 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Human Motion Compensation Framework for a Supernumerary Robotic Arm
Oct 16, 2023
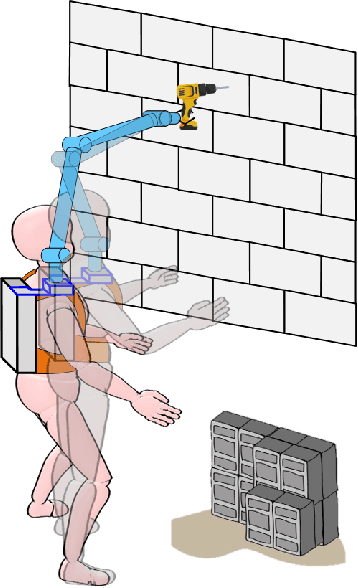
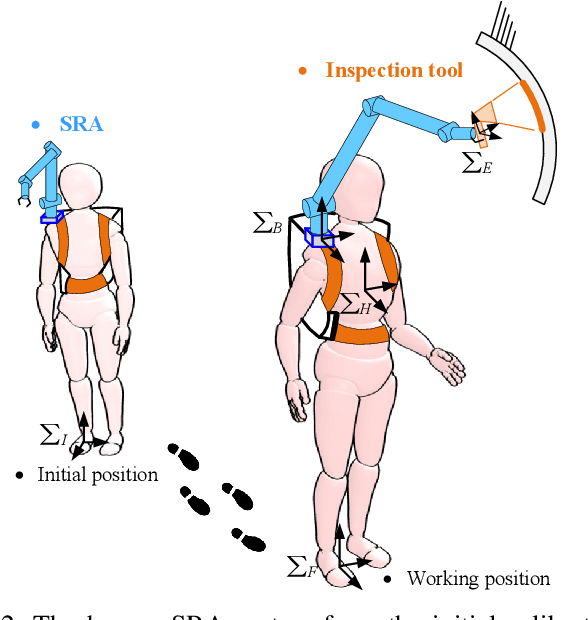
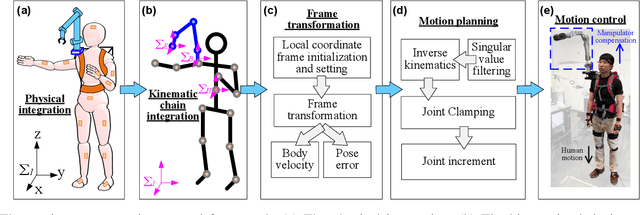

Supernumerary robotic arms (SRAs) can be used as the third arm to complement and augment the abilities of human users. The user carrying a SRA forms a connected kinodynamic chain, which can be viewed as a special class of floating-base robot systems. However, unlike general floating-base robot systems, human users are the bases of SRAs and they have their subjective behaviors/motions. This implies that human body motions can unintentionally affect the SRA's end-effector movements. To address this challenge, we propose a framework to compensate for the human whole-body motions that interfere with the SRA's end-effector trajectories. The SRA system in this study consists of a 6-degree-of-freedom lightweight arm and a wearable interface. The wearable interface allows users to adjust the installation position of the SRA to fit different body shapes. An inertial measurement unit (IMU)-based sensory interface can provide the body skeleton motion feedback of the human user in real time. By simplifying the floating-base kinematics model, we design an effective motion planner by reconstructing the Jacobian matrix of the SRA. Under the proposed framework, the performance of the reconstructed Jacobian method is assessed by comparing the results obtained with the classical nullspace-based method through two sets of experiments.
Object Detection in Aerial Images in Scarce Data Regimes
Oct 16, 2023Most contributions on Few-Shot Object Detection (FSOD) evaluate their methods on natural images only, yet the transferability of the announced performance is not guaranteed for applications on other kinds of images. We demonstrate this with an in-depth analysis of existing FSOD methods on aerial images and observed a large performance gap compared to natural images. Small objects, more numerous in aerial images, are the cause for the apparent performance gap between natural and aerial images. As a consequence, we improve FSOD performance on small objects with a carefully designed attention mechanism. In addition, we also propose a scale-adaptive box similarity criterion, that improves the training and evaluation of FSOD methods, particularly for small objects. We also contribute to generic FSOD with two distinct approaches based on metric learning and fine-tuning. Impressive results are achieved with the fine-tuning method, which encourages tackling more complex scenarios such as Cross-Domain FSOD. We conduct preliminary experiments in this direction and obtain promising results. Finally, we address the deployment of the detection models inside COSE's systems. Detection must be done in real-time in extremely large images (more than 100 megapixels), with limited computation power. Leveraging existing optimization tools such as TensorRT, we successfully tackle this engineering challenge.
Generative Calibration for In-context Learning
Oct 16, 2023As one of the most exciting features of large language models (LLMs), in-context learning is a mixed blessing. While it allows users to fast-prototype a task solver with only a few training examples, the performance is generally sensitive to various configurations of the prompt such as the choice or order of the training examples. In this paper, we for the first time theoretically and empirically identify that such a paradox is mainly due to the label shift of the in-context model to the data distribution, in which LLMs shift the label marginal $p(y)$ while having a good label conditional $p(x|y)$. With this understanding, we can simply calibrate the in-context predictive distribution by adjusting the label marginal, which is estimated via Monte-Carlo sampling over the in-context model, i.e., generation of LLMs. We call our approach as generative calibration. We conduct exhaustive experiments with 12 text classification tasks and 12 LLMs scaling from 774M to 33B, generally find that the proposed method greatly and consistently outperforms the ICL as well as state-of-the-art calibration methods, by up to 27% absolute in macro-F1. Meanwhile, the proposed method is also stable under different prompt configurations.
An Interpretable Deep-Learning Framework for Predicting Hospital Readmissions From Electronic Health Records
Oct 16, 2023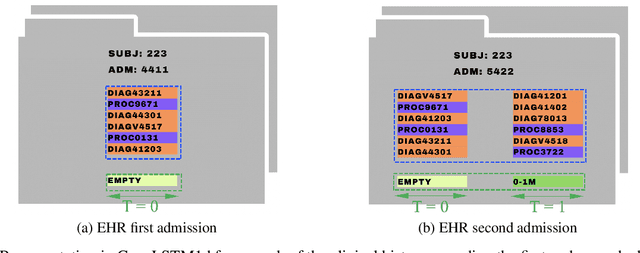
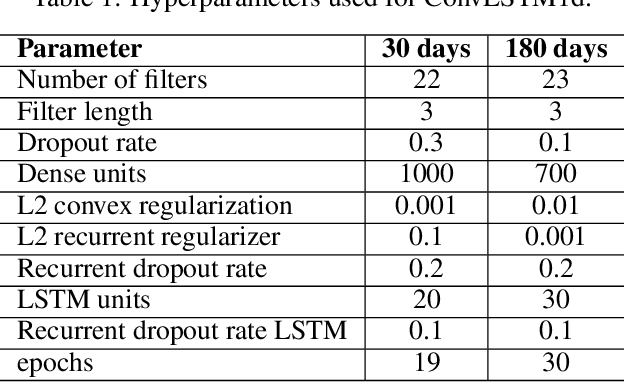
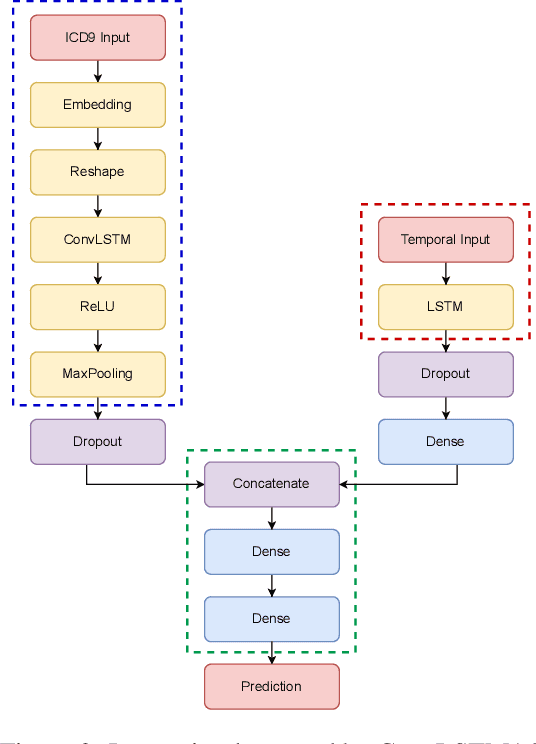
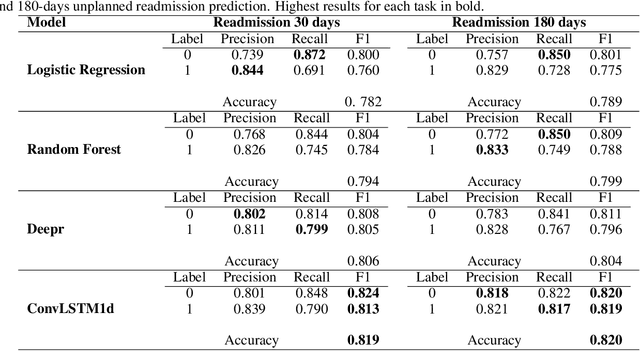
With the increasing availability of patients' data, modern medicine is shifting towards prospective healthcare. Electronic health records contain a variety of information useful for clinical patient description and can be exploited for the construction of predictive models, given that similar medical histories will likely lead to similar progressions. One example is unplanned hospital readmission prediction, an essential task for reducing hospital costs and improving patient health. Despite predictive models showing very good performances especially with deep-learning models, they are often criticized for the poor interpretability of their results, a fundamental characteristic in the medical field, where incorrect predictions might have serious consequences for the patient health. In this paper we propose a novel, interpretable deep-learning framework for predicting unplanned hospital readmissions, supported by NLP findings on word embeddings and by neural-network models (ConvLSTM) for better handling temporal data. We validate our system on the two predictive tasks of hospital readmission within 30 and 180 days, using real-world data. In addition, we introduce and test a model-dependent technique to make the representation of results easily interpretable by the medical staff. Our solution achieves better performances compared to traditional models based on machine learning, while providing at the same time more interpretable results.
Population-based wind farm monitoring based on a spatial autoregressive approach
Oct 16, 2023An important challenge faced by wind farm operators is to reduce operation and maintenance cost. Structural health monitoring provides a means of cost reduction through minimising unnecessary maintenance trips as well as prolonging turbine service life. Population-based structural health monitoring can further reduce the cost of health monitoring systems by implementing one system for multiple structures (i.e.~turbines). At the same time, shared data within a population of structures may improve the predictions of structural behaviour. To monitor turbine performance at a population/farm level, an important initial step is to construct a model that describes the behaviour of all turbines under normal conditions. This paper proposes a population-level model that explicitly captures the spatial and temporal correlations (between turbines) induced by the wake effect. The proposed model is a Gaussian process-based spatial autoregressive model, named here a GP-SPARX model. This approach is developed since (a) it reflects our physical understanding of the wake effect, and (b) it benefits from a stochastic data-based learner. A case study is provided to demonstrate the capability of the GP-SPARX model in capturing spatial and temporal variations as well as its potential applicability in a health monitoring system.
PELA: Learning Parameter-Efficient Models with Low-Rank Approximation
Oct 16, 2023Applying a pre-trained large model to downstream tasks is prohibitive under resource-constrained conditions. Recent dominant approaches for addressing efficiency issues involve adding a few learnable parameters to the fixed backbone model. This strategy, however, leads to more challenges in loading large models for downstream fine-tuning with limited resources. In this paper, we propose a novel method for increasing the parameter efficiency of pre-trained models by introducing an intermediate pre-training stage. To this end, we first employ low-rank approximation to compress the original large model and then devise a feature distillation module and a weight perturbation regularization module. These modules are specifically designed to enhance the low-rank model. Concretely, we update only the low-rank model while freezing the backbone parameters during pre-training. This allows for direct and efficient utilization of the low-rank model for downstream tasks. The proposed method achieves both efficiencies in terms of required parameters and computation time while maintaining comparable results with minimal modifications to the base architecture. Specifically, when applied to three vision-only and one vision-language Transformer models, our approach often demonstrates a $\sim$0.6 point decrease in performance while reducing the original parameter size by 1/3 to 2/3.
Unlocking Metasurface Practicality for B5G Networks: AI-assisted RIS Planning
Oct 16, 2023The advent of reconfigurable intelligent surfaces(RISs) brings along significant improvements for wireless technology on the verge of beyond-fifth-generation networks (B5G).The proven flexibility in influencing the propagation environment opens up the possibility of programmatically altering the wireless channel to the advantage of network designers, enabling the exploitation of higher-frequency bands for superior throughput overcoming the challenging electromagnetic (EM) propagation properties at these frequency bands. However, RISs are not magic bullets. Their employment comes with significant complexity, requiring ad-hoc deployments and management operations to come to fruition. In this paper, we tackle the open problem of bringing RISs to the field, focusing on areas with little or no coverage. In fact, we present a first-of-its-kind deep reinforcement learning (DRL) solution, dubbed as D-RISA, which trains a DRL agent and, in turn, obtain san optimal RIS deployment. We validate our framework in the indoor scenario of the Rennes railway station in France, assessing the performance of our algorithm against state-of-the-art (SOA) approaches. Our benchmarks showcase better coverage, i.e., 10-dB increase in minimum signal-to-noise ratio (SNR), at lower computational time (up to -25 percent) while improving scalability towards denser network deployments.
GRU-D-Weibull: A Novel Real-Time Individualized Endpoint Prediction
Aug 14, 2023Accurate prediction models for individual-level endpoints and time-to-endpoints are crucial in clinical practice. In this study, we propose a novel approach, GRU-D-Weibull, which combines gated recurrent units with decay (GRU-D) to model the Weibull distribution. Our method enables real-time individualized endpoint prediction and population-level risk management. Using a cohort of 6,879 patients with stage 4 chronic kidney disease (CKD4), we evaluated the performance of GRU-D-Weibull in endpoint prediction. The C-index of GRU-D-Weibull was ~0.7 at the index date and increased to ~0.77 after 4.3 years of follow-up, similar to random survival forest. Our approach achieved an absolute L1-loss of ~1.1 years (SD 0.95) at the CKD4 index date and a minimum of ~0.45 years (SD0.3) at 4 years of follow-up, outperforming competing methods significantly. GRU-D-Weibull consistently constrained the predicted survival probability at the time of an event within a smaller and more fixed range compared to other models throughout the follow-up period. We observed significant correlations between the error in point estimates and missing proportions of input features at the index date (correlations from ~0.1 to ~0.3), which diminished within 1 year as more data became available. By post-training recalibration, we successfully aligned the predicted and observed survival probabilities across multiple prediction horizons at different time points during follow-up. Our findings demonstrate the considerable potential of GRU-D-Weibull as the next-generation architecture for endpoint risk management, capable of generating various endpoint estimates for real-time monitoring using clinical data.
How to Capture Higher-order Correlations? Generalizing Matrix Softmax Attention to Kronecker Computation
Oct 06, 2023In the classical transformer attention scheme, we are given three $n \times d$ size matrices $Q, K, V$ (the query, key, and value tokens), and the goal is to compute a new $n \times d$ size matrix $D^{-1} \exp(QK^\top) V$ where $D = \mathrm{diag}( \exp(QK^\top) {\bf 1}_n )$. In this work, we study a generalization of attention which captures triple-wise correlations. This generalization is able to solve problems about detecting triple-wise connections that were shown to be impossible for transformers. The potential downside of this generalization is that it appears as though computations are even more difficult, since the straightforward algorithm requires cubic time in $n$. However, we show that in the bounded-entry setting (which arises in practice, and which is well-studied in both theory and practice), there is actually a near-linear time algorithm. More precisely, we show that bounded entries are both necessary and sufficient for quickly performing generalized computations: $\bullet$ On the positive side, if all entries of the input matrices are bounded above by $o(\sqrt[3]{\log n})$ then we show how to approximate the ``tensor-type'' attention matrix in $n^{1+o(1)}$ time. $\bullet$ On the negative side, we show that if the entries of the input matrices may be as large as $\Omega(\sqrt[3]{\log n})$, then there is no algorithm that runs faster than $n^{3-o(1)}$ (assuming the Strong Exponential Time Hypothesis from fine-grained complexity theory). We also show that our construction, algorithms, and lower bounds naturally generalize to higher-order tensors and correlations. Interestingly, the higher the order of the tensors, the lower the bound on the entries needs to be for an efficient algorithm. Our results thus yield a natural tradeoff between the boundedness of the entries, and order of the tensor one may use for more expressive, efficient attention computation.
Learning to Generate Parameters of ConvNets for Unseen Image Data
Oct 18, 2023Typical Convolutional Neural Networks (ConvNets) depend heavily on large amounts of image data and resort to an iterative optimization algorithm (e.g., SGD or Adam) to learn network parameters, which makes training very time- and resource-intensive. In this paper, we propose a new training paradigm and formulate the parameter learning of ConvNets into a prediction task: given a ConvNet architecture, we observe there exists correlations between image datasets and their corresponding optimal network parameters, and explore if we can learn a hyper-mapping between them to capture the relations, such that we can directly predict the parameters of the network for an image dataset never seen during the training phase. To do this, we put forward a new hypernetwork based model, called PudNet, which intends to learn a mapping between datasets and their corresponding network parameters, and then predicts parameters for unseen data with only a single forward propagation. Moreover, our model benefits from a series of adaptive hyper recurrent units sharing weights to capture the dependencies of parameters among different network layers. Extensive experiments demonstrate that our proposed method achieves good efficacy for unseen image datasets on two kinds of settings: Intra-dataset prediction and Inter-dataset prediction. Our PudNet can also well scale up to large-scale datasets, e.g., ImageNet-1K. It takes 8967 GPU seconds to train ResNet-18 on the ImageNet-1K using GC from scratch and obtain a top-5 accuracy of 44.65 %. However, our PudNet costs only 3.89 GPU seconds to predict the network parameters of ResNet-18 achieving comparable performance (44.92 %), more than 2,300 times faster than the traditional training paradigm.