 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A new economic and financial theory of money
Oct 17, 2023
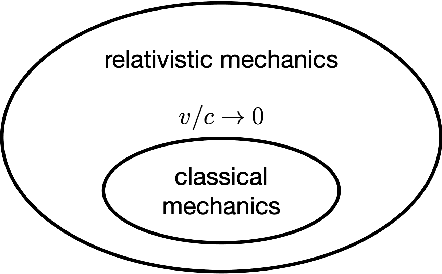
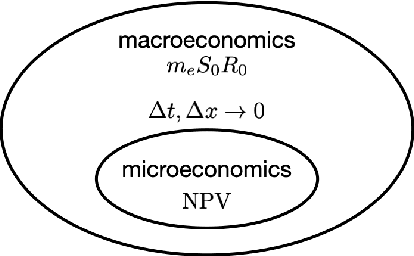
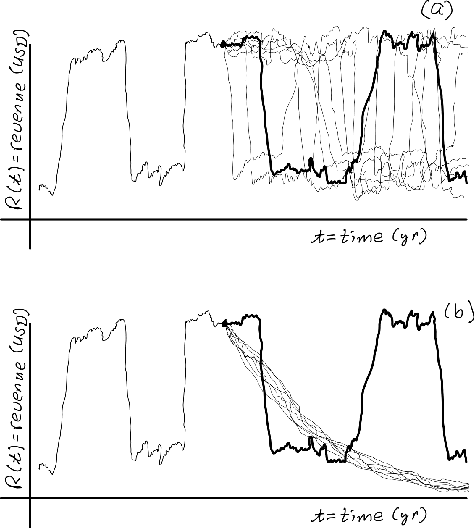
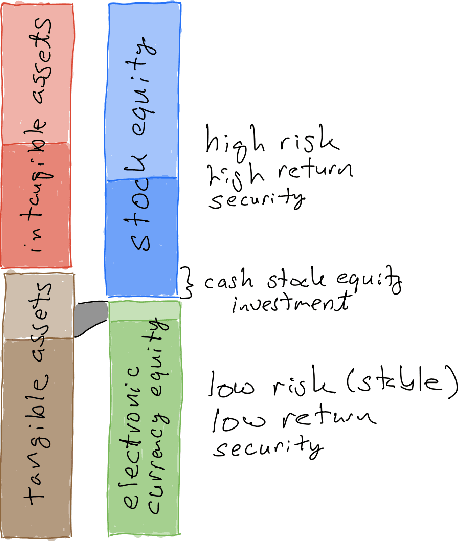
This paper fundamentally reformulates economic and financial theory to include electronic currencies. The valuation of the electronic currencies will be based on macroeconomic theory and the fundamental equation of monetary policy, not the microeconomic theory of discounted cash flows. The view of electronic currency as a transactional equity associated with tangible assets of a sub-economy will be developed, in contrast to the view of stock as an equity associated mostly with intangible assets of a sub-economy. The view will be developed of the electronic currency management firm as an entity responsible for coordinated monetary (electronic currency supply and value stabilization) and fiscal (investment and operational) policies of a substantial (for liquidity of the electronic currency) sub-economy. The risk model used in the valuations and the decision-making will not be the ubiquitous, yet inappropriate, exponential risk model that leads to discount rates, but will be multi time scale models that capture the true risk. The decision-making will be approached from the perspective of true systems control based on a system response function given by the multi scale risk model and system controllers that utilize the Deep Reinforcement Learning, Generative Pretrained Transformers, and other methods of Artificial Intelligence (DRL/GPT/AI). Finally, the sub-economy will be viewed as a nonlinear complex physical system with both stable equilibriums that are associated with short-term exploitation, and unstable equilibriums that need to be stabilized with active nonlinear control based on the multi scale system response functions and DRL/GPT/AI.
Synthetic Data Generation with Large Language Models for Text Classification: Potential and Limitations
Oct 13, 2023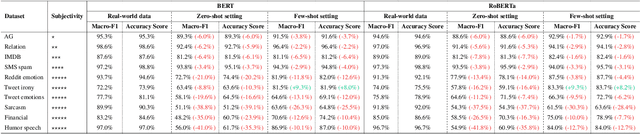
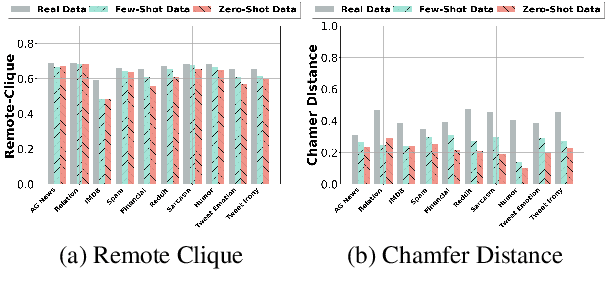

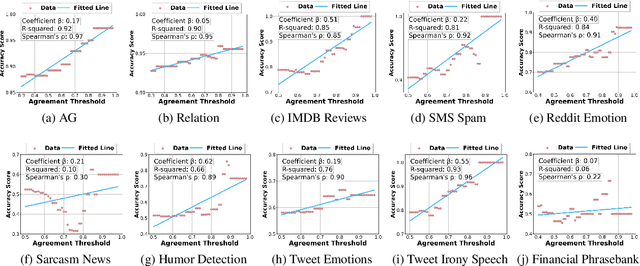
The collection and curation of high-quality training data is crucial for developing text classification models with superior performance, but it is often associated with significant costs and time investment. Researchers have recently explored using large language models (LLMs) to generate synthetic datasets as an alternative approach. However, the effectiveness of the LLM-generated synthetic data in supporting model training is inconsistent across different classification tasks. To better understand factors that moderate the effectiveness of the LLM-generated synthetic data, in this study, we look into how the performance of models trained on these synthetic data may vary with the subjectivity of classification. Our results indicate that subjectivity, at both the task level and instance level, is negatively associated with the performance of the model trained on synthetic data. We conclude by discussing the implications of our work on the potential and limitations of leveraging LLM for synthetic data generation.
DATT: Deep Adaptive Trajectory Tracking for Quadrotor Control
Oct 13, 2023Precise arbitrary trajectory tracking for quadrotors is challenging due to unknown nonlinear dynamics, trajectory infeasibility, and actuation limits. To tackle these challenges, we present Deep Adaptive Trajectory Tracking (DATT), a learning-based approach that can precisely track arbitrary, potentially infeasible trajectories in the presence of large disturbances in the real world. DATT builds on a novel feedforward-feedback-adaptive control structure trained in simulation using reinforcement learning. When deployed on real hardware, DATT is augmented with a disturbance estimator using L1 adaptive control in closed-loop, without any fine-tuning. DATT significantly outperforms competitive adaptive nonlinear and model predictive controllers for both feasible smooth and infeasible trajectories in unsteady wind fields, including challenging scenarios where baselines completely fail. Moreover, DATT can efficiently run online with an inference time less than 3.2 ms, less than 1/4 of the adaptive nonlinear model predictive control baseline
Energy-Aware Route Planning for a Battery-Constrained Robot with Multiple Charging Depots
Oct 02, 2023This paper considers energy-aware route planning for a battery-constrained robot operating in environments with multiple recharging depots. The robot has a battery discharge time $D$, and it should visit the recharging depots at most every $D$ time units to not run out of charge. The objective is to minimize robot's travel time while ensuring it visits all task locations in the environment. We present a $O(\log D)$ approximation algorithm for this problem. We also present heuristic improvements to the approximation algorithm and assess its performance on instances from TSPLIB, comparing it to an optimal solution obtained through Integer Linear Programming (ILP). The simulation results demonstrate that, despite a more than $20$-fold reduction in runtime, the proposed algorithm provides solutions that are, on average, within $31\%$ of the ILP solution.
Energy-Aware Ergodic Search: Continuous Exploration for Multi-Agent Systems with Battery Constraints
Oct 14, 2023
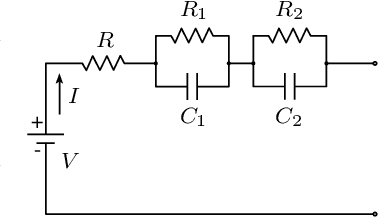
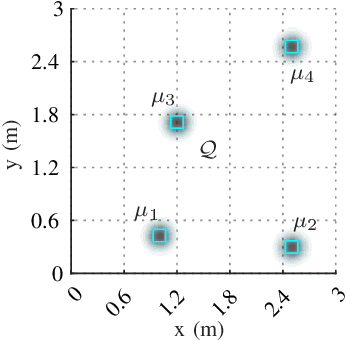
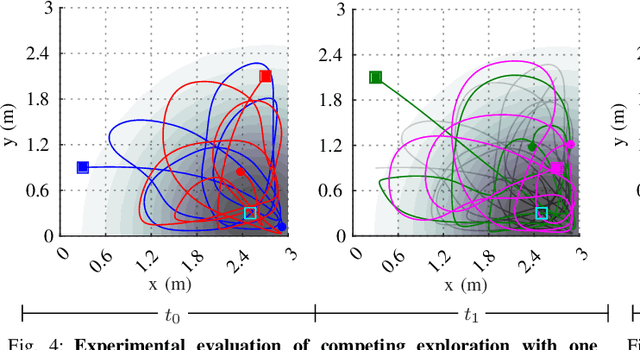
Autonomous exploration without interruption is important in scenarios such as search and rescue and precision agriculture, where consistent presence is needed to detect events over large areas. Ergodic search already derives continuous coverage trajectories in these scenarios so that a robot spends more time in areas with high information density. However, existing literature on ergodic search does not consider the robot's energy constraints, limiting how long a robot can explore. In fact, if the robots are battery-powered, it is physically not possible to continuously explore on a single battery charge. Our paper tackles this challenge by integrating ergodic search methods with energy-aware coverage. We trade off battery usage and coverage quality, maintaining uninterrupted exploration of a given space by at least one agent. Our approach derives an abstract battery model for future state-of-charge estimation and extends canonical ergodic search to ergodic search under battery constraints. Empirical data from simulations and real-world experiments demonstrate the effectiveness of our energy-aware ergodic search, which ensures continuous and uninterrupted exploration and guarantees spatial coverage.
Large-Scale OD Matrix Estimation with A Deep Learning Method
Oct 09, 2023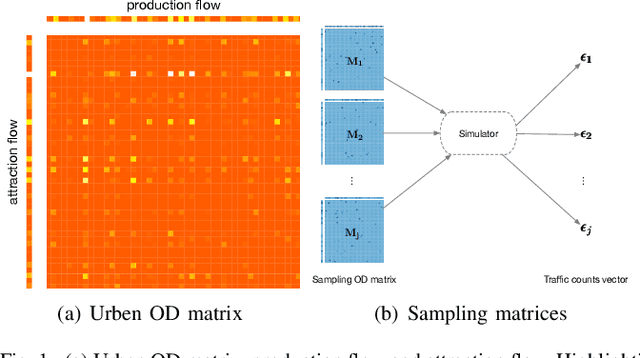
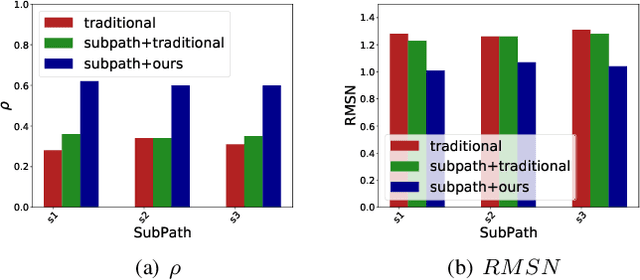
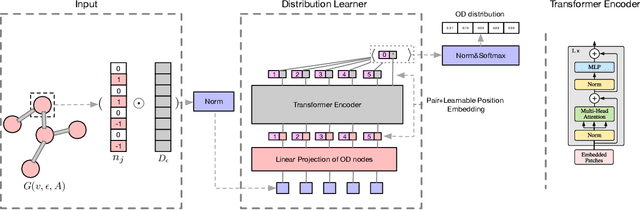
The estimation of origin-destination (OD) matrices is a crucial aspect of Intelligent Transport Systems (ITS). It involves adjusting an initial OD matrix by regressing the current observations like traffic counts of road sections (e.g., using least squares). However, the OD estimation problem lacks sufficient constraints and is mathematically underdetermined. To alleviate this problem, some researchers incorporate a prior OD matrix as a target in the regression to provide more structural constraints. However, this approach is highly dependent on the existing prior matrix, which may be outdated. Others add structural constraints through sensor data, such as vehicle trajectory and speed, which can reflect more current structural constraints in real-time. Our proposed method integrates deep learning and numerical optimization algorithms to infer matrix structure and guide numerical optimization. This approach combines the advantages of both deep learning and numerical optimization algorithms. The neural network(NN) learns to infer structural constraints from probe traffic flows, eliminating dependence on prior information and providing real-time performance. Additionally, due to the generalization capability of NN, this method is economical in engineering. We conducted tests to demonstrate the good generalization performance of our method on a large-scale synthetic dataset. Subsequently, we verified the stability of our method on real traffic data. Our experiments provided confirmation of the benefits of combining NN and numerical optimization.
Combining recurrent and residual learning for deforestation monitoring using multitemporal SAR images
Oct 09, 2023
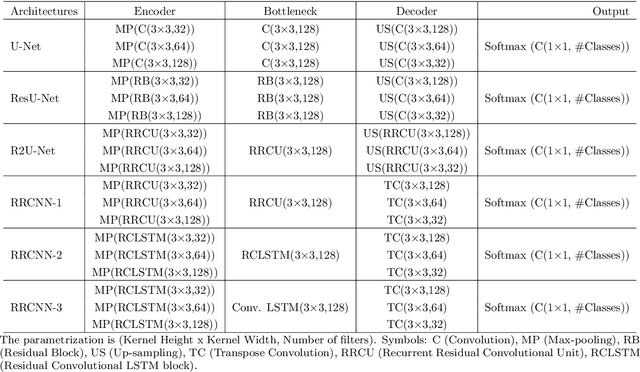
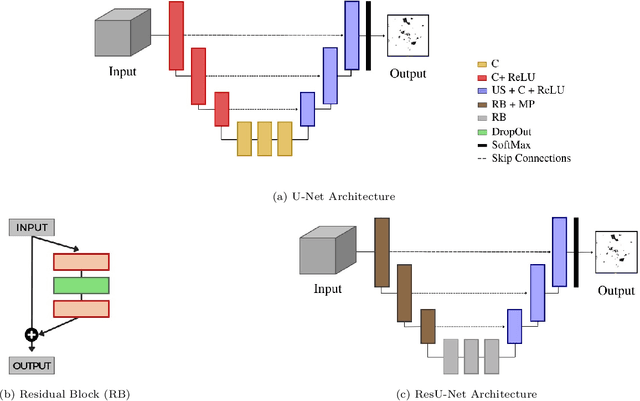
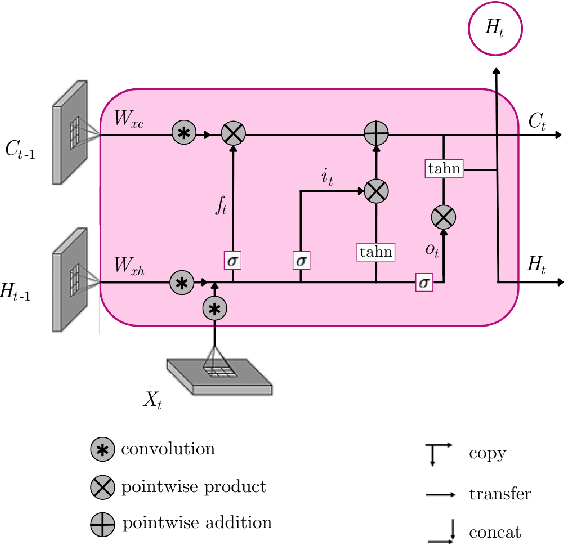
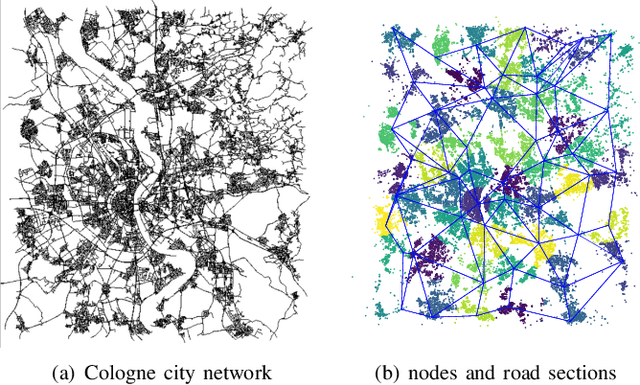
With its vast expanse, exceeding that of Western Europe by twice, the Amazon rainforest stands as the largest forest of the Earth, holding immense importance in global climate regulation. Yet, deforestation detection from remote sensing data in this region poses a critical challenge, often hindered by the persistent cloud cover that obscures optical satellite data for much of the year. Addressing this need, this paper proposes three deep-learning models tailored for deforestation monitoring, utilizing SAR (Synthetic Aperture Radar) multitemporal data moved by its independence on atmospheric conditions. Specifically, the study proposes three novel recurrent fully convolutional network architectures-namely, RRCNN-1, RRCNN-2, and RRCNN-3, crafted to enhance the accuracy of deforestation detection. Additionally, this research explores replacing a bitemporal with multitemporal SAR sequences, motivated by the hypothesis that deforestation signs quickly fade in SAR images over time. A comprehensive assessment of the proposed approaches was conducted using a Sentinel-1 multitemporal sequence from a sample site in the Brazilian rainforest. The experimental analysis confirmed that analyzing a sequence of SAR images over an observation period can reveal deforestation spots undetectable in a pair of images. Notably, experimental results underscored the superiority of the multitemporal approach, yielding approximately a five percent enhancement in F1-Score across all tested network architectures. Particularly the RRCNN-1 achieved the highest accuracy and also boasted half the processing time of its closest counterpart.
Quantifying and mitigating the impact of label errors on model disparity metrics
Oct 04, 2023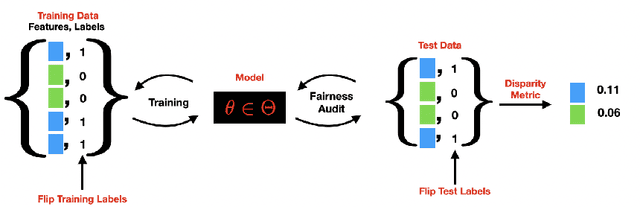

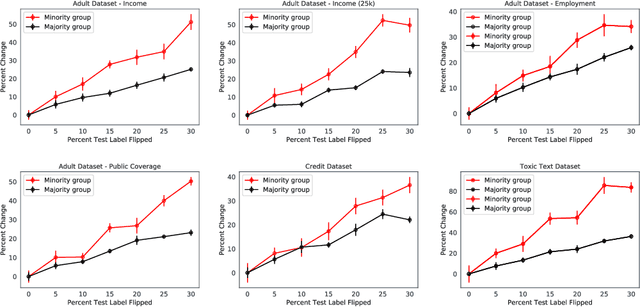
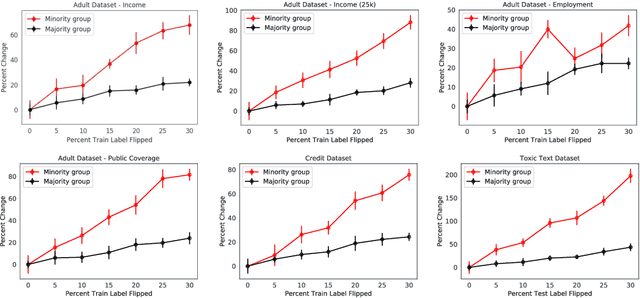
Errors in labels obtained via human annotation adversely affect a model's performance. Existing approaches propose ways to mitigate the effect of label error on a model's downstream accuracy, yet little is known about its impact on a model's disparity metrics. Here we study the effect of label error on a model's disparity metrics. We empirically characterize how varying levels of label error, in both training and test data, affect these disparity metrics. We find that group calibration and other metrics are sensitive to train-time and test-time label error -- particularly for minority groups. This disparate effect persists even for models trained with noise-aware algorithms. To mitigate the impact of training-time label error, we present an approach to estimate the influence of a training input's label on a model's group disparity metric. We empirically assess the proposed approach on a variety of datasets and find significant improvement, compared to alternative approaches, in identifying training inputs that improve a model's disparity metric. We complement the approach with an automatic relabel-and-finetune scheme that produces updated models with, provably, improved group calibration error.
Sparse Binary Transformers for Multivariate Time Series Modeling
Aug 09, 2023Compressed Neural Networks have the potential to enable deep learning across new applications and smaller computational environments. However, understanding the range of learning tasks in which such models can succeed is not well studied. In this work, we apply sparse and binary-weighted Transformers to multivariate time series problems, showing that the lightweight models achieve accuracy comparable to that of dense floating-point Transformers of the same structure. Our model achieves favorable results across three time series learning tasks: classification, anomaly detection, and single-step forecasting. Additionally, to reduce the computational complexity of the attention mechanism, we apply two modifications, which show little to no decline in model performance: 1) in the classification task, we apply a fixed mask to the query, key, and value activations, and 2) for forecasting and anomaly detection, which rely on predicting outputs at a single point in time, we propose an attention mask to allow computation only at the current time step. Together, each compression technique and attention modification substantially reduces the number of non-zero operations necessary in the Transformer. We measure the computational savings of our approach over a range of metrics including parameter count, bit size, and floating point operation (FLOPs) count, showing up to a 53x reduction in storage size and up to 10.5x reduction in FLOPs.
Physics-assisted machine learning for THz spectroscopy: sensing moisture on plant leaves
Oct 06, 2023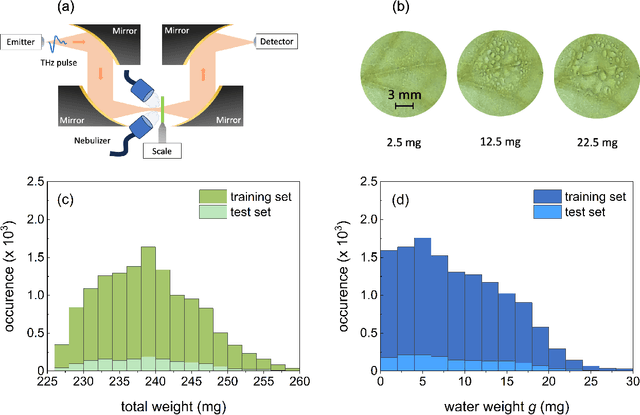
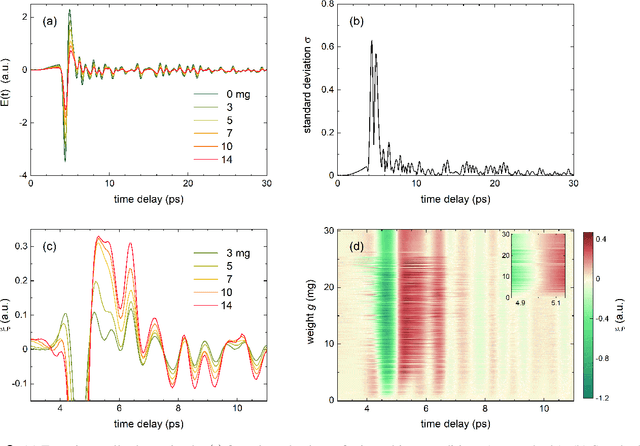
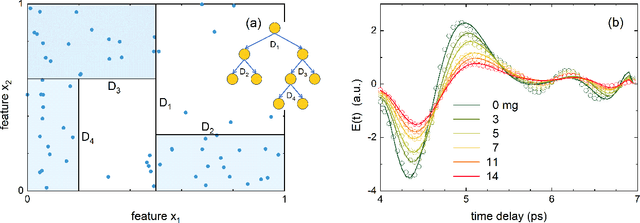
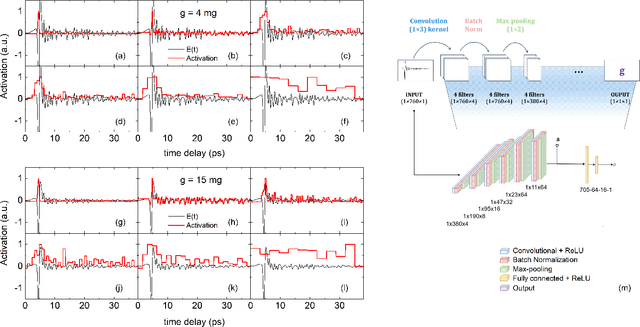
Signal processing techniques are of vital importance to bring THz spectroscopy to a maturity level to reach practical applications. In this work, we illustrate the use of machine learning techniques for THz time-domain spectroscopy assisted by domain knowledge based on light-matter interactions. We aim at the potential agriculture application to determine the amount of free water on plant leaves, so-called leaf wetness. This quantity is important for understanding and predicting plant diseases that need leaf wetness for disease development. The overall transmission of a moist plant leaf for 12,000 distinct water patterns was experimentally acquired using THz time-domain spectroscopy. We report on key insights of applying decision trees and convolutional neural networks to the data using physics-motivated choices. Eventually, we discuss the generalizability of these models to determine leaf wetness after testing them on cases with increasing deviations from the training set.