 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
Multi-view and Multi-source Transfers in Neural Topic Modeling with Pretrained Topic and Word Embeddings
Sep 17, 2019

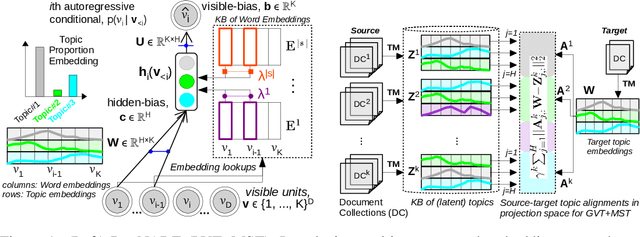
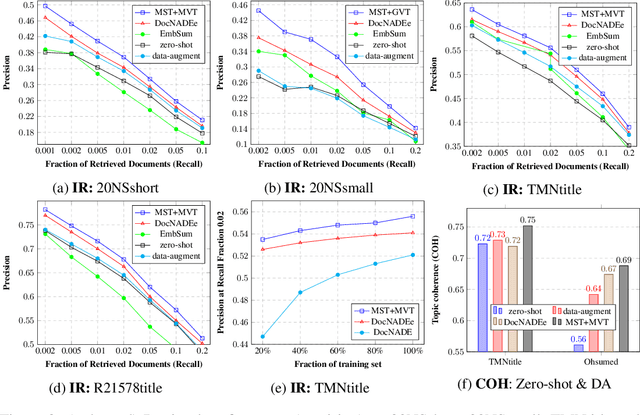
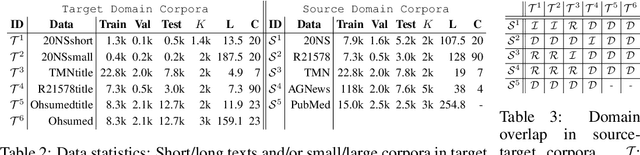
Though word embeddings and topics are complementary representations, several past works have only used pre-trained word embeddings in (neural) topic modeling to address data sparsity problem in short text or small collection of documents. However, no prior work has employed (pre-trained latent) topics in transfer learning paradigm. In this paper, we propose an approach to (1) perform knowledge transfer using latent topics obtained from a large source corpus, and (2) jointly transfer knowledge via the two representations (or views) in neural topic modeling to improve topic quality, better deal with polysemy and data sparsity issues in a target corpus. In doing so, we first accumulate topics and word representations from one or many source corpora to build a pool of topics and word vectors. Then, we identify one or multiple relevant source domain(s) and take advantage of corresponding topics and word features via the respective pools to guide meaningful learning in the sparse target domain. We quantify the quality of topic and document representations via generalization (perplexity), interpretability (topic coherence) and information retrieval (IR) using short-text, long-text, small and large document collections from news and medical domains. We have demonstrated the state-of-the-art results on topic modeling with the proposed framework.
Aircraft Environmental Impact Segmentation via Metric Learning
Jun 24, 2023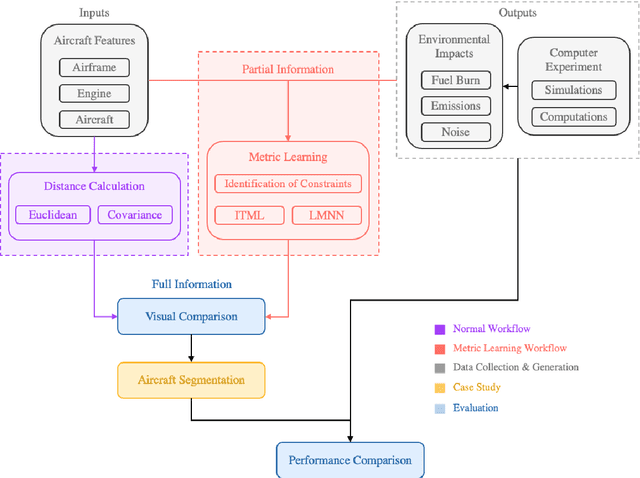

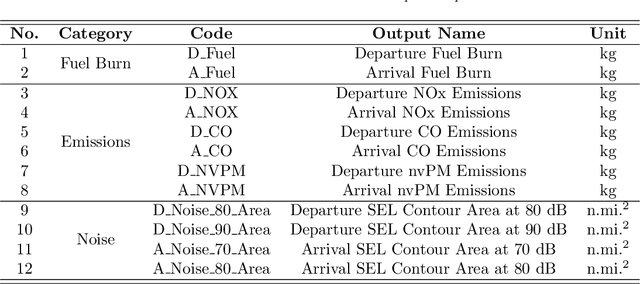
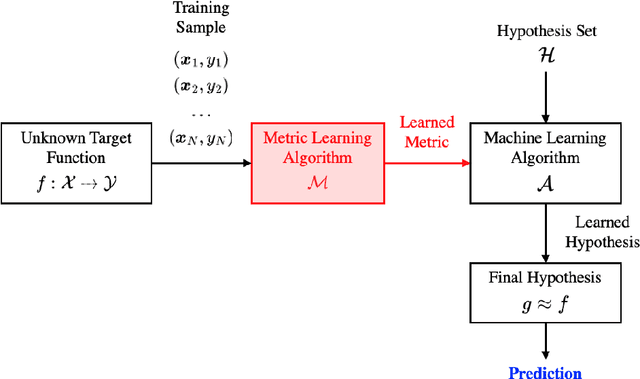
Metric learning is the process of learning a tailored distance metric for a particular task. This advanced subfield of machine learning is useful to any machine learning or data mining task that relies on the computation of distances or similarities over objects. In recently years, machine learning techniques have been extensively used in aviation and aerospace engineering to make predictions, extract patterns, discover knowledge, etc. Nevertheless, metric learning, an element that can advance the performance of complex machine learning tasks, has so far been hardly utilized in relevant literature. In this study, we apply classic metric learning formulations with novel components on aviation environmental impact modeling. Through a weakly-supervised metric learning task, we achieve significant improvement in the newly emerged problem of aircraft characterization and segmentation for environmental impacts. The result will enable the more efficient and accurate modeling of aircraft environmental impacts, a focal topic in sustainable aviation. This work is also a demonstration that shows the potential and value of metric learning in a wide variety of similar studies in the transportation domain.
Anchored Correlation Explanation: Topic Modeling with Minimal Domain Knowledge
Sep 03, 2018While generative models such as Latent Dirichlet Allocation (LDA) have proven fruitful in topic modeling, they often require detailed assumptions and careful specification of hyperparameters. Such model complexity issues only compound when trying to generalize generative models to incorporate human input. We introduce Correlation Explanation (CorEx), an alternative approach to topic modeling that does not assume an underlying generative model, and instead learns maximally informative topics through an information-theoretic framework. This framework naturally generalizes to hierarchical and semi-supervised extensions with no additional modeling assumptions. In particular, word-level domain knowledge can be flexibly incorporated within CorEx through anchor words, allowing topic separability and representation to be promoted with minimal human intervention. Across a variety of datasets, metrics, and experiments, we demonstrate that CorEx produces topics that are comparable in quality to those produced by unsupervised and semi-supervised variants of LDA.
* 21 pages, 7 figures. 2018/09/03: Updated citation for HA/DR dataset
Anchor Prediction: A Topic Modeling Approach
Jun 01, 2022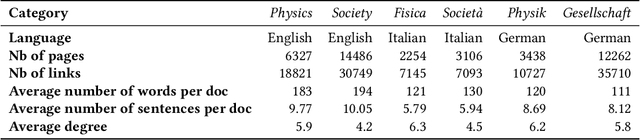
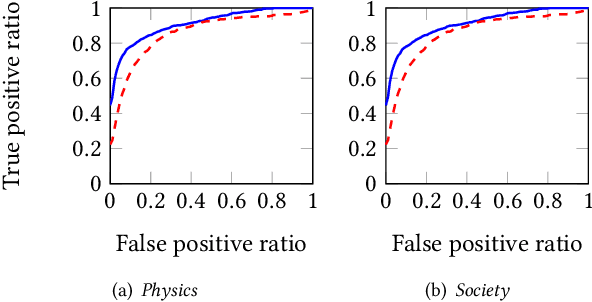
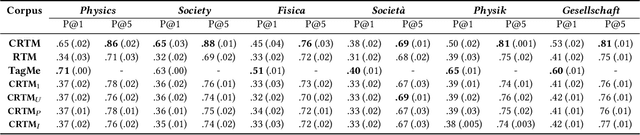

Networks of documents connected by hyperlinks, such as Wikipedia, are ubiquitous. Hyperlinks are inserted by the authors to enrich the text and facilitate the navigation through the network. However, authors tend to insert only a fraction of the relevant hyperlinks, mainly because this is a time consuming task. In this paper we address an annotation, which we refer to as anchor prediction. Even though it is conceptually close to link prediction or entity linking, it is a different task that require developing a specific method to solve it. Given a source document and a target document, this task consists in automatically identifying anchors in the source document, i.e words or terms that should carry a hyperlink pointing towards the target document. We propose a contextualized relational topic model, CRTM, that models directed links between documents as a function of the local context of the anchor in the source document and the whole content of the target document. The model can be used to predict anchors in a source document, given the target document, without relying on a dictionary of previously seen mention or title, nor any external knowledge graph. Authors can benefit from CRTM, by letting it automatically suggest hyperlinks, given a new document and the set of target document to connect to. It can also benefit to readers, by dynamically inserting hyperlinks between the documents they're reading. Experiments conducted on several Wikipedia corpora (in English, Italian and German) highlight the practical usefulness of anchor prediction and demonstrate the relevancy of our approach.
Conceptualization Topic Modeling
Apr 07, 2017
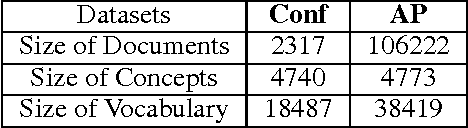
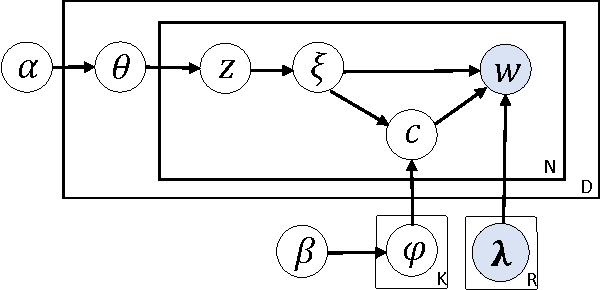
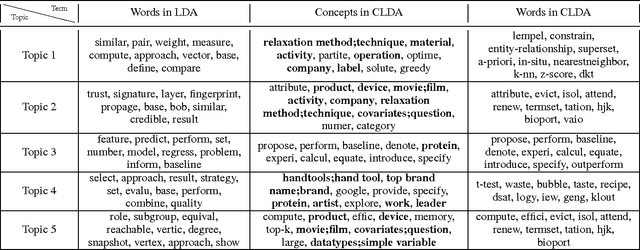
Recently, topic modeling has been widely used to discover the abstract topics in text corpora. Most of the existing topic models are based on the assumption of three-layer hierarchical Bayesian structure, i.e. each document is modeled as a probability distribution over topics, and each topic is a probability distribution over words. However, the assumption is not optimal. Intuitively, it's more reasonable to assume that each topic is a probability distribution over concepts, and then each concept is a probability distribution over words, i.e. adding a latent concept layer between topic layer and word layer in traditional three-layer assumption. In this paper, we verify the proposed assumption by incorporating the new assumption in two representative topic models, and obtain two novel topic models. Extensive experiments were conducted among the proposed models and corresponding baselines, and the results show that the proposed models significantly outperform the baselines in terms of case study and perplexity, which means the new assumption is more reasonable than traditional one.
Ordering-sensitive and Semantic-aware Topic Modeling
Feb 12, 2015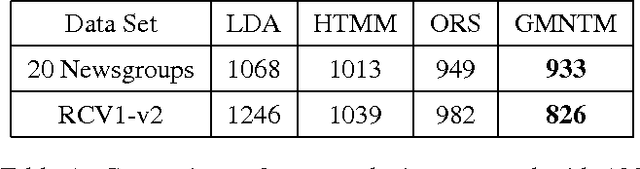
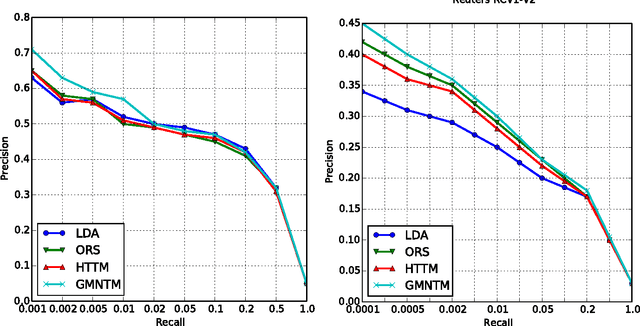
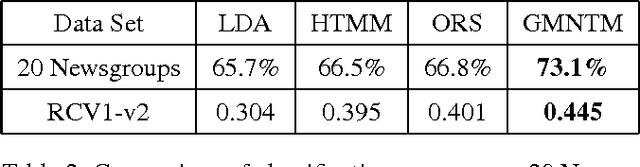
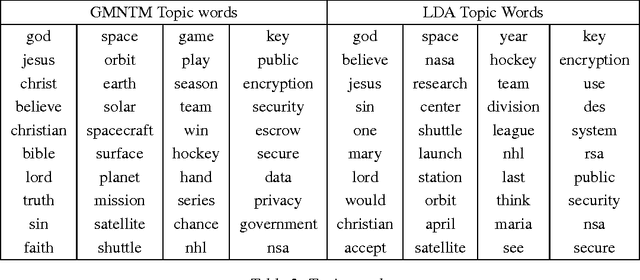
Topic modeling of textual corpora is an important and challenging problem. In most previous work, the "bag-of-words" assumption is usually made which ignores the ordering of words. This assumption simplifies the computation, but it unrealistically loses the ordering information and the semantic of words in the context. In this paper, we present a Gaussian Mixture Neural Topic Model (GMNTM) which incorporates both the ordering of words and the semantic meaning of sentences into topic modeling. Specifically, we represent each topic as a cluster of multi-dimensional vectors and embed the corpus into a collection of vectors generated by the Gaussian mixture model. Each word is affected not only by its topic, but also by the embedding vector of its surrounding words and the context. The Gaussian mixture components and the topic of documents, sentences and words can be learnt jointly. Extensive experiments show that our model can learn better topics and more accurate word distributions for each topic. Quantitatively, comparing to state-of-the-art topic modeling approaches, GMNTM obtains significantly better performance in terms of perplexity, retrieval accuracy and classification accuracy.
AOBTM: Adaptive Online Biterm Topic Modeling for Version Sensitive Short-texts Analysis
Sep 13, 2020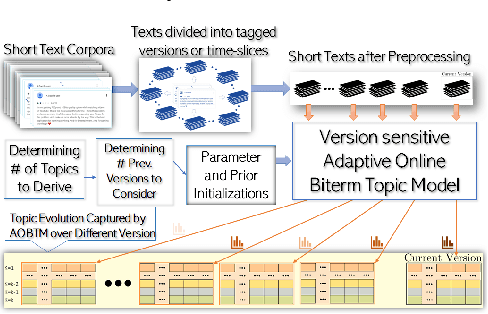
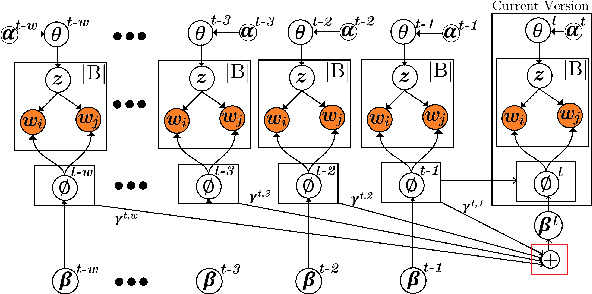
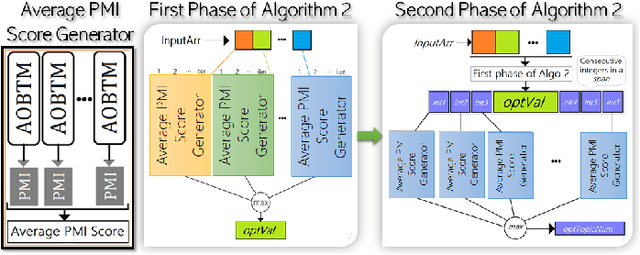
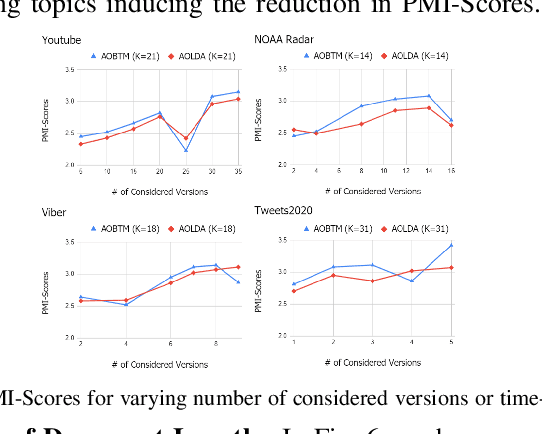
Analysis of mobile app reviews has shown its important role in requirement engineering, software maintenance and evolution of mobile apps. Mobile app developers check their users' reviews frequently to clarify the issues experienced by users or capture the new issues that are introduced due to a recent app update. App reviews have a dynamic nature and their discussed topics change over time. The changes in the topics among collected reviews for different versions of an app can reveal important issues about the app update. A main technique in this analysis is using topic modeling algorithms. However, app reviews are short texts and it is challenging to unveil their latent topics over time. Conventional topic models suffer from the sparsity of word co-occurrence patterns while inferring topics for short texts. Furthermore, these algorithms cannot capture topics over numerous consecutive time-slices. Online topic modeling algorithms speed up the inference of topic models for the texts collected in the latest time-slice by saving a fraction of data from the previous time-slice. But these algorithms do not analyze the statistical-data of all the previous time-slices, which can confer contributions to the topic distribution of the current time-slice. We propose Adaptive Online Biterm Topic Model (AOBTM) to model topics in short texts adaptively. AOBTM alleviates the sparsity problem in short-texts and considers the statistical-data for an optimal number of previous time-slices. We also propose parallel algorithms to automatically determine the optimal number of topics and the best number of previous versions that should be considered in topic inference phase. Automatic evaluation on collections of app reviews and real-world short text datasets confirm that AOBTM can find more coherent topics and outperforms the state-of-the-art baselines.
Experiments on Generalizability of BERTopic on Multi-Domain Short Text
Dec 16, 2022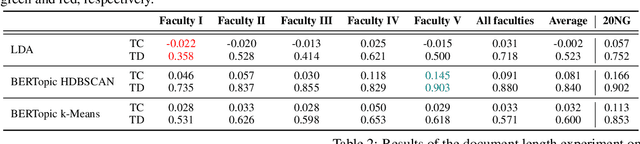
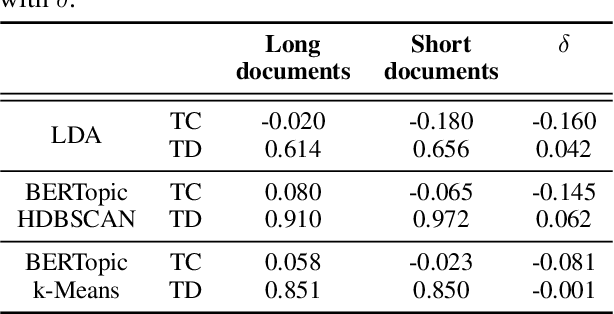
Topic modeling is widely used for analytically evaluating large collections of textual data. One of the most popular topic techniques is Latent Dirichlet Allocation (LDA), which is flexible and adaptive, but not optimal for e.g. short texts from various domains. We explore how the state-of-the-art BERTopic algorithm performs on short multi-domain text and find that it generalizes better than LDA in terms of topic coherence and diversity. We further analyze the performance of the HDBSCAN clustering algorithm utilized by BERTopic and find that it classifies a majority of the documents as outliers. This crucial, yet overseen problem excludes too many documents from further analysis. When we replace HDBSCAN with k-Means, we achieve similar performance, but without outliers.
Moving beyond word lists: towards abstractive topic labels for human-like topics of scientific documents
Oct 28, 2022
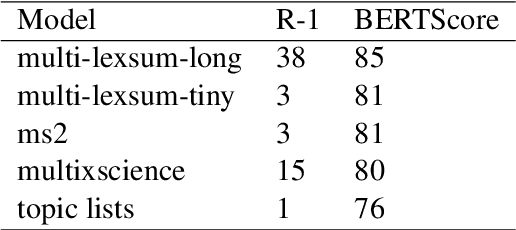
Topic models represent groups of documents as a list of words (the topic labels). This work asks whether an alternative approach to topic labeling can be developed that is closer to a natural language description of a topic than a word list. To this end, we present an approach to generating human-like topic labels using abstractive multi-document summarization (MDS). We investigate our approach with an exploratory case study. We model topics in citation sentences in order to understand what further research needs to be done to fully operationalize MDS for topic labeling. Our case study shows that in addition to more human-like topics there are additional advantages to evaluation by using clustering and summarization measures instead of topic model measures. However, we find that there are several developments needed before we can design a well-powered study to evaluate MDS for topic modeling fully. Namely, improving cluster cohesion, improving the factuality and faithfulness of MDS, and increasing the number of documents that might be supported by MDS. We present a number of ideas on how these can be tackled and conclude with some thoughts on how topic modeling can also be used to improve MDS in general.
ContCommRTD: A Distributed Content-based Misinformation-aware Community Detection System for Real-Time Disaster Reporting
Jan 30, 2023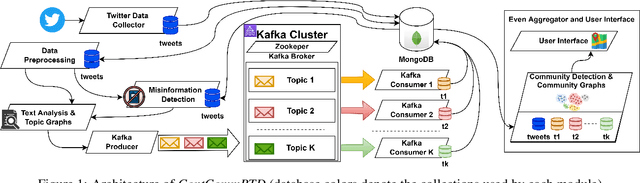
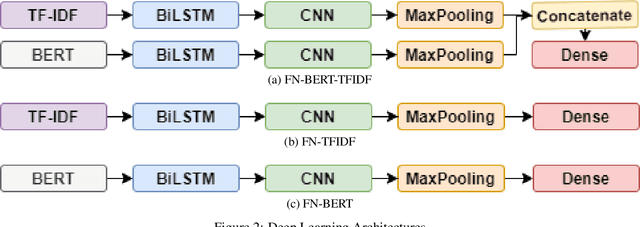
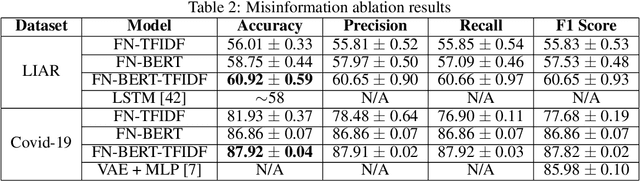
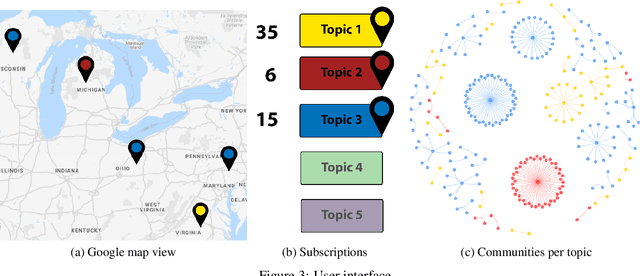
Real-time social media data can provide useful information on evolving hazards. Alongside traditional methods of disaster detection, the integration of social media data can considerably enhance disaster management. In this paper, we investigate the problem of detecting geolocation-content communities on Twitter and propose a novel distributed system that provides in near real-time information on hazard-related events and their evolution. We show that content-based community analysis leads to better and faster dissemination of reports on hazards. Our distributed disaster reporting system analyzes the social relationship among worldwide geolocated tweets, and applies topic modeling to group tweets by topics. Considering for each tweet the following information: user, timestamp, geolocation, retweets, and replies, we create a publisher-subscriber distribution model for topics. We use content similarity and the proximity of nodes to create a new model for geolocation-content based communities. Users can subscribe to different topics in specific geographical areas or worldwide and receive real-time reports regarding these topics. As misinformation can lead to increase damage if propagated in hazards related tweets, we propose a new deep learning model to detect fake news. The misinformed tweets are then removed from display. We also show empirically the scalability capabilities of the proposed system.