 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
ET-LDA: Joint Topic Modeling for Aligning Events and their Twitter Feedback
Dec 21, 2012
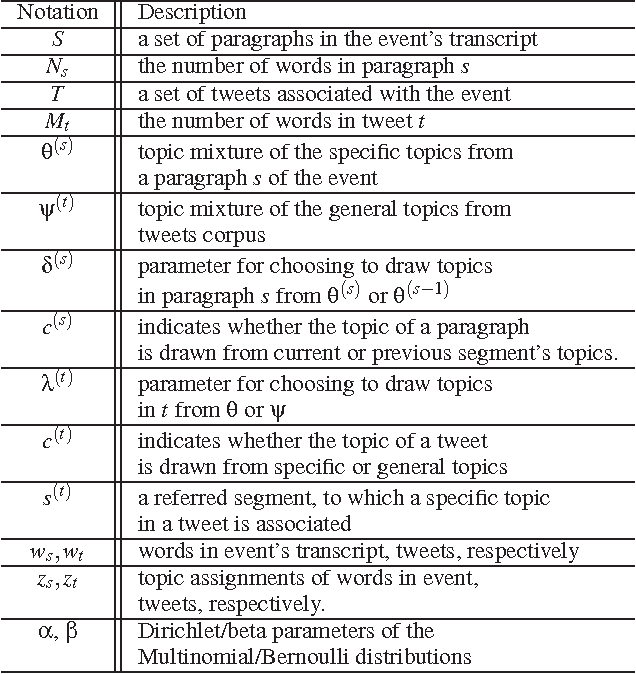
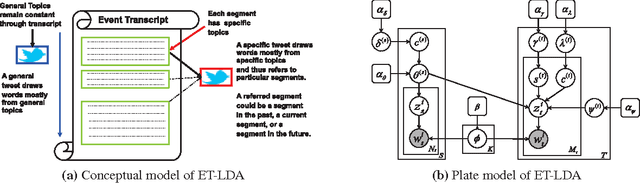
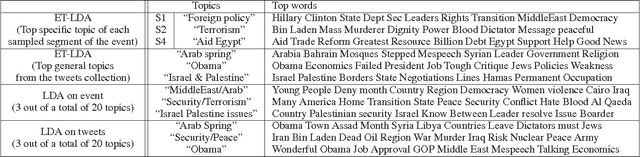

During broadcast events such as the Superbowl, the U.S. Presidential and Primary debates, etc., Twitter has become the de facto platform for crowds to share perspectives and commentaries about them. Given an event and an associated large-scale collection of tweets, there are two fundamental research problems that have been receiving increasing attention in recent years. One is to extract the topics covered by the event and the tweets; the other is to segment the event. So far these problems have been viewed separately and studied in isolation. In this work, we argue that these problems are in fact inter-dependent and should be addressed together. We develop a joint Bayesian model that performs topic modeling and event segmentation in one unified framework. We evaluate the proposed model both quantitatively and qualitatively on two large-scale tweet datasets associated with two events from different domains to show that it improves significantly over baseline models.
An Empirical Study of IoT Security Aspects at Sentence-Level in Developer Textual Discussions
Jun 07, 2022
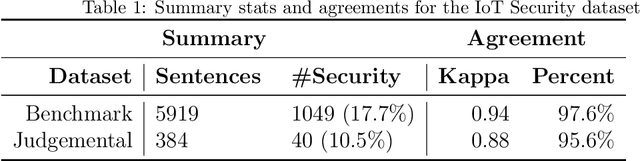
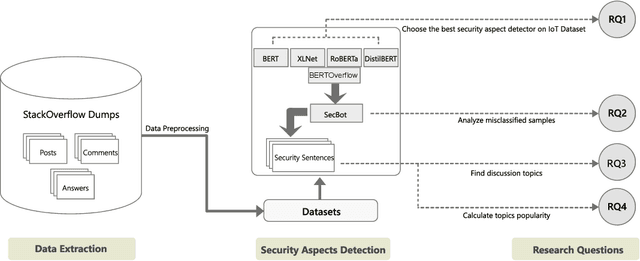
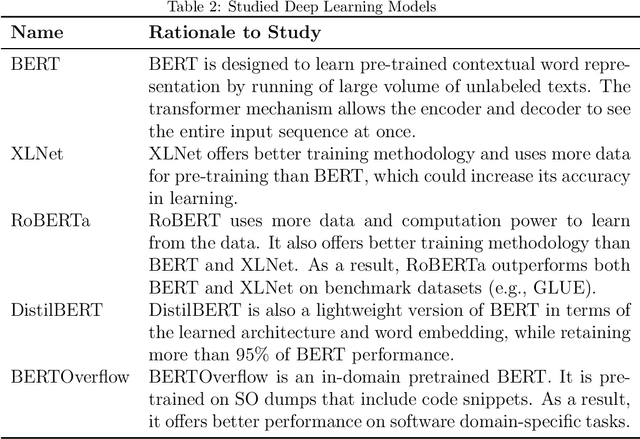
IoT is a rapidly emerging paradigm that now encompasses almost every aspect of our modern life. As such, ensuring the security of IoT devices is crucial. IoT devices can differ from traditional computing, thereby the design and implementation of proper security measures can be challenging in IoT devices. We observed that IoT developers discuss their security-related challenges in developer forums like Stack Overflow(SO). However, we find that IoT security discussions can also be buried inside non-security discussions in SO. In this paper, we aim to understand the challenges IoT developers face while applying security practices and techniques to IoT devices. We have two goals: (1) Develop a model that can automatically find security-related IoT discussions in SO, and (2) Study the model output to learn about IoT developer security-related challenges. First, we download 53K posts from SO that contain discussions about IoT. Second, we manually labeled 5,919 sentences from 53K posts as 1 or 0. Third, we use this benchmark to investigate a suite of deep learning transformer models. The best performing model is called SecBot. Fourth, we apply SecBot on the entire posts and find around 30K security related sentences. Fifth, we apply topic modeling to the security-related sentences. Then we label and categorize the topics. Sixth, we analyze the evolution of the topics in SO. We found that (1) SecBot is based on the retraining of the deep learning model RoBERTa. SecBot offers the best F1-Score of 0.935, (2) there are six error categories in misclassified samples by SecBot. SecBot was mostly wrong when the keywords/contexts were ambiguous (e.g., gateway can be a security gateway or a simple gateway), (3) there are 9 security topics grouped into three categories: Software, Hardware, and Network, and (4) the highest number of topics belongs to software security, followed by network security.
Representing Mixtures of Word Embeddings with Mixtures of Topic Embeddings
Mar 15, 2022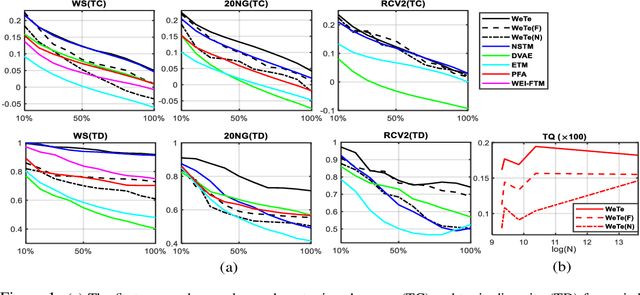
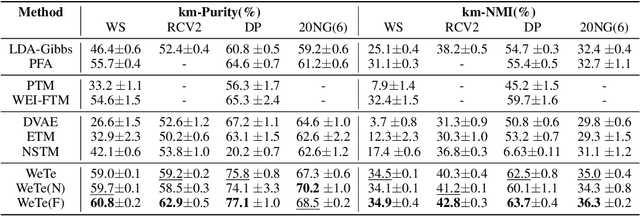
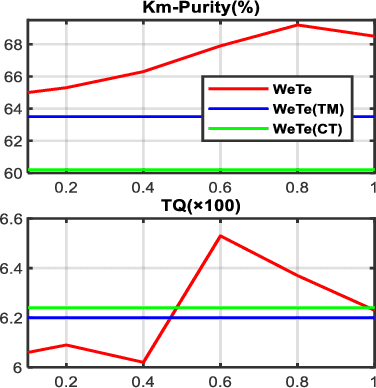

A topic model is often formulated as a generative model that explains how each word of a document is generated given a set of topics and document-specific topic proportions. It is focused on capturing the word co-occurrences in a document and hence often suffers from poor performance in analyzing short documents. In addition, its parameter estimation often relies on approximate posterior inference that is either not scalable or suffers from large approximation error. This paper introduces a new topic-modeling framework where each document is viewed as a set of word embedding vectors and each topic is modeled as an embedding vector in the same embedding space. Embedding the words and topics in the same vector space, we define a method to measure the semantic difference between the embedding vectors of the words of a document and these of the topics, and optimize the topic embeddings to minimize the expected difference over all documents. Experiments on text analysis demonstrate that the proposed method, which is amenable to mini-batch stochastic gradient descent based optimization and hence scalable to big corpora, provides competitive performance in discovering more coherent and diverse topics and extracting better document representations.
Tecnologica cosa: Modeling Storyteller Personalities in Boccaccio's Decameron
Sep 22, 2021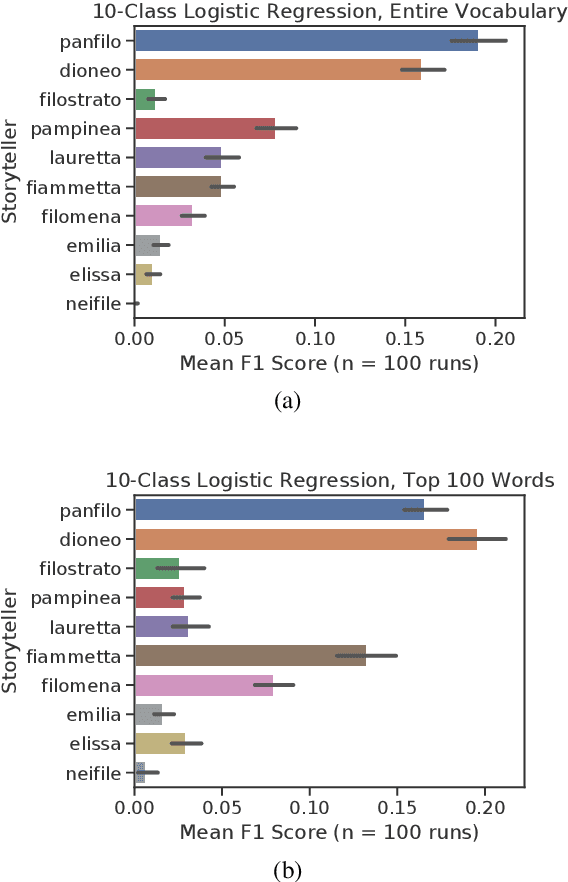


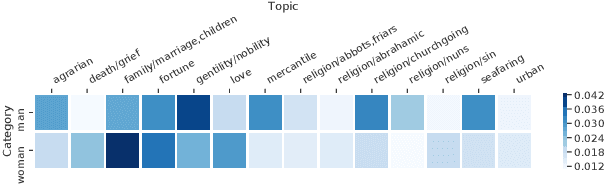
We explore Boccaccio's Decameron to see how digital humanities tools can be used for tasks that have limited data in a language no longer in contemporary use: medieval Italian. We focus our analysis on the question: Do the different storytellers in the text exhibit distinct personalities? To answer this question, we curate and release a dataset based on the authoritative edition of the text. We use supervised classification methods to predict storytellers based on the stories they tell, confirming the difficulty of the task, and demonstrate that topic modeling can extract thematic storyteller "profiles."
Is Automated Topic Model Evaluation Broken?: The Incoherence of Coherence
Jul 05, 2021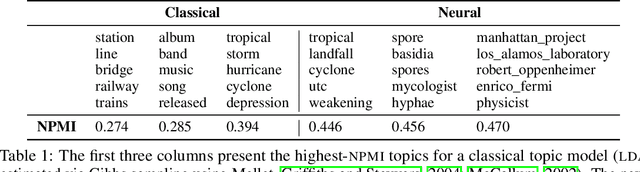


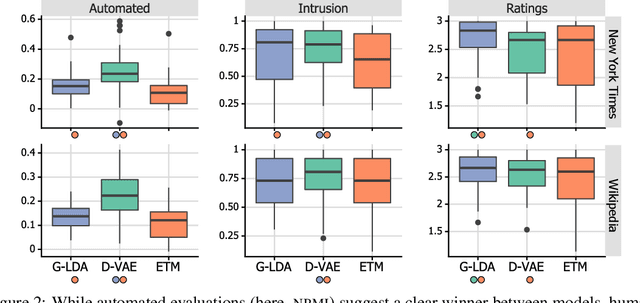
Topic model evaluation, like evaluation of other unsupervised methods, can be contentious. However, the field has coalesced around automated estimates of topic coherence, which rely on the frequency of word co-occurrences in a reference corpus. Recent models relying on neural components surpass classical topic models according to these metrics. At the same time, unlike classical models, the practice of neural topic model evaluation suffers from a validation gap: automatic coherence for neural models has not been validated using human experimentation. In addition, as we show via a meta-analysis of topic modeling literature, there is a substantial standardization gap in the use of automated topic modeling benchmarks. We address both the standardization gap and the validation gap. Using two of the most widely used topic model evaluation datasets, we assess a dominant classical model and two state-of-the-art neural models in a systematic, clearly documented, reproducible way. We use automatic coherence along with the two most widely accepted human judgment tasks, namely, topic rating and word intrusion. Automated evaluation will declare one model significantly different from another when corresponding human evaluations do not, calling into question the validity of fully automatic evaluations independent of human judgments.
Topic Analysis of Superconductivity Literature by Semantic Non-negative Matrix Factorization
Dec 01, 2021
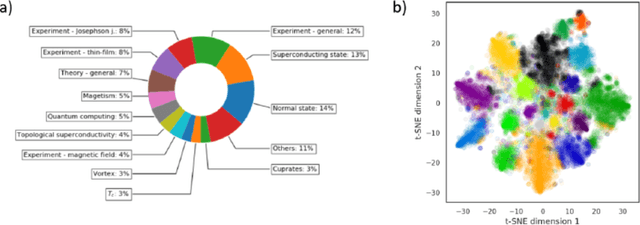
We utilize a recently developed topic modeling method called SeNMFk, extending the standard Non-negative Matrix Factorization (NMF) methods by incorporating the semantic structure of the text, and adding a robust system for determining the number of topics. With SeNMFk, we were able to extract coherent topics validated by human experts. From these topics, a few are relatively general and cover broad concepts, while the majority can be precisely mapped to specific scientific effects or measurement techniques. The topics also differ by ubiquity, with only three topics prevalent in almost 40 percent of the abstract, while each specific topic tends to dominate a small subset of the abstracts. These results demonstrate the ability of SeNMFk to produce a layered and nuanced analysis of large scientific corpora.
Neural Topic Modeling by Incorporating Document Relationship Graph
Sep 29, 2020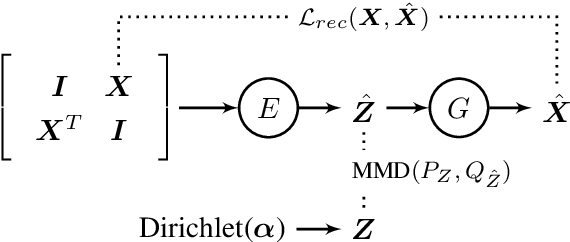
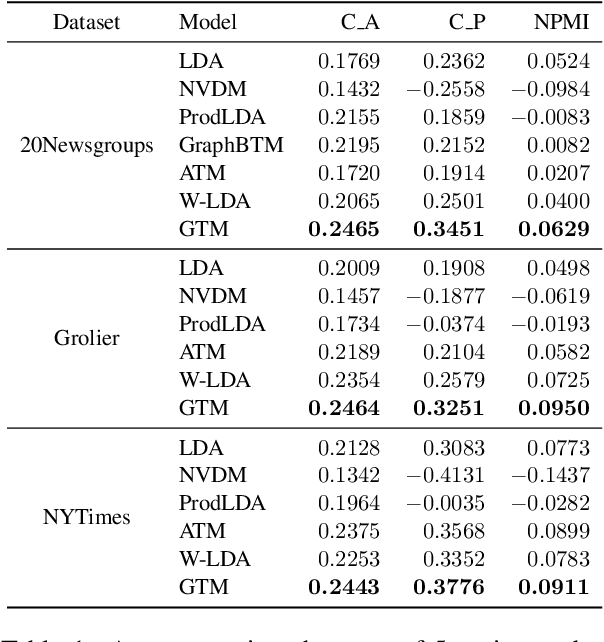
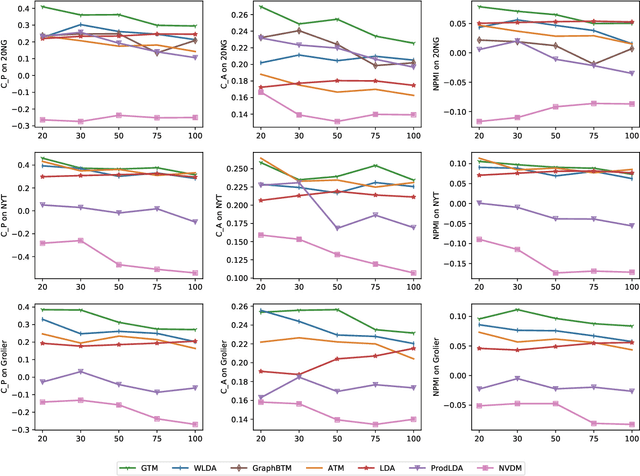

Graph Neural Networks (GNNs) that capture the relationships between graph nodes via message passing have been a hot research direction in the natural language processing community. In this paper, we propose Graph Topic Model (GTM), a GNN based neural topic model that represents a corpus as a document relationship graph. Documents and words in the corpus become nodes in the graph and are connected based on document-word co-occurrences. By introducing the graph structure, the relationships between documents are established through their shared words and thus the topical representation of a document is enriched by aggregating information from its neighboring nodes using graph convolution. Extensive experiments on three datasets were conducted and the results demonstrate the effectiveness of the proposed approach.
Learning Hidden Markov Models from Pairwise Co-occurrences with Application to Topic Modeling
Jun 18, 2018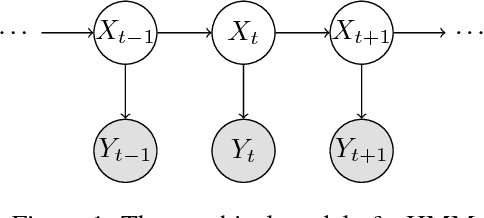

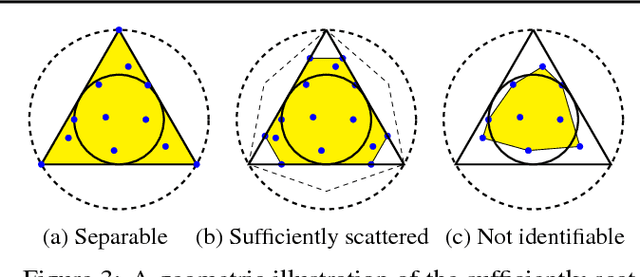
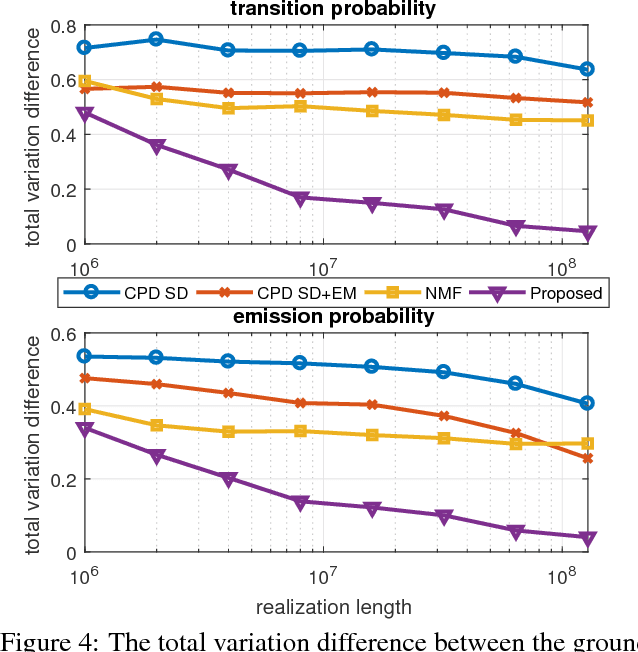
We present a new algorithm for identifying the transition and emission probabilities of a hidden Markov model (HMM) from the emitted data. Expectation-maximization becomes computationally prohibitive for long observation records, which are often required for identification. The new algorithm is particularly suitable for cases where the available sample size is large enough to accurately estimate second-order output probabilities, but not higher-order ones. We show that if one is only able to obtain a reliable estimate of the pairwise co-occurrence probabilities of the emissions, it is still possible to uniquely identify the HMM if the emission probability is \emph{sufficiently scattered}. We apply our method to hidden topic Markov modeling, and demonstrate that we can learn topics with higher quality if documents are modeled as observations of HMMs sharing the same emission (topic) probability, compared to the simple but widely used bag-of-words model.
Generating Cyber Threat Intelligence to Discover Potential Security Threats Using Classification and Topic Modeling
Aug 16, 2021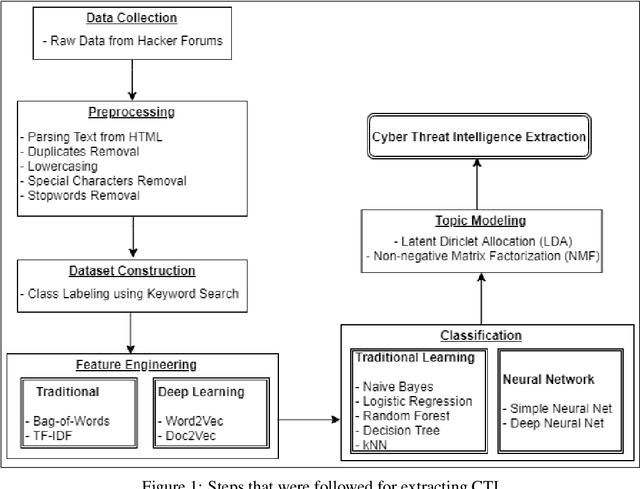

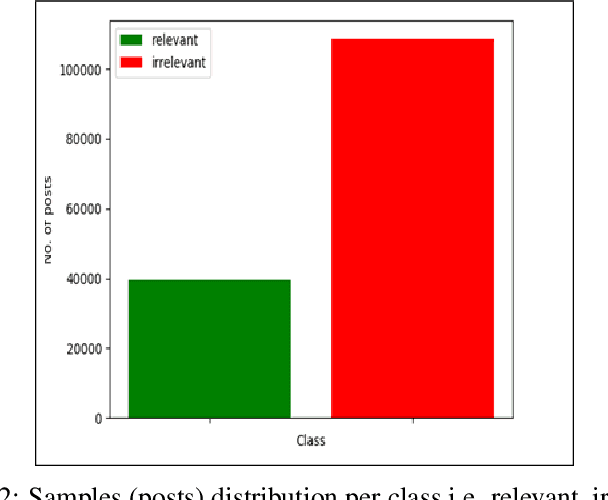

Due to the variety of cyber-attacks or threats, the cybersecurity community has been enhancing the traditional security control mechanisms to an advanced level so that automated tools can encounter potential security threats. Very recently a term, Cyber Threat Intelligence (CTI) has been represented as one of the proactive and robust mechanisms because of its automated cybersecurity threat prediction based on data. In general, CTI collects and analyses data from various sources e.g. online security forums, social media where cyber enthusiasts, analysts, even cybercriminals discuss cyber or computer security related topics and discovers potential threats based on the analysis. As the manual analysis of every such discussion i.e. posts on online platforms is time-consuming, inefficient, and susceptible to errors, CTI as an automated tool can perform uniquely to detect cyber threats. In this paper, our goal is to identify and explore relevant CTI from hacker forums by using different supervised and unsupervised learning techniques. To this end, we collect data from a real hacker forum and constructed two datasets: a binary dataset and a multi-class dataset. Our binary dataset contains two classes one containing cybersecurity-relevant posts and another one containing posts that are not related to security. This dataset is constructed using simple keyword search technique. Using a similar approach, we further categorize posts from security-relevant posts into five different threat categories. We then applied several machine learning classifiers along with deep neural network-based classifiers and use them on the datasets to compare their performances. We also tested the classifiers on a leaked dataset with labels named nulled.io as our ground truth. We further explore the datasets using unsupervised techniques i.e. Latent Dirichlet Allocation (LDA) and Non-negative Matrix Factorization (NMF).