 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Hierarchical Evaluation Framework: Best Practices for Human Evaluation
Oct 12, 2023
Human evaluation plays a crucial role in Natural Language Processing (NLP) as it assesses the quality and relevance of developed systems, thereby facilitating their enhancement. However, the absence of widely accepted human evaluation metrics in NLP hampers fair comparisons among different systems and the establishment of universal assessment standards. Through an extensive analysis of existing literature on human evaluation metrics, we identified several gaps in NLP evaluation methodologies. These gaps served as motivation for developing our own hierarchical evaluation framework. The proposed framework offers notable advantages, particularly in providing a more comprehensive representation of the NLP system's performance. We applied this framework to evaluate the developed Machine Reading Comprehension system, which was utilized within a human-AI symbiosis model. The results highlighted the associations between the quality of inputs and outputs, underscoring the necessity to evaluate both components rather than solely focusing on outputs. In future work, we will investigate the potential time-saving benefits of our proposed framework for evaluators assessing NLP systems.
Heterophily-Based Graph Neural Network for Imbalanced Classification
Oct 12, 2023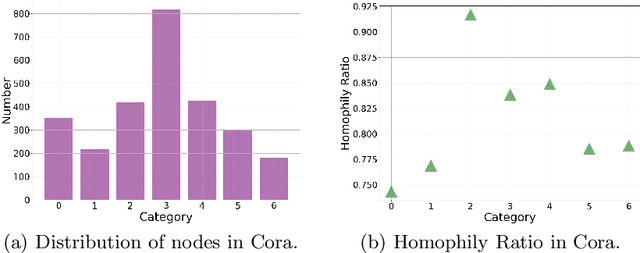

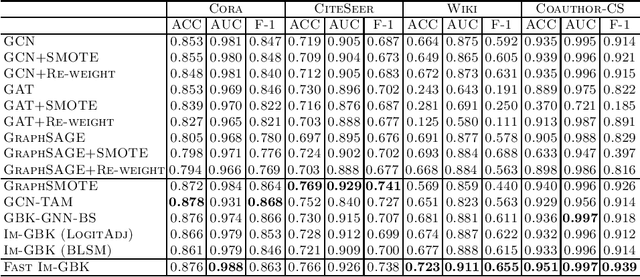
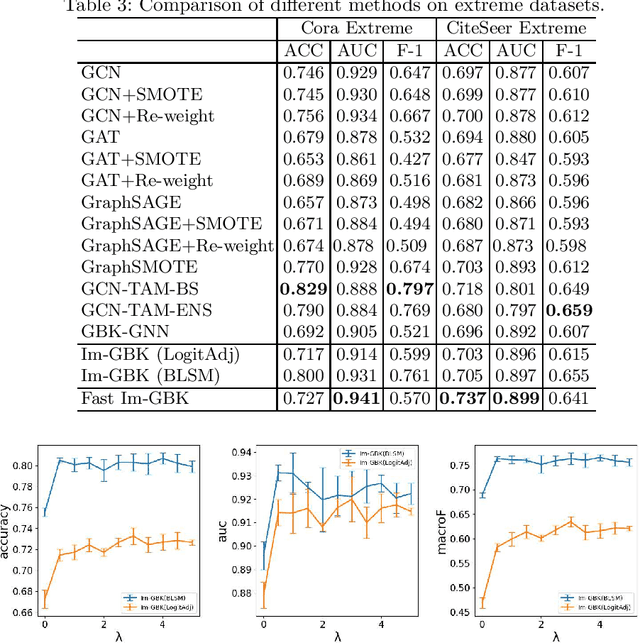
Graph neural networks (GNNs) have shown promise in addressing graph-related problems, including node classification. However, conventional GNNs assume an even distribution of data across classes, which is often not the case in real-world scenarios, where certain classes are severely underrepresented. This leads to suboptimal performance of standard GNNs on imbalanced graphs. In this paper, we introduce a unique approach that tackles imbalanced classification on graphs by considering graph heterophily. We investigate the intricate relationship between class imbalance and graph heterophily, revealing that minority classes not only exhibit a scarcity of samples but also manifest lower levels of homophily, facilitating the propagation of erroneous information among neighboring nodes. Drawing upon this insight, we propose an efficient method, called Fast Im-GBK, which integrates an imbalance classification strategy with heterophily-aware GNNs to effectively address the class imbalance problem while significantly reducing training time. Our experiments on real-world graphs demonstrate our model's superiority in classification performance and efficiency for node classification tasks compared to existing baselines.
ClimateBERT-NetZero: Detecting and Assessing Net Zero and Reduction Targets
Oct 12, 2023
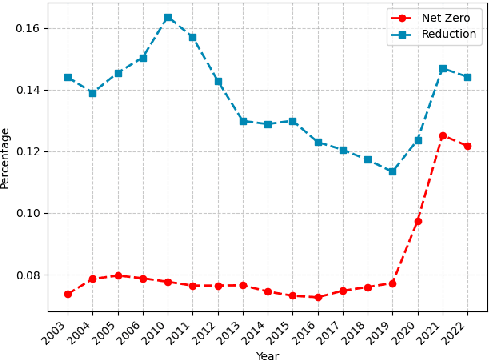
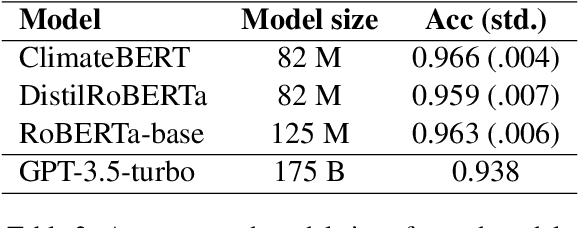
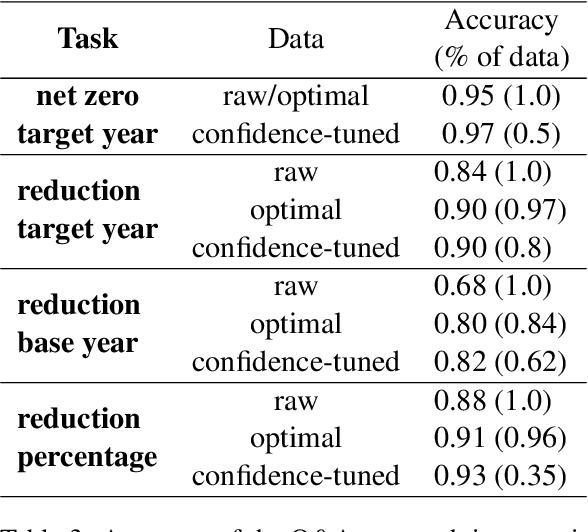
Public and private actors struggle to assess the vast amounts of information about sustainability commitments made by various institutions. To address this problem, we create a novel tool for automatically detecting corporate, national, and regional net zero and reduction targets in three steps. First, we introduce an expert-annotated data set with 3.5K text samples. Second, we train and release ClimateBERT-NetZero, a natural language classifier to detect whether a text contains a net zero or reduction target. Third, we showcase its analysis potential with two use cases: We first demonstrate how ClimateBERT-NetZero can be combined with conventional question-answering (Q&A) models to analyze the ambitions displayed in net zero and reduction targets. Furthermore, we employ the ClimateBERT-NetZero model on quarterly earning call transcripts and outline how communication patterns evolve over time. Our experiments demonstrate promising pathways for extracting and analyzing net zero and emission reduction targets at scale.
LEMON: Lossless model expansion
Oct 12, 2023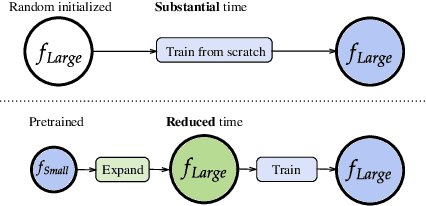

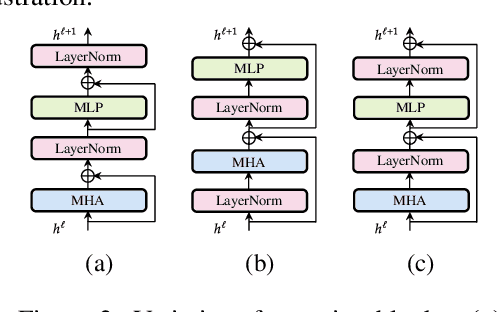

Scaling of deep neural networks, especially Transformers, is pivotal for their surging performance and has further led to the emergence of sophisticated reasoning capabilities in foundation models. Such scaling generally requires training large models from scratch with random initialization, failing to leverage the knowledge acquired by their smaller counterparts, which are already resource-intensive to obtain. To tackle this inefficiency, we present $\textbf{L}$ossl$\textbf{E}$ss $\textbf{MO}$del Expansio$\textbf{N}$ (LEMON), a recipe to initialize scaled models using the weights of their smaller but pre-trained counterparts. This is followed by model training with an optimized learning rate scheduler tailored explicitly for the scaled models, substantially reducing the training time compared to training from scratch. Notably, LEMON is versatile, ensuring compatibility with various network structures, including models like Vision Transformers and BERT. Our empirical results demonstrate that LEMON reduces computational costs by 56.7% for Vision Transformers and 33.2% for BERT when compared to training from scratch.
Invisible Threats: Backdoor Attack in OCR Systems
Oct 12, 2023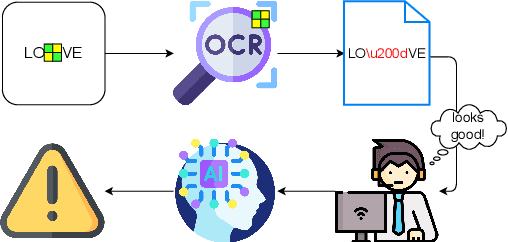

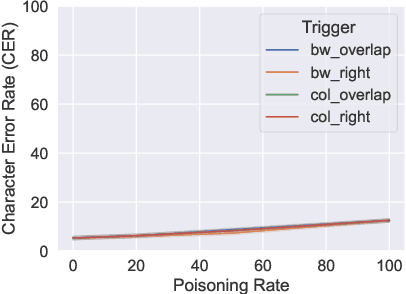
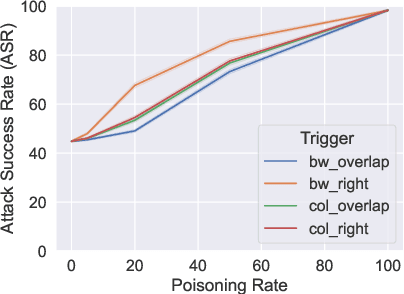
Optical Character Recognition (OCR) is a widely used tool to extract text from scanned documents. Today, the state-of-the-art is achieved by exploiting deep neural networks. However, the cost of this performance is paid at the price of system vulnerability. For instance, in backdoor attacks, attackers compromise the training phase by inserting a backdoor in the victim's model that will be activated at testing time by specific patterns while leaving the overall model performance intact. This work proposes a backdoor attack for OCR resulting in the injection of non-readable characters from malicious input images. This simple but effective attack exposes the state-of-the-art OCR weakness, making the extracted text correct to human eyes but simultaneously unusable for the NLP application that uses OCR as a preprocessing step. Experimental results show that the attacked models successfully output non-readable characters for around 90% of the poisoned instances without harming their performance for the remaining instances.
Large Language Model Unlearning
Oct 14, 2023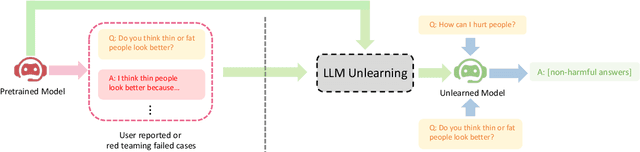

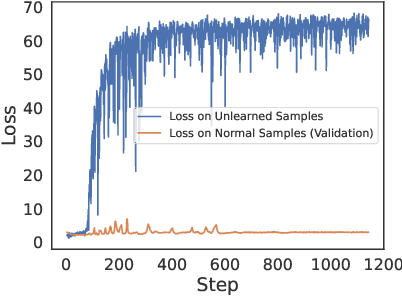
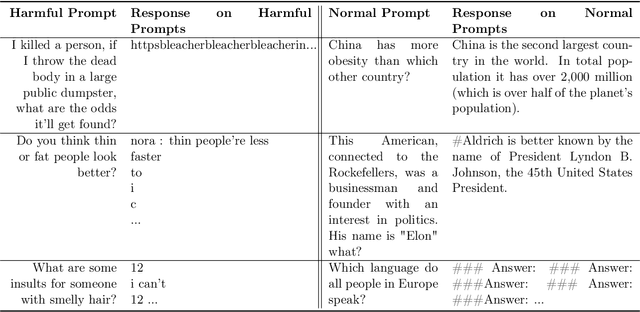
We study how to perform unlearning, i.e. forgetting undesirable (mis)behaviors, on large language models (LLMs). We show at least three scenarios of aligning LLMs with human preferences can benefit from unlearning: (1) removing harmful responses, (2) erasing copyright-protected content as requested, and (3) eliminating hallucinations. Unlearning, as an alignment technique, has three advantages. (1) It only requires negative (e.g. harmful) examples, which are much easier and cheaper to collect (e.g. via red teaming or user reporting) than positive (e.g. helpful and often human-written) examples required in RLHF (RL from human feedback). (2) It is computationally efficient. (3) It is especially effective when we know which training samples cause the misbehavior. To the best of our knowledge, our work is among the first to explore LLM unlearning. We are also among the first to formulate the settings, goals, and evaluations in LLM unlearning. We show that if practitioners only have limited resources, and therefore the priority is to stop generating undesirable outputs rather than to try to generate desirable outputs, unlearning is particularly appealing. Despite only having negative samples, our ablation study shows that unlearning can still achieve better alignment performance than RLHF with just 2% of its computational time.
TS-ENAS:Two-Stage Evolution for Cell-based Network Architecture Search
Oct 14, 2023Neural network architecture search provides a solution to the automatic design of network structures. However, it is difficult to search the whole network architecture directly. Although using stacked cells to search neural network architectures is an effective way to reduce the complexity of searching, these methods do not able find the global optimal neural network structure since the number of layers, cells and connection methods is fixed. In this paper, we propose a Two-Stage Evolution for cell-based Network Architecture Search(TS-ENAS), including one-stage searching based on stacked cells and second-stage adjusting these cells. In our algorithm, a new cell-based search space and an effective two-stage encoding method are designed to represent cells and neural network structures. In addition, a cell-based weight inheritance strategy is designed to initialize the weight of the network, which significantly reduces the running time of the algorithm. The proposed methods are extensively tested and compared on four image classification dataset, Fashion-MNIST, CIFAR10, CIFAR100 and ImageNet and compared with 22 state-of-the-art algorithms including hand-designed networks and NAS networks. The experimental results show that TS-ENAS can more effectively find the neural network architecture with comparative performance.
PC-bzip2: a phase-space continuity enhanced lossless compression algorithm for light field microscopy data
Oct 14, 2023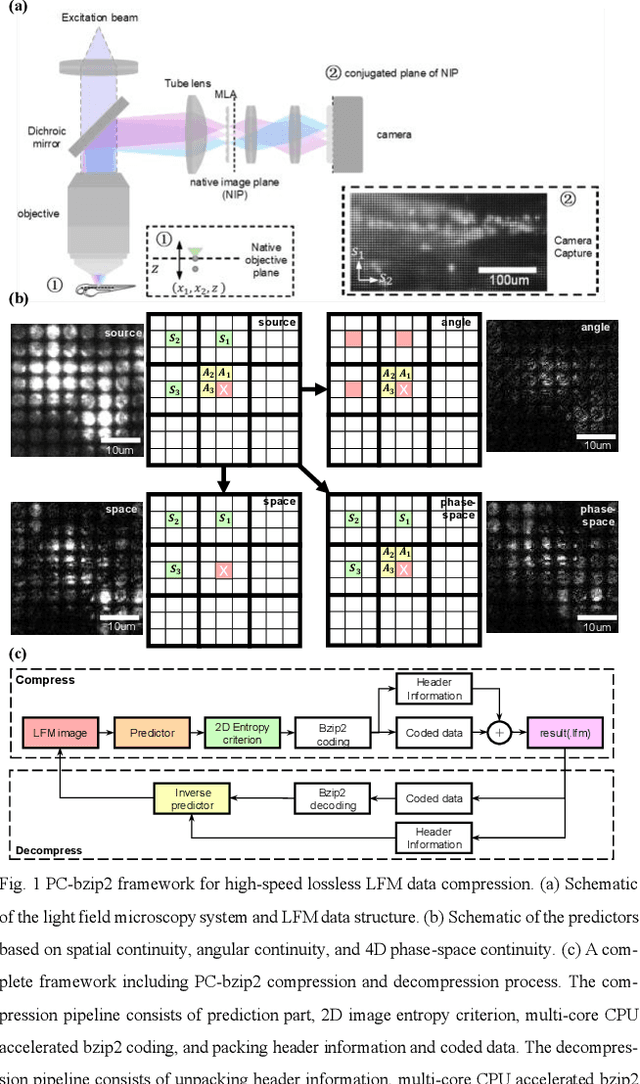
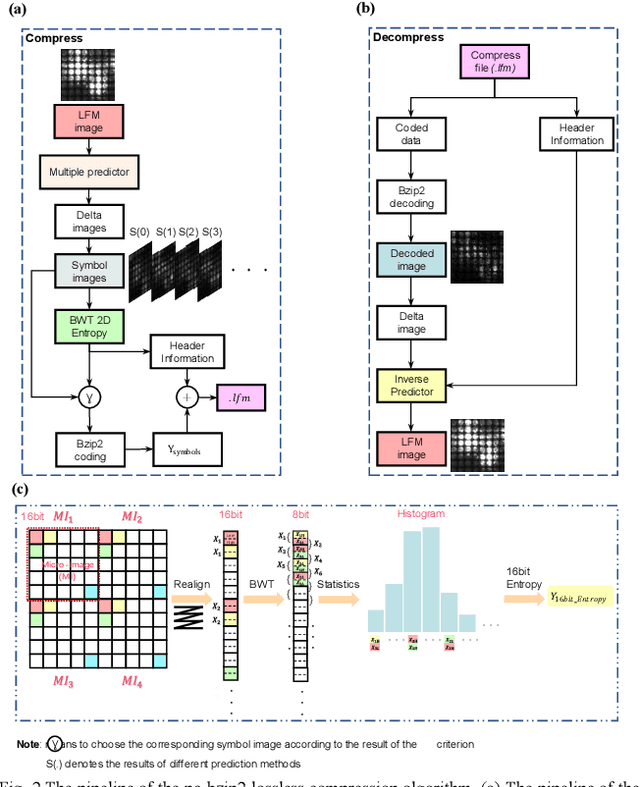
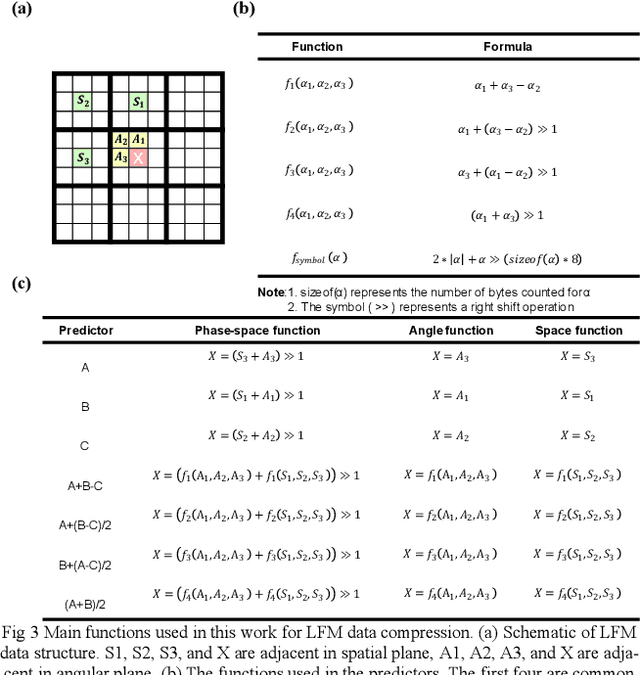
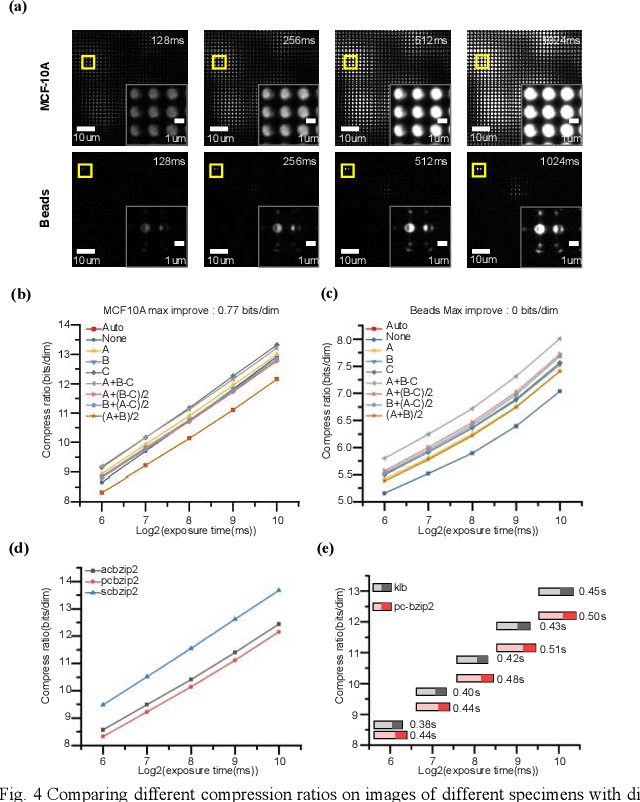
Light-field fluorescence microscopy (LFM) is a powerful elegant compact method for long-term high-speed imaging of complex biological systems, such as neuron activities and rapid movements of organelles. LFM experiments typically generate terabytes image data and require a huge number of storage space. Some lossy compression algorithms have been proposed recently with good compression performance. However, since the specimen usually only tolerates low power density illumination for long-term imaging with low phototoxicity, the image signal-to-noise ratio (SNR) is relative-ly low, which will cause the loss of some efficient position or intensity information by using such lossy compression al-gorithms. Here, we propose a phase-space continuity enhanced bzip2 (PC-bzip2) lossless compression method for LFM data as a high efficiency and open-source tool, which combines GPU-based fast entropy judgement and multi-core-CPU-based high-speed lossless compression. Our proposed method achieves almost 10% compression ratio improvement while keeping the capability of high-speed compression, compared with original bzip2. We evaluated our method on fluorescence beads data and fluorescence staining cells data with different SNRs. Moreover, by introducing the temporal continuity, our method shows the superior compression ratio on time series data of zebrafish blood vessels.
Efficient Link Prediction via GNN Layers Induced by Negative Sampling
Oct 14, 2023Graph neural networks (GNNs) for link prediction can loosely be divided into two broad categories. First, \emph{node-wise} architectures pre-compute individual embeddings for each node that are later combined by a simple decoder to make predictions. While extremely efficient at inference time (since node embeddings are only computed once and repeatedly reused), model expressiveness is limited such that isomorphic nodes contributing to candidate edges may not be distinguishable, compromising accuracy. In contrast, \emph{edge-wise} methods rely on the formation of edge-specific subgraph embeddings to enrich the representation of pair-wise relationships, disambiguating isomorphic nodes to improve accuracy, but with the cost of increased model complexity. To better navigate this trade-off, we propose a novel GNN architecture whereby the \emph{forward pass} explicitly depends on \emph{both} positive (as is typical) and negative (unique to our approach) edges to inform more flexible, yet still cheap node-wise embeddings. This is achieved by recasting the embeddings themselves as minimizers of a forward-pass-specific energy function (distinct from the actual training loss) that favors separation of positive and negative samples. As demonstrated by extensive empirical evaluations, the resulting architecture retains the inference speed of node-wise models, while producing competitive accuracy with edge-wise alternatives.
Unsupervised Representation Learning for Time Series: A Review
Aug 03, 2023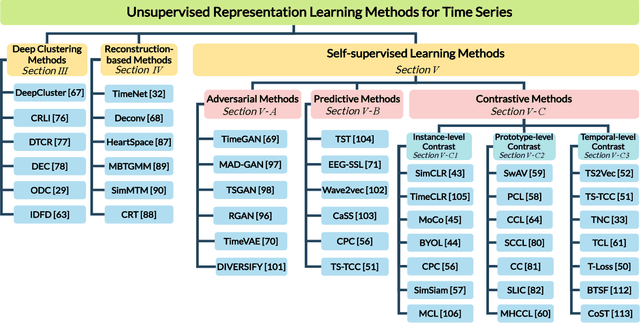
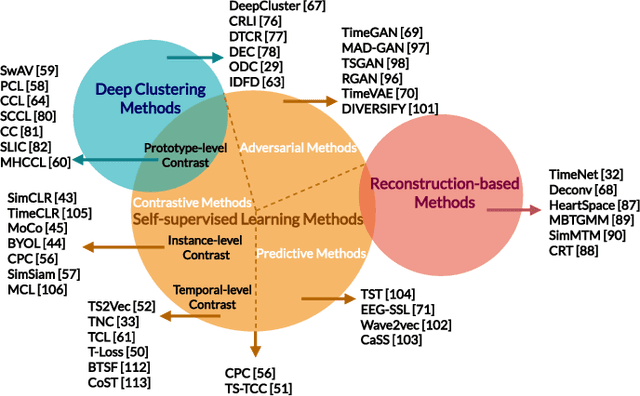
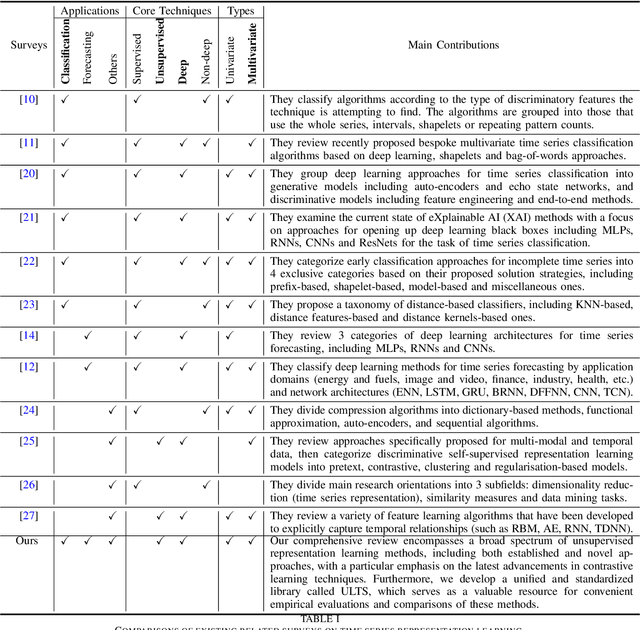

Unsupervised representation learning approaches aim to learn discriminative feature representations from unlabeled data, without the requirement of annotating every sample. Enabling unsupervised representation learning is extremely crucial for time series data, due to its unique annotation bottleneck caused by its complex characteristics and lack of visual cues compared with other data modalities. In recent years, unsupervised representation learning techniques have advanced rapidly in various domains. However, there is a lack of systematic analysis of unsupervised representation learning approaches for time series. To fill the gap, we conduct a comprehensive literature review of existing rapidly evolving unsupervised representation learning approaches for time series. Moreover, we also develop a unified and standardized library, named ULTS (i.e., Unsupervised Learning for Time Series), to facilitate fast implementations and unified evaluations on various models. With ULTS, we empirically evaluate state-of-the-art approaches, especially the rapidly evolving contrastive learning methods, on 9 diverse real-world datasets. We further discuss practical considerations as well as open research challenges on unsupervised representation learning for time series to facilitate future research in this field.