 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FM Tone Transfer with Envelope Learning
Oct 07, 2023
Tone Transfer is a novel deep-learning technique for interfacing a sound source with a synthesizer, transforming the timbre of audio excerpts while keeping their musical form content. Due to its good audio quality results and continuous controllability, it has been recently applied in several audio processing tools. Nevertheless, it still presents several shortcomings related to poor sound diversity, and limited transient and dynamic rendering, which we believe hinder its possibilities of articulation and phrasing in a real-time performance context. In this work, we present a discussion on current Tone Transfer architectures for the task of controlling synthetic audio with musical instruments and discuss their challenges in allowing expressive performances. Next, we introduce Envelope Learning, a novel method for designing Tone Transfer architectures that map musical events using a training objective at the synthesis parameter level. Our technique can render note beginnings and endings accurately and for a variety of sounds; these are essential steps for improving musical articulation, phrasing, and sound diversity with Tone Transfer. Finally, we implement a VST plugin for real-time live use and discuss possibilities for improvement.
On Temporal References in Emergent Communication
Oct 10, 2023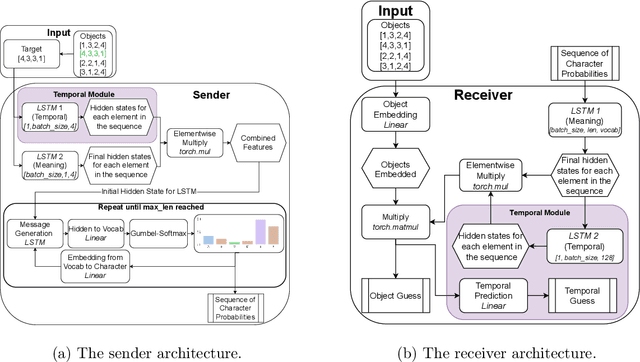

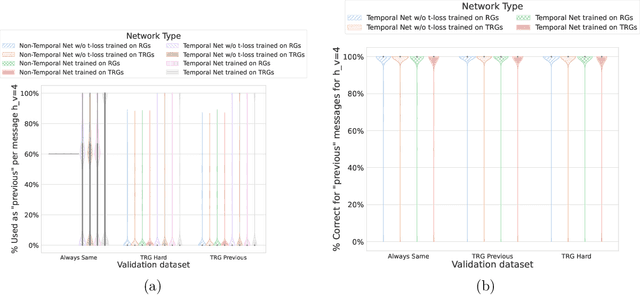
As humans, we use linguistic elements referencing time, such as before or tomorrow, to easily share past experiences and future predictions. While temporal aspects of the language have been considered in computational linguistics, no such exploration has been done within the field of emergent communication. We research this gap, providing the first reported temporal vocabulary within emergent communication literature. Our experimental analysis shows that a different agent architecture is sufficient for the natural emergence of temporal references, and that no additional losses are necessary. Our readily transferable architectural insights provide the basis for the incorporation of temporal referencing into other emergent communication environments.
Deep Geometric Learning with Monotonicity Constraints for Alzheimer's Disease Progression
Oct 05, 2023Alzheimer's disease (AD) is a devastating neurodegenerative condition that precedes progressive and irreversible dementia; thus, predicting its progression over time is vital for clinical diagnosis and treatment. Numerous studies have implemented structural magnetic resonance imaging (MRI) to model AD progression, focusing on three integral aspects: (i) temporal variability, (ii) incomplete observations, and (iii) temporal geometric characteristics. However, deep learning-based approaches regarding data variability and sparsity have yet to consider inherent geometrical properties sufficiently. The ordinary differential equation-based geometric modeling method (ODE-RGRU) has recently emerged as a promising strategy for modeling time-series data by intertwining a recurrent neural network and an ODE in Riemannian space. Despite its achievements, ODE-RGRU encounters limitations when extrapolating positive definite symmetric metrics from incomplete samples, leading to feature reverse occurrences that are particularly problematic, especially within the clinical facet. Therefore, this study proposes a novel geometric learning approach that models longitudinal MRI biomarkers and cognitive scores by combining three modules: topological space shift, ODE-RGRU, and trajectory estimation. We have also developed a training algorithm that integrates manifold mapping with monotonicity constraints to reflect measurement transition irreversibility. We verify our proposed method's efficacy by predicting clinical labels and cognitive scores over time in regular and irregular settings. Furthermore, we thoroughly analyze our proposed framework through an ablation study.
Sparse Binary Transformers for Multivariate Time Series Modeling
Aug 09, 2023Compressed Neural Networks have the potential to enable deep learning across new applications and smaller computational environments. However, understanding the range of learning tasks in which such models can succeed is not well studied. In this work, we apply sparse and binary-weighted Transformers to multivariate time series problems, showing that the lightweight models achieve accuracy comparable to that of dense floating-point Transformers of the same structure. Our model achieves favorable results across three time series learning tasks: classification, anomaly detection, and single-step forecasting. Additionally, to reduce the computational complexity of the attention mechanism, we apply two modifications, which show little to no decline in model performance: 1) in the classification task, we apply a fixed mask to the query, key, and value activations, and 2) for forecasting and anomaly detection, which rely on predicting outputs at a single point in time, we propose an attention mask to allow computation only at the current time step. Together, each compression technique and attention modification substantially reduces the number of non-zero operations necessary in the Transformer. We measure the computational savings of our approach over a range of metrics including parameter count, bit size, and floating point operation (FLOPs) count, showing up to a 53x reduction in storage size and up to 10.5x reduction in FLOPs.
Online Adaptive Disparity Estimation for Dynamic Scenes in Structured Light Systems
Oct 13, 2023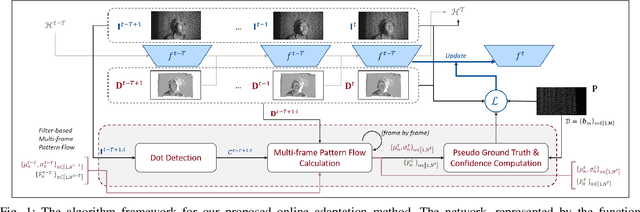
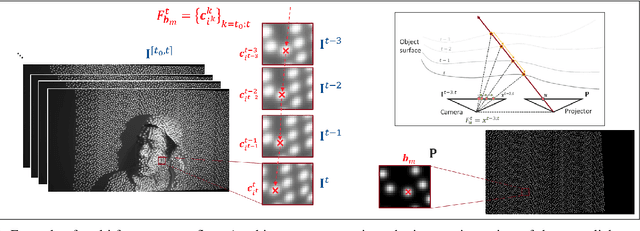
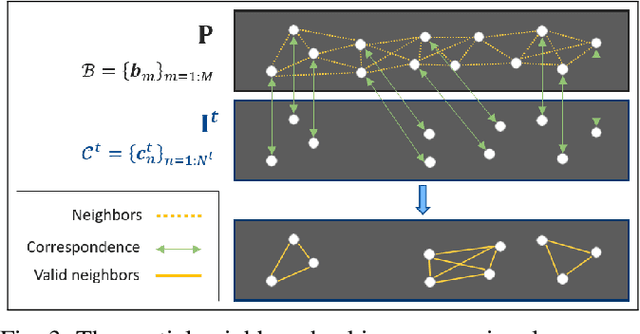

In recent years, deep neural networks have shown remarkable progress in dense disparity estimation from dynamic scenes in monocular structured light systems. However, their performance significantly drops when applied in unseen environments. To address this issue, self-supervised online adaptation has been proposed as a solution to bridge this performance gap. Unlike traditional fine-tuning processes, online adaptation performs test-time optimization to adapt networks to new domains. Therefore, achieving fast convergence during the adaptation process is critical for attaining satisfactory accuracy. In this paper, we propose an unsupervised loss function based on long sequential inputs. It ensures better gradient directions and faster convergence. Our loss function is designed using a multi-frame pattern flow, which comprises a set of sparse trajectories of the projected pattern along the sequence. We estimate the sparse pseudo ground truth with a confidence mask using a filter-based method, which guides the online adaptation process. Our proposed framework significantly improves the online adaptation speed and achieves superior performance on unseen data.
When Collaborative Filtering is not Collaborative: Unfairness of PCA for Recommendations
Oct 15, 2023We study the fairness of dimensionality reduction methods for recommendations. We focus on the established method of principal component analysis (PCA), which identifies latent components and produces a low-rank approximation via the leading components while discarding the trailing components. Prior works have defined notions of "fair PCA"; however, these definitions do not answer the following question: what makes PCA unfair? We identify two underlying mechanisms of PCA that induce unfairness at the item level. The first negatively impacts less popular items, due to the fact that less popular items rely on trailing latent components to recover their values. The second negatively impacts the highly popular items, since the leading PCA components specialize in individual popular items instead of capturing similarities between items. To address these issues, we develop a polynomial-time algorithm, Item-Weighted PCA, a modification of PCA that uses item-specific weights in the objective. On a stylized class of matrices, we prove that Item-Weighted PCA using a specific set of weights minimizes a popularity-normalized error metric. Our evaluations on real-world datasets show that Item-Weighted PCA not only improves overall recommendation quality by up to $0.1$ item-level AUC-ROC but also improves on both popular and less popular items.
Holistic Parking Slot Detection with Polygon-Shaped Representations
Oct 17, 2023Current parking slot detection in advanced driver-assistance systems (ADAS) primarily relies on ultrasonic sensors. This method has several limitations such as the need to scan the entire parking slot before detecting it, the incapacity of detecting multiple slots in a row, and the difficulty of classifying them. Due to the complex visual environment, vehicles are equipped with surround view camera systems to detect vacant parking slots. Previous research works in this field mostly use image-domain models to solve the problem. These two-stage approaches separate the 2D detection and 3D pose estimation steps using camera calibration. In this paper, we propose one-step Holistic Parking Slot Network (HPS-Net), a tailor-made adaptation of the You Only Look Once (YOLO)v4 algorithm. This camera-based approach directly outputs the four vertex coordinates of the parking slot in topview domain, instead of a bounding box in raw camera images. Several visible points and shapes can be proposed from different angles. A novel regression loss function named polygon-corner Generalized Intersection over Union (GIoU) for polygon vertex position optimization is also proposed to manage the slot orientation and to distinguish the entrance line. Experiments show that HPS-Net can detect various vacant parking slots with a F1-score of 0.92 on our internal Valeo Parking Slots Dataset (VPSD) and 0.99 on the public dataset PS2.0. It provides a satisfying generalization and robustness in various parking scenarios, such as indoor (F1: 0.86) or paved ground (F1: 0.91). Moreover, it achieves a real-time detection speed of 17 FPS on Nvidia Drive AGX Xavier. A demo video can be found at https://streamable.com/75j7sj.
Sparse-DySta: Sparsity-Aware Dynamic and Static Scheduling for Sparse Multi-DNN Workloads
Oct 17, 2023
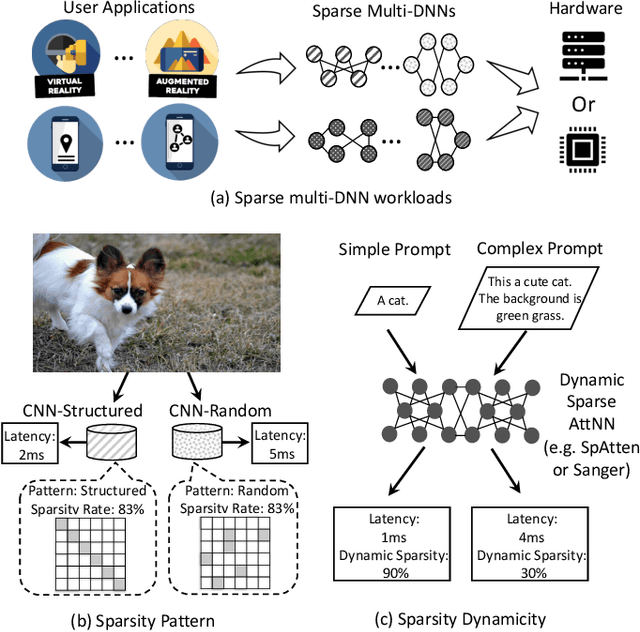


Running multiple deep neural networks (DNNs) in parallel has become an emerging workload in both edge devices, such as mobile phones where multiple tasks serve a single user for daily activities, and data centers, where various requests are raised from millions of users, as seen with large language models. To reduce the costly computational and memory requirements of these workloads, various efficient sparsification approaches have been introduced, resulting in widespread sparsity across different types of DNN models. In this context, there is an emerging need for scheduling sparse multi-DNN workloads, a problem that is largely unexplored in previous literature. This paper systematically analyses the use-cases of multiple sparse DNNs and investigates the opportunities for optimizations. Based on these findings, we propose Dysta, a novel bi-level dynamic and static scheduler that utilizes both static sparsity patterns and dynamic sparsity information for the sparse multi-DNN scheduling. Both static and dynamic components of Dysta are jointly designed at the software and hardware levels, respectively, to improve and refine the scheduling approach. To facilitate future progress in the study of this class of workloads, we construct a public benchmark that contains sparse multi-DNN workloads across different deployment scenarios, spanning from mobile phones and AR/VR wearables to data centers. A comprehensive evaluation on the sparse multi-DNN benchmark demonstrates that our proposed approach outperforms the state-of-the-art methods with up to 10% decrease in latency constraint violation rate and nearly 4X reduction in average normalized turnaround time. Our artifacts and code are publicly available at: https://github.com/SamsungLabs/Sparse-Multi-DNN-Scheduling.
Humanising robot-assisted navigation
Oct 17, 2023Robot-assisted navigation is a perfect example of a class of applications requiring flexible control approaches. When the human is reliable, the robot should concede space to their initiative. When the human makes inappropriate choices the robot controller should kick-in guiding them towards safer paths. Shared authority control is a way to achieve this behaviour by deciding online how much of the authority should be given to the human and how much should be retained by the robot. An open problem is how to evaluate the appropriateness of the human's choices. One possible way is to consider the deviation from an ideal path computed by the robot. This choice is certainly safe and efficient, but it emphasises the importance of the robot's decision and relegates the human to a secondary role. In this paper, we propose a different paradigm: a human's behaviour is correct if, at every time, it bears a close resemblance to what other humans do in similar situations. This idea is implemented through the combination of machine learning and adaptive control. The map of the environment is decomposed into a grid. In each cell, we classify the possible motions that the human executes. We use a neural network classifier to classify the current motion, and the probability score is used as a hyperparameter in the control to vary the amount of intervention. The experiments collected for the paper show the feasibility of the idea. A qualitative evaluation, done by surveying the users after they have tested the robot, shows that the participants preferred our control method over a state-of-the-art visco-elastic control.
Quantifying Assistive Robustness Via the Natural-Adversarial Frontier
Oct 16, 2023Our ultimate goal is to build robust policies for robots that assist people. What makes this hard is that people can behave unexpectedly at test time, potentially interacting with the robot outside its training distribution and leading to failures. Even just measuring robustness is a challenge. Adversarial perturbations are the default, but they can paint the wrong picture: they can correspond to human motions that are unlikely to occur during natural interactions with people. A robot policy might fail under small adversarial perturbations but work under large natural perturbations. We propose that capturing robustness in these interactive settings requires constructing and analyzing the entire natural-adversarial frontier: the Pareto-frontier of human policies that are the best trade-offs between naturalness and low robot performance. We introduce RIGID, a method for constructing this frontier by training adversarial human policies that trade off between minimizing robot reward and acting human-like (as measured by a discriminator). On an Assistive Gym task, we use RIGID to analyze the performance of standard collaborative Reinforcement Learning, as well as the performance of existing methods meant to increase robustness. We also compare the frontier RIGID identifies with the failures identified in expert adversarial interaction, and with naturally-occurring failures during user interaction. Overall, we find evidence that RIGID can provide a meaningful measure of robustness predictive of deployment performance, and uncover failure cases in human-robot interaction that are difficult to find manually. https://ood-human.github.io.