 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
Transfer Topic Modeling with Ease and Scalability
Jan 26, 2013



The increasing volume of short texts generated on social media sites, such as Twitter or Facebook, creates a great demand for effective and efficient topic modeling approaches. While latent Dirichlet allocation (LDA) can be applied, it is not optimal due to its weakness in handling short texts with fast-changing topics and scalability concerns. In this paper, we propose a transfer learning approach that utilizes abundant labeled documents from other domains (such as Yahoo! News or Wikipedia) to improve topic modeling, with better model fitting and result interpretation. Specifically, we develop Transfer Hierarchical LDA (thLDA) model, which incorporates the label information from other domains via informative priors. In addition, we develop a parallel implementation of our model for large-scale applications. We demonstrate the effectiveness of our thLDA model on both a microblogging dataset and standard text collections including AP and RCV1 datasets.
Are Neural Topic Models Broken?
Oct 28, 2022
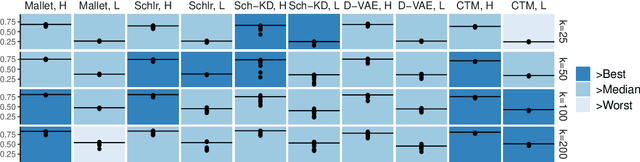
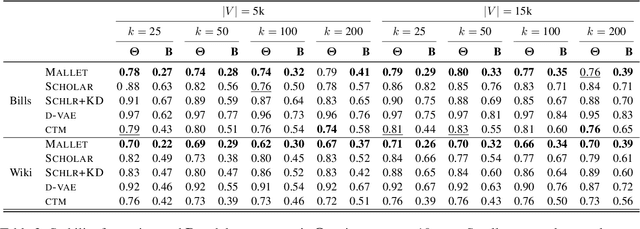
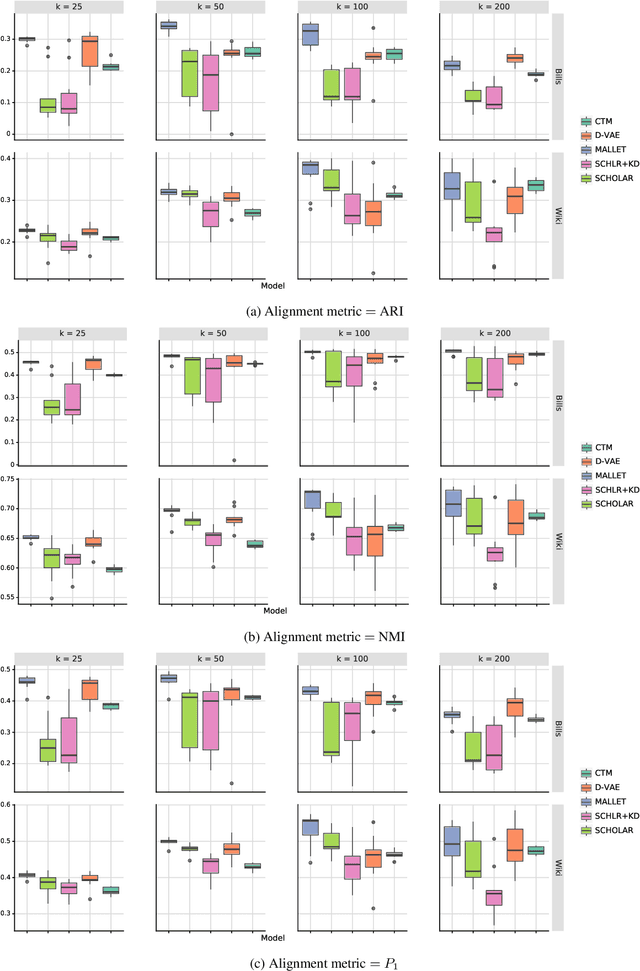
Recently, the relationship between automated and human evaluation of topic models has been called into question. Method developers have staked the efficacy of new topic model variants on automated measures, and their failure to approximate human preferences places these models on uncertain ground. Moreover, existing evaluation paradigms are often divorced from real-world use. Motivated by content analysis as a dominant real-world use case for topic modeling, we analyze two related aspects of topic models that affect their effectiveness and trustworthiness in practice for that purpose: the stability of their estimates and the extent to which the model's discovered categories align with human-determined categories in the data. We find that neural topic models fare worse in both respects compared to an established classical method. We take a step toward addressing both issues in tandem by demonstrating that a straightforward ensembling method can reliably outperform the members of the ensemble.
Joint Sentiment/Topic Modeling on Text Data Using Boosted Restricted Boltzmann Machine
Nov 10, 2017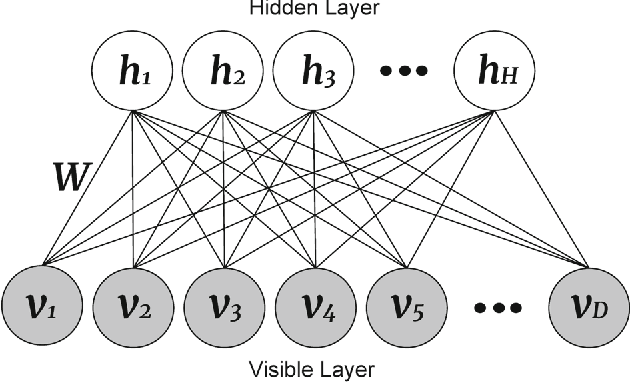
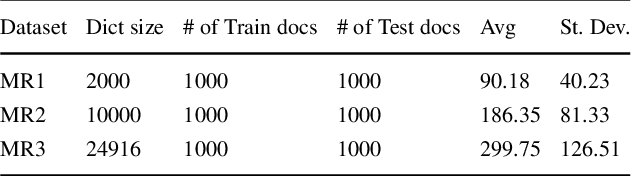
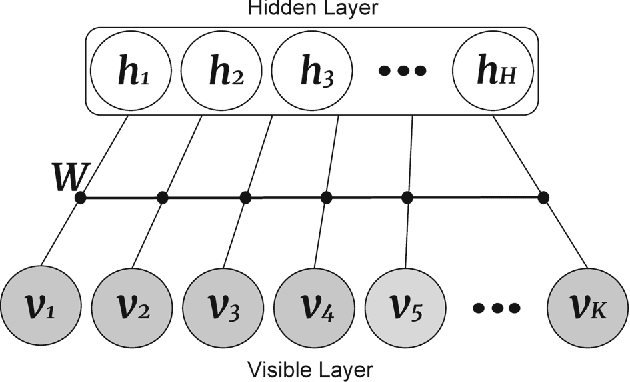
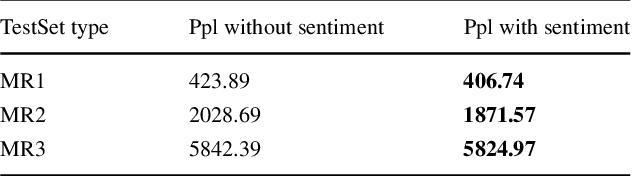
Recently by the development of the Internet and the Web, different types of social media such as web blogs become an immense source of text data. Through the processing of these data, it is possible to discover practical information about different topics, individuals opinions and a thorough understanding of the society. Therefore, applying models which can automatically extract the subjective information from the documents would be efficient and helpful. Topic modeling methods, also sentiment analysis are the most raised topics in the natural language processing and text mining fields. In this paper a new structure for joint sentiment-topic modeling based on Restricted Boltzmann Machine (RBM) which is a type of neural networks is proposed. By modifying the structure of RBM as well as appending a layer which is analogous to sentiment of text data to it, we propose a generative structure for joint sentiment topic modeling based on neutral networks. The proposed method is supervised and trained by the Contrastive Divergence algorithm. The new attached layer in the proposed model is a layer with the multinomial probability distribution which can be used in text data sentiment classification or any other supervised application. The proposed model is compared with existing models in the experiments such as evaluating as a generative model, sentiment classification, information retrieval and the corresponding results demonstrate the efficiency of the method.
Learning Semantic Textual Similarity via Topic-informed Discrete Latent Variables
Nov 07, 2022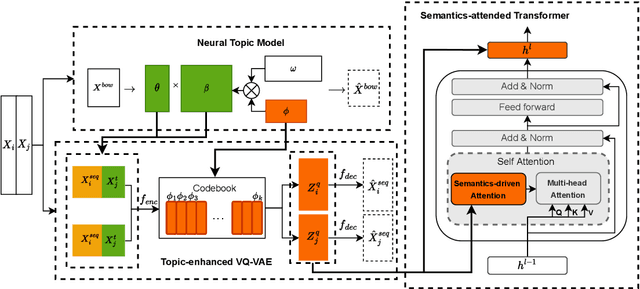
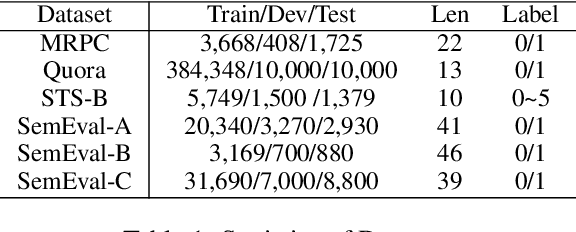
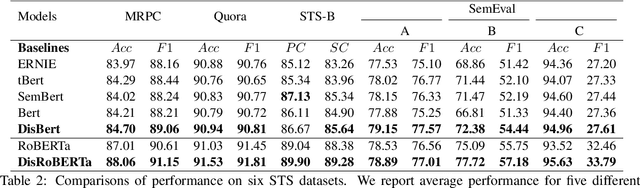
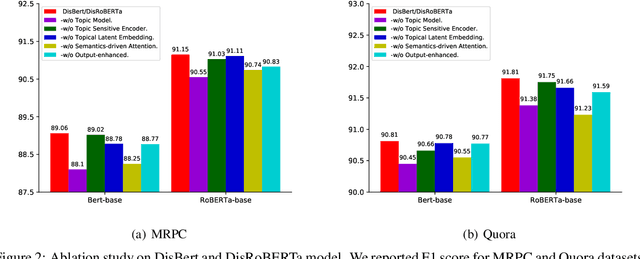
Recently, discrete latent variable models have received a surge of interest in both Natural Language Processing (NLP) and Computer Vision (CV), attributed to their comparable performance to the continuous counterparts in representation learning, while being more interpretable in their predictions. In this paper, we develop a topic-informed discrete latent variable model for semantic textual similarity, which learns a shared latent space for sentence-pair representation via vector quantization. Compared with previous models limited to local semantic contexts, our model can explore richer semantic information via topic modeling. We further boost the performance of semantic similarity by injecting the quantized representation into a transformer-based language model with a well-designed semantic-driven attention mechanism. We demonstrate, through extensive experiments across various English language datasets, that our model is able to surpass several strong neural baselines in semantic textual similarity tasks.
Analyses of Multi-collection Corpora via Compound Topic Modeling
Jun 17, 2019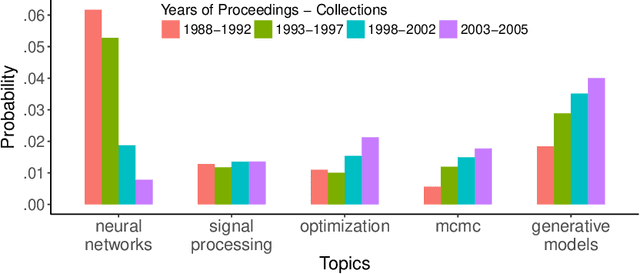
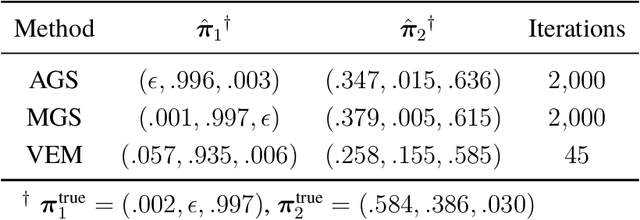
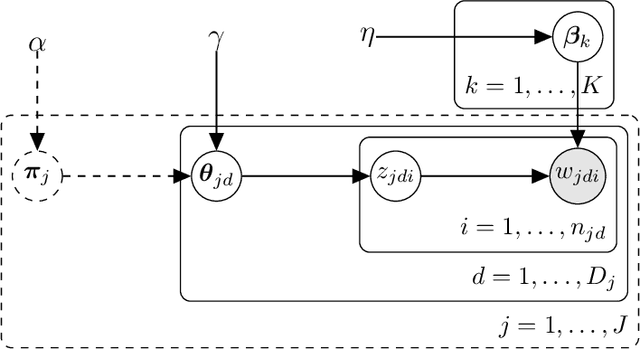
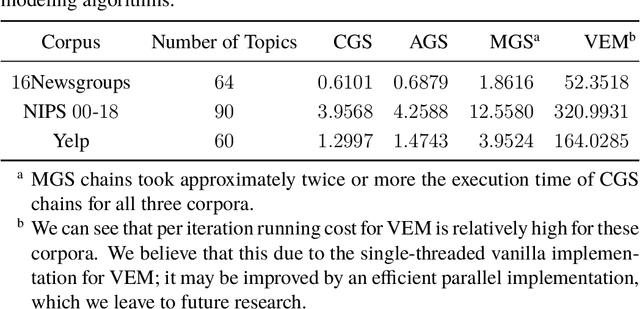
As electronically stored data grow in daily life, obtaining novel and relevant information becomes challenging in text mining. Thus people have sought statistical methods based on term frequency, matrix algebra, or topic modeling for text mining. Popular topic models have centered on one single text collection, which is deficient for comparative text analyses. We consider a setting where one can partition the corpus into subcollections. Each subcollection shares a common set of topics, but there exists relative variation in topic proportions among collections. Including any prior knowledge about the corpus (e.g. organization structure), we propose the compound latent Dirichlet allocation (cLDA) model, improving on previous work, encouraging generalizability, and depending less on user-input parameters. To identify the parameters of interest in cLDA, we study Markov chain Monte Carlo (MCMC) and variational inference approaches extensively, and suggest an efficient MCMC method. We evaluate cLDA qualitatively and quantitatively using both synthetic and real-world corpora. The usability study on some real-world corpora illustrates the superiority of cLDA to explore the underlying topics automatically but also model their connections and variations across multiple collections.
Ontology-Grounded Topic Modeling for Climate Science Research
Jul 31, 2018
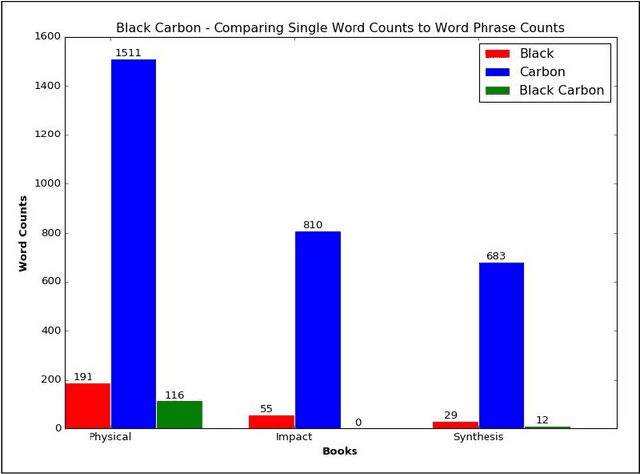
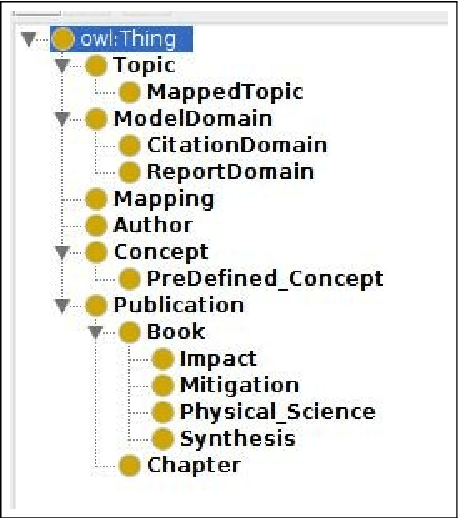
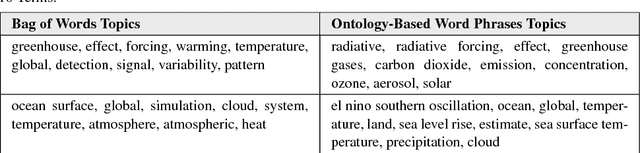
In scientific disciplines where research findings have a strong impact on society, reducing the amount of time it takes to understand, synthesize and exploit the research is invaluable. Topic modeling is an effective technique for summarizing a collection of documents to find the main themes among them and to classify other documents that have a similar mixture of co-occurring words. We show how grounding a topic model with an ontology, extracted from a glossary of important domain phrases, improves the topics generated and makes them easier to understand. We apply and evaluate this method to the climate science domain. The result improves the topics generated and supports faster research understanding, discovery of social networks among researchers, and automatic ontology generation.
Dependent Hierarchical Normalized Random Measures for Dynamic Topic Modeling
Jun 18, 2012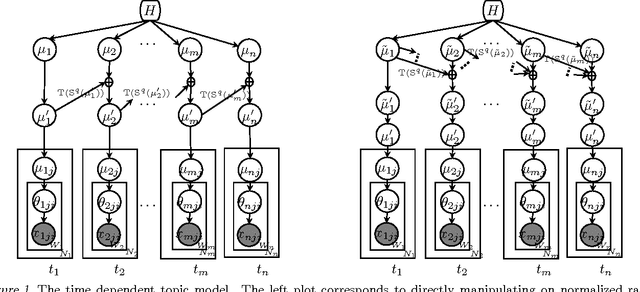
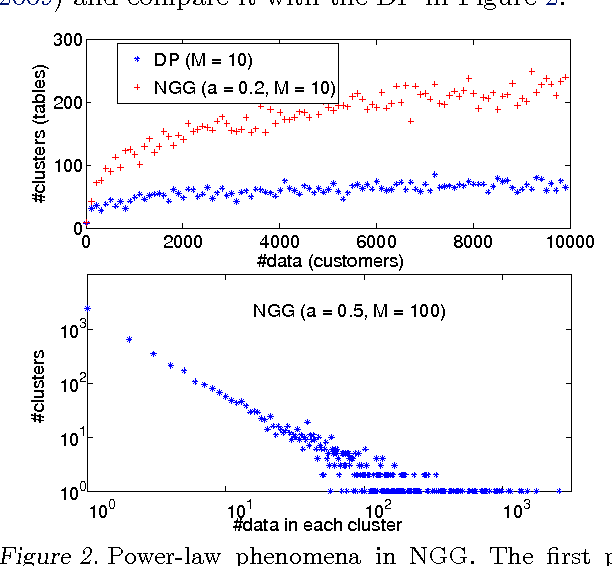
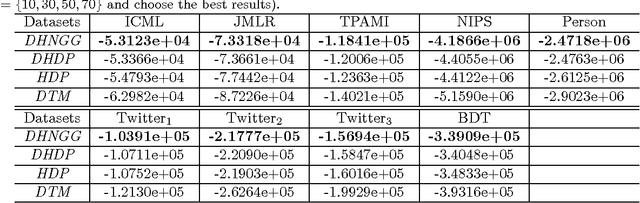
We develop dependent hierarchical normalized random measures and apply them to dynamic topic modeling. The dependency arises via superposition, subsampling and point transition on the underlying Poisson processes of these measures. The measures used include normalised generalised Gamma processes that demonstrate power law properties, unlike Dirichlet processes used previously in dynamic topic modeling. Inference for the model includes adapting a recently developed slice sampler to directly manipulate the underlying Poisson process. Experiments performed on news, blogs, academic and Twitter collections demonstrate the technique gives superior perplexity over a number of previous models.
Application of Rényi and Tsallis Entropies to Topic Modeling Optimization
Feb 28, 2018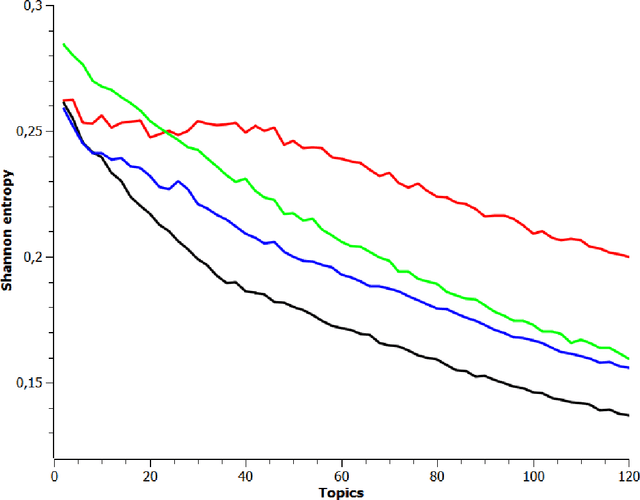
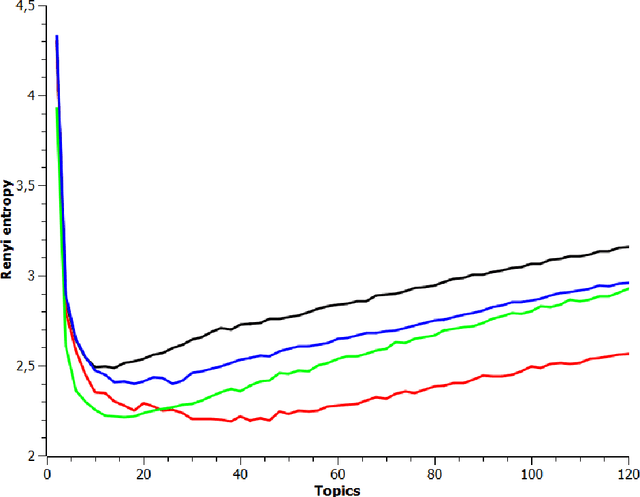
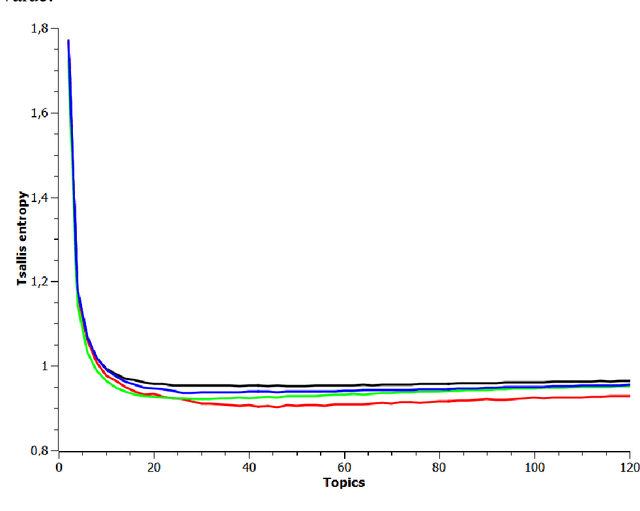
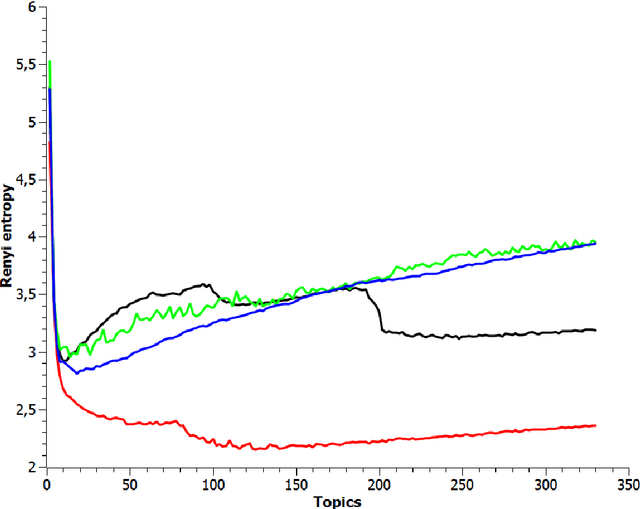
This is full length article (draft version) where problem number of topics in Topic Modeling is discussed. We proposed idea that Renyi and Tsallis entropy can be used for identification of optimal number in large textual collections. We also report results of numerical experiments of Semantic stability for 4 topic models, which shows that semantic stability play very important role in problem topic number. The calculation of Renyi and Tsallis entropy based on thermodynamics approach.
Analysis of Computational Science Papers from ICCS 2001-2016 using Topic Modeling and Graph Theory
Apr 18, 2017
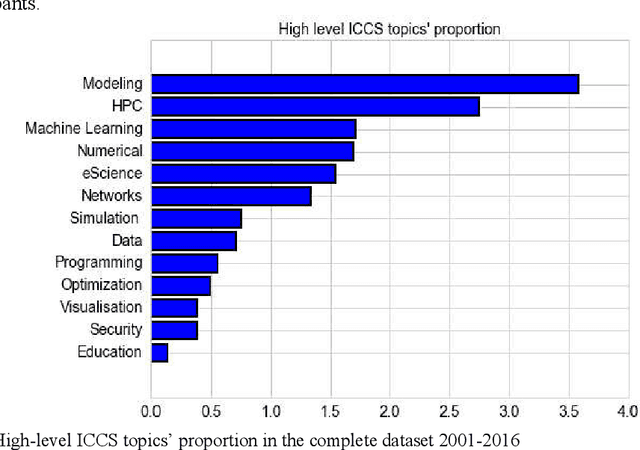

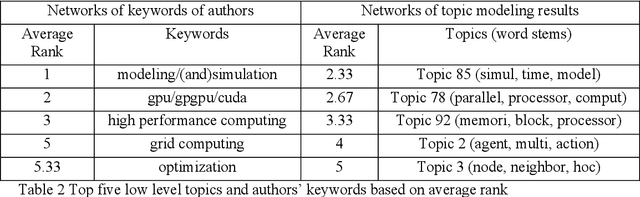
This paper presents results of topic modeling and network models of topics using the International Conference on Computational Science corpus, which contains domain-specific (computational science) papers over sixteen years (a total of 5695 papers). We discuss topical structures of International Conference on Computational Science, how these topics evolve over time in response to the topicality of various problems, technologies and methods, and how all these topics relate to one another. This analysis illustrates multidisciplinary research and collaborations among scientific communities, by constructing static and dynamic networks from the topic modeling results and the keywords of authors. The results of this study give insights about the past and future trends of core discussion topics in computational science. We used the Non-negative Matrix Factorization topic modeling algorithm to discover topics and labeled and grouped results hierarchically.
Submission-Aware Reviewer Profiling for Reviewer Recommender System
Nov 08, 2022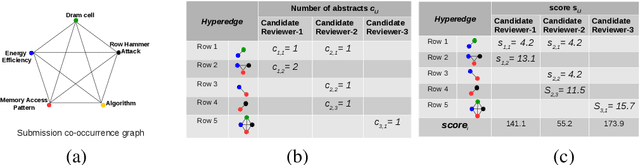
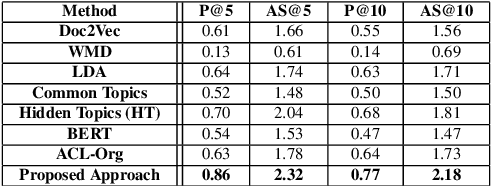
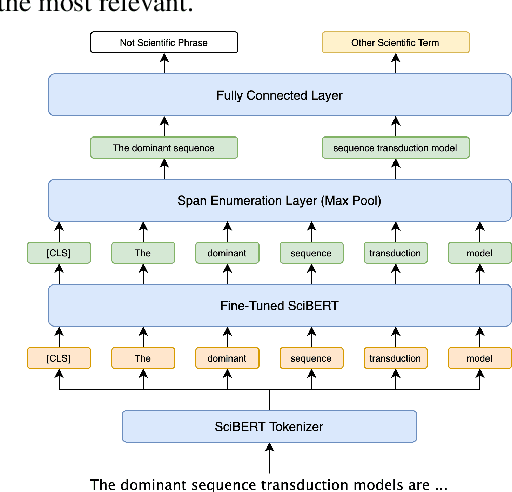

Assigning qualified, unbiased and interested reviewers to paper submissions is vital for maintaining the integrity and quality of the academic publishing system and providing valuable reviews to authors. However, matching thousands of submissions with thousands of potential reviewers within a limited time is a daunting challenge for a conference program committee. Prior efforts based on topic modeling have suffered from losing the specific context that help define the topics in a publication or submission abstract. Moreover, in some cases, topics identified are difficult to interpret. We propose an approach that learns from each abstract published by a potential reviewer the topics studied and the explicit context in which the reviewer studied the topics. Furthermore, we contribute a new dataset for evaluating reviewer matching systems. Our experiments show a significant, consistent improvement in precision when compared with the existing methods. We also use examples to demonstrate why our recommendations are more explainable. The new approach has been deployed successfully at top-tier conferences in the last two years.