 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
Analyzing the impact of climate change on critical infrastructure from the scientific literature: A weakly supervised NLP approach
Feb 06, 2023
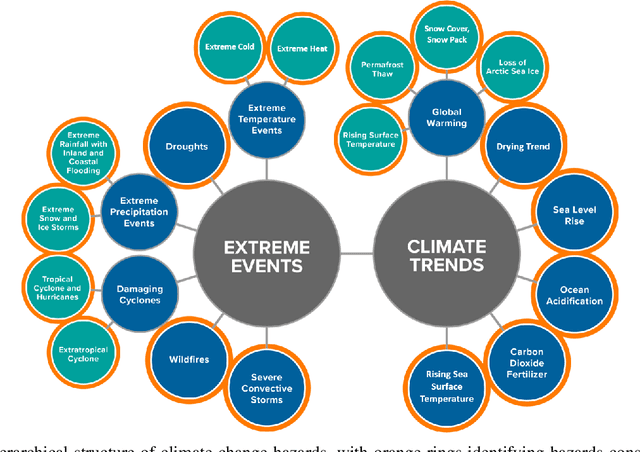
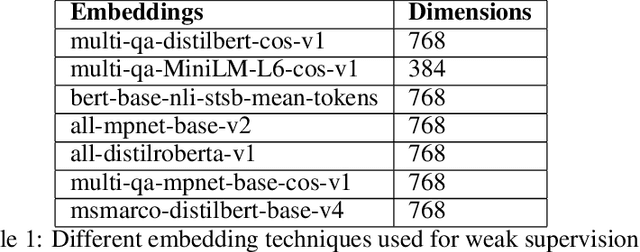
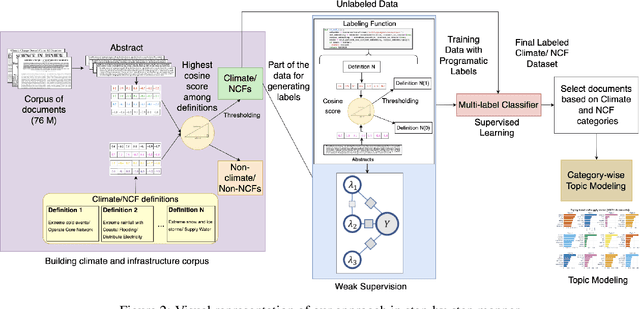
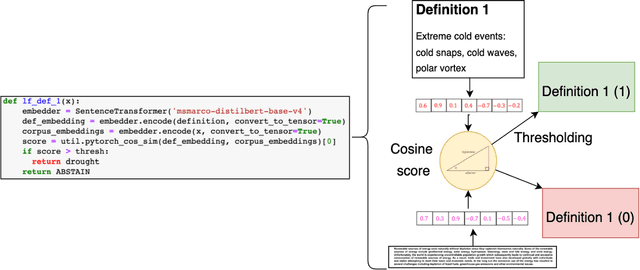
Natural language processing (NLP) is a promising approach for analyzing large volumes of climate-change and infrastructure-related scientific literature. However, best-in-practice NLP techniques require large collections of relevant documents (corpus). Furthermore, NLP techniques using machine learning and deep learning techniques require labels grouping the articles based on user-defined criteria for a significant subset of a corpus in order to train the supervised model. Even labeling a few hundred documents with human subject-matter experts is a time-consuming process. To expedite this process, we developed a weak supervision-based NLP approach that leverages semantic similarity between categories and documents to (i) establish a topic-specific corpus by subsetting a large-scale open-access corpus and (ii) generate category labels for the topic-specific corpus. In comparison with a months-long process of subject-matter expert labeling, we assign category labels to the whole corpus using weak supervision and supervised learning in about 13 hours. The labeled climate and NCF corpus enable targeted, efficient identification of documents discussing a topic (or combination of topics) of interest and identification of various effects of climate change on critical infrastructure, improving the usability of scientific literature and ultimately supporting enhanced policy and decision making. To demonstrate this capability, we conduct topic modeling on pairs of climate hazards and NCFs to discover trending topics at the intersection of these categories. This method is useful for analysts and decision-makers to quickly grasp the relevant topics and most important documents linked to the topic.
Scalable Dynamic Topic Modeling with Clustered Latent Dirichlet Allocation (CLDA)
Oct 15, 2017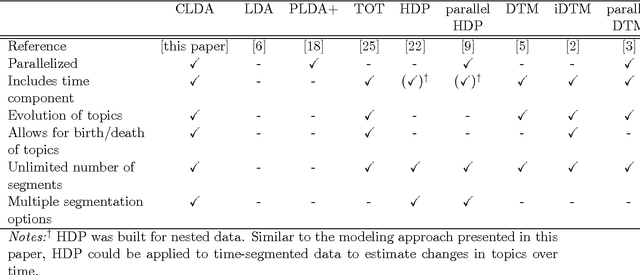
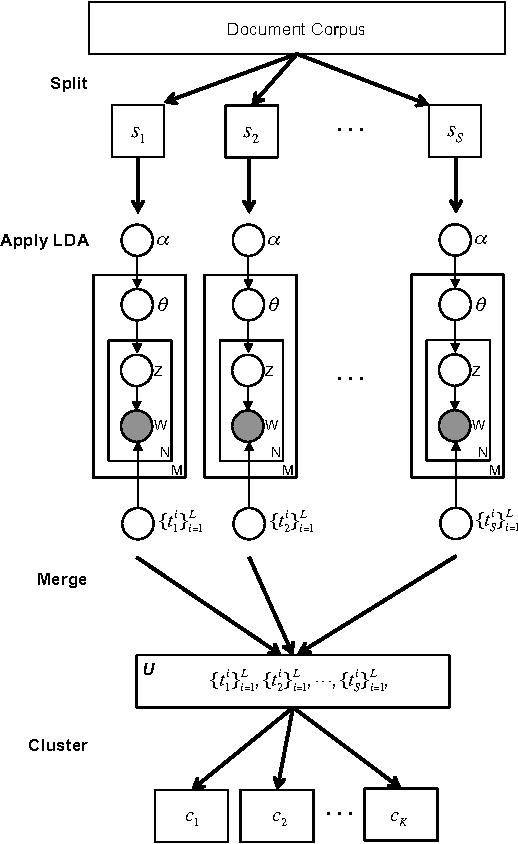
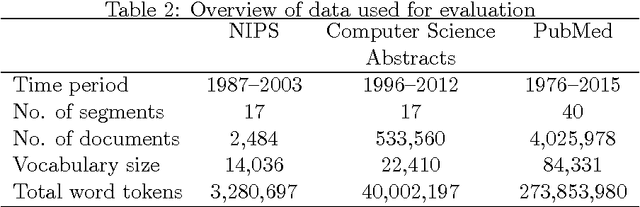
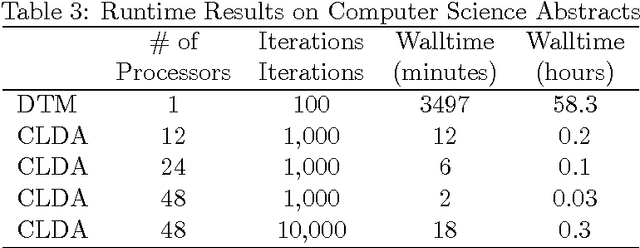
Topic modeling, a method for extracting the underlying themes from a collection of documents, is an increasingly important component of the design of intelligent systems enabling the sense-making of highly dynamic and diverse streams of text data. Traditional methods such as Dynamic Topic Modeling (DTM) do not lend themselves well to direct parallelization because of dependencies from one time step to another. In this paper, we introduce and empirically analyze Clustered Latent Dirichlet Allocation (CLDA), a method for extracting dynamic latent topics from a collection of documents. Our approach is based on data decomposition in which the data is partitioned into segments, followed by topic modeling on the individual segments. The resulting local models are then combined into a global solution using clustering. The decomposition and resulting parallelization leads to very fast runtime even on very large datasets. Our approach furthermore provides insight into how the composition of topics changes over time and can also be applied using other data partitioning strategies over any discrete features of the data, such as geographic features or classes of users. In this paper CLDA is applied successfully to seventeen years of NIPS conference papers (2,484 documents and 3,280,697 words), seventeen years of computer science journal abstracts (533,560 documents and 32,551,540 words), and to forty years of the PubMed corpus (4,025,978 documents and 273,853,980 words).
Understanding Crosslingual Transfer Mechanisms in Probabilistic Topic Modeling
Oct 13, 2018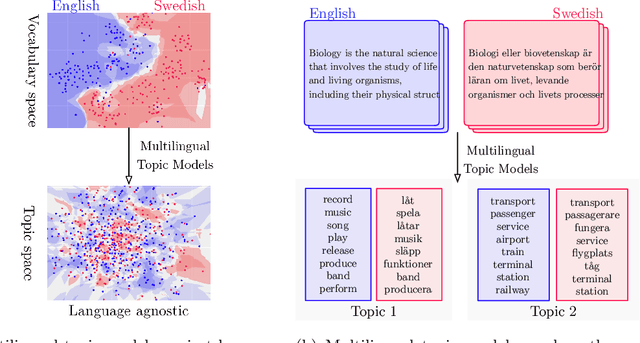


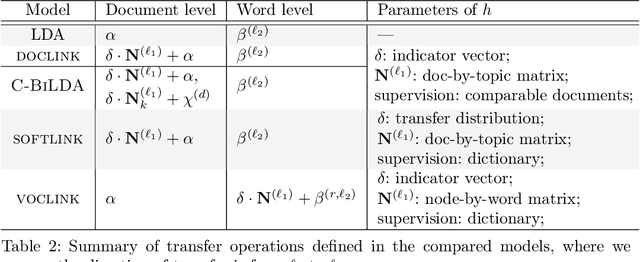
Probabilistic topic modeling is a popular choice as the first step of crosslingual tasks to enable knowledge transfer and extract multilingual features. While many multilingual topic models have been developed, their assumptions on the training corpus are quite varied, and it is not clear how well the models can be applied under various training conditions. In this paper, we systematically study the knowledge transfer mechanisms behind different multilingual topic models, and through a broad set of experiments with four models on ten languages, we provide empirical insights that can inform the selection and future development of multilingual topic models.
Interpretable and Scalable Graphical Models for Complex Spatio-temporal Processes
Jan 15, 2023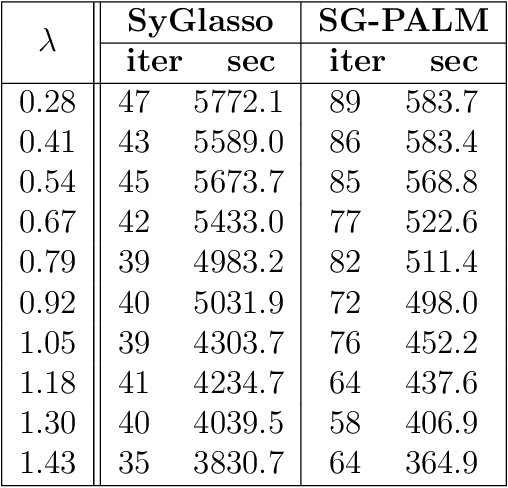
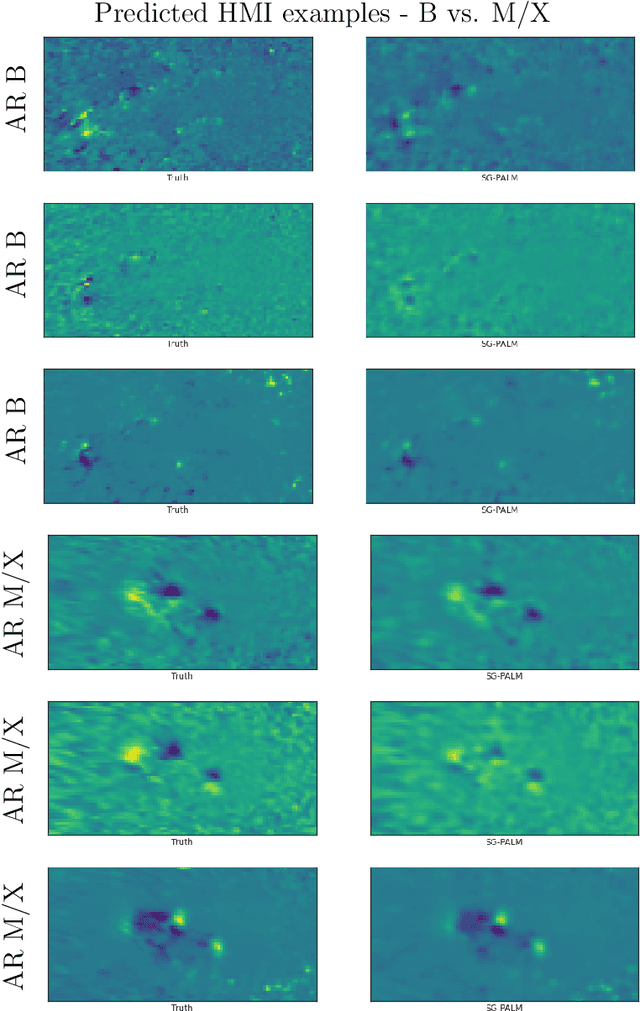
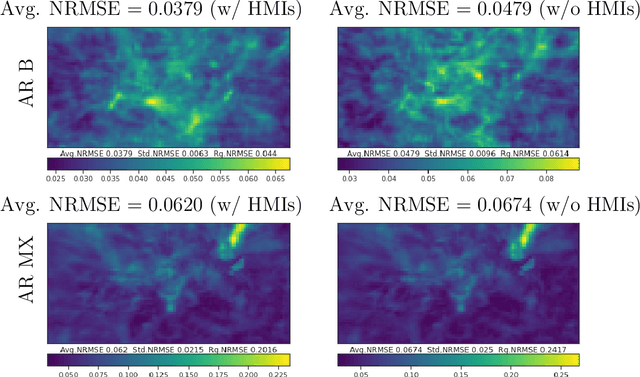
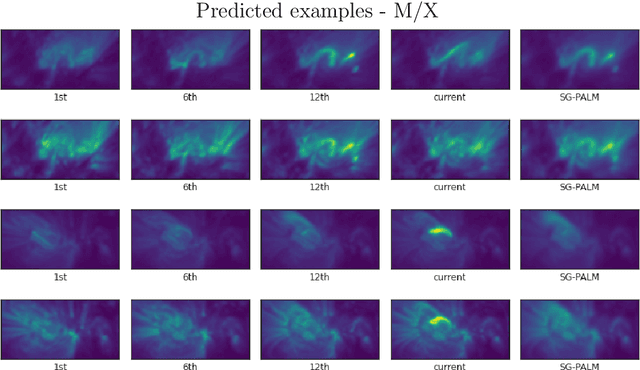
This thesis focuses on data that has complex spatio-temporal structure and on probabilistic graphical models that learn the structure in an interpretable and scalable manner. We target two research areas of interest: Gaussian graphical models for tensor-variate data and summarization of complex time-varying texts using topic models. This work advances the state-of-the-art in several directions. First, it introduces a new class of tensor-variate Gaussian graphical models via the Sylvester tensor equation. Second, it develops an optimization technique based on a fast-converging proximal alternating linearized minimization method, which scales tensor-variate Gaussian graphical model estimations to modern big-data settings. Third, it connects Kronecker-structured (inverse) covariance models with spatio-temporal partial differential equations (PDEs) and introduces a new framework for ensemble Kalman filtering that is capable of tracking chaotic physical systems. Fourth, it proposes a modular and interpretable framework for unsupervised and weakly-supervised probabilistic topic modeling of time-varying data that combines generative statistical models with computational geometric methods. Throughout, practical applications of the methodology are considered using real datasets. This includes brain-connectivity analysis using EEG data, space weather forecasting using solar imaging data, longitudinal analysis of public opinions using Twitter data, and mining of mental health related issues using TalkLife data. We show in each case that the graphical modeling framework introduced here leads to improved interpretability, accuracy, and scalability.
Survival-Supervised Topic Modeling with Anchor Words: Characterizing Pancreatitis Outcomes
Dec 07, 2017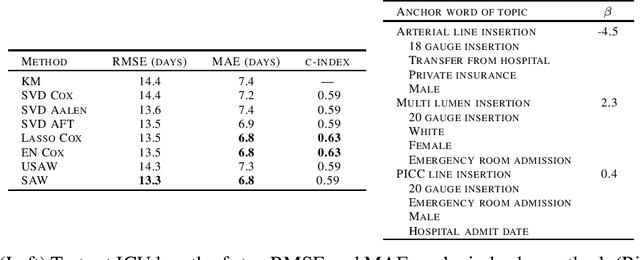
We introduce a new approach for topic modeling that is supervised by survival analysis. Specifically, we build on recent work on unsupervised topic modeling with so-called anchor words by providing supervision through an elastic-net regularized Cox proportional hazards model. In short, an anchor word being present in a document provides strong indication that the document is partially about a specific topic. For example, by seeing "gallstones" in a document, we are fairly certain that the document is partially about medicine. Our proposed method alternates between learning a topic model and learning a survival model to find a local minimum of a block convex optimization problem. We apply our proposed approach to predicting how long patients with pancreatitis admitted to an intensive care unit (ICU) will stay in the ICU. Our approach is as accurate as the best of a variety of baselines while being more interpretable than any of the baselines.
Topic Modeling Based Multi-modal Depression Detection
Mar 28, 2018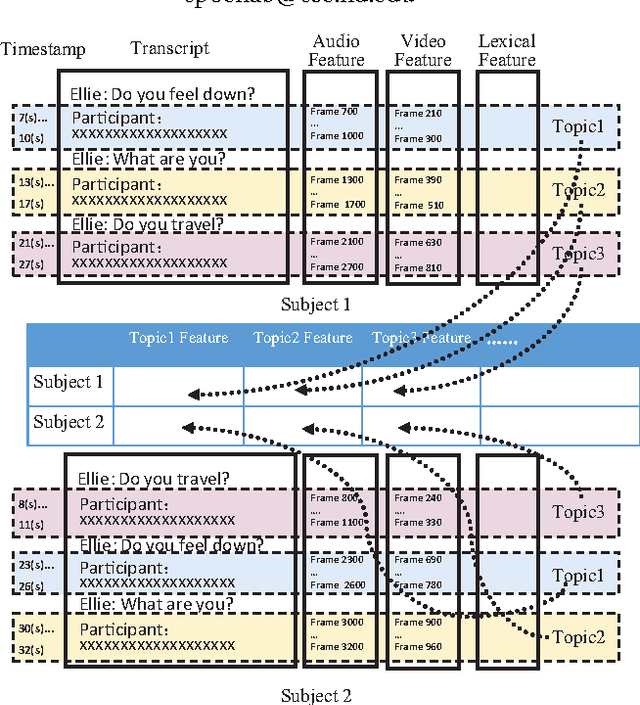
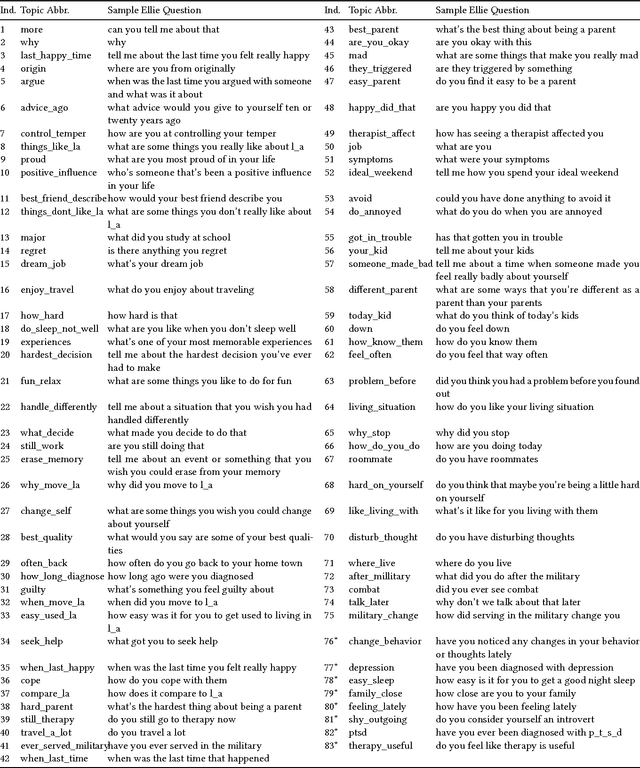
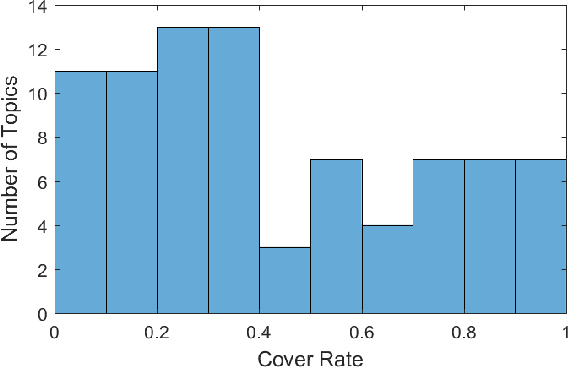
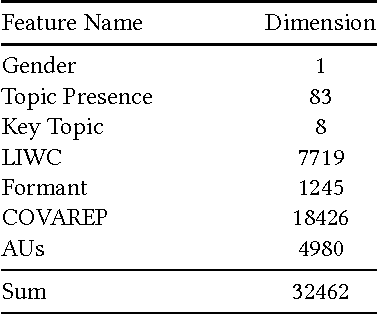
Major depressive disorder is a common mental disorder that affects almost 7% of the adult U.S. population. The 2017 Audio/Visual Emotion Challenge (AVEC) asks participants to build a model to predict depression levels based on the audio, video, and text of an interview ranging between 7-33 minutes. Since averaging features over the entire interview will lose most temporal information, how to discover, capture, and preserve useful temporal details for such a long interview are significant challenges. Therefore, we propose a novel topic modeling based approach to perform context-aware analysis of the recording. Our experiments show that the proposed approach outperforms context-unaware methods and the challenge baselines for all metrics.
Topic Modeling on User Stories using Word Mover's Distance
Jul 13, 2020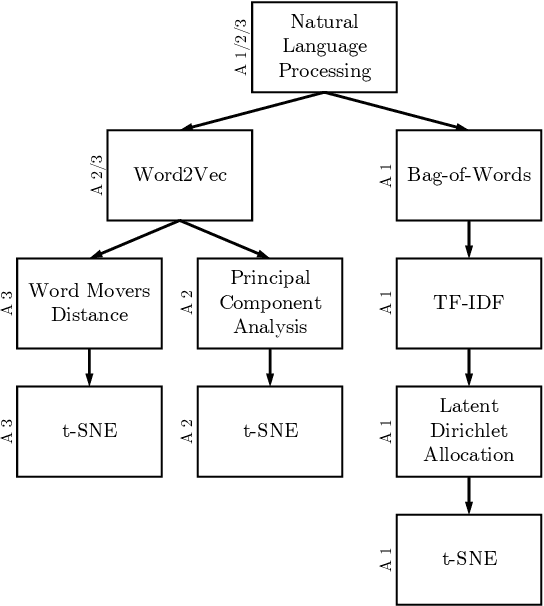
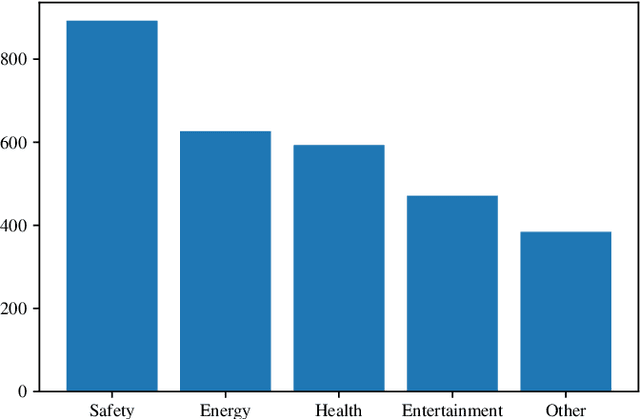
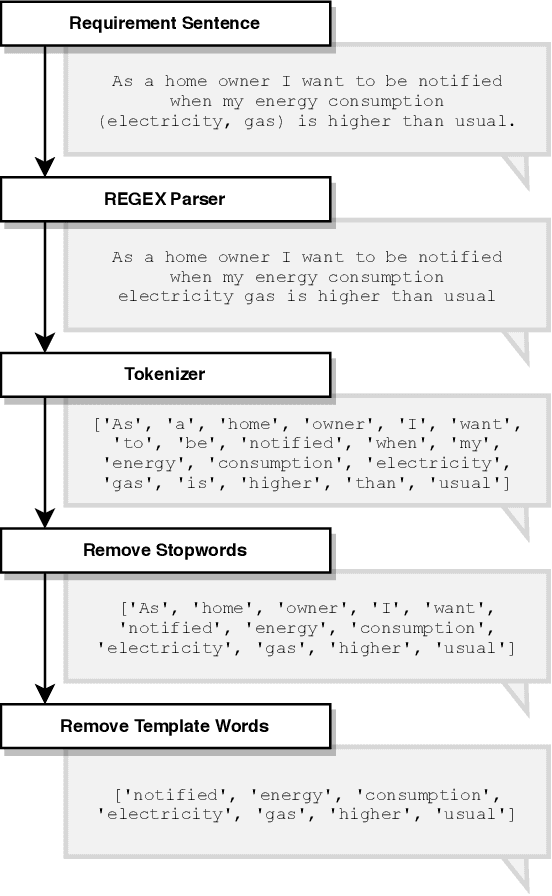

Requirements elicitation has recently been complemented with crowd-based techniques, which continuously involve large, heterogeneous groups of users who express their feedback through a variety of media. Crowd-based elicitation has great potential for engaging with (potential) users early on but also results in large sets of raw and unstructured feedback. Consolidating and analyzing this feedback is a key challenge for turning it into sensible user requirements. In this paper, we focus on topic modeling as a means to identify topics within a large set of crowd-generated user stories and compare three approaches: (1) a traditional approach based on Latent Dirichlet Allocation, (2) a combination of word embeddings and principal component analysis, and (3) a combination of word embeddings and Word Mover's Distance. We evaluate the approaches on a publicly available set of 2,966 user stories written and categorized by crowd workers. We found that a combination of word embeddings and Word Mover's Distance is most promising. Depending on the word embeddings we use in our approaches, we manage to cluster the user stories in two ways: one that is closer to the original categorization and another that allows new insights into the dataset, e.g. to find potentially new categories. Unfortunately, no measure exists to rate the quality of our results objectively. Still, our findings provide a basis for future work towards analyzing crowd-sourced user stories.
SentiBubbles: Topic Modeling and Sentiment Visualization of Entity-centric Tweets
Jan 23, 2018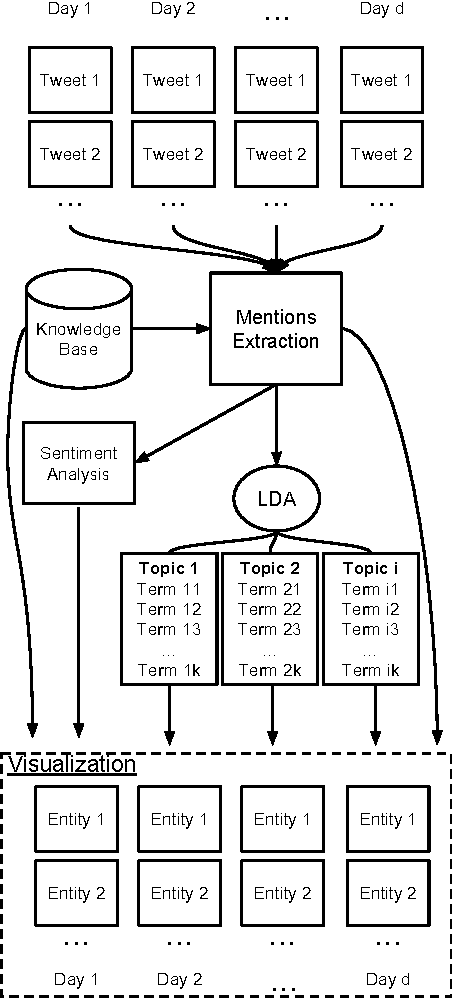
Social Media users tend to mention entities when reacting to news events. The main purpose of this work is to create entity-centric aggregations of tweets on a daily basis. By applying topic modeling and sentiment analysis, we create data visualization insights about current events and people reactions to those events from an entity-centric perspective.
Anchor-Free Correlated Topic Modeling: Identifiability and Algorithm
Nov 15, 2016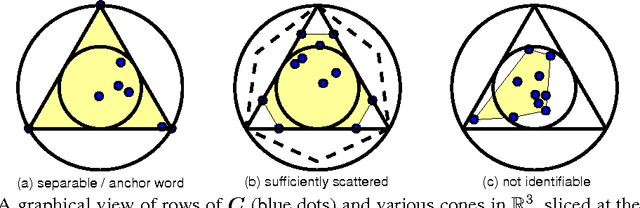
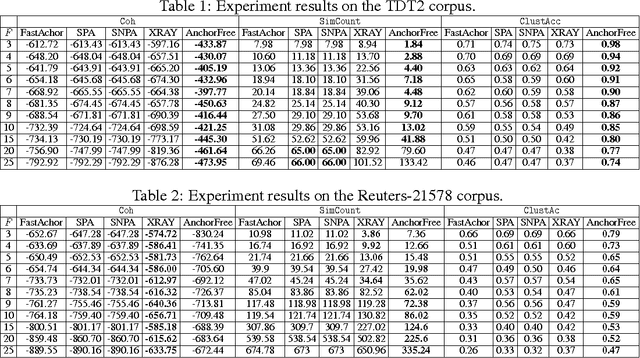
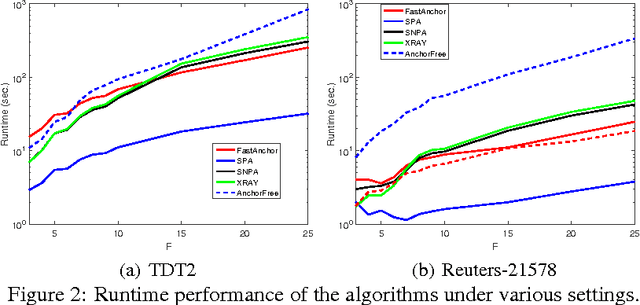
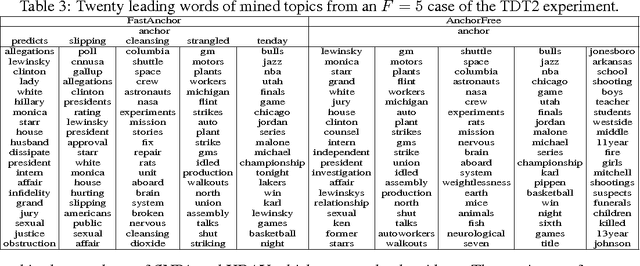
In topic modeling, many algorithms that guarantee identifiability of the topics have been developed under the premise that there exist anchor words -- i.e., words that only appear (with positive probability) in one topic. Follow-up work has resorted to three or higher-order statistics of the data corpus to relax the anchor word assumption. Reliable estimates of higher-order statistics are hard to obtain, however, and the identification of topics under those models hinges on uncorrelatedness of the topics, which can be unrealistic. This paper revisits topic modeling based on second-order moments, and proposes an anchor-free topic mining framework. The proposed approach guarantees the identification of the topics under a much milder condition compared to the anchor-word assumption, thereby exhibiting much better robustness in practice. The associated algorithm only involves one eigen-decomposition and a few small linear programs. This makes it easy to implement and scale up to very large problem instances. Experiments using the TDT2 and Reuters-21578 corpus demonstrate that the proposed anchor-free approach exhibits very favorable performance (measured using coherence, similarity count, and clustering accuracy metrics) compared to the prior art.
Topic modeling of public repositories at scale using names in source code
May 20, 2017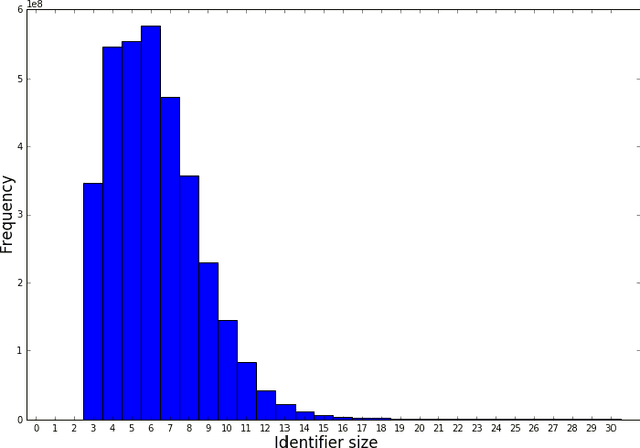
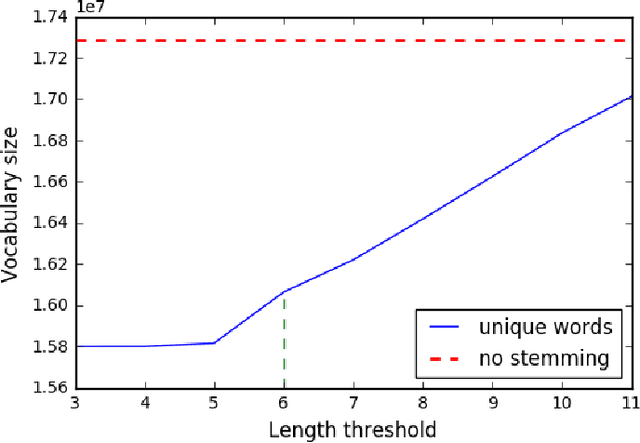
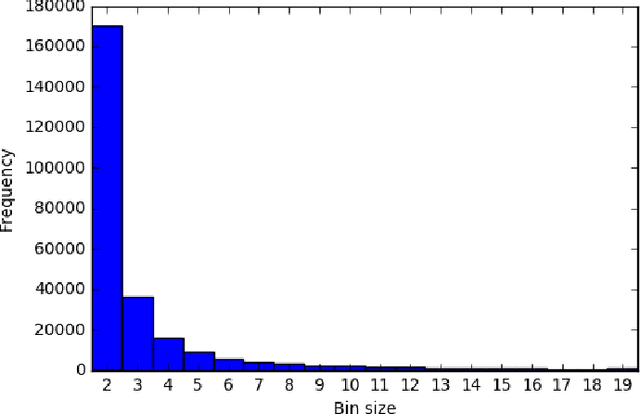
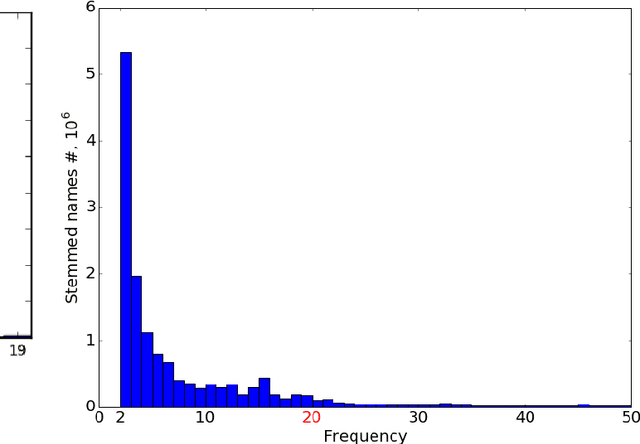
Programming languages themselves have a limited number of reserved keywords and character based tokens that define the language specification. However, programmers have a rich use of natural language within their code through comments, text literals and naming entities. The programmer defined names that can be found in source code are a rich source of information to build a high level understanding of the project. The goal of this paper is to apply topic modeling to names used in over 13.6 million repositories and perceive the inferred topics. One of the problems in such a study is the occurrence of duplicate repositories not officially marked as forks (obscure forks). We show how to address it using the same identifiers which are extracted for topic modeling. We open with a discussion on naming in source code, we then elaborate on our approach to remove exact duplicate and fuzzy duplicate repositories using Locality Sensitive Hashing on the bag-of-words model and then discuss our work on topic modeling; and finally present the results from our data analysis together with open-access to the source code, tools and datasets.