 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Distributed Estimation with Partially Accessible Information: An IMAT Approach to LMS Diffusion
Oct 17, 2023
Distributed algorithms, particularly Diffusion Least Mean Square, are widely favored for their reliability, robustness, and fast convergence in various industries. However, limited observability of the target can compromise the integrity of the algorithm. To address this issue, this paper proposes a framework for analyzing combination strategies by drawing inspiration from signal flow analysis. A thresholding-based algorithm is also presented to identify and utilize the support vector in scenarios with missing information about the target vector's support. The proposed approach is demonstrated in two combination scenarios, showcasing the effectiveness of the algorithm in situations characterized by sparse observations in the time and transform domains.
Field Robot for High-throughput and High-resolution 3D Plant Phenotyping
Oct 17, 2023With the need to feed a growing world population, the efficiency of crop production is of paramount importance. To support breeding and field management, various characteristics of the plant phenotype need to be measured -- a time-consuming process when performed manually. We present a robotic platform equipped with multiple laser and camera sensors for high-throughput, high-resolution in-field plant scanning. We create digital twins of the plants through 3D reconstruction. This allows the estimation of phenotypic traits such as leaf area, leaf angle, and plant height. We validate our system on a real field, where we reconstruct accurate point clouds and meshes of sugar beet, soybean, and maize.
Towards Design and Development of an ArUco Markers-Based Quantitative Surface Tactile Sensor
Oct 12, 2023

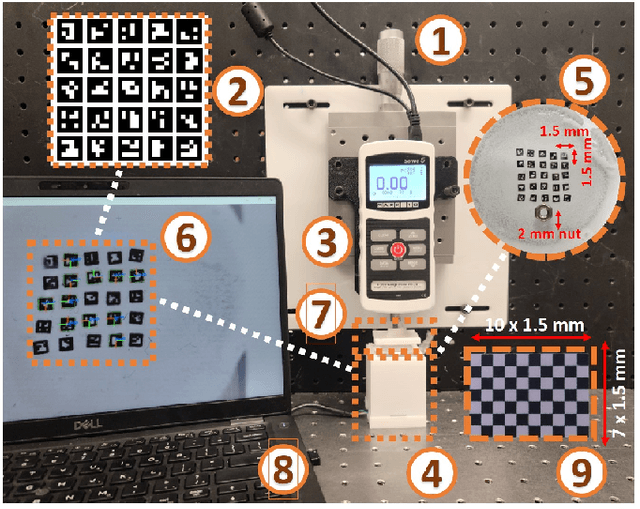
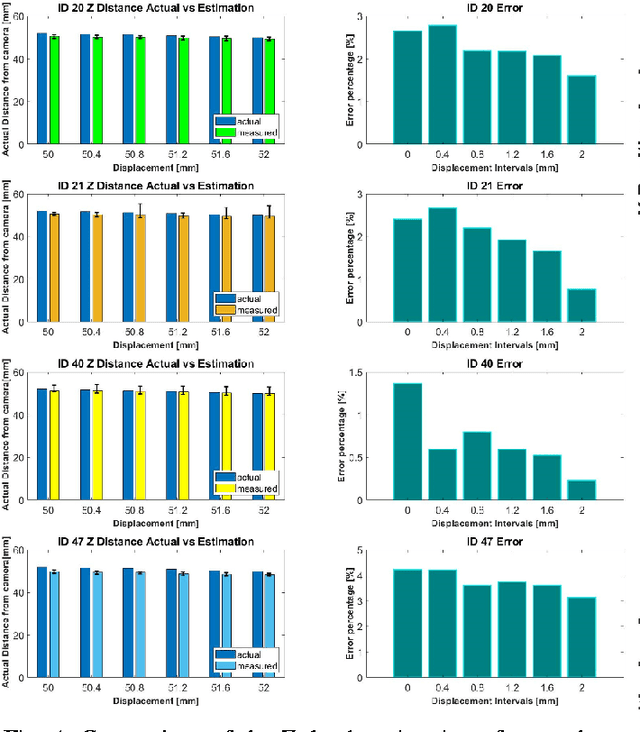
In this paper, with the goal of quantifying the qualitative image outputs of a Vision-based Tactile Sensor (VTS), we present the design, fabrication, and characterization of a novel Quantitative Surface Tactile Sensor (called QS-TS). QS-TS directly estimates the sensor's gel layer deformation in real-time enabling safe and autonomous tactile manipulation and servoing of delicate objects using robotic manipulators. The core of the proposed sensor is the utilization of miniature 1.5 mm x 1.5 mm synthetic square markers with inner binary patterns and a broad black border, called ArUco Markers. Each ArUco marker can provide real-time camera pose estimation that, in our design, is used as a quantitative measure for obtaining deformation of the QS-TS gel layer. Moreover, thanks to the use of ArUco markers, we propose a unique fabrication procedure that mitigates various challenges associated with the fabrication of the existing marker-based VTSs and offers an intuitive and less-arduous method for the construction of the VTS. Remarkably, the proposed fabrication facilitates the integration and adherence of markers with the gel layer to robustly and reliably obtain a quantitative measure of deformation in real-time regardless of the orientation of ArUco Markers. The performance and efficacy of the proposed QS-TS in estimating the deformation of the sensor's gel layer were experimentally evaluated and verified. Results demonstrate the phenomenal performance of the QS-TS in estimating the deformation of the gel layer with a relative error of <5%.
MacFormer: Map-Agent Coupled Transformer for Real-time and Robust Trajectory Prediction
Aug 31, 2023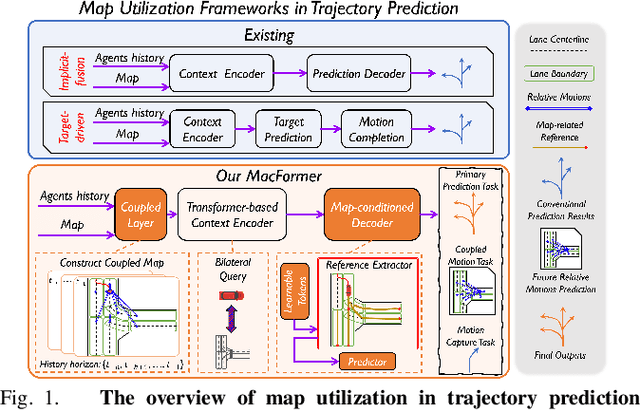
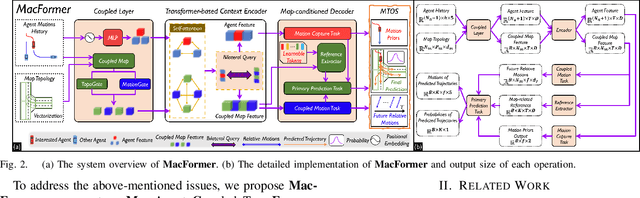
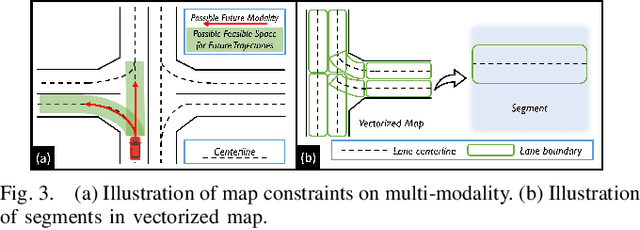
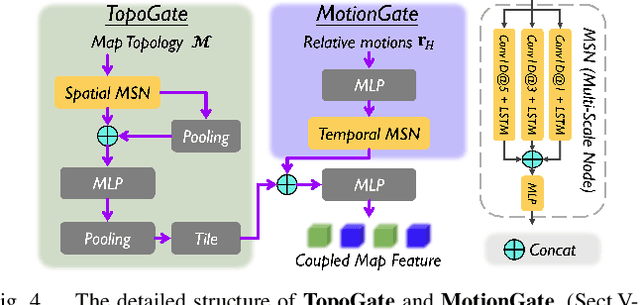
Predicting the future behavior of agents is a fundamental task in autonomous vehicle domains. Accurate prediction relies on comprehending the surrounding map, which significantly regularizes agent behaviors. However, existing methods have limitations in exploiting the map and exhibit a strong dependence on historical trajectories, which yield unsatisfactory prediction performance and robustness. Additionally, their heavy network architectures impede real-time applications. To tackle these problems, we propose Map-Agent Coupled Transformer (MacFormer) for real-time and robust trajectory prediction. Our framework explicitly incorporates map constraints into the network via two carefully designed modules named coupled map and reference extractor. A novel multi-task optimization strategy (MTOS) is presented to enhance learning of topology and rule constraints. We also devise bilateral query scheme in context fusion for a more efficient and lightweight network. We evaluated our approach on Argoverse 1, Argoverse 2, and nuScenes real-world benchmarks, where it all achieved state-of-the-art performance with the lowest inference latency and smallest model size. Experiments also demonstrate that our framework is resilient to imperfect tracklet inputs. Furthermore, we show that by combining with our proposed strategies, classical models outperform their baselines, further validating the versatility of our framework.
LARA: A Light and Anti-overfitting Retraining Approach for Unsupervised Anomaly Detection
Oct 09, 2023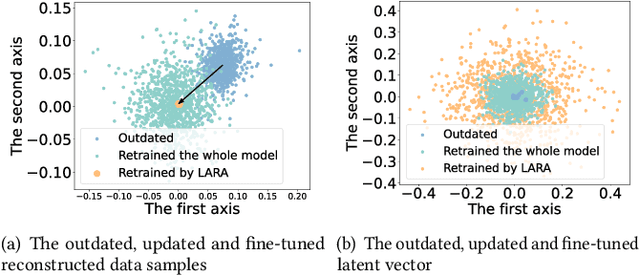

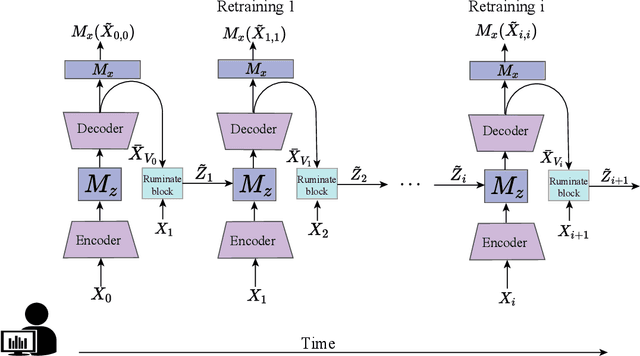
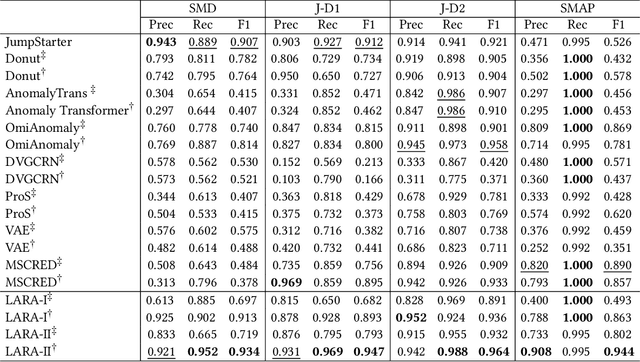
Most of current anomaly detection models assume that the normal pattern remains same all the time. However, the normal patterns of Web services change dramatically and frequently. The model trained on old-distribution data is outdated after such changes. Retraining the whole model every time is expensive. Besides, at the beginning of normal pattern changes, there is not enough observation data from the new distribution. Retraining a large neural network model with limited data is vulnerable to overfitting. Thus, we propose a Light and Anti-overfitting Retraining Approach (LARA) for deep variational auto-encoder based time series anomaly detection methods (VAEs). This work aims to make three novel contributions: 1) the retraining process is formulated as a convex problem and can converge at a fast rate as well as prevent overfitting; 2) designing a ruminate block, which leverages the historical data without the need to store them; 3) mathematically proving that when fine-tuning the latent vector and reconstructed data, the linear formations can achieve the least adjusting errors between the ground truths and the fine-tuned ones. Moreover, we have performed many experiments to verify that retraining LARA with even 43 time slots of data from new distribution can result in its competitive F1 Score in comparison with the state-of-the-art anomaly detection models trained with sufficient data. Besides, we verify its light overhead.
ALGAN: Time Series Anomaly Detection with Adjusted-LSTM GAN
Aug 13, 2023
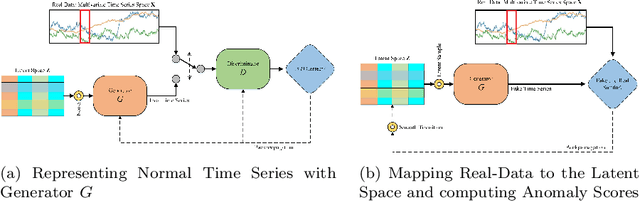
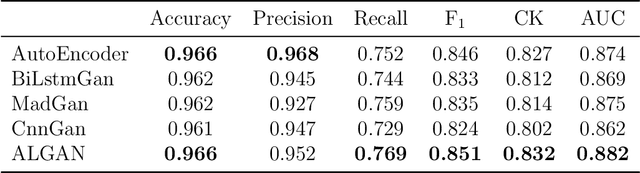
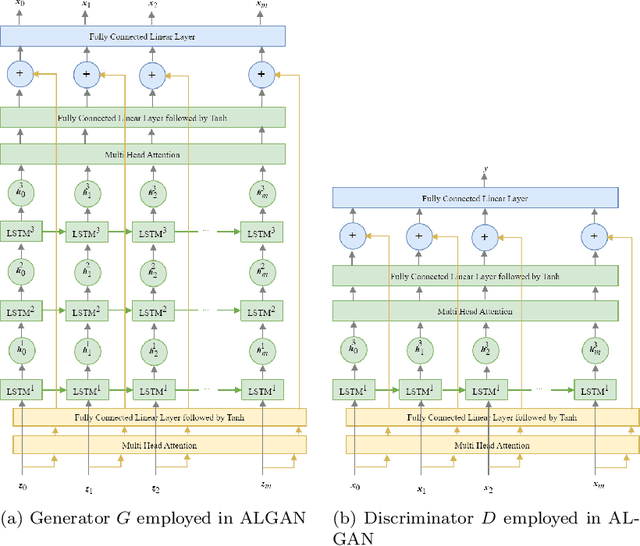
Anomaly detection in time series data, to identify points that deviate from normal behaviour, is a common problem in various domains such as manufacturing, medical imaging, and cybersecurity. Recently, Generative Adversarial Networks (GANs) are shown to be effective in detecting anomalies in time series data. The neural network architecture of GANs (i.e. Generator and Discriminator) can significantly improve anomaly detection accuracy. In this paper, we propose a new GAN model, named Adjusted-LSTM GAN (ALGAN), which adjusts the output of an LSTM network for improved anomaly detection in both univariate and multivariate time series data in an unsupervised setting. We evaluate the performance of ALGAN on 46 real-world univariate time series datasets and a large multivariate dataset that spans multiple domains. Our experiments demonstrate that ALGAN outperforms traditional, neural network-based, and other GAN-based methods for anomaly detection in time series data.
High-Quality 3D Face Reconstruction with Affine Convolutional Networks
Oct 22, 2023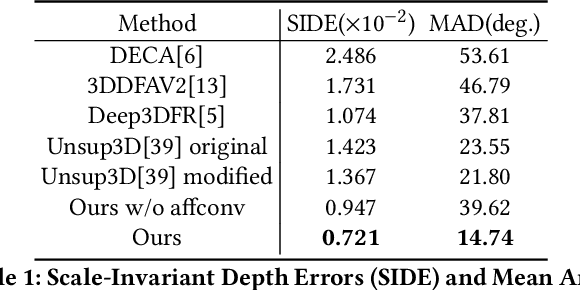
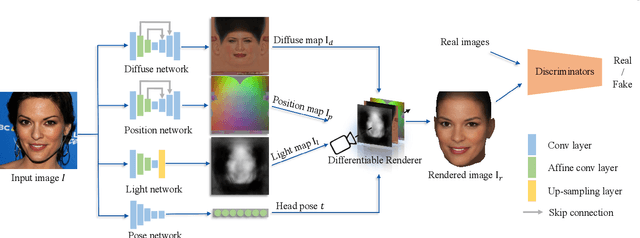
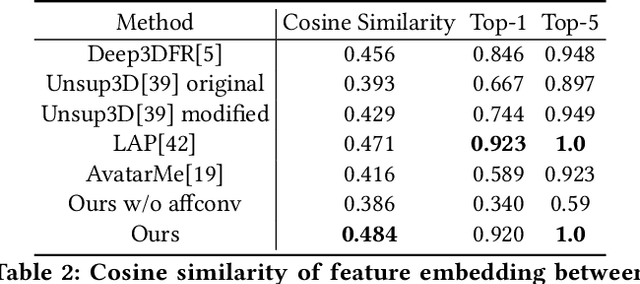
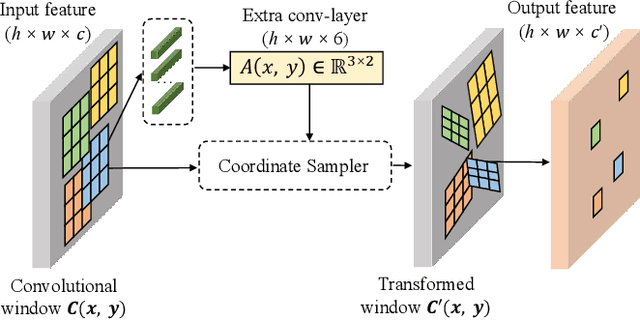
Recent works based on convolutional encoder-decoder architecture and 3DMM parameterization have shown great potential for canonical view reconstruction from a single input image. Conventional CNN architectures benefit from exploiting the spatial correspondence between the input and output pixels. However, in 3D face reconstruction, the spatial misalignment between the input image (e.g. face) and the canonical/UV output makes the feature encoding-decoding process quite challenging. In this paper, to tackle this problem, we propose a new network architecture, namely the Affine Convolution Networks, which enables CNN based approaches to handle spatially non-corresponding input and output images and maintain high-fidelity quality output at the same time. In our method, an affine transformation matrix is learned from the affine convolution layer for each spatial location of the feature maps. In addition, we represent 3D human heads in UV space with multiple components, including diffuse maps for texture representation, position maps for geometry representation, and light maps for recovering more complex lighting conditions in the real world. All the components can be trained without any manual annotations. Our method is parametric-free and can generate high-quality UV maps at resolution of 512 x 512 pixels, while previous approaches normally generate 256 x 256 pixels or smaller. Our code will be released once the paper got accepted.
Computation-Limited Signals: A Channel Capacity Regime Constrained by Computational Complexity
Oct 09, 2023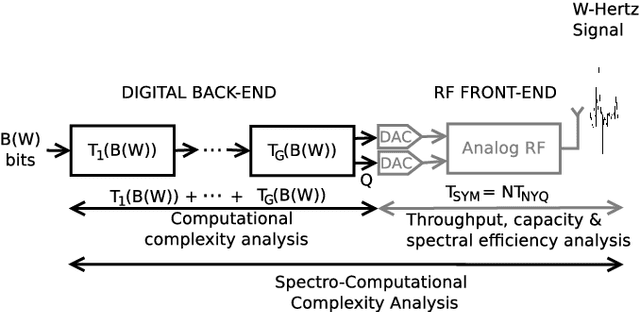
In this letter, we introduce the computational-limited (comp-limited) signals, a communication capacity regime in which the signal time computational complexity overhead is the key constraint -- rather than power or bandwidth -- to the overall communication capacity. To relate capacity and time complexity, we propose a novel mathematical framework that builds on concepts of information theory and computational complexity. In particular, the algorithmic capacity stands for the ratio between the upper-bound number of bits modulated in a symbol and the lower-bound time complexity required to turn these bits into a communication symbol. By setting this ratio as function of the channel resources, we classify a given signal design as comp-limited if its algorithmic capacity nullifies as the channel resources grow. As a use-case, we show that an uncoded OFDM transmitter is comp-limited unless the lower-bound computational complexity of the N-point DFT problem verifies as $\Omega(N)$, which remains an open challenge in theoretical computer science.
Denoising total scattering data using Compressed Sensing
Oct 19, 2023To obtain the best resolution for any measurement there is an ever-present challenge to achieve maximal differentiation between signal and noise over as fine of sampling dimensions as possible. In diffraction science these issues are particularly pervasive when analyzing small crystals, systems with diffuse scattering, or other systems in which the signal of interest is extremely weak and incident flux and instrument time is limited. We here demonstrate that the tool of compressed sensing, which has successfully been applied to photography, facial recognition, and medical imaging, can be effectively applied to diffraction images to dramatically improve the signal-to-noise ratio (SNR) in a data-driven fashion without the need for additional measurements or modification of existing hardware. We outline a technique that leverages compressive sensing to bootstrap a single diffraction measurement into an effectively arbitrary number of virtual measurements, thereby providing a means of super-resolution imaging.
Mean Estimation Under Heterogeneous Privacy Demands
Oct 19, 2023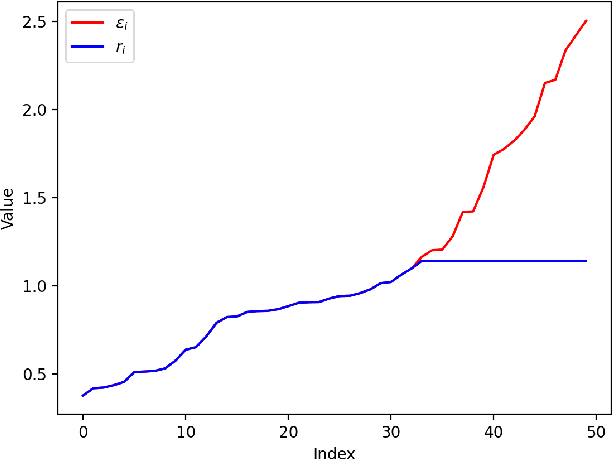
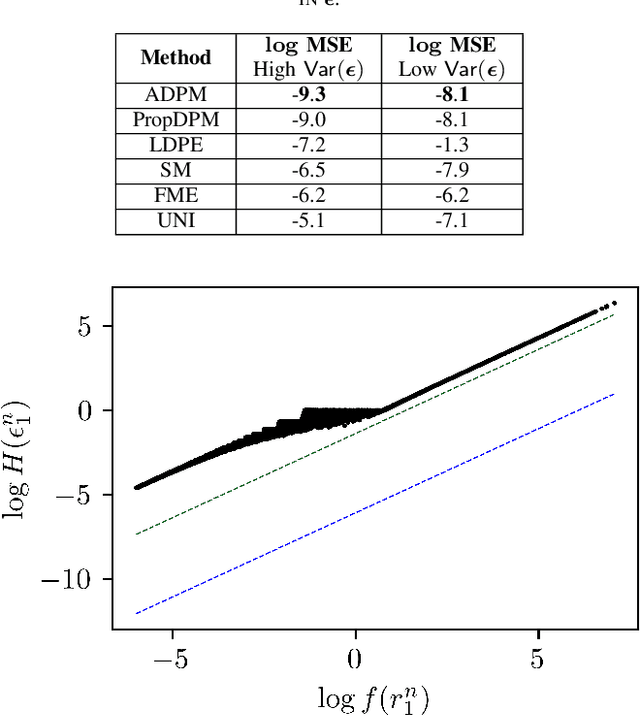
Differential Privacy (DP) is a well-established framework to quantify privacy loss incurred by any algorithm. Traditional formulations impose a uniform privacy requirement for all users, which is often inconsistent with real-world scenarios in which users dictate their privacy preferences individually. This work considers the problem of mean estimation, where each user can impose their own distinct privacy level. The algorithm we propose is shown to be minimax optimal and has a near-linear run-time. Our results elicit an interesting saturation phenomenon that occurs. Namely, the privacy requirements of the most stringent users dictate the overall error rates. As a consequence, users with less but differing privacy requirements are all given more privacy than they require, in equal amounts. In other words, these privacy-indifferent users are given a nontrivial degree of privacy for free, without any sacrifice in the performance of the estimator.