 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
Police Text Analysis: Topic Modeling and Spatial Relative Density Estimation
Feb 08, 2022

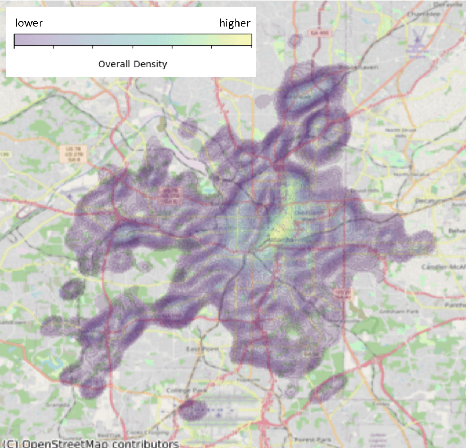
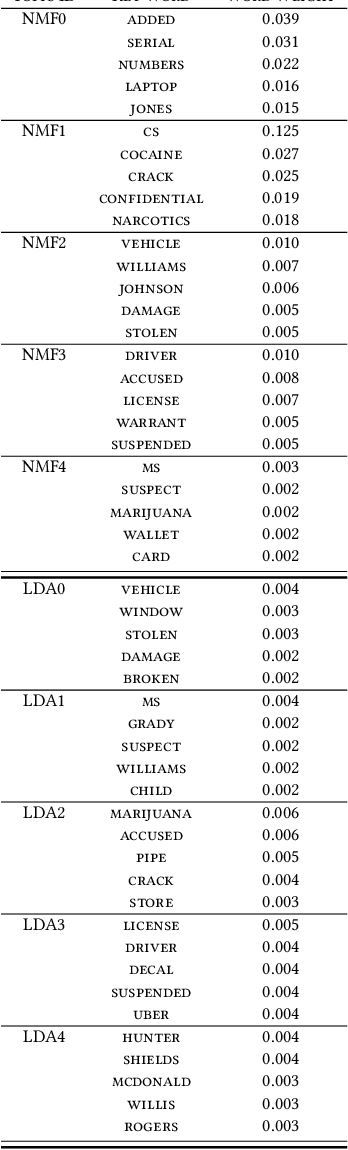
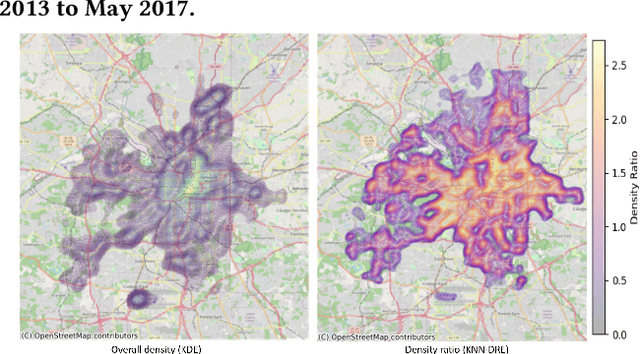
We analyze a large corpus of police incident narrative documents in understanding the spatial distribution of the topics. The motivation for doing this is that police narratives in each incident report contains very fine-grained information that is richer than the category that is manually assigned by the police. Our approach is to split the corpus into topics using two different unsupervised machine learning algorithms - Latent Dirichlet Allocation and Non-negative Matrix Factorization. We validate the performance of each learned topic model using model coherence. Then, using a k-nearest neighbors density ratio estimation (kNN-DRE) approach that we propose, we estimate the spatial density ratio per topic and use this for data discovery and analysis of each topic, allowing for insights into the described incidents at scale. We provide a qualitative assessment of each topic and highlight some key benefits for using our kNN-DRE model for estimating spatial trends.
Learning Methods for Dynamic Topic Modeling in Automated Behaviour Analysis
Sep 18, 2017
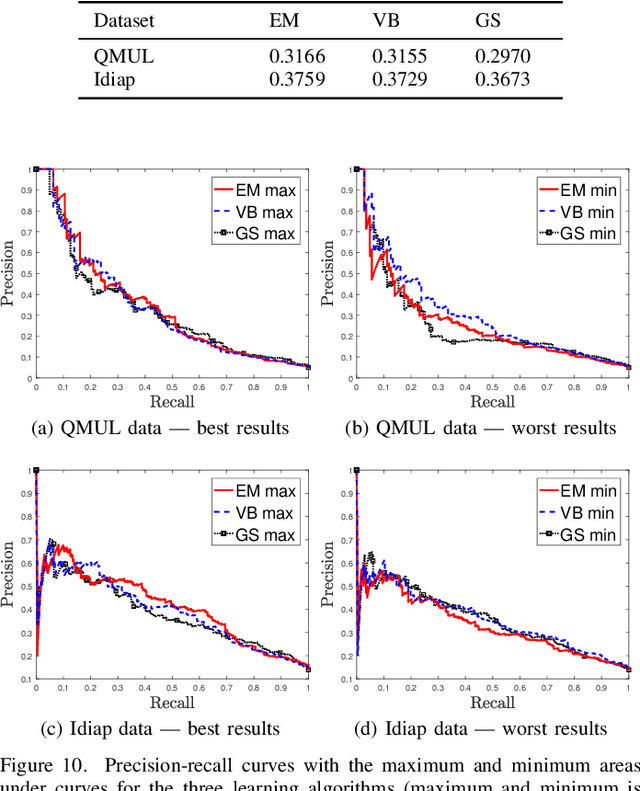

Semi-supervised and unsupervised systems provide operators with invaluable support and can tremendously reduce the operators load. In the light of the necessity to process large volumes of video data and provide autonomous decisions, this work proposes new learning algorithms for activity analysis in video. The activities and behaviours are described by a dynamic topic model. Two novel learning algorithms based on the expectation maximisation approach and variational Bayes inference are proposed. Theoretical derivations of the posterior of model parameters are given. The designed learning algorithms are compared with the Gibbs sampling inference scheme introduced earlier in the literature. A detailed comparison of the learning algorithms is presented on real video data. We also propose an anomaly localisation procedure, elegantly embedded in the topic modeling framework. The proposed framework can be applied to a number of areas, including transportation systems, security and surveillance.
n-stage Latent Dirichlet Allocation: A Novel Approach for LDA
Oct 20, 2021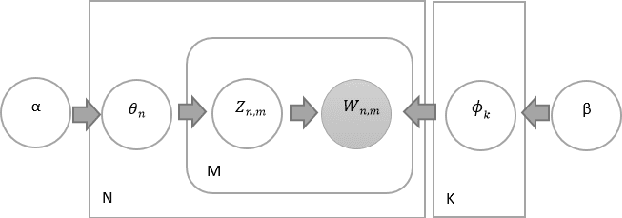

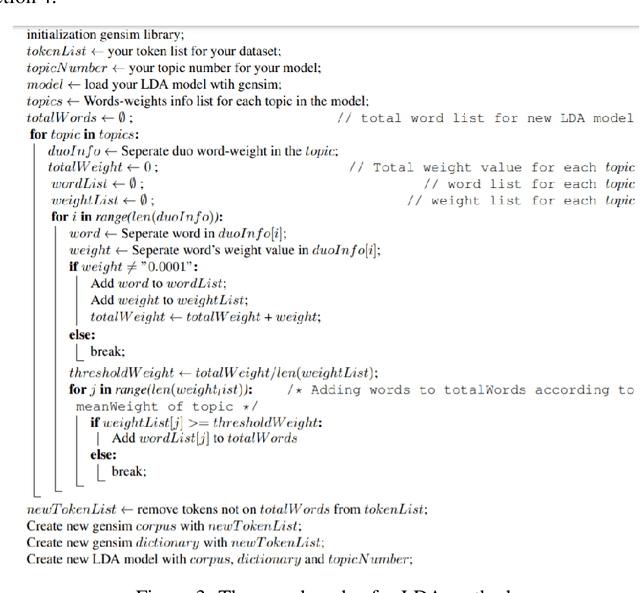
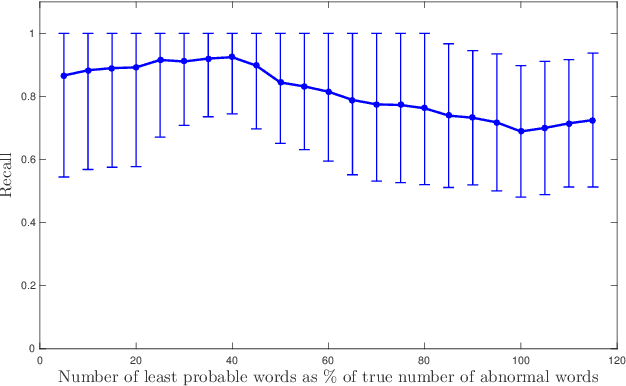
Nowadays, data analysis has become a problem as the amount of data is constantly increasing. In order to overcome this problem in textual data, many models and methods are used in natural language processing. The topic modeling field is one of these methods. Topic modeling allows determining the semantic structure of a text document. Latent Dirichlet Allocation (LDA) is the most common method among topic modeling methods. In this article, the proposed n-stage LDA method, which can enable the LDA method to be used more effectively, is explained in detail. The positive effect of the method has been demonstrated by the applied English and Turkish studies. Since the method focuses on reducing the word count in the dictionary, it can be used language-independently. You can access the open-source code of the method and the example: https://github.com/anil1055/n-stage_LDA
Scholastic: Graphical Human-Al Collaboration for Inductive and Interpretive Text Analysis
Aug 12, 2022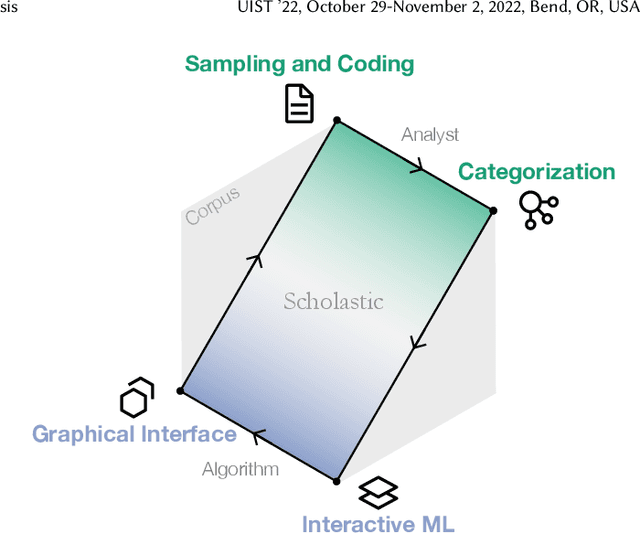
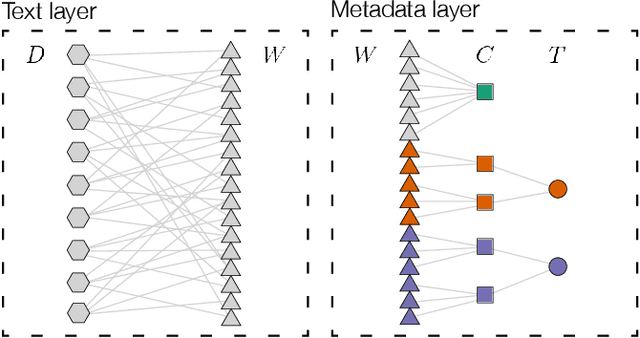
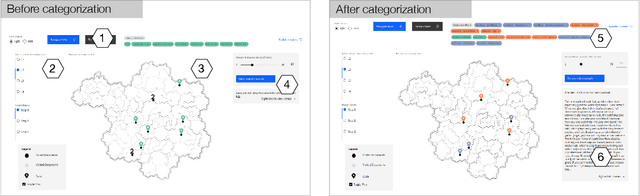
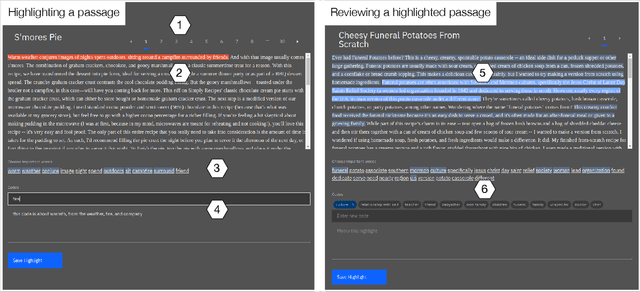
Interpretive scholars generate knowledge from text corpora by manually sampling documents, applying codes, and refining and collating codes into categories until meaningful themes emerge. Given a large corpus, machine learning could help scale this data sampling and analysis, but prior research shows that experts are generally concerned about algorithms potentially disrupting or driving interpretive scholarship. We take a human-centered design approach to addressing concerns around machine-assisted interpretive research to build Scholastic, which incorporates a machine-in-the-loop clustering algorithm to scaffold interpretive text analysis. As a scholar applies codes to documents and refines them, the resulting coding schema serves as structured metadata which constrains hierarchical document and word clusters inferred from the corpus. Interactive visualizations of these clusters can help scholars strategically sample documents further toward insights. Scholastic demonstrates how human-centered algorithm design and visualizations employing familiar metaphors can support inductive and interpretive research methodologies through interactive topic modeling and document clustering.
Learning Concept Hierarchies through Probabilistic Topic Modeling
Nov 29, 2016
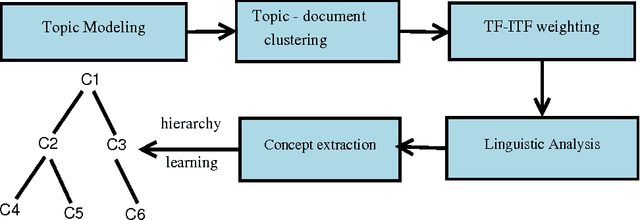
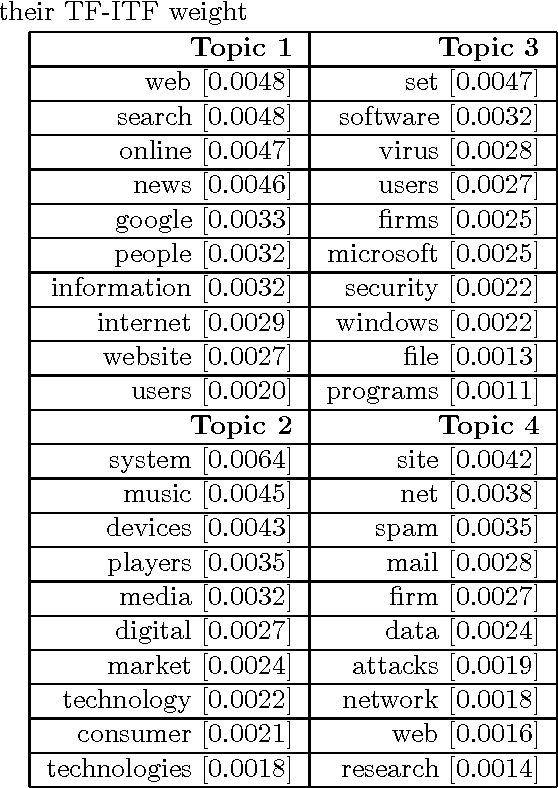

With the advent of semantic web, various tools and techniques have been introduced for presenting and organizing knowledge. Concept hierarchies are one such technique which gained significant attention due to its usefulness in creating domain ontologies that are considered as an integral part of semantic web. Automated concept hierarchy learning algorithms focus on extracting relevant concepts from unstructured text corpus and connect them together by identifying some potential relations exist between them. In this paper, we propose a novel approach for identifying relevant concepts from plain text and then learns hierarchy of concepts by exploiting subsumption relation between them. To start with, we model topics using a probabilistic topic model and then make use of some lightweight linguistic process to extract semantically rich concepts. Then we connect concepts by identifying an "is-a" relationship between pair of concepts. The proposed method is completely unsupervised and there is no need for a domain specific training corpus for concept extraction and learning. Experiments on large and real-world text corpora such as BBC News dataset and Reuters News corpus shows that the proposed method outperforms some of the existing methods for concept extraction and efficient concept hierarchy learning is possible if the overall task is guided by a probabilistic topic modeling algorithm.
Topic Modeling the Reading and Writing Behavior of Information Foragers
Jun 30, 2019

The general problem of "information foraging" in an environment about which agents have incomplete information has been explored in many fields, including cognitive psychology, neuroscience, economics, finance, ecology, and computer science. In all of these areas, the searcher aims to enhance future performance by surveying enough of existing knowledge to orient themselves in the information space. Individuals can be viewed as conducting a cognitive search in which they must balance exploration of ideas that are novel to them against exploitation of knowledge in domains in which they are already expert. In this dissertation, I present several case studies that demonstrate how reading and writing behaviors interact to construct personal knowledge bases. These studies use LDA topic modeling to represent the information environment of the texts each author read and wrote. Three studies revolve around Charles Darwin. Darwin left detailed records of every book he read for 23 years, from disembarking from the H.M.S. Beagle to just after publication of The Origin of Species. Additionally, he left copies of his drafts before publication. I characterize his reading behavior, then show how that reading behavior interacted with the drafts and subsequent revisions of The Origin of Species, and expand the dataset to include later readings and writings. Then, through a study of Thomas Jefferson's correspondence, I expand the study to non-book data. Finally, through an examination of neuroscience citation data, I move from individual behavior to collective behavior in constructing an information environment. Together, these studies reveal "the interplay between individual and collective phenomena where innovation takes place" (Tria et al. 2014).
TIAGE: A Benchmark for Topic-Shift Aware Dialog Modeling
Sep 09, 2021
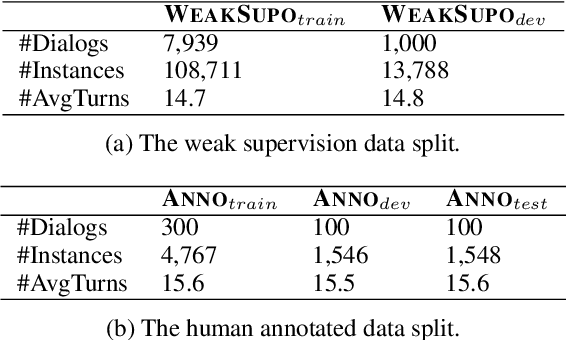
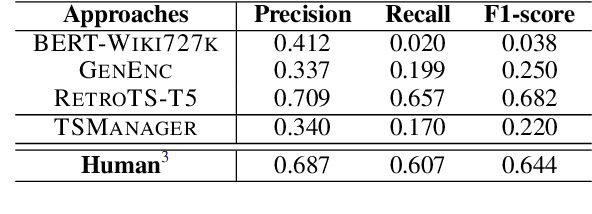
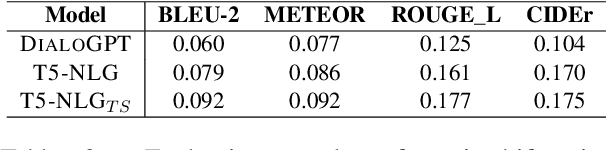
Human conversations naturally evolve around different topics and fluently move between them. In research on dialog systems, the ability to actively and smoothly transition to new topics is often ignored. In this paper we introduce TIAGE, a new topic-shift aware dialog benchmark constructed utilizing human annotations on topic shifts. Based on TIAGE, we introduce three tasks to investigate different scenarios of topic-shift modeling in dialog settings: topic-shift detection, topic-shift triggered response generation and topic-aware dialog generation. Experiments on these tasks show that the topic-shift signals in TIAGE are useful for topic-shift response generation. On the other hand, dialog systems still struggle to decide when to change topic. This indicates further research is needed in topic-shift aware dialog modeling.
Nested Variational Autoencoder for Topic Modeling on Microtexts with Word Vectors
Jun 03, 2019
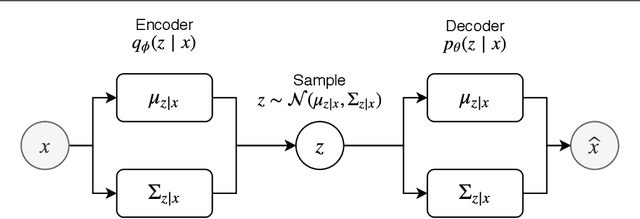
Most of the information on the Internet is represented in the form of microtexts, which are short text snippets like news headlines or tweets. These source of information is abundant and mining this data could uncover meaningful insights. Topic modeling is one of the popular methods to extract knowledge from a collection of documents, nevertheless conventional topic models such as Latent Dirichlet Allocation (LDA) is unable to perform well on short documents, mostly due to the scarcity of word co-occurrence statistics embedded in the data. The objective of our research is to create a topic model which can achieve great performances on microtexts while requiring a small runtime for scalability to large datasets. To solve the lack of information of microtexts, we allow our method to take advantage of word embeddings for additional knowledge of relationships between words. For speed and scalability, we apply Auto-Encoding Variational Bayes, an algorithm that can perform efficient black-box inference in probabilistic models. The result of our work is a novel topic model called Nested Variational Autoencoder which is a distribution that takes into account word vectors and is parameterized by a neural network architecture. For optimization, the model is trained to approximate the posterior distribution of the original LDA model. Experiments show the improvements of our model on microtexts as well as its runtime advantage.
Topic Modeling the Hàn diăn Ancient Classics
Feb 02, 2017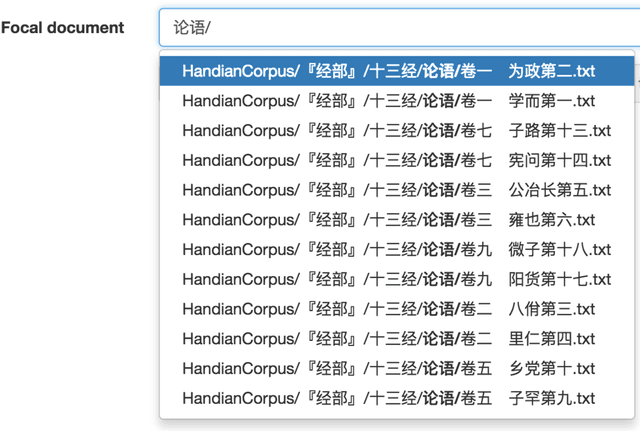
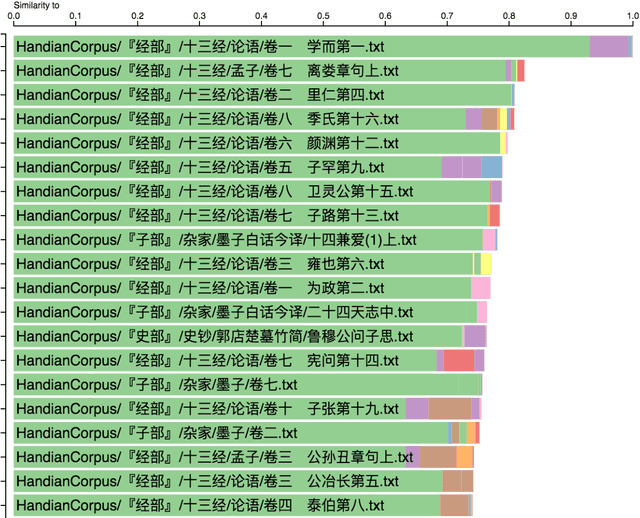
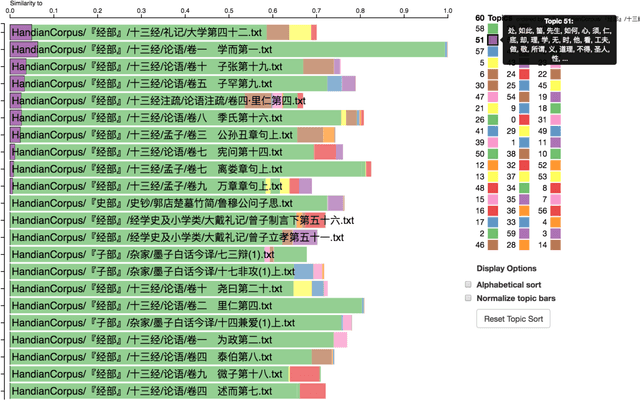
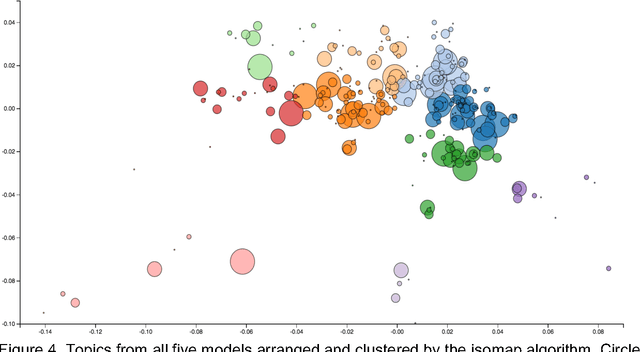
Ancient Chinese texts present an area of enormous challenge and opportunity for humanities scholars interested in exploiting computational methods to assist in the development of new insights and interpretations of culturally significant materials. In this paper we describe a collaborative effort between Indiana University and Xi'an Jiaotong University to support exploration and interpretation of a digital corpus of over 18,000 ancient Chinese documents, which we refer to as the "Handian" ancient classics corpus (H\`an di\u{a}n g\u{u} j\'i, i.e, the "Han canon" or "Chinese classics"). It contains classics of ancient Chinese philosophy, documents of historical and biographical significance, and literary works. We begin by describing the Digital Humanities context of this joint project, and the advances in humanities computing that made this project feasible. We describe the corpus and introduce our application of probabilistic topic modeling to this corpus, with attention to the particular challenges posed by modeling ancient Chinese documents. We give a specific example of how the software we have developed can be used to aid discovery and interpretation of themes in the corpus. We outline more advanced forms of computer-aided interpretation that are also made possible by the programming interface provided by our system, and the general implications of these methods for understanding the nature of meaning in these texts.