 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Diffusion-based Data Augmentation for Nuclei Image Segmentation
Oct 22, 2023
Nuclei segmentation is a fundamental but challenging task in the quantitative analysis of histopathology images. Although fully-supervised deep learning-based methods have made significant progress, a large number of labeled images are required to achieve great segmentation performance. Considering that manually labeling all nuclei instances for a dataset is inefficient, obtaining a large-scale human-annotated dataset is time-consuming and labor-intensive. Therefore, augmenting a dataset with only a few labeled images to improve the segmentation performance is of significant research and application value. In this paper, we introduce the first diffusion-based augmentation method for nuclei segmentation. The idea is to synthesize a large number of labeled images to facilitate training the segmentation model. To achieve this, we propose a two-step strategy. In the first step, we train an unconditional diffusion model to synthesize the Nuclei Structure that is defined as the representation of pixel-level semantic and distance transform. Each synthetic nuclei structure will serve as a constraint on histopathology image synthesis and is further post-processed to be an instance map. In the second step, we train a conditioned diffusion model to synthesize histopathology images based on nuclei structures. The synthetic histopathology images paired with synthetic instance maps will be added to the real dataset for training the segmentation model. The experimental results show that by augmenting 10% labeled real dataset with synthetic samples, one can achieve comparable segmentation results with the fully-supervised baseline.
Detecting Moving Objects Using a Novel Optical-Flow-Based Range-Independent Invariant
Oct 14, 2023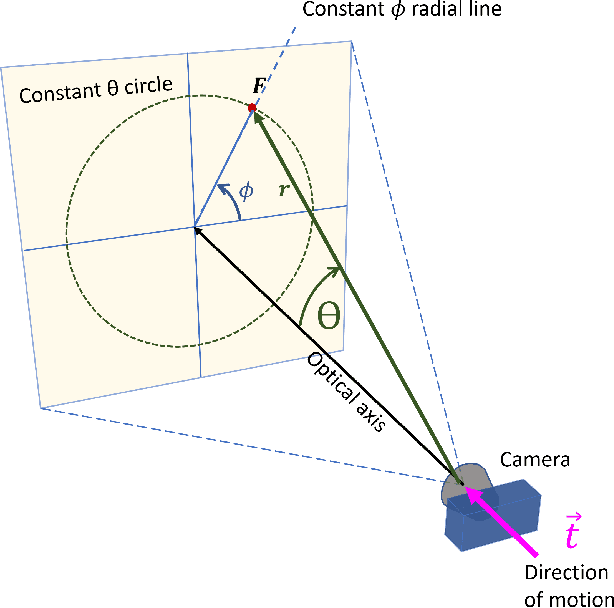



This paper focuses on a novel approach for detecting moving objects during camera motion. We present an optical-flow-based transformation that yields a consistent 2D invariant image output regardless of time instants, range of points in 3D, and the speed of the camera. In other words, this transformation generates a lookup image that remains invariant despite the changing projection of the 3D scene and camera motion. In the new domain, projections of 3D points that deviate from the values of the predefined lookup image can be clearly identified as moving relative to the stationary 3D environment, making them seamlessly detectable. The method does not require prior knowledge of the direction of motion or speed of the camera, nor does it necessitate 3D point range information. It is well-suited for real-time parallel processing, rendering it highly practical for implementation. We have validated the effectiveness of the new domain through simulations and experiments, demonstrating its robustness in scenarios involving rectilinear camera motion, both in simulations and with real-world data. This approach introduces new ways for moving objects detection during camera motion, and also lays the foundation for future research in the context of moving object detection during six-degrees-of-freedom camera motion.
Online Estimation with Rolling Validation: Adaptive Nonparametric Estimation with Stream Data
Oct 18, 2023Online nonparametric estimators are gaining popularity due to their efficient computation and competitive generalization abilities. An important example includes variants of stochastic gradient descent. These algorithms often take one sample point at a time and instantly update the parameter estimate of interest. In this work we consider model selection and hyperparameter tuning for such online algorithms. We propose a weighted rolling-validation procedure, an online variant of leave-one-out cross-validation, that costs minimal extra computation for many typical stochastic gradient descent estimators. Similar to batch cross-validation, it can boost base estimators to achieve a better, adaptive convergence rate. Our theoretical analysis is straightforward, relying mainly on some general statistical stability assumptions. The simulation study underscores the significance of diverging weights in rolling validation in practice and demonstrates its sensitivity even when there is only a slim difference between candidate estimators.
Uncovering User Interest from Biased and Noised Watch Time in Video Recommendation
Aug 16, 2023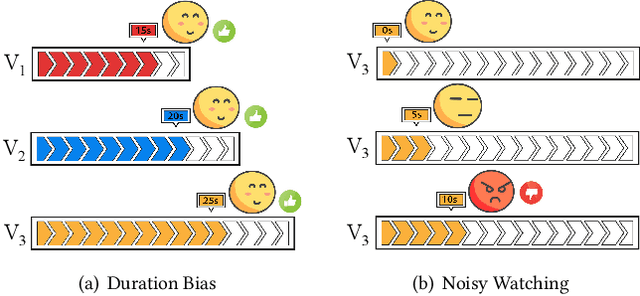

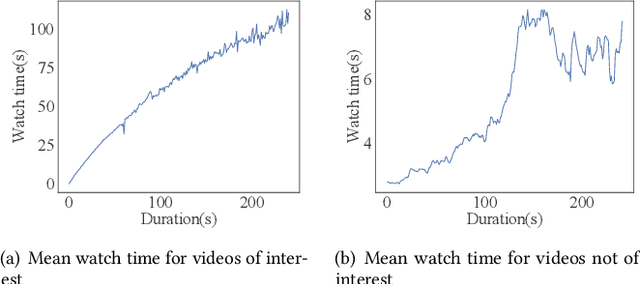
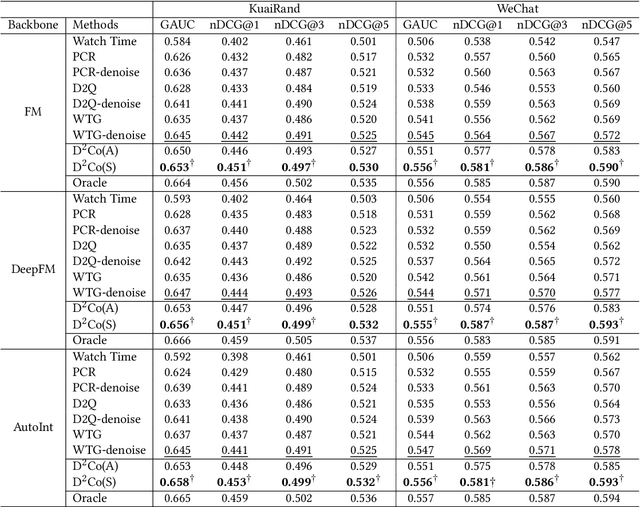
In the video recommendation, watch time is commonly adopted as an indicator of user interest. However, watch time is not only influenced by the matching of users' interests but also by other factors, such as duration bias and noisy watching. Duration bias refers to the tendency for users to spend more time on videos with longer durations, regardless of their actual interest level. Noisy watching, on the other hand, describes users taking time to determine whether they like a video or not, which can result in users spending time watching videos they do not like. Consequently, the existence of duration bias and noisy watching make watch time an inadequate label for indicating user interest. Furthermore, current methods primarily address duration bias and ignore the impact of noisy watching, which may limit their effectiveness in uncovering user interest from watch time. In this study, we first analyze the generation mechanism of users' watch time from a unified causal viewpoint. Specifically, we considered the watch time as a mixture of the user's actual interest level, the duration-biased watch time, and the noisy watch time. To mitigate both the duration bias and noisy watching, we propose Debiased and Denoised watch time Correction (D$^2$Co), which can be divided into two steps: First, we employ a duration-wise Gaussian Mixture Model plus frequency-weighted moving average for estimating the bias and noise terms; then we utilize a sensitivity-controlled correction function to separate the user interest from the watch time, which is robust to the estimation error of bias and noise terms. The experiments on two public video recommendation datasets and online A/B testing indicate the effectiveness of the proposed method.
Real-time Detection of AI-Generated Speech for DeepFake Voice Conversion
Aug 24, 2023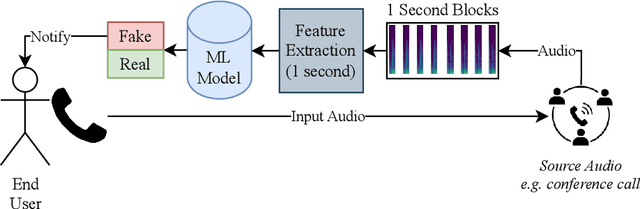

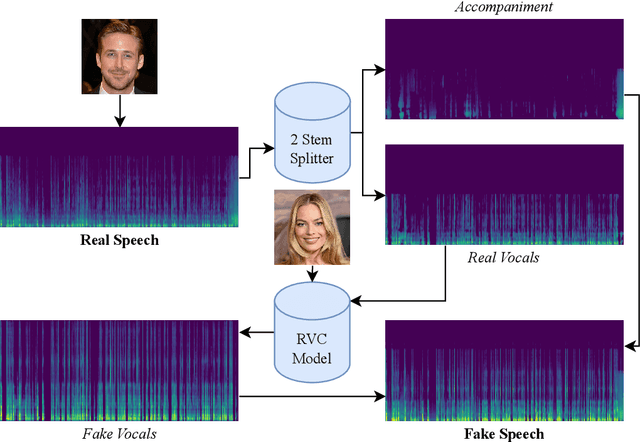
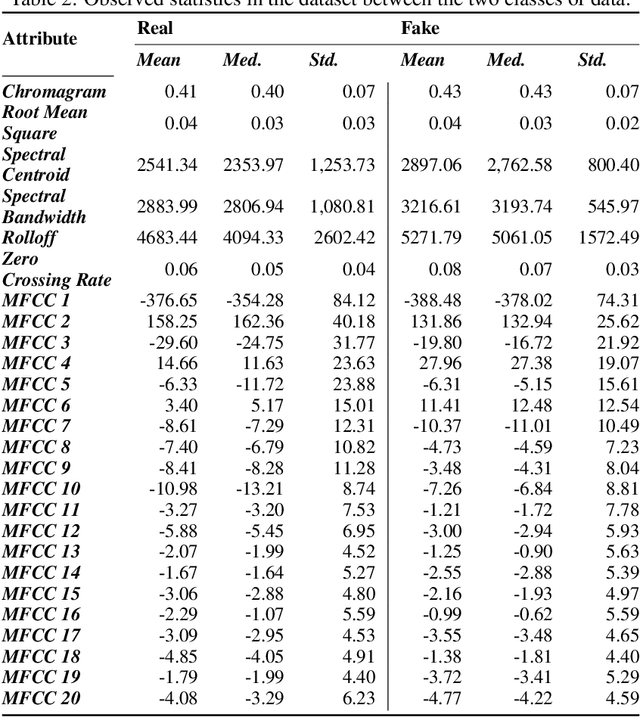
There are growing implications surrounding generative AI in the speech domain that enable voice cloning and real-time voice conversion from one individual to another. This technology poses a significant ethical threat and could lead to breaches of privacy and misrepresentation, thus there is an urgent need for real-time detection of AI-generated speech for DeepFake Voice Conversion. To address the above emerging issues, the DEEP-VOICE dataset is generated in this study, comprised of real human speech from eight well-known figures and their speech converted to one another using Retrieval-based Voice Conversion. Presenting as a binary classification problem of whether the speech is real or AI-generated, statistical analysis of temporal audio features through t-testing reveals that there are significantly different distributions. Hyperparameter optimisation is implemented for machine learning models to identify the source of speech. Following the training of 208 individual machine learning models over 10-fold cross validation, it is found that the Extreme Gradient Boosting model can achieve an average classification accuracy of 99.3% and can classify speech in real-time, at around 0.004 milliseconds given one second of speech. All data generated for this study is released publicly for future research on AI speech detection.
3D Non-Stationary Channel Measurement and Analysis for MaMIMO-UAV Communications
Oct 10, 2023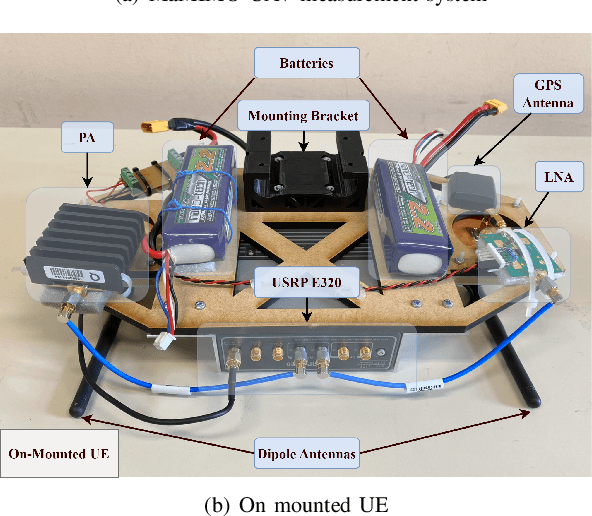
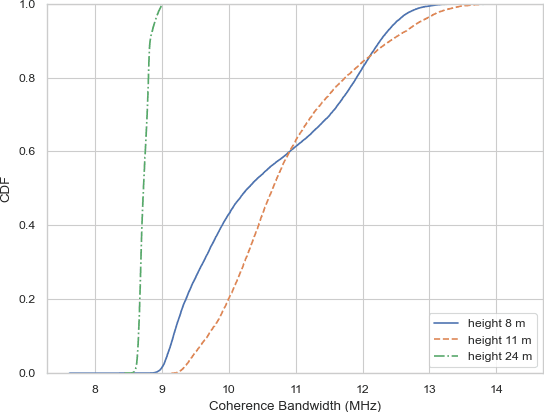
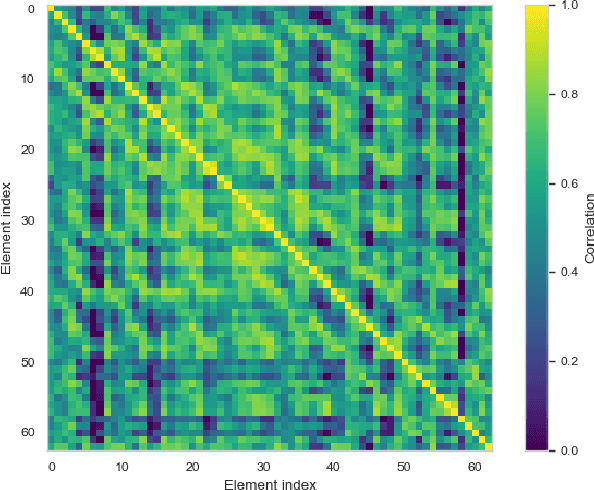
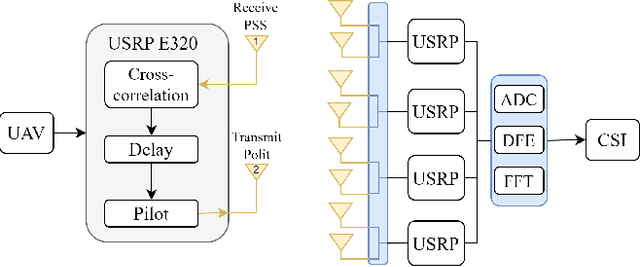
Unmanned aerial vehicles (UAVs) have gained popularity in the communications research community because of their versatility in placement and potential to extend the functions of communication networks. However, there remains still a gap in existing works regarding detailed and measurement-verified air-to-ground (A2G) Massive Multi-Input Multi-Output (MaMIMO) channel characteristics which play an important role in realistic deployment. In this paper, we first design a UAV MaMIMO communication platform for channel acquisition. We then use the testbed to measure uplink Channel State Information (CSI) between a rotary-wing drone and a 64-element MaMIMO base station (BS). For characterization, we focus on multidimensional channel stationarity which is a fundamental metric in communication systems. Afterward, we present measurement results and analyze the channel statistics based on power delay profiles (PDPs) considering space, time, and frequency domains. We propose the stationary angle (SA) as a supplementary metric of stationary distance (SD) in the time domain. We analyze the coherence bandwidth and RMS delay spread for frequency stationarity. Finally, spatial correlations between elements are analyzed to indicate the spatial stationarity of the array. The space-time-frequency channel stationary characterization will benefit the physical layer design of MaMIMO-UAV communications.
Data Drift Monitoring for Log Anomaly Detection Pipelines
Oct 17, 2023Logs enable the monitoring of infrastructure status and the performance of associated applications. Logs are also invaluable for diagnosing the root causes of any problems that may arise. Log Anomaly Detection (LAD) pipelines automate the detection of anomalies in logs, providing assistance to site reliability engineers (SREs) in system diagnosis. Log patterns change over time, necessitating updates to the LAD model defining the `normal' log activity profile. In this paper, we introduce a Bayes Factor-based drift detection method that identifies when intervention, retraining, and updating of the LAD model are required with human involvement. We illustrate our method using sequences of log activity, both from unaltered data, and simulated activity with controlled levels of anomaly contamination, based on real collected log data.
Weighted Joint Maximum Mean Discrepancy Enabled Multi-Source-Multi-Target Unsupervised Domain Adaptation Fault Diagnosis
Oct 20, 2023Despite the remarkable results that can be achieved by data-driven intelligent fault diagnosis techniques, they presuppose the same distribution of training and test data as well as sufficient labeled data. Various operating states often exist in practical scenarios, leading to the problem of domain shift that hinders the effectiveness of fault diagnosis. While recent unsupervised domain adaptation methods enable cross-domain fault diagnosis, they struggle to effectively utilize information from multiple source domains and achieve effective diagnosis faults in multiple target domains simultaneously. In this paper, we innovatively proposed a weighted joint maximum mean discrepancy enabled multi-source-multi-target unsupervised domain adaptation (WJMMD-MDA), which realizes domain adaptation under multi-source-multi-target scenarios in the field of fault diagnosis for the first time. The proposed method extracts sufficient information from multiple labeled source domains and achieves domain alignment between source and target domains through an improved weighted distance loss. As a result, domain-invariant and discriminative features between multiple source and target domains are learned with cross-domain fault diagnosis realized. The performance of the proposed method is evaluated in comprehensive comparative experiments on three datasets, and the experimental results demonstrate the superiority of this method.
Challenges and Contributing Factors in the Utilization of Large Language Models (LLMs)
Oct 20, 2023With the development of large language models (LLMs) like the GPT series, their widespread use across various application scenarios presents a myriad of challenges. This review initially explores the issue of domain specificity, where LLMs may struggle to provide precise answers to specialized questions within niche fields. The problem of knowledge forgetting arises as these LLMs might find it hard to balance old and new information. The knowledge repetition phenomenon reveals that sometimes LLMs might deliver overly mechanized responses, lacking depth and originality. Furthermore, knowledge illusion describes situations where LLMs might provide answers that seem insightful but are actually superficial, while knowledge toxicity focuses on harmful or biased information outputs. These challenges underscore problems in the training data and algorithmic design of LLMs. To address these issues, it's suggested to diversify training data, fine-tune models, enhance transparency and interpretability, and incorporate ethics and fairness training. Future technological trends might lean towards iterative methodologies, multimodal learning, model personalization and customization, and real-time learning and feedback mechanisms. In conclusion, future LLMs should prioritize fairness, transparency, and ethics, ensuring they uphold high moral and ethical standards when serving humanity.
Let's Synthesize Step by Step: Iterative Dataset Synthesis with Large Language Models by Extrapolating Errors from Small Models
Oct 20, 2023*Data Synthesis* is a promising way to train a small model with very little labeled data. One approach for data synthesis is to leverage the rich knowledge from large language models to synthesize pseudo training examples for small models, making it possible to achieve both data and compute efficiency at the same time. However, a key challenge in data synthesis is that the synthesized dataset often suffers from a large distributional discrepancy from the *real task* data distribution. Thus, in this paper, we propose *Synthesis Step by Step* (**S3**), a data synthesis framework that shrinks this distribution gap by iteratively extrapolating the errors made by a small model trained on the synthesized dataset on a small real-world validation dataset using a large language model. Extensive experiments on multiple NLP tasks show that our approach improves the performance of a small model by reducing the gap between the synthetic dataset and the real data, resulting in significant improvement compared to several baselines: 9.48% improvement compared to ZeroGen and 2.73% compared to GoldGen, and at most 15.17% improvement compared to the small model trained on human-annotated data.