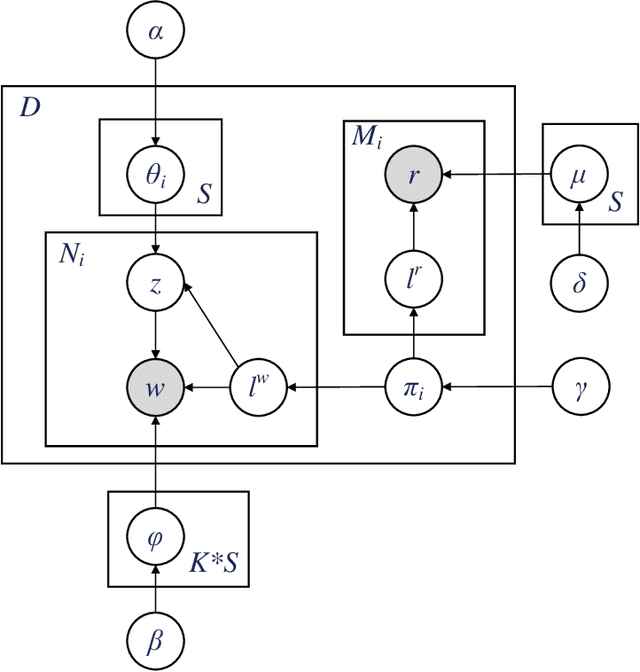

Analysis of online reviews has attracted great attention with broad applications. Often times, the textual reviews are coupled with the numerical ratings in the data. In this work, we propose a probabilistic model to accommodate both textual reviews and overall ratings with consideration of their intrinsic connection for a joint sentiment-topic prediction. The key of the proposed method is to develop a unified generative model where the topic modeling is constructed based on review texts and the sentiment prediction is obtained by combining review texts and overall ratings. The inference of model parameters are obtained by an efficient Gibbs sampling procedure. The proposed method can enhance the prediction accuracy of review data and achieve an effective detection of interpretable topics and sentiments. The merits of the proposed method are elaborated by the case study from Amazon datasets and simulation studies.
Auto-Encoding Variational Bayes for Inferring Topics and Visualization
Oct 25, 2020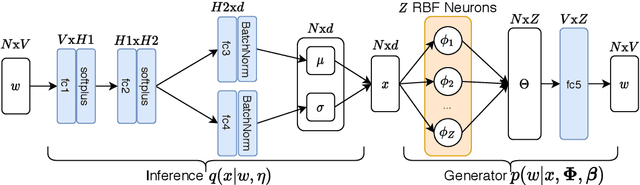



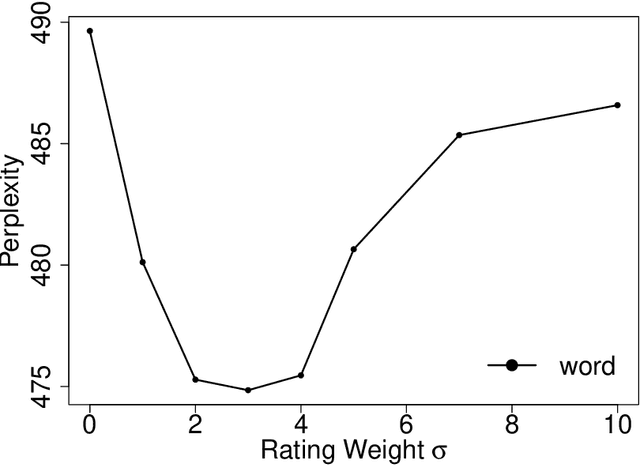
Visualization and topic modeling are widely used approaches for text analysis. Traditional visualization methods find low-dimensional representations of documents in the visualization space (typically 2D or 3D) that can be displayed using a scatterplot. In contrast, topic modeling aims to discover topics from text, but for visualization, one needs to perform a post-hoc embedding using dimensionality reduction methods. Recent approaches propose using a generative model to jointly find topics and visualization, allowing the semantics to be infused in the visualization space for a meaningful interpretation. A major challenge that prevents these methods from being used practically is the scalability of their inference algorithms. We present, to the best of our knowledge, the first fast Auto-Encoding Variational Bayes based inference method for jointly inferring topics and visualization. Since our method is black box, it can handle model changes efficiently with little mathematical rederivation effort. We demonstrate the efficiency and effectiveness of our method on real-world large datasets and compare it with existing baselines.
TeCoMiner: Topic Discovery Through Term Community Detection
Mar 23, 2021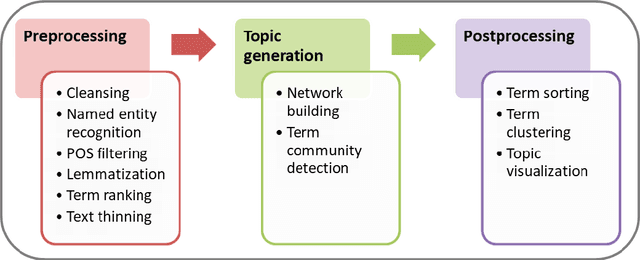
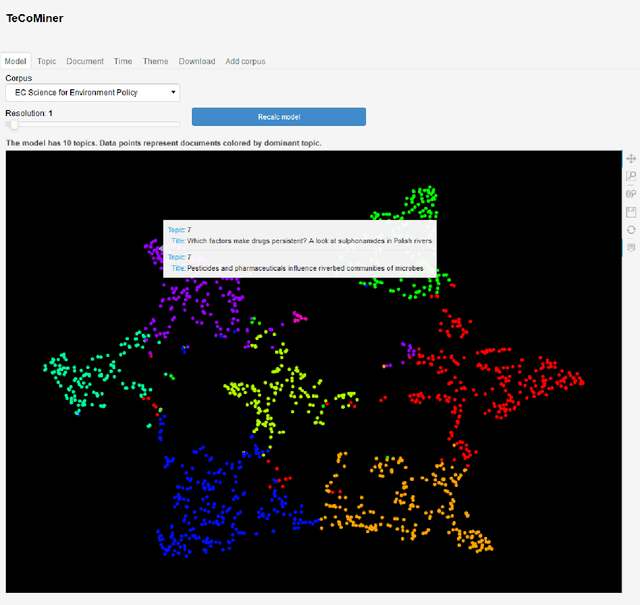
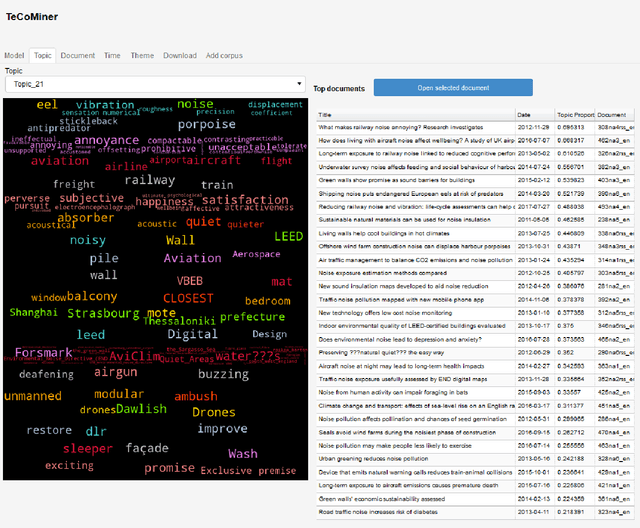
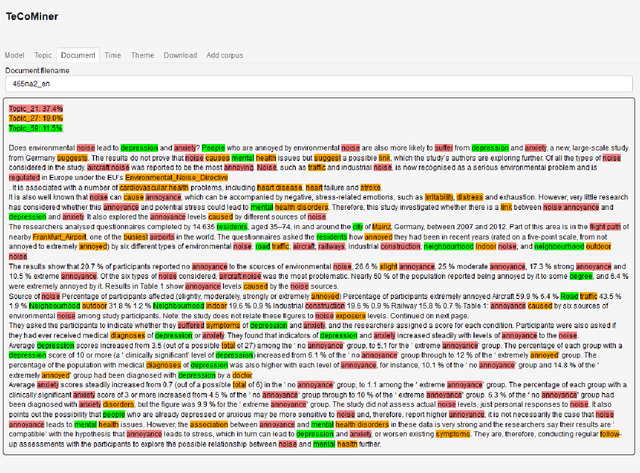
This note is a short description of TeCoMiner, an interactive tool for exploring the topic content of text collections. Unlike other topic modeling tools, TeCoMiner is not based on some generative probabilistic model but on topological considerations about co-occurrence networks of terms. We outline the methods used for identifying topics, describe the features of the tool, and sketch an application, using a corpus of policy related scientific news on environmental issues published by the European Commission over the last decade.
Effective user intent mining with unsupervised word representation models and topic modelling
Sep 04, 2021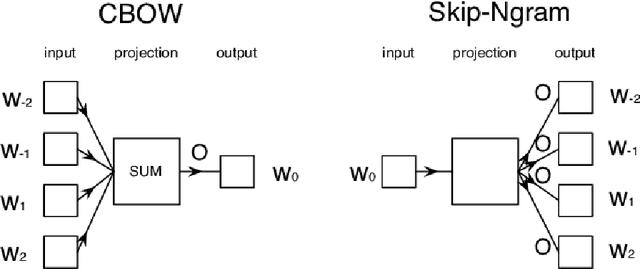
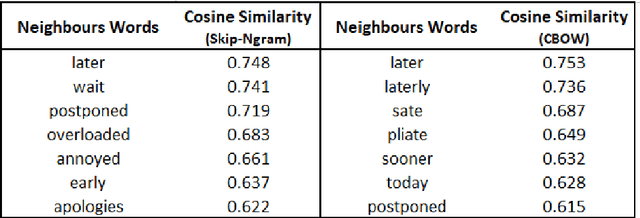
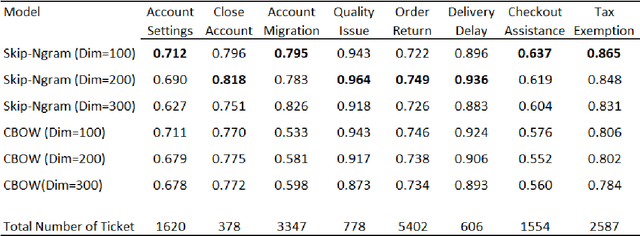
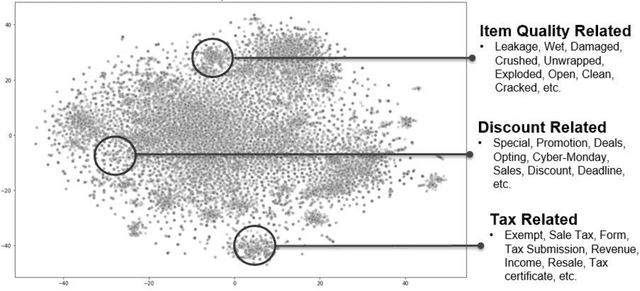
Understanding the intent behind chat between customers and customer service agents has become a crucial problem nowadays due to an exponential increase in the use of the Internet by people from different cultures and educational backgrounds. More importantly, the explosion of e-commerce has led to a significant increase in text conversation between customers and agents. In this paper, we propose an approach to data mining the conversation intents behind the textual data. Using the customer service data set, we train unsupervised text representation models, and then develop an intent mapping model which would rank the predefined intents base on cosine similarity between sentences and intents. Topic-modeling techniques are used to define intents and domain experts are also involved to interpret topic modelling results. With this approach, we can get a good understanding of the user intentions behind the unlabelled customer service textual data.
ImageArg: A Multi-modal Tweet Dataset for Image Persuasiveness Mining
Sep 14, 2022


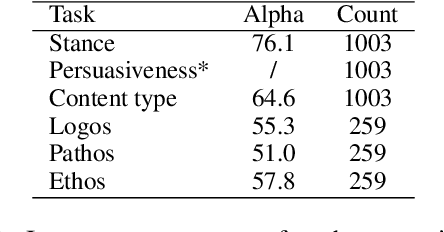
The growing interest in developing corpora of persuasive texts has promoted applications in automated systems, e.g., debating and essay scoring systems; however, there is little prior work mining image persuasiveness from an argumentative perspective. To expand persuasiveness mining into a multi-modal realm, we present a multi-modal dataset, ImageArg, consisting of annotations of image persuasiveness in tweets. The annotations are based on a persuasion taxonomy we developed to explore image functionalities and the means of persuasion. We benchmark image persuasiveness tasks on ImageArg using widely-used multi-modal learning methods. The experimental results show that our dataset offers a useful resource for this rich and challenging topic, and there is ample room for modeling improvement.
Extractive Summarization of Call Transcripts
Mar 19, 2021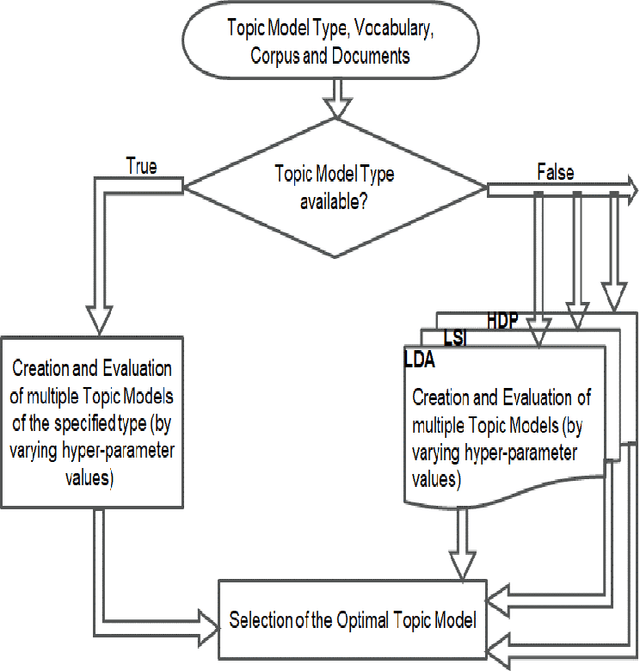
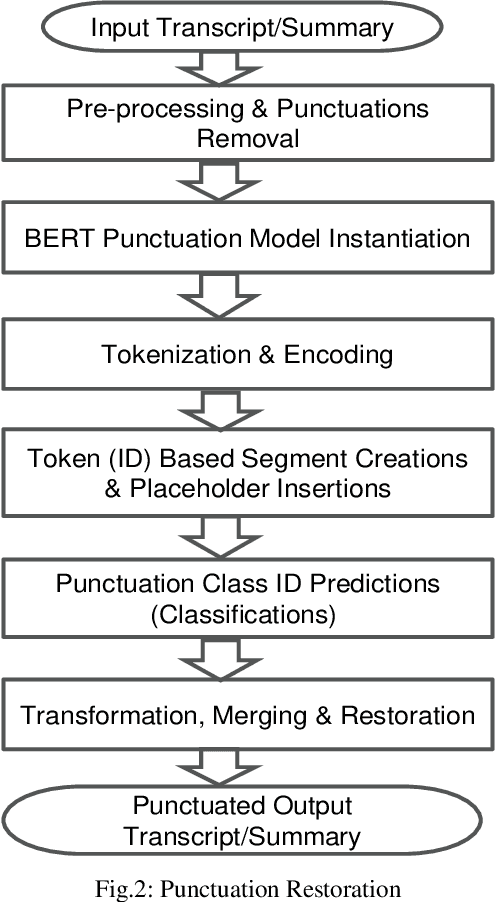
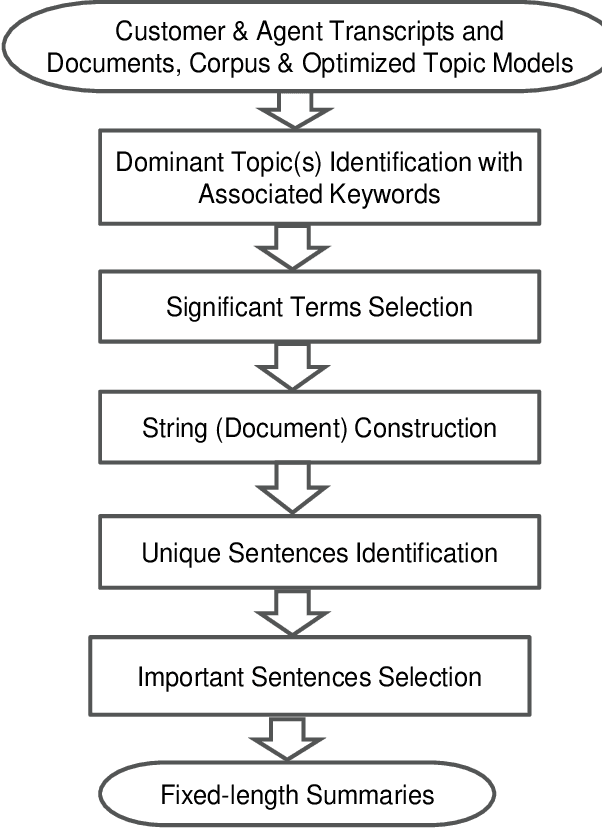
Text summarization is the process of extracting the most important information from the text and presenting it concisely in fewer sentences. Call transcript is a text that involves textual description of a phone conversation between a customer (caller) and agent(s) (customer representatives). This paper presents an indigenously developed method that combines topic modeling and sentence selection with punctuation restoration in condensing ill-punctuated or un-punctuated call transcripts to produce summaries that are more readable. Extensive testing, evaluation and comparisons have demonstrated the efficacy of this summarizer for call transcript summarization.
Lifelong Neural Topic Learning in Contextualized Autoregressive Topic Models of Language via Informative Transfers
Sep 29, 2019
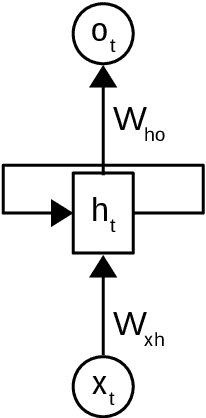
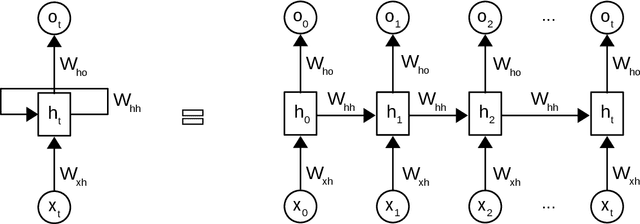
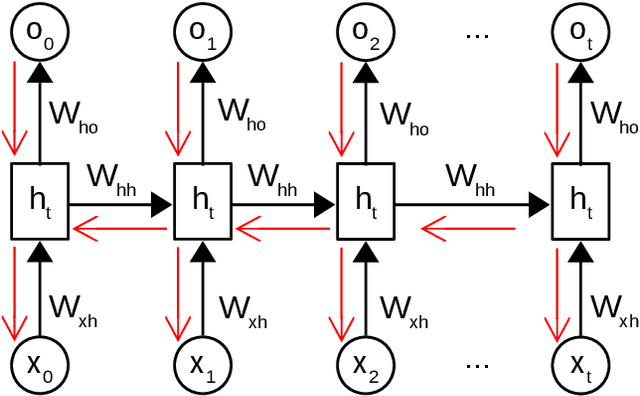
Topic models such as LDA, DocNADE, iDocNADEe have been popular in document analysis. However, the traditional topic models have several limitations including: (1) Bag-of-words (BoW) assumption, where they ignore word ordering, (2) Data sparsity, where the application of topic models is challenging due to limited word co-occurrences, leading to incoherent topics and (3) No Continuous Learning framework for topic learning in lifelong fashion, exploiting historical knowledge (or latent topics) and minimizing catastrophic forgetting. This thesis focuses on addressing the above challenges within neural topic modeling framework. We propose: (1) Contextualized topic model that combines a topic and a language model and introduces linguistic structures (such as word ordering, syntactic and semantic features, etc.) in topic modeling, (2) A novel lifelong learning mechanism into neural topic modeling framework to demonstrate continuous learning in sequential document collections and minimizing catastrophic forgetting. Additionally, we perform a selective data augmentation to alleviate the need for complete historical corpora during data hallucination or replay.
A quantitative and qualitative citation analysis of retracted articles in the humanities
Nov 09, 2021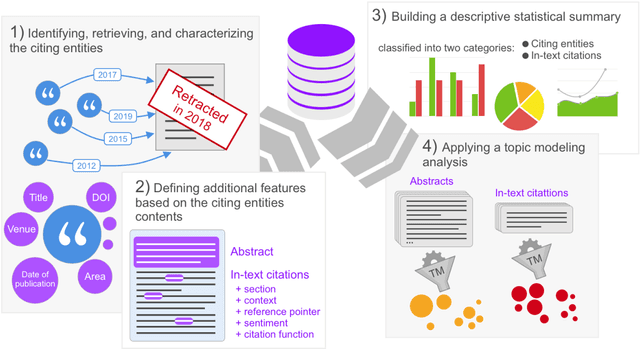
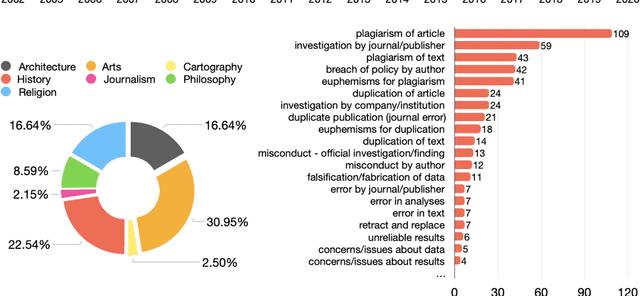
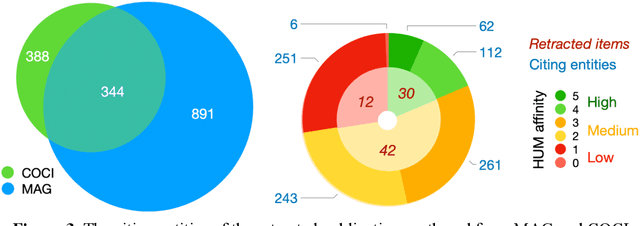
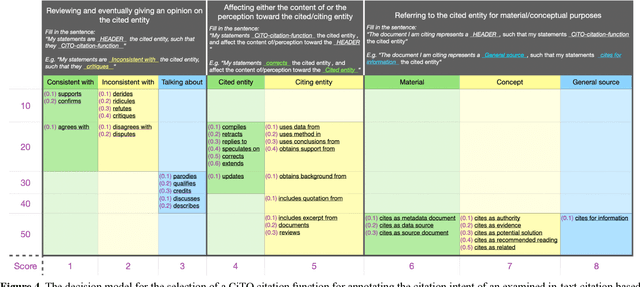
In this article, we show and discuss the results of a quantitative and qualitative analysis of citations to retracted publications in the humanities domain. Our study was conducted by selecting retracted papers in the humanities domain and marking their main characteristics (e.g., retraction reason). Then, we gathered the citing entities and annotated their basic metadata (e.g., title, venue, subject, etc.) and the characteristics of their in-text citations (e.g., intent, sentiment, etc.). Using these data, we performed a quantitative and qualitative study of retractions in the humanities, presenting descriptive statistics and a topic modeling analysis of the citing entities' abstracts and the in-text citation contexts. As part of our main findings, we noticed a continuous increment in the overall number of citations after the retraction year, with few entities which have either mentioned the retraction or expressed a negative sentiment toward the cited entities. In addition, on several occasions we noticed a higher concern and awareness when it was about citing a retracted article, by the citing entities belonging to the health sciences domain, if compared to the humanities and the social sciences domains. Philosophy, arts, and history are the humanities areas that showed the higher concerns toward the retraction.
Contextual Topic Modeling For Dialog Systems
Oct 19, 2018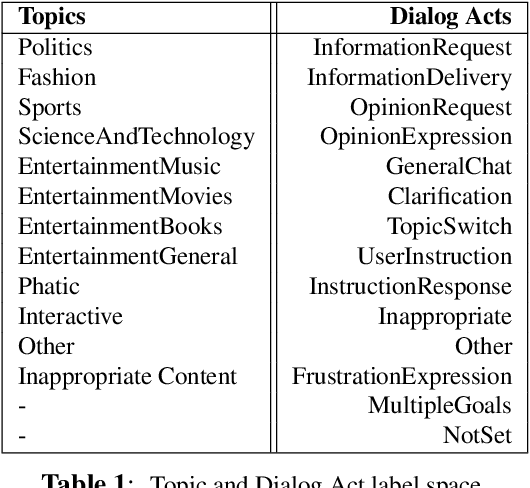
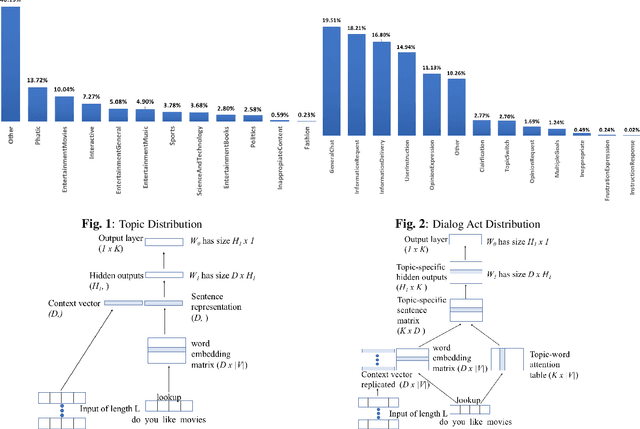

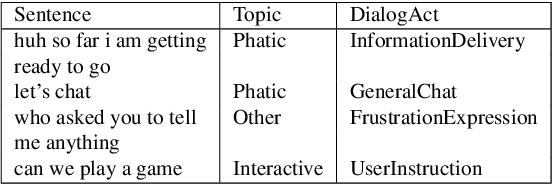
Accurate prediction of conversation topics can be a valuable signal for creating coherent and engaging dialog systems. In this work, we focus on context-aware topic classification methods for identifying topics in free-form human-chatbot dialogs. We extend previous work on neural topic classification and unsupervised topic keyword detection by incorporating conversational context and dialog act features. On annotated data, we show that incorporating context and dialog acts leads to relative gains in topic classification accuracy by 35% and on unsupervised keyword detection recall by 11% for conversational interactions where topics frequently span multiple utterances. We show that topical metrics such as topical depth is highly correlated with dialog evaluation metrics such as coherence and engagement implying that conversational topic models can predict user satisfaction. Our work for detecting conversation topics and keywords can be used to guide chatbots towards coherent dialog.