 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PoCo: Point Context Cluster for RGBD Indoor Place Recognition
Apr 03, 2024
We present a novel end-to-end algorithm (PoCo) for the indoor RGB-D place recognition task, aimed at identifying the most likely match for a given query frame within a reference database. The task presents inherent challenges attributed to the constrained field of view and limited range of perception sensors. We propose a new network architecture, which generalizes the recent Context of Clusters (CoCs) to extract global descriptors directly from the noisy point clouds through end-to-end learning. Moreover, we develop the architecture by integrating both color and geometric modalities into the point features to enhance the global descriptor representation. We conducted evaluations on public datasets ScanNet-PR and ARKit with 807 and 5047 scenarios, respectively. PoCo achieves SOTA performance: on ScanNet-PR, we achieve R@1 of 64.63%, a 5.7% improvement from the best-published result CGis (61.12%); on Arkit, we achieve R@1 of 45.12%, a 13.3% improvement from the best-published result CGis (39.82%). In addition, PoCo shows higher efficiency than CGis in inference time (1.75X-faster), and we demonstrate the effectiveness of PoCo in recognizing places within a real-world laboratory environment.
Federated Computing -- Survey on Building Blocks, Extensions and Systems
Apr 03, 2024In response to the increasing volume and sensitivity of data, traditional centralized computing models face challenges, such as data security breaches and regulatory hurdles. Federated Computing (FC) addresses these concerns by enabling collaborative processing without compromising individual data privacy. This is achieved through a decentralized network of devices, each retaining control over its data, while participating in collective computations. The motivation behind FC extends beyond technical considerations to encompass societal implications. As the need for responsible AI and ethical data practices intensifies, FC aligns with the principles of user empowerment and data sovereignty. FC comprises of Federated Learning (FL) and Federated Analytics (FA). FC systems became more complex over time and they currently lack a clear definition and taxonomy describing its moving pieces. Current surveys capture domain-specific FL use cases, describe individual components in an FC pipeline individually or decoupled from each other, or provide a quantitative overview of the number of published papers. This work surveys more than 150 papers to distill the underlying structure of FC systems with their basic building blocks, extensions, architecture, environment, and motivation. We capture FL and FA systems individually and point out unique difference between those two.
Digital Twin Channel for 6G: Concepts, Architectures and Potential Applications
Mar 31, 2024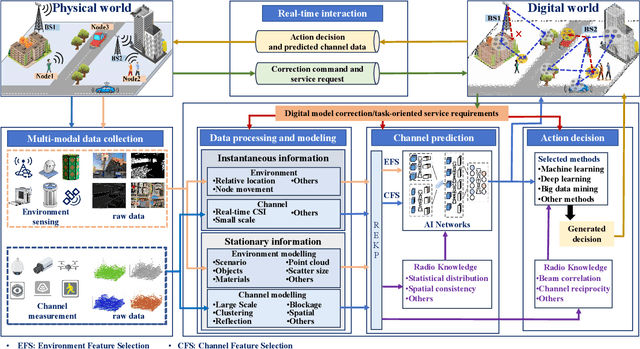
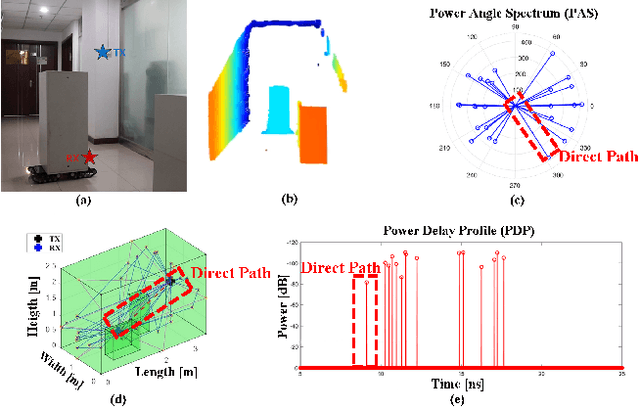
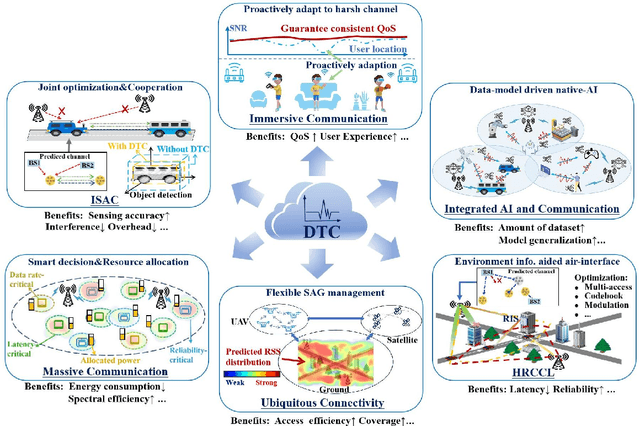
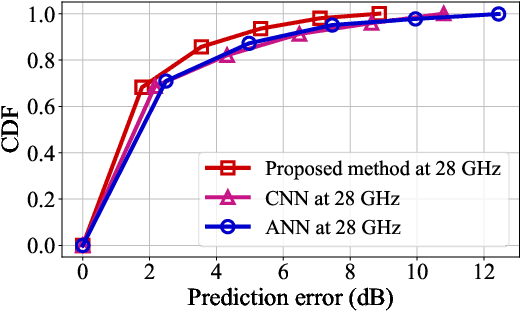
Digital twin channel (DTC) is the real-time mapping of a wireless channel from the physical world to the digital world, which is expected to provide significant performance enhancements for the sixth-generation (6G) air-interface design. In this work, we first define five evolution levels of channel twins with the progression of wireless communication. The fifth level, autonomous DTC, is elaborated with multi-dimensional factors such as methodology, characterization precision, and data category. Then, we provide detailed insights into the requirements and architecture of a complete DTC for 6G. Subsequently, a sensing-enhanced real-time channel prediction platform and experimental validations are exhibited. Finally, drawing from the vision of the 6G network, we explore the potential applications and the open issues in future DTC research.
Resource-Aware Collaborative Monte Carlo Localization with Distribution Compression
Apr 02, 2024Global localization is essential in enabling robot autonomy, and collaborative localization is key for multi-robot systems. In this paper, we address the task of collaborative global localization under computational and communication constraints. We propose a method which reduces the amount of information exchanged and the computational cost. We also analyze, implement and open-source seminal approaches, which we believe to be a valuable contribution to the community. We exploit techniques for distribution compression in near-linear time, with error guarantees. We evaluate our approach and the implemented baselines on multiple challenging scenarios, simulated and real-world. Our approach can run online on an onboard computer. We release an open-source C++/ROS2 implementation of our approach, as well as the baselines
Time-series Initialization and Conditioning for Video-agnostic Stabilization of Video Super-Resolution using Recurrent Networks
Mar 23, 2024A Recurrent Neural Network (RNN) for Video Super Resolution (VSR) is generally trained with randomly clipped and cropped short videos extracted from original training videos due to various challenges in learning RNNs. However, since this RNN is optimized to super-resolve short videos, VSR of long videos is degraded due to the domain gap. Our preliminary experiments reveal that such degradation changes depending on the video properties, such as the video length and dynamics. To avoid this degradation, this paper proposes the training strategy of RNN for VSR that can work efficiently and stably independently of the video length and dynamics. The proposed training strategy stabilizes VSR by training a VSR network with various RNN hidden states changed depending on the video properties. Since computing such a variety of hidden states is time-consuming, this computational cost is reduced by reusing the hidden states for efficient training. In addition, training stability is further improved with frame-number conditioning. Our experimental results demonstrate that the proposed method performed better than base methods in videos with various lengths and dynamics.
Force-EvT: A Closer Look at Robotic Gripper Force Measurement with Event-based Vision Transformer
Apr 01, 2024Robotic grippers are receiving increasing attention in various industries as essential components of robots for interacting and manipulating objects. While significant progress has been made in the past, conventional rigid grippers still have limitations in handling irregular objects and can damage fragile objects. We have shown that soft grippers offer deformability to adapt to a variety of object shapes and maximize object protection. At the same time, dynamic vision sensors (e.g., event-based cameras) are capable of capturing small changes in brightness and streaming them asynchronously as events, unlike RGB cameras, which do not perform well in low-light and fast-moving environments. In this paper, a dynamic-vision-based algorithm is proposed to measure the force applied to the gripper. In particular, we first set up a DVXplorer Lite series event camera to capture twenty-five sets of event data. Second, motivated by the impressive performance of the Vision Transformer (ViT) algorithm in dense image prediction tasks, we propose a new approach that demonstrates the potential for real-time force estimation and meets the requirements of real-world scenarios. We extensively evaluate the proposed algorithm on a wide range of scenarios and settings, and show that it consistently outperforms recent approaches.
AMOR: Ambiguous Authorship Order
Apr 01, 2024As we all know, writing scientific papers together with our beloved colleagues is a truly remarkable experience (partially): endless discussions about the same useless paragraph over and over again, followed by long days and long nights -- both at the same time. What a wonderful ride it is! What a beautiful life we have. But wait, there's one tiny little problem that utterly shatters the peace, turning even renowned scientists into bloodthirsty monsters: author order. The reason is that, contrary to widespread opinion, it's not the font size that matters, but the way things are ordered. Of course, this is a fairly well-known fact among scientists all across the planet (and beyond) and explains clearly why we regularly have to read about yet another escalated paper submission in local police reports. In this paper, we take an important step backwards to tackle this issue by solving the so-called author ordering problem (AOP) once and for all. Specifically, we propose AMOR, a system that replaces silly constructs like co-first or co-middle authorship with a simple yet easy probabilistic approach based on random shuffling of the author list at viewing time. In addition to AOP, we also solve the ambiguous author ordering citation problem} (AAOCP) on the fly. Stop author violence, be human.
A Novel Sector-Based Algorithm for an Optimized Star-Galaxy Classification
Apr 01, 2024This paper introduces a novel sector-based methodology for star-galaxy classification, leveraging the latest Sloan Digital Sky Survey data (SDSS-DR18). By strategically segmenting the sky into sectors aligned with SDSS observational patterns and employing a dedicated convolutional neural network (CNN), we achieve state-of-the-art performance for star galaxy classification. Our preliminary results demonstrate a promising pathway for efficient and precise astronomical analysis, especially in real-time observational settings.
HCTO: Optimality-Aware LiDAR Inertial Odometry with Hybrid Continuous Time Optimization for Compact Wearable Mapping System
Mar 21, 2024

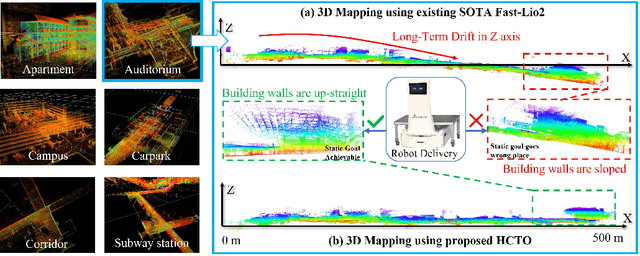
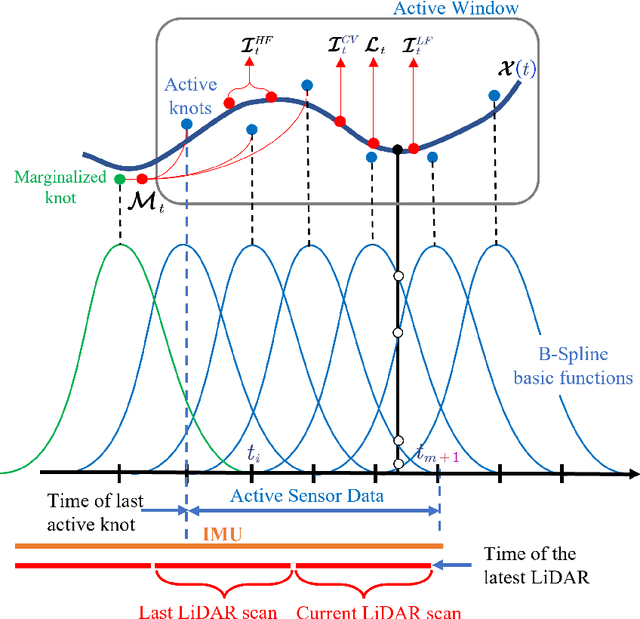
Compact wearable mapping system (WMS) has gained significant attention due to their convenience in various applications. Specifically, it provides an efficient way to collect prior maps for 3D structure inspection and robot-based "last-mile delivery" in complex environments. However, vibrations in human motion and the uneven distribution of point cloud features in complex environments often lead to rapid drift, which is a prevalent issue when applying existing LiDAR Inertial Odometry (LIO) methods on low-cost WMS. To address these limitations, we propose a novel LIO for WMSs based on Hybrid Continuous Time Optimization (HCTO) considering the optimality of Lidar correspondences. First, HCTO recognizes patterns in human motion (high-frequency part, low-frequency part, and constant velocity part) by analyzing raw IMU measurements. Second, HCTO constructs hybrid IMU factors according to different motion states, which enables robust and accurate estimation against vibration-induced noise in the IMU measurements. Third, the best point correspondences are selected using optimal design to achieve real-time performance and better odometry accuracy. We conduct experiments on head-mounted WMS datasets to evaluate the performance of our system, demonstrating significant advantages over state-of-the-art methods. Video recordings of experiments can be found on the project page of HCTO: \href{https://github.com/kafeiyin00/HCTO}{https://github.com/kafeiyin00/HCTO}.
NL2KQL: From Natural Language to Kusto Query
Apr 03, 2024Data is growing rapidly in volume and complexity. Proficiency in database query languages is pivotal for crafting effective queries. As coding assistants become more prevalent, there is significant opportunity to enhance database query languages. The Kusto Query Language (KQL) is a widely used query language for large semi-structured data such as logs, telemetries, and time-series for big data analytics platforms. This paper introduces NL2KQL an innovative framework that uses large language models (LLMs) to convert natural language queries (NLQs) to KQL queries. The proposed NL2KQL framework includes several key components: Schema Refiner which narrows down the schema to its most pertinent elements; the Few-shot Selector which dynamically selects relevant examples from a few-shot dataset; and the Query Refiner which repairs syntactic and semantic errors in KQL queries. Additionally, this study outlines a method for generating large datasets of synthetic NLQ-KQL pairs which are valid within a specific database contexts. To validate NL2KQL's performance, we utilize an array of online (based on query execution) and offline (based on query parsing) metrics. Through ablation studies, the significance of each framework component is examined, and the datasets used for benchmarking are made publicly available. This work is the first of its kind and is compared with available baselines to demonstrate its effectiveness.