 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
Exploratory topic modeling with distributional semantics
Jul 16, 2015
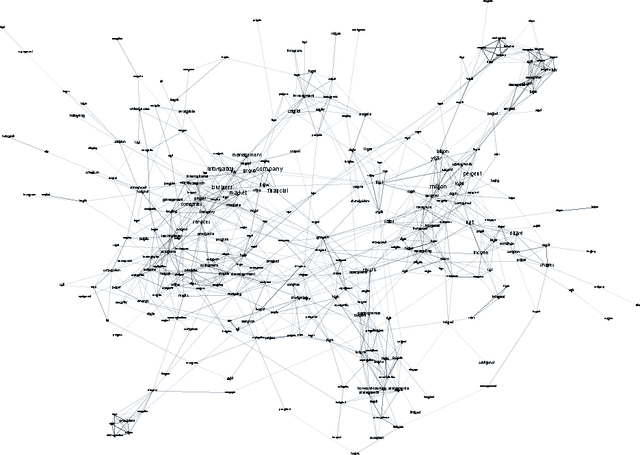
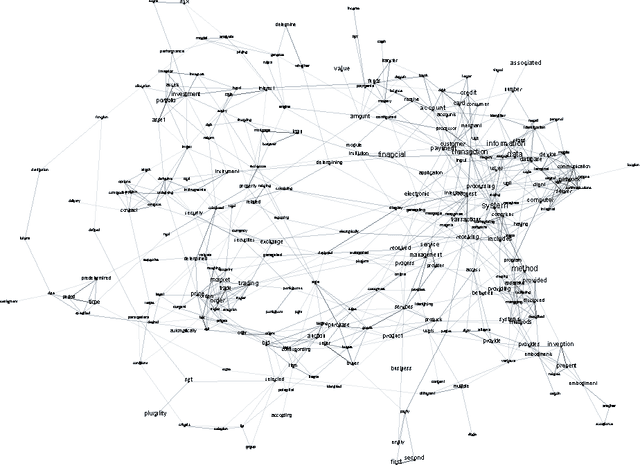
As we continue to collect and store textual data in a multitude of domains, we are regularly confronted with material whose largely unknown thematic structure we want to uncover. With unsupervised, exploratory analysis, no prior knowledge about the content is required and highly open-ended tasks can be supported. In the past few years, probabilistic topic modeling has emerged as a popular approach to this problem. Nevertheless, the representation of the latent topics as aggregations of semi-coherent terms limits their interpretability and level of detail. This paper presents an alternative approach to topic modeling that maps topics as a network for exploration, based on distributional semantics using learned word vectors. From the granular level of terms and their semantic similarity relations global topic structures emerge as clustered regions and gradients of concepts. Moreover, the paper discusses the visual interactive representation of the topic map, which plays an important role in supporting its exploration.
Topic Modeling on Health Journals with Regularized Variational Inference
Jan 15, 2018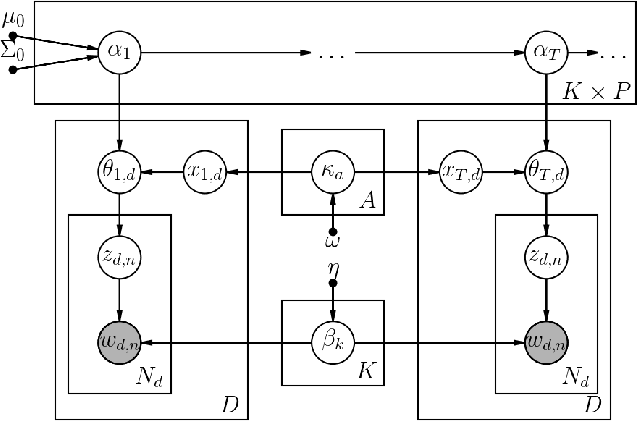

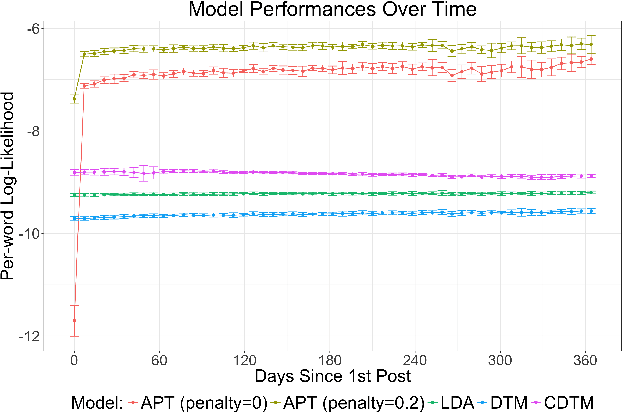
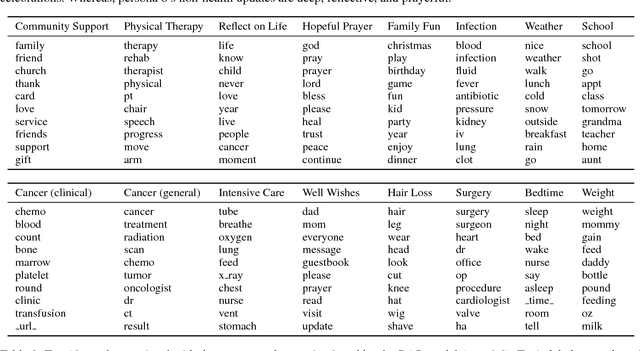
Topic modeling enables exploration and compact representation of a corpus. The CaringBridge (CB) dataset is a massive collection of journals written by patients and caregivers during a health crisis. Topic modeling on the CB dataset, however, is challenging due to the asynchronous nature of multiple authors writing about their health journeys. To overcome this challenge we introduce the Dynamic Author-Persona topic model (DAP), a probabilistic graphical model designed for temporal corpora with multiple authors. The novelty of the DAP model lies in its representation of authors by a persona --- where personas capture the propensity to write about certain topics over time. Further, we present a regularized variational inference algorithm, which we use to encourage the DAP model's personas to be distinct. Our results show significant improvements over competing topic models --- particularly after regularization, and highlight the DAP model's unique ability to capture common journeys shared by different authors.
Fast Clustering and Topic Modeling Based on Rank-2 Nonnegative Matrix Factorization
Oct 02, 2015
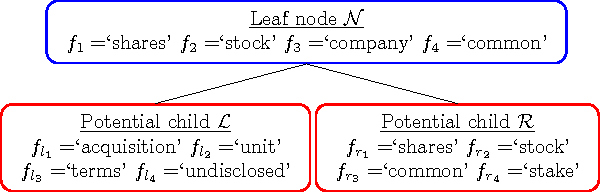

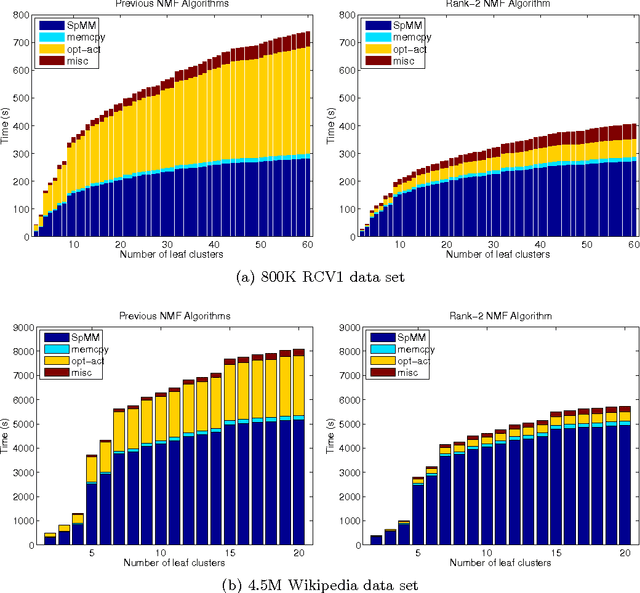
The importance of unsupervised clustering and topic modeling is well recognized with ever-increasing volumes of text data. In this paper, we propose a fast method for hierarchical clustering and topic modeling called HierNMF2. Our method is based on fast Rank-2 nonnegative matrix factorization (NMF) that performs binary clustering and an efficient node splitting rule. Further utilizing the final leaf nodes generated in HierNMF2 and the idea of nonnegative least squares fitting, we propose a new clustering/topic modeling method called FlatNMF2 that recovers a flat clustering/topic modeling result in a very simple yet significantly more effective way than any other existing methods. We implement highly optimized open source software in C++ for both HierNMF2 and FlatNMF2 for hierarchical and partitional clustering/topic modeling of document data sets. Substantial experimental tests are presented that illustrate significant improvements both in computational time as well as quality of solutions. We compare our methods to other clustering methods including K-means, standard NMF, and CLUTO, and also topic modeling methods including latent Dirichlet allocation (LDA) and recently proposed algorithms for NMF with separability constraints. Overall, we present efficient tools for analyzing large-scale data sets, and techniques that can be generalized to many other data analytics problem domains.
Graph Based Long-Term And Short-Term Interest Model for Click-Through Rate Prediction
Jun 05, 2023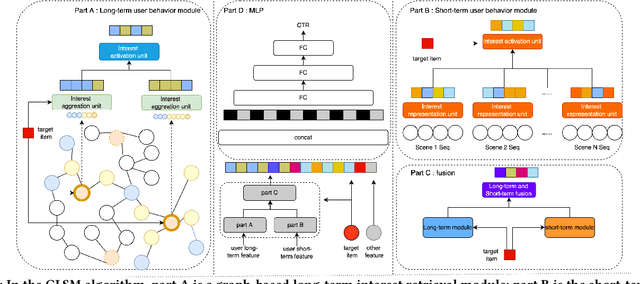
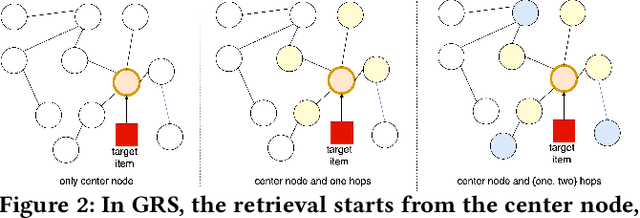
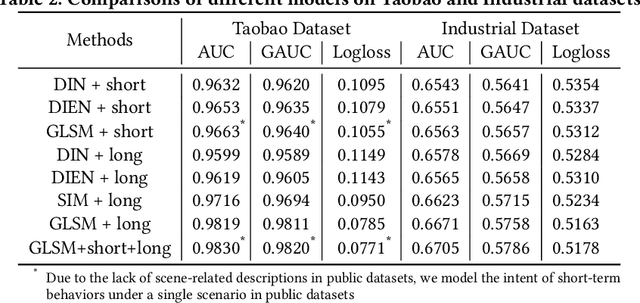
Click-through rate (CTR) prediction aims to predict the probability that the user will click an item, which has been one of the key tasks in online recommender and advertising systems. In such systems, rich user behavior (viz. long- and short-term) has been proved to be of great value in capturing user interests. Both industry and academy have paid much attention to this topic and propose different approaches to modeling with long-term and short-term user behavior data. But there are still some unresolved issues. More specially, (1) rule and truncation based methods to extract information from long-term behavior are easy to cause information loss, and (2) single feedback behavior regardless of scenario to extract information from short-term behavior lead to information confusion and noise. To fill this gap, we propose a Graph based Long-term and Short-term interest Model, termed GLSM. It consists of a multi-interest graph structure for capturing long-term user behavior, a multi-scenario heterogeneous sequence model for modeling short-term information, then an adaptive fusion mechanism to fused information from long-term and short-term behaviors. Comprehensive experiments on real-world datasets, GLSM achieved SOTA score on offline metrics. At the same time, the GLSM algorithm has been deployed in our industrial application, bringing 4.9% CTR and 4.3% GMV lift, which is significant to the business.
A new evaluation framework for topic modeling algorithms based on synthetic corpora
Jan 28, 2019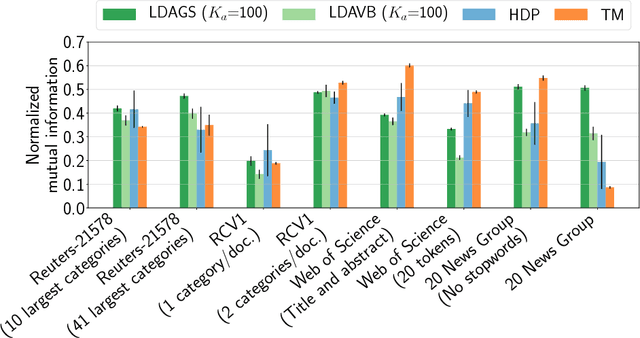
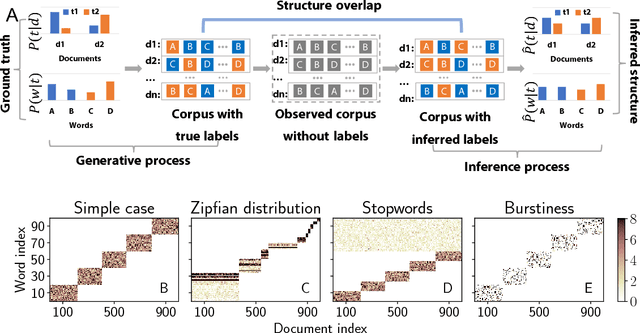
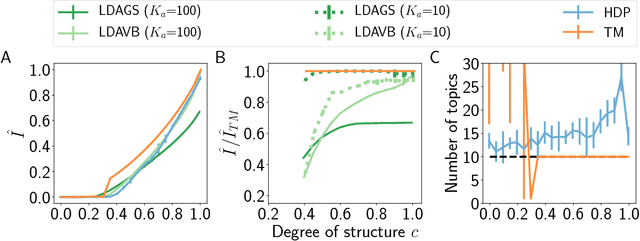
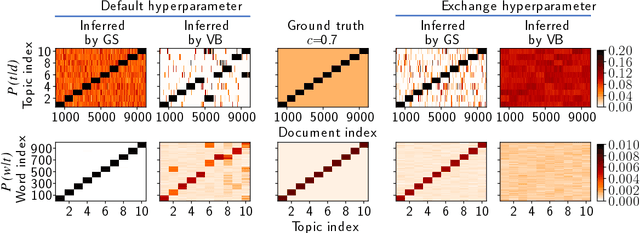
Topic models are in widespread use in natural language processing and beyond. Here, we propose a new framework for the evaluation of probabilistic topic modeling algorithms based on synthetic corpora containing an unambiguously defined ground truth topic structure. The major innovation of our approach is the ability to quantify the agreement between the planted and inferred topic structures by comparing the assigned topic labels at the level of the tokens. In experiments, our approach yields novel insights about the relative strengths of topic models as corpus characteristics vary, and the first evidence of an "undetectable phase" for topic models when the planted structure is weak. We also establish the practical relevance of the insights gained for synthetic corpora by predicting the performance of topic modeling algorithms in classification tasks in real-world corpora.
Generalized Topic Modeling
Nov 04, 2016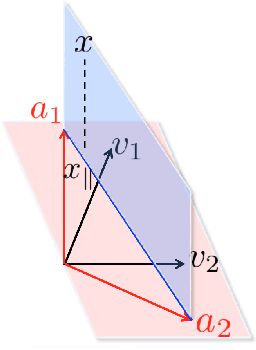
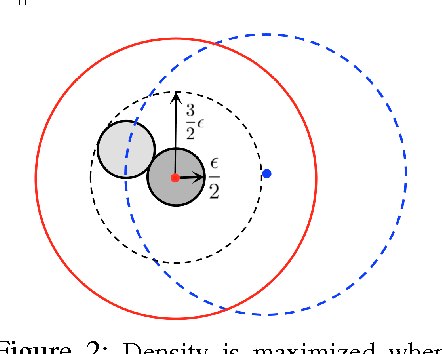
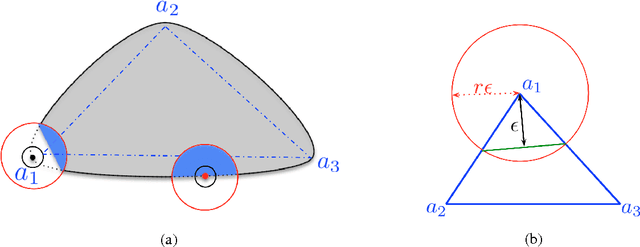
Recently there has been significant activity in developing algorithms with provable guarantees for topic modeling. In standard topic models, a topic (such as sports, business, or politics) is viewed as a probability distribution $\vec a_i$ over words, and a document is generated by first selecting a mixture $\vec w$ over topics, and then generating words i.i.d. from the associated mixture $A{\vec w}$. Given a large collection of such documents, the goal is to recover the topic vectors and then to correctly classify new documents according to their topic mixture. In this work we consider a broad generalization of this framework in which words are no longer assumed to be drawn i.i.d. and instead a topic is a complex distribution over sequences of paragraphs. Since one could not hope to even represent such a distribution in general (even if paragraphs are given using some natural feature representation), we aim instead to directly learn a document classifier. That is, we aim to learn a predictor that given a new document, accurately predicts its topic mixture, without learning the distributions explicitly. We present several natural conditions under which one can do this efficiently and discuss issues such as noise tolerance and sample complexity in this model. More generally, our model can be viewed as a generalization of the multi-view or co-training setting in machine learning.
A Topic Modeling Toolbox Using Belief Propagation
Apr 05, 2012
Latent Dirichlet allocation (LDA) is an important hierarchical Bayesian model for probabilistic topic modeling, which attracts worldwide interests and touches on many important applications in text mining, computer vision and computational biology. This paper introduces a topic modeling toolbox (TMBP) based on the belief propagation (BP) algorithms. TMBP toolbox is implemented by MEX C++/Matlab/Octave for either Windows 7 or Linux. Compared with existing topic modeling packages, the novelty of this toolbox lies in the BP algorithms for learning LDA-based topic models. The current version includes BP algorithms for latent Dirichlet allocation (LDA), author-topic models (ATM), relational topic models (RTM), and labeled LDA (LaLDA). This toolbox is an ongoing project and more BP-based algorithms for various topic models will be added in the near future. Interested users may also extend BP algorithms for learning more complicated topic models. The source codes are freely available under the GNU General Public Licence, Version 1.0 at https://mloss.org/software/view/399/.
* 4 pages
A New Approach to Speeding Up Topic Modeling
Apr 08, 2014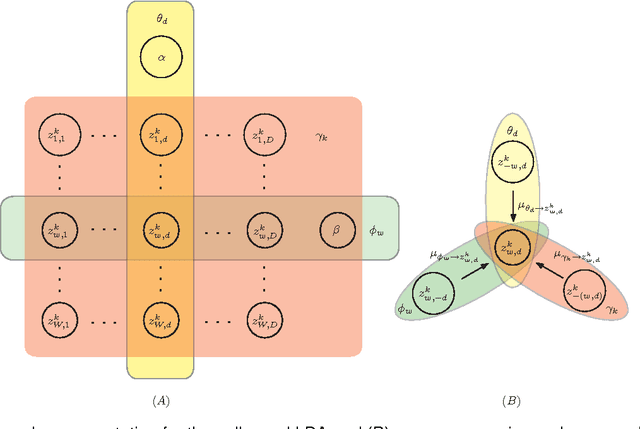
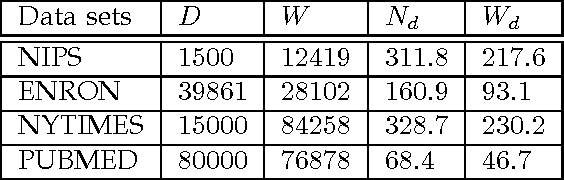

Latent Dirichlet allocation (LDA) is a widely-used probabilistic topic modeling paradigm, and recently finds many applications in computer vision and computational biology. In this paper, we propose a fast and accurate batch algorithm, active belief propagation (ABP), for training LDA. Usually batch LDA algorithms require repeated scanning of the entire corpus and searching the complete topic space. To process massive corpora having a large number of topics, the training iteration of batch LDA algorithms is often inefficient and time-consuming. To accelerate the training speed, ABP actively scans the subset of corpus and searches the subset of topic space for topic modeling, therefore saves enormous training time in each iteration. To ensure accuracy, ABP selects only those documents and topics that contribute to the largest residuals within the residual belief propagation (RBP) framework. On four real-world corpora, ABP performs around $10$ to $100$ times faster than state-of-the-art batch LDA algorithms with a comparable topic modeling accuracy.
Natural Language Processing of Aviation Occurrence Reports for Safety Management
Jan 13, 2023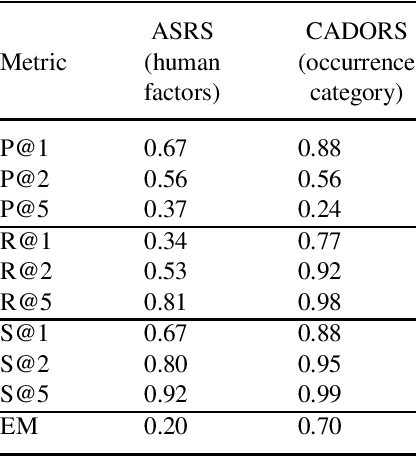
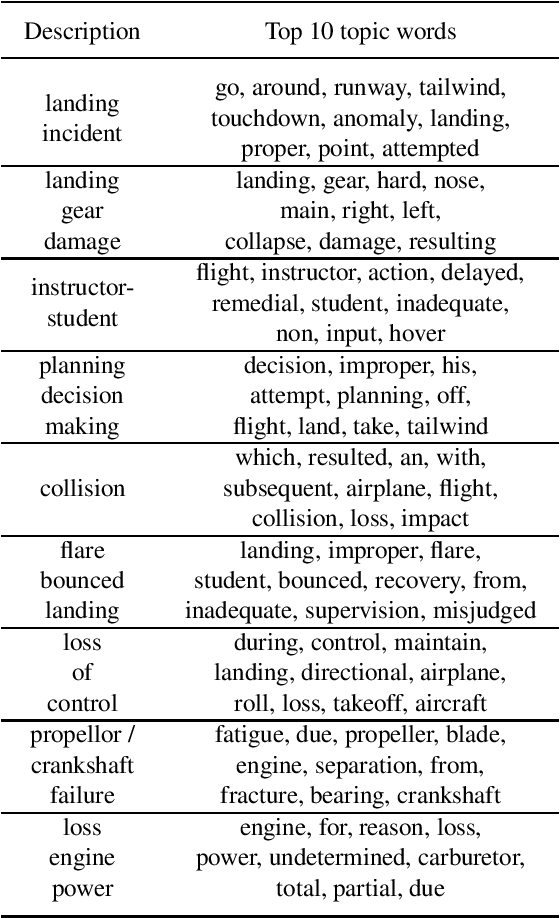
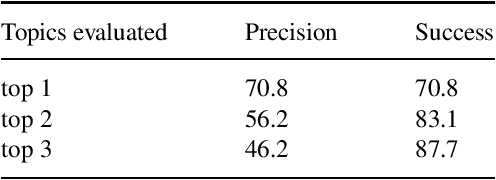

Occurrence reporting is a commonly used method in safety management systems to obtain insight in the prevalence of hazards and accident scenarios. In support of safety data analysis, reports are often categorized according to a taxonomy. However, the processing of the reports can require significant effort from safety analysts and a common problem is interrater variability in labeling processes. Also, in some cases, reports are not processed according to a taxonomy, or the taxonomy does not fully cover the contents of the documents. This paper explores various Natural Language Processing (NLP) methods to support the analysis of aviation safety occurrence reports. In particular, the problems studied are the automatic labeling of reports using a classification model, extracting the latent topics in a collection of texts using a topic model and the automatic generation of probable cause texts. Experimental results showed that (i) under the right conditions the labeling of occurrence reports can be effectively automated with a transformer-based classifier, (ii) topic modeling can be useful for finding the topics present in a collection of reports, and (iii) using a summarization model can be a promising direction for generating probable cause texts.
Cross-referencing using Fine-grained Topic Modeling
May 18, 2019

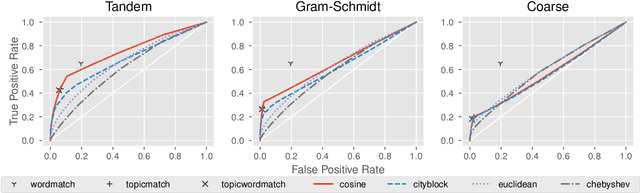
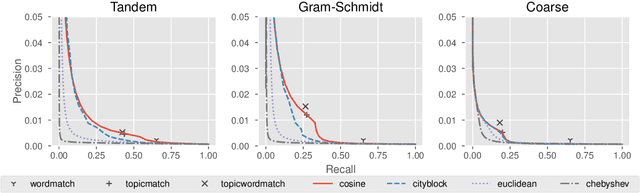
Cross-referencing, which links passages of text to other related passages, can be a valuable study aid for facilitating comprehension of a text. However, cross-referencing requires first, a comprehensive thematic knowledge of the entire corpus, and second, a focused search through the corpus specifically to find such useful connections. Due to this, cross-reference resources are prohibitively expensive and exist only for the most well-studied texts (e.g. religious texts). We develop a topic-based system for automatically producing candidate cross-references which can be easily verified by human annotators. Our system utilizes fine-grained topic modeling with thousands of highly nuanced and specific topics to identify verse pairs which are topically related. We demonstrate that our system can be cost effective compared to having annotators acquire the expertise necessary to produce cross-reference resources unaided.