 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Spiking Semantic Communication for Feature Transmission with HARQ
Oct 13, 2023
In Collaborative Intelligence (CI), the Artificial Intelligence (AI) model is divided between the edge and the cloud, with intermediate features being sent from the edge to the cloud for inference. Several deep learning-based Semantic Communication (SC) models have been proposed to reduce feature transmission overhead and mitigate channel noise interference. Previous research has demonstrated that Spiking Neural Network (SNN)-based SC models exhibit greater robustness on digital channels compared to Deep Neural Network (DNN)-based SC models. However, the existing SNN-based SC models require fixed time steps, resulting in fixed transmission bandwidths that cannot be adaptively adjusted based on channel conditions. To address this issue, this paper introduces a novel SC model called SNN-SC-HARQ, which combines the SNN-based SC model with the Hybrid Automatic Repeat Request (HARQ) mechanism. SNN-SC-HARQ comprises an SNN-based SC model that supports the transmission of features at varying bandwidths, along with a policy model that determines the appropriate bandwidth. Experimental results show that SNN-SC-HARQ can dynamically adjust the bandwidth according to the channel conditions without performance loss.
pose-format: Library for Viewing, Augmenting, and Handling .pose Files
Oct 13, 2023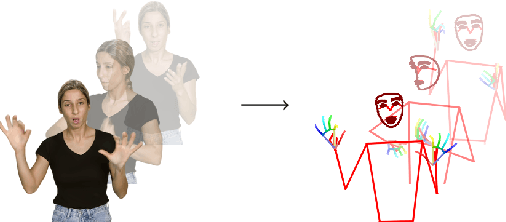
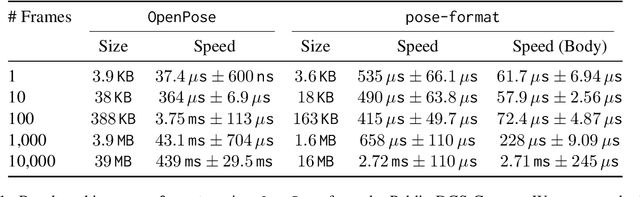
Managing and analyzing pose data is a complex task, with challenges ranging from handling diverse file structures and data types to facilitating effective data manipulations such as normalization and augmentation. This paper presents \texttt{pose-format}, a comprehensive toolkit designed to address these challenges by providing a unified, flexible, and easy-to-use interface. The library includes a specialized file format that encapsulates various types of pose data, accommodating multiple individuals and an indefinite number of time frames, thus proving its utility for both image and video data. Furthermore, it offers seamless integration with popular numerical libraries such as NumPy, PyTorch, and TensorFlow, thereby enabling robust machine-learning applications. Through benchmarking, we demonstrate that our \texttt{.pose} file format offers vastly superior performance against prevalent formats like OpenPose, with added advantages like self-contained pose specification. Additionally, the library includes features for data normalization, augmentation, and easy-to-use visualization capabilities, both in Python and Browser environments. \texttt{pose-format} emerges as a one-stop solution, streamlining the complexities of pose data management and analysis.
Online Relocating and Matching of Ride-Hailing Services: A Model-Based Modular Approach
Oct 13, 2023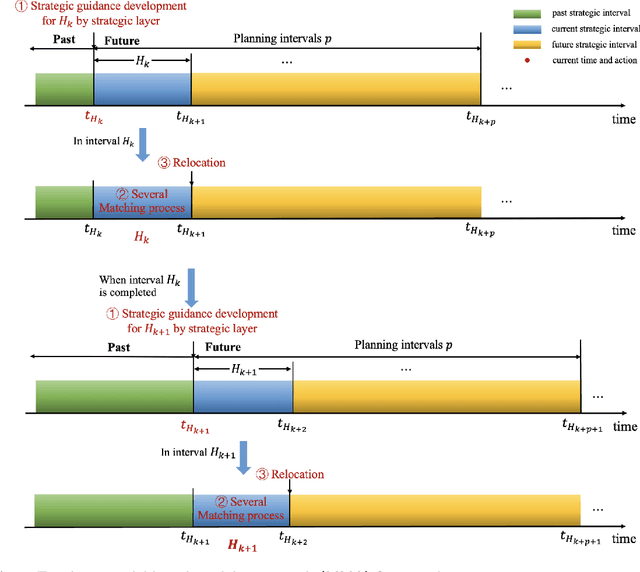
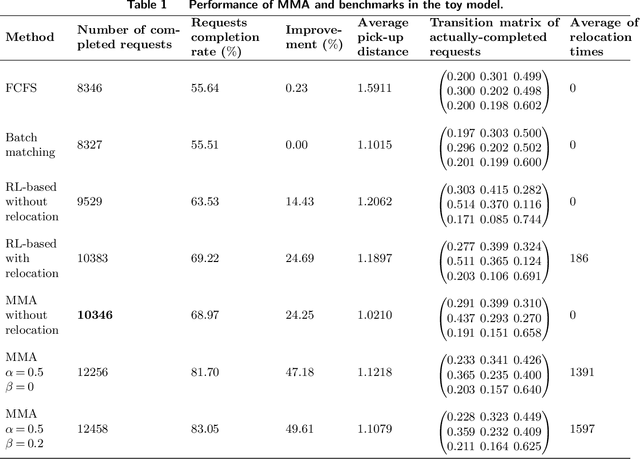
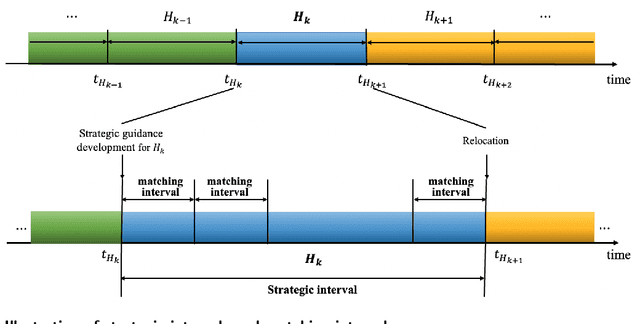
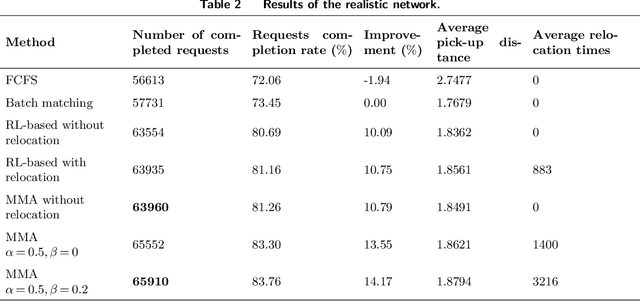
This study proposes an innovative model-based modular approach (MMA) to dynamically optimize order matching and vehicle relocation in a ride-hailing platform. MMA utilizes a two-layer and modular modeling structure. The upper layer determines the spatial transfer patterns of vehicle flow within the system to maximize the total revenue of the current and future stages. With the guidance provided by the upper layer, the lower layer performs rapid vehicle-to-order matching and vehicle relocation. MMA is interpretable, and equipped with the customized and polynomial-time algorithm, which, as an online order-matching and vehicle-relocation algorithm, can scale past thousands of vehicles. We theoretically prove that the proposed algorithm can achieve the global optimum in stylized networks, while the numerical experiments based on both the toy network and realistic dataset demonstrate that MMA is capable of achieving superior systematic performance compared to batch matching and reinforcement-learning based methods. Moreover, its modular and lightweight modeling structure further enables it to achieve a high level of robustness against demand variation while maintaining a relatively low computational cost.
Learning nonlinear integral operators via Recurrent Neural Networks and its application in solving Integro-Differential Equations
Oct 13, 2023In this paper, we propose using LSTM-RNNs (Long Short-Term Memory-Recurrent Neural Networks) to learn and represent nonlinear integral operators that appear in nonlinear integro-differential equations (IDEs). The LSTM-RNN representation of the nonlinear integral operator allows us to turn a system of nonlinear integro-differential equations into a system of ordinary differential equations for which many efficient solvers are available. Furthermore, because the use of LSTM-RNN representation of the nonlinear integral operator in an IDE eliminates the need to perform a numerical integration in each numerical time evolution step, the overall temporal cost of the LSTM-RNN-based IDE solver can be reduced to $O(n_T)$ from $O(n_T^2)$ if a $n_T$-step trajectory is to be computed. We illustrate the efficiency and robustness of this LSTM-RNN-based numerical IDE solver with a model problem. Additionally, we highlight the generalizability of the learned integral operator by applying it to IDEs driven by different external forces. As a practical application, we show how this methodology can effectively solve the Dyson's equation for quantum many-body systems.
AutoGluon-TimeSeries: AutoML for Probabilistic Time Series Forecasting
Aug 10, 2023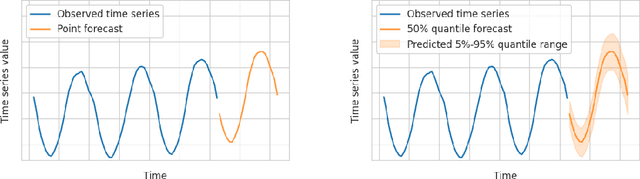
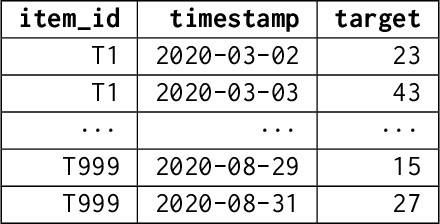
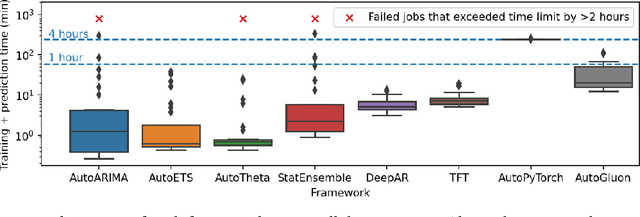
We introduce AutoGluon-TimeSeries - an open-source AutoML library for probabilistic time series forecasting. Focused on ease of use and robustness, AutoGluon-TimeSeries enables users to generate accurate point and quantile forecasts with just 3 lines of Python code. Built on the design philosophy of AutoGluon, AutoGluon-TimeSeries leverages ensembles of diverse forecasting models to deliver high accuracy within a short training time. AutoGluon-TimeSeries combines both conventional statistical models, machine-learning based forecasting approaches, and ensembling techniques. In our evaluation on 29 benchmark datasets, AutoGluon-TimeSeries demonstrates strong empirical performance, outperforming a range of forecasting methods in terms of both point and quantile forecast accuracy, and often even improving upon the best-in-hindsight combination of prior methods.
Deep Learning Approach for Large-Scale, Real-Time Quantification of Green Fluorescent Protein-Labeled Biological Samples in Microreactors
Sep 04, 2023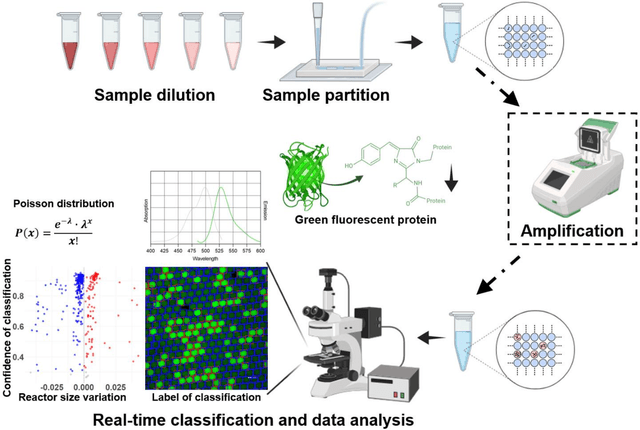

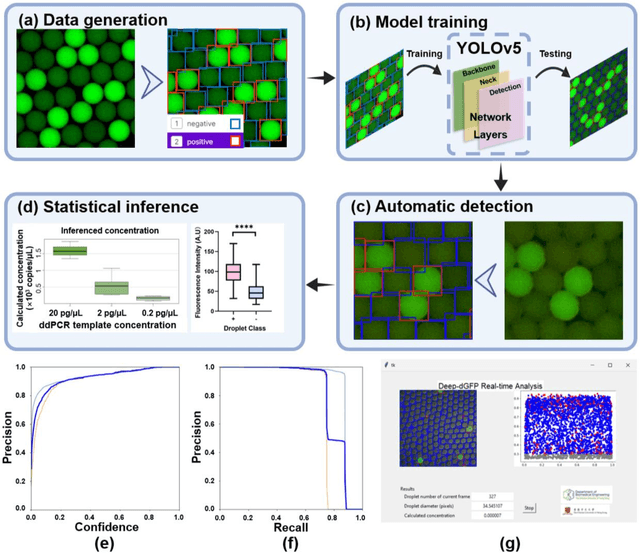
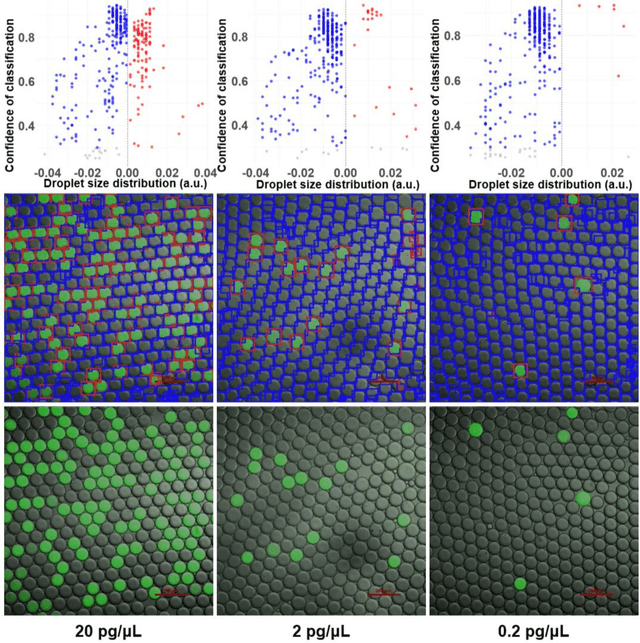
Absolute quantification of biological samples entails determining expression levels in precise numerical copies, offering enhanced accuracy and superior performance for rare templates. However, existing methodologies suffer from significant limitations: flow cytometers are both costly and intricate, while fluorescence imaging relying on software tools or manual counting is time-consuming and prone to inaccuracies. In this study, we have devised a comprehensive deep-learning-enabled pipeline that enables the automated segmentation and classification of GFP (green fluorescent protein)-labeled microreactors, facilitating real-time absolute quantification. Our findings demonstrate the efficacy of this technique in accurately predicting the sizes and occupancy status of microreactors using standard laboratory fluorescence microscopes, thereby providing precise measurements of template concentrations. Notably, our approach exhibits an analysis speed of quantifying over 2,000 microreactors (across 10 images) within remarkably 2.5 seconds, and a dynamic range spanning from 56.52 to 1569.43 copies per micron-liter. Furthermore, our Deep-dGFP algorithm showcases remarkable generalization capabilities, as it can be directly applied to various GFP-labeling scenarios, including droplet-based, microwell-based, and agarose-based biological applications. To the best of our knowledge, this represents the first successful implementation of an all-in-one image analysis algorithm in droplet digital PCR (polymerase chain reaction), microwell digital PCR, droplet single-cell sequencing, agarose digital PCR, and bacterial quantification, without necessitating any transfer learning steps, modifications, or retraining procedures. We firmly believe that our Deep-dGFP technique will be readily embraced by biomedical laboratories and holds potential for further development in related clinical applications.
Implementation of digital MemComputing using standard electronic components
Oct 03, 2023Digital MemComputing machines (DMMs), which employ nonlinear dynamical systems with memory (time non-locality), have proven to be a robust and scalable unconventional computing approach for solving a wide variety of combinatorial optimization problems. However, most of the research so far has focused on the numerical simulations of the equations of motion of DMMs. This inevitably subjects time to discretization, which brings its own (numerical) issues that would be absent in actual physical systems operating in continuous time. Although hardware realizations of DMMs have been previously suggested, their implementation would require materials and devices that are not so easy to integrate with traditional electronics. In this study, we propose a novel hardware design for DMMs that leverages only conventional electronic components. Our findings suggest that this design offers a marked improvement in speed compared to existing realizations of these machines, without requiring special materials or novel device concepts. We also show that these DMMs are robust against additive noise. Moreover, the absence of numerical noise promises enhanced stability over extended periods of the machines' operation, paving the way for addressing even more complex problems.
Learning to Receive Help: Intervention-Aware Concept Embedding Models
Sep 29, 2023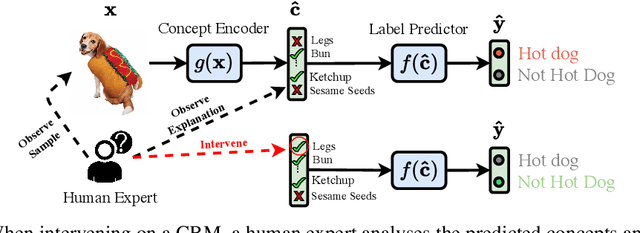
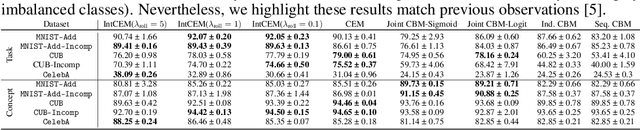
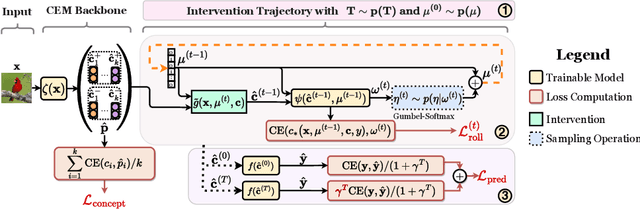
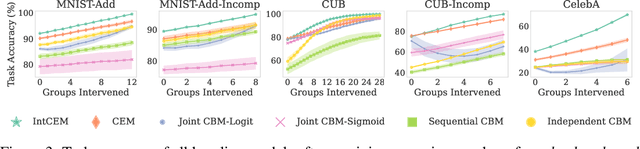
Concept Bottleneck Models (CBMs) tackle the opacity of neural architectures by constructing and explaining their predictions using a set of high-level concepts. A special property of these models is that they permit concept interventions, wherein users can correct mispredicted concepts and thus improve the model's performance. Recent work, however, has shown that intervention efficacy can be highly dependent on the order in which concepts are intervened on and on the model's architecture and training hyperparameters. We argue that this is rooted in a CBM's lack of train-time incentives for the model to be appropriately receptive to concept interventions. To address this, we propose Intervention-aware Concept Embedding models (IntCEMs), a novel CBM-based architecture and training paradigm that improves a model's receptiveness to test-time interventions. Our model learns a concept intervention policy in an end-to-end fashion from where it can sample meaningful intervention trajectories at train-time. This conditions IntCEMs to effectively select and receive concept interventions when deployed at test-time. Our experiments show that IntCEMs significantly outperform state-of-the-art concept-interpretable models when provided with test-time concept interventions, demonstrating the effectiveness of our approach.
CoPAL: Corrective Planning of Robot Actions with Large Language Models
Oct 11, 2023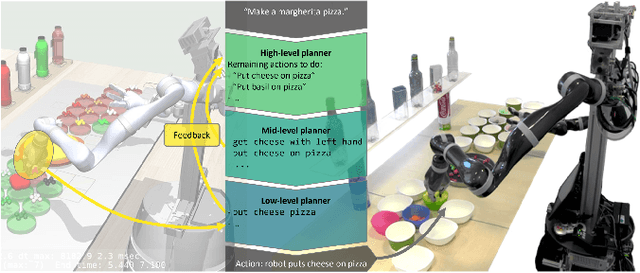
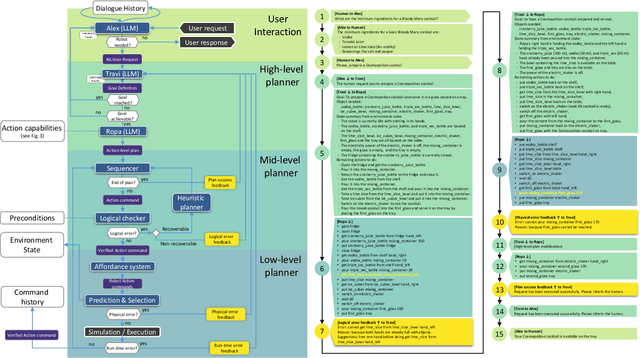
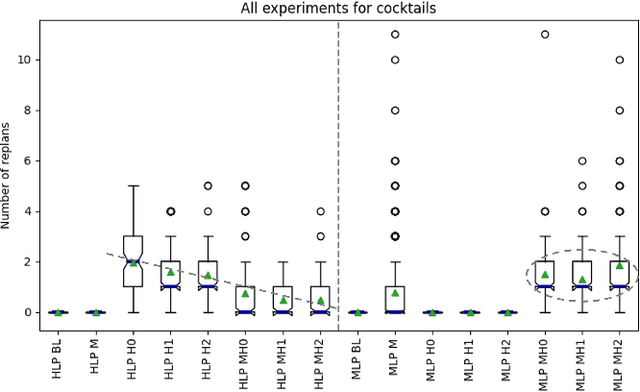
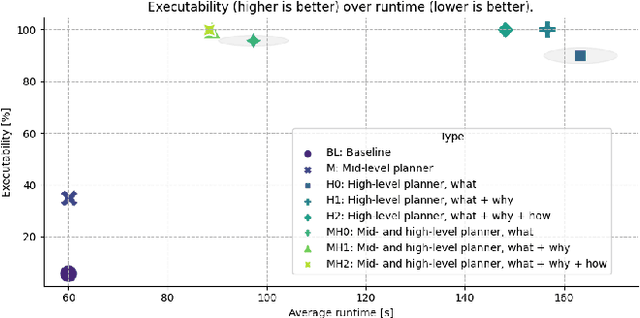
In the pursuit of fully autonomous robotic systems capable of taking over tasks traditionally performed by humans, the complexity of open-world environments poses a considerable challenge. Addressing this imperative, this study contributes to the field of Large Language Models (LLMs) applied to task and motion planning for robots. We propose a system architecture that orchestrates a seamless interplay between multiple cognitive levels, encompassing reasoning, planning, and motion generation. At its core lies a novel replanning strategy that handles physically grounded, logical, and semantic errors in the generated plans. We demonstrate the efficacy of the proposed feedback architecture, particularly its impact on executability, correctness, and time complexity via empirical evaluation in the context of a simulation and two intricate real-world scenarios: blocks world, barman and pizza preparation.
Experimental quantum natural gradient optimization in photonics
Oct 11, 2023Variational quantum algorithms (VQAs) combining the advantages of parameterized quantum circuits and classical optimizers, promise practical quantum applications in the Noisy Intermediate-Scale Quantum era. The performance of VQAs heavily depends on the optimization method. Compared with gradient-free and ordinary gradient descent methods, the quantum natural gradient (QNG), which mirrors the geometric structure of the parameter space, can achieve faster convergence and avoid local minima more easily, thereby reducing the cost of circuit executions. We utilized a fully programmable photonic chip to experimentally estimate the QNG in photonics for the first time. We obtained the dissociation curve of the He-H$^+$ cation and achieved chemical accuracy, verifying the outperformance of QNG optimization on a photonic device. Our work opens up a vista of utilizing QNG in photonics to implement practical near-term quantum applications.