 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
1st Place Solution of Egocentric 3D Hand Pose Estimation Challenge 2023 Technical Report:A Concise Pipeline for Egocentric Hand Pose Reconstruction
Oct 10, 2023
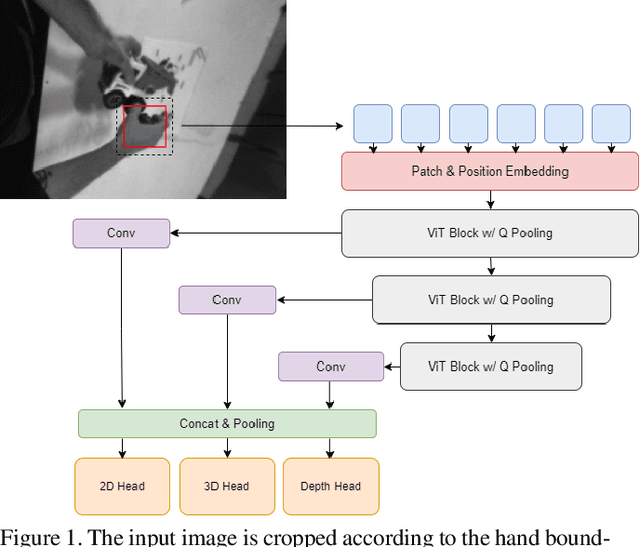

This report introduce our work on Egocentric 3D Hand Pose Estimation workshop. Using AssemblyHands, this challenge focuses on egocentric 3D hand pose estimation from a single-view image. In the competition, we adopt ViT based backbones and a simple regressor for 3D keypoints prediction, which provides strong model baselines. We noticed that Hand-objects occlusions and self-occlusions lead to performance degradation, thus proposed a non-model method to merge multi-view results in the post-process stage. Moreover, We utilized test time augmentation and model ensemble to make further improvement. We also found that public dataset and rational preprocess are beneficial. Our method achieved 12.21mm MPJPE on test dataset, achieve the first place in Egocentric 3D Hand Pose Estimation challenge.
Advanced Deep Regression Models for Forecasting Time Series Oil Production
Aug 30, 2023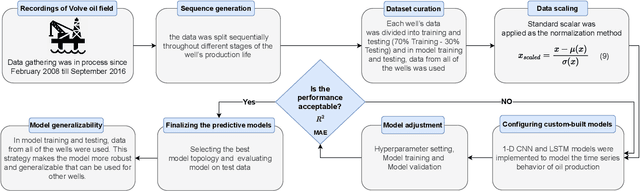
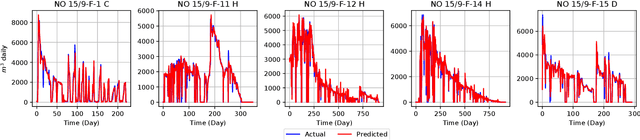
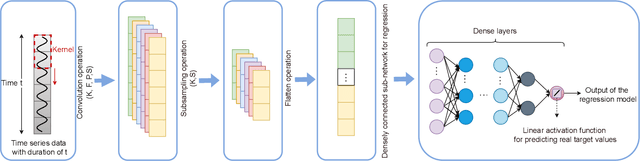
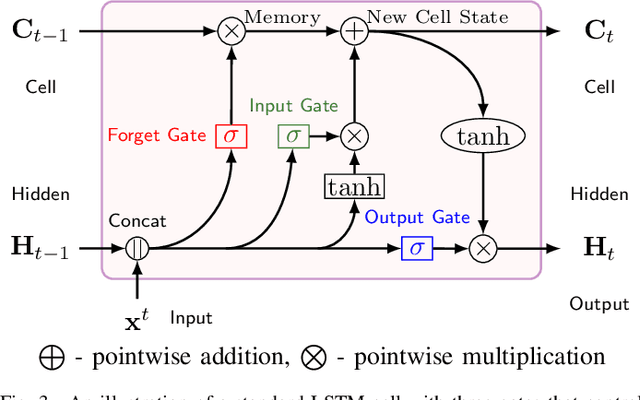
Global oil demand is rapidly increasing and is expected to reach 106.3 million barrels per day by 2040. Thus, it is vital for hydrocarbon extraction industries to forecast their production to optimize their operations and avoid losses. Big companies have realized that exploiting the power of deep learning (DL) and the massive amount of data from various oil wells for this purpose can save a lot of operational costs and reduce unwanted environmental impacts. In this direction, researchers have proposed models using conventional machine learning (ML) techniques for oil production forecasting. However, these techniques are inappropriate for this problem as they can not capture historical patterns found in time series data, resulting in inaccurate predictions. This research aims to overcome these issues by developing advanced data-driven regression models using sequential convolutions and long short-term memory (LSTM) units. Exhaustive analyses are conducted to select the optimal sequence length, model hyperparameters, and cross-well dataset formation to build highly generalized robust models. A comprehensive experimental study on Volve oilfield data validates the proposed models. It reveals that the LSTM-based sequence learning model can predict oil production better than the 1-D convolutional neural network (CNN) with mean absolute error (MAE) and R2 score of 111.16 and 0.98, respectively. It is also found that the LSTM-based model performs better than all the existing state-of-the-art solutions and achieves a 37% improvement compared to a standard linear regression, which is considered the baseline model in this work.
Graph data modelling for outcome prediction in oropharyngeal cancer patients
Oct 04, 2023Graph neural networks (GNNs) are becoming increasingly popular in the medical domain for the tasks of disease classification and outcome prediction. Since patient data is not readily available as a graph, most existing methods either manually define a patient graph, or learn a latent graph based on pairwise similarities between the patients. There are also hypergraph neural network (HGNN)-based methods that were introduced recently to exploit potential higher order associations between the patients by representing them as a hypergraph. In this work, we propose a patient hypergraph network (PHGN), which has been investigated in an inductive learning setup for binary outcome prediction in oropharyngeal cancer (OPC) patients using computed tomography (CT)-based radiomic features for the first time. Additionally, the proposed model was extended to perform time-to-event analyses, and compared with GNN and baseline linear models.
Optimal Scheduling of Electric Vehicle Charging with Deep Reinforcement Learning considering End Users Flexibility
Oct 13, 2023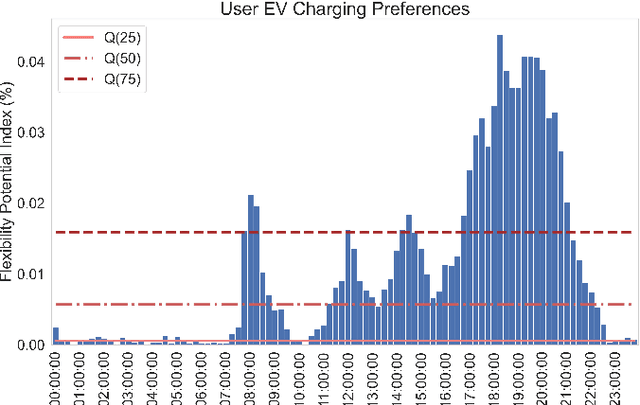
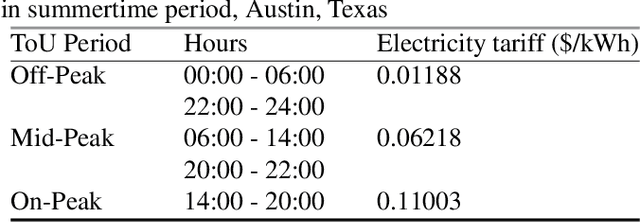
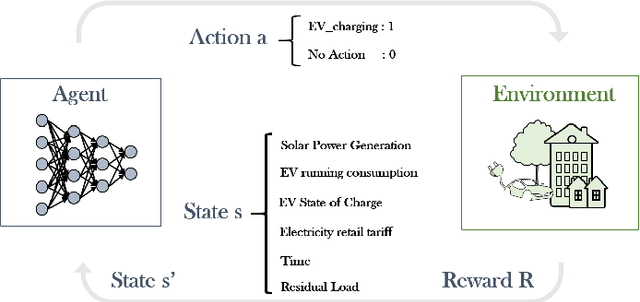
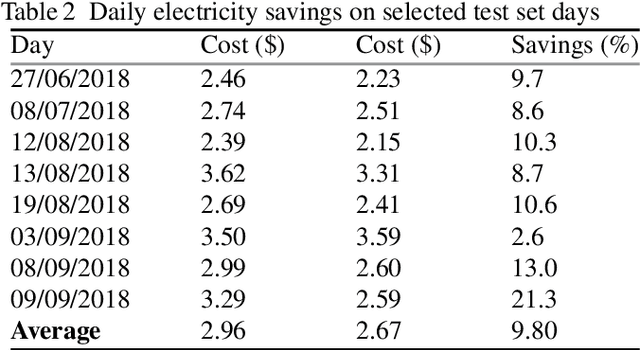
The rapid growth of decentralized energy resources and especially Electric Vehicles (EV), that are expected to increase sharply over the next decade, will put further stress on existing power distribution networks, increasing the need for higher system reliability and flexibility. In an attempt to avoid unnecessary network investments and to increase the controllability over distribution networks, network operators develop demand response (DR) programs that incentivize end users to shift their consumption in return for financial or other benefits. Artificial intelligence (AI) methods are in the research forefront for residential load scheduling applications, mainly due to their high accuracy, high computational speed and lower dependence on the physical characteristics of the models under development. The aim of this work is to identify households' EV cost-reducing charging policy under a Time-of-Use tariff scheme, with the use of Deep Reinforcement Learning, and more specifically Deep Q-Networks (DQN). A novel end users flexibility potential reward is inferred from historical data analysis, where households with solar power generation have been used to train and test the designed algorithm. The suggested DQN EV charging policy can lead to more than 20% of savings in end users electricity bills.
PromptRE: Weakly-Supervised Document-Level Relation Extraction via Prompting-Based Data Programming
Oct 13, 2023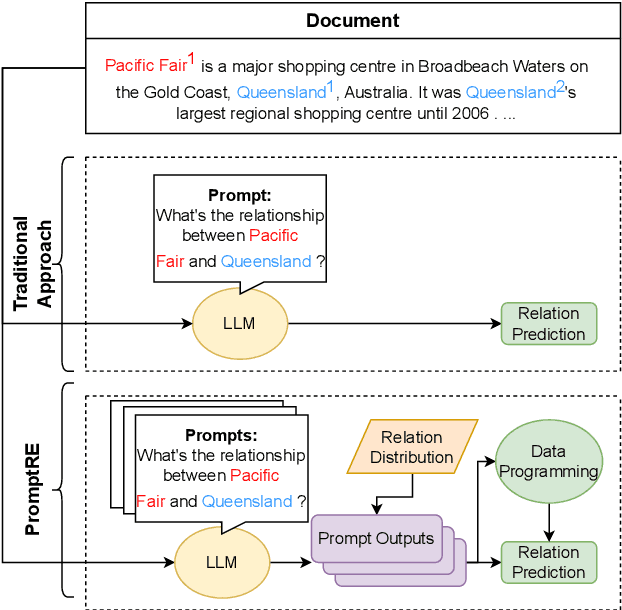
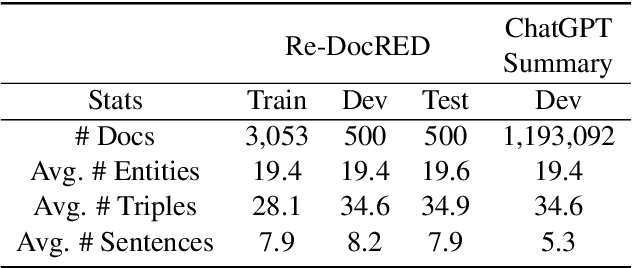
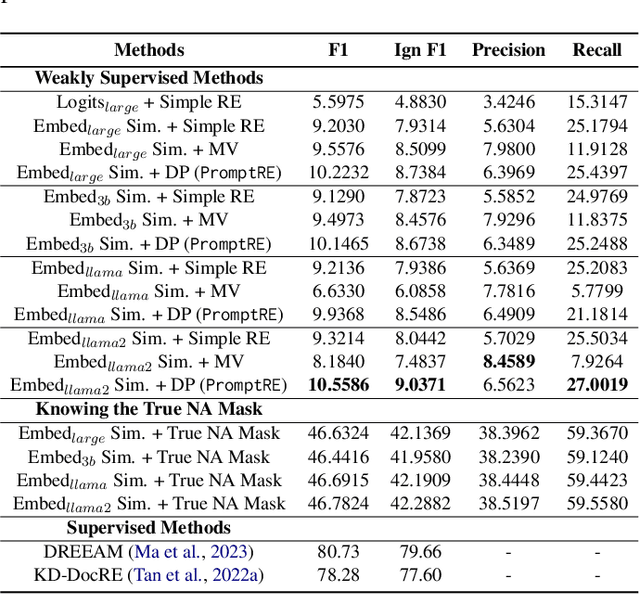
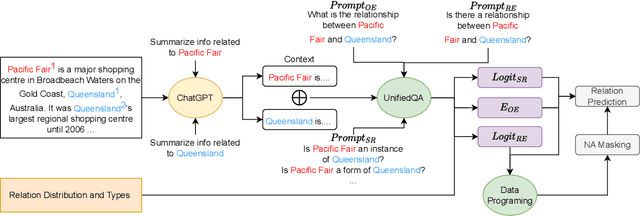
Relation extraction aims to classify the relationships between two entities into pre-defined categories. While previous research has mainly focused on sentence-level relation extraction, recent studies have expanded the scope to document-level relation extraction. Traditional relation extraction methods heavily rely on human-annotated training data, which is time-consuming and labor-intensive. To mitigate the need for manual annotation, recent weakly-supervised approaches have been developed for sentence-level relation extraction while limited work has been done on document-level relation extraction. Weakly-supervised document-level relation extraction faces significant challenges due to an imbalanced number "no relation" instances and the failure of directly probing pretrained large language models for document relation extraction. To address these challenges, we propose PromptRE, a novel weakly-supervised document-level relation extraction method that combines prompting-based techniques with data programming. Furthermore, PromptRE incorporates the label distribution and entity types as prior knowledge to improve the performance. By leveraging the strengths of both prompting and data programming, PromptRE achieves improved performance in relation classification and effectively handles the "no relation" problem. Experimental results on ReDocRED, a benchmark dataset for document-level relation extraction, demonstrate the superiority of PromptRE over baseline approaches.
Recognition of Heat-Induced Food State Changes by Time-Series Use of Vision-Language Model for Cooking Robot
Sep 06, 2023Cooking tasks are characterized by large changes in the state of the food, which is one of the major challenges in robot execution of cooking tasks. In particular, cooking using a stove to apply heat to the foodstuff causes many special state changes that are not seen in other tasks, making it difficult to design a recognizer. In this study, we propose a unified method for recognizing changes in the cooking state of robots by using the vision-language model that can discriminate open-vocabulary objects in a time-series manner. We collected data on four typical state changes in cooking using a real robot and confirmed the effectiveness of the proposed method. We also compared the conditions and discussed the types of natural language prompts and the image regions that are suitable for recognizing the state changes.
Towards Real-Time Analysis of Broadcast Badminton Videos
Aug 23, 2023

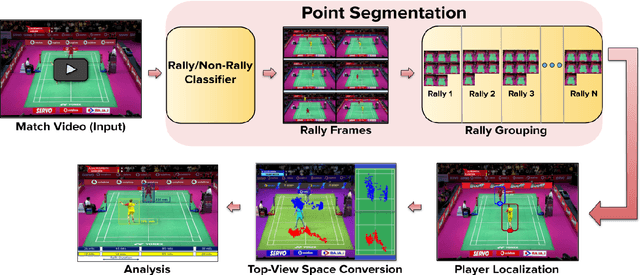

Analysis of player movements is a crucial subset of sports analysis. Existing player movement analysis methods use recorded videos after the match is over. In this work, we propose an end-to-end framework for player movement analysis for badminton matches on live broadcast match videos. We only use the visual inputs from the match and, unlike other approaches which use multi-modal sensor data, our approach uses only visual cues. We propose a method to calculate the on-court distance covered by both the players from the video feed of a live broadcast badminton match. To perform this analysis, we focus on the gameplay by removing replays and other redundant parts of the broadcast match. We then perform player tracking to identify and track the movements of both players in each frame. Finally, we calculate the distance covered by each player and the average speed with which they move on the court. We further show a heatmap of the areas covered by the player on the court which is useful for analyzing the gameplay of the player. Our proposed framework was successfully used to analyze live broadcast matches in real-time during the Premier Badminton League 2019 (PBL 2019), with commentators and broadcasters appreciating the utility.
Predicting Future Spatiotemporal Occupancy Grids with Semantics for Autonomous Driving
Oct 03, 2023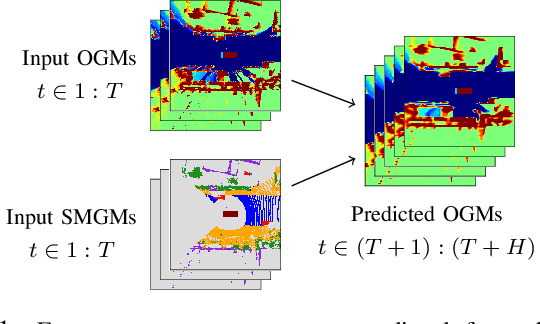
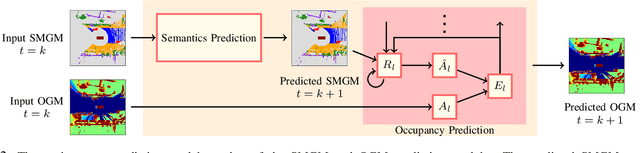
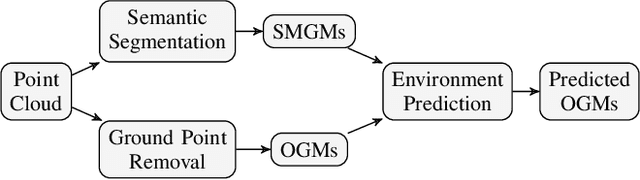
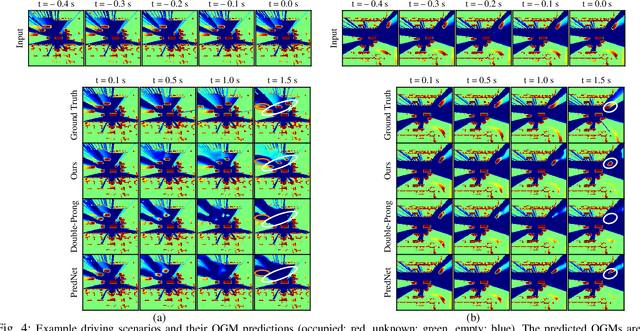
For autonomous vehicles to proactively plan safe trajectories and make informed decisions, they must be able to predict the future occupancy states of the local environment. However, common issues with occupancy prediction include predictions where moving objects vanish or become blurred, particularly at longer time horizons. We propose an environment prediction framework that incorporates environment semantics for future occupancy prediction. Our method first semantically segments the environment and uses this information along with the occupancy information to predict the spatiotemporal evolution of the environment. We validate our approach on the real-world Waymo Open Dataset. Compared to baseline methods, our model has higher prediction accuracy and is capable of maintaining moving object appearances in the predictions for longer prediction time horizons.
STORM: Efficient Stochastic Transformer based World Models for Reinforcement Learning
Oct 14, 2023Recently, model-based reinforcement learning algorithms have demonstrated remarkable efficacy in visual input environments. These approaches begin by constructing a parameterized simulation world model of the real environment through self-supervised learning. By leveraging the imagination of the world model, the agent's policy is enhanced without the constraints of sampling from the real environment. The performance of these algorithms heavily relies on the sequence modeling and generation capabilities of the world model. However, constructing a perfectly accurate model of a complex unknown environment is nearly impossible. Discrepancies between the model and reality may cause the agent to pursue virtual goals, resulting in subpar performance in the real environment. Introducing random noise into model-based reinforcement learning has been proven beneficial. In this work, we introduce Stochastic Transformer-based wORld Model (STORM), an efficient world model architecture that combines the strong sequence modeling and generation capabilities of Transformers with the stochastic nature of variational autoencoders. STORM achieves a mean human performance of $126.7\%$ on the Atari $100$k benchmark, setting a new record among state-of-the-art methods that do not employ lookahead search techniques. Moreover, training an agent with $1.85$ hours of real-time interaction experience on a single NVIDIA GeForce RTX 3090 graphics card requires only $4.3$ hours, showcasing improved efficiency compared to previous methodologies.
Swin-Tempo: Temporal-Aware Lung Nodule Detection in CT Scans as Video Sequences Using Swin Transformer-Enhanced UNet
Oct 14, 2023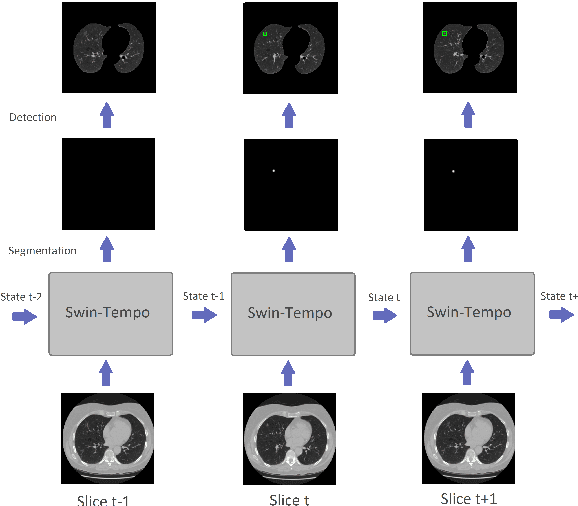

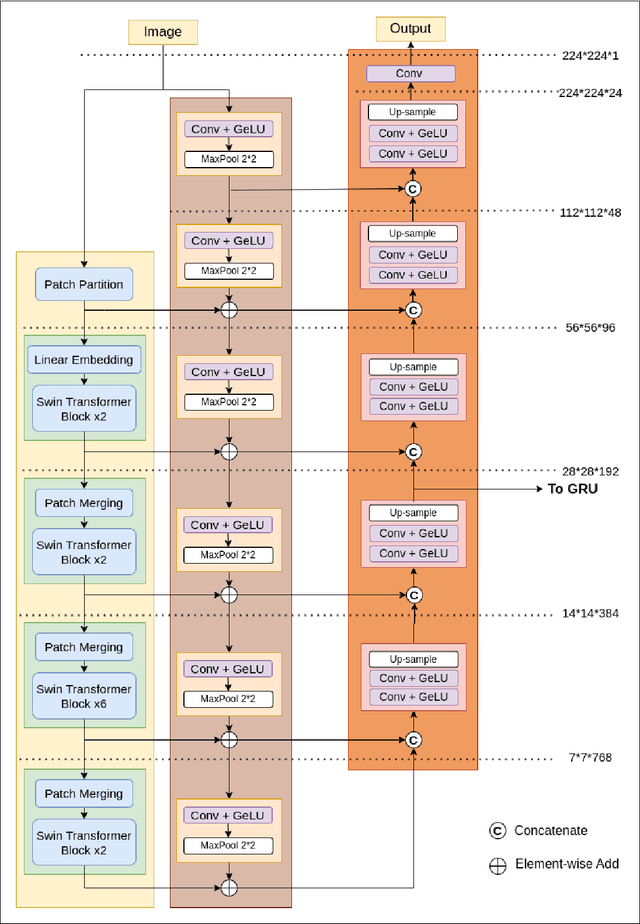
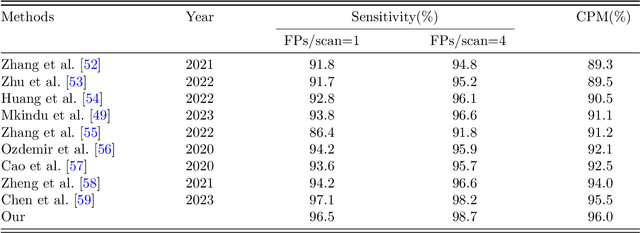
Lung cancer is highly lethal, emphasizing the critical need for early detection. However, identifying lung nodules poses significant challenges for radiologists, who rely heavily on their expertise for accurate diagnosis. To address this issue, computer-aided diagnosis (CAD) systems based on machine learning techniques have emerged to assist doctors in identifying lung nodules from computed tomography (CT) scans. Unfortunately, existing networks in this domain often suffer from computational complexity, leading to high rates of false negatives and false positives, limiting their effectiveness. To address these challenges, we present an innovative model that harnesses the strengths of both convolutional neural networks and vision transformers. Inspired by object detection in videos, we treat each 3D CT image as a video, individual slices as frames, and lung nodules as objects, enabling a time-series application. The primary objective of our work is to overcome hardware limitations during model training, allowing for efficient processing of 2D data while utilizing inter-slice information for accurate identification based on 3D image context. We validated the proposed network by applying a 10-fold cross-validation technique to the publicly available Lung Nodule Analysis 2016 dataset. Our proposed architecture achieves an average sensitivity criterion of 97.84% and a competition performance metrics (CPM) of 96.0% with few parameters. Comparative analysis with state-of-the-art advancements in lung nodule identification demonstrates the significant accuracy achieved by our proposed model.