 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Enhancing Prediction and Analysis of UK Road Traffic Accident Severity Using AI: Integration of Machine Learning, Econometric Techniques, and Time Series Forecasting in Public Health Research
Sep 23, 2023
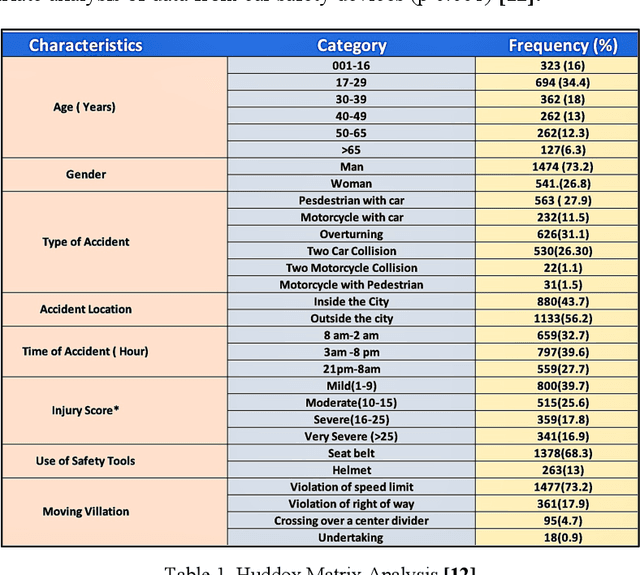
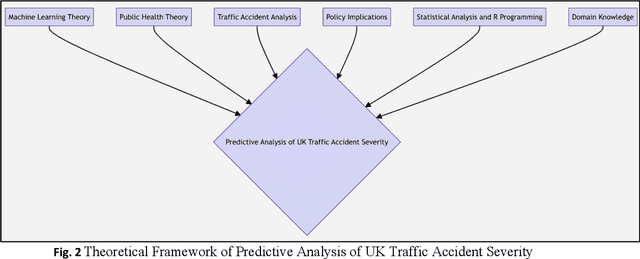
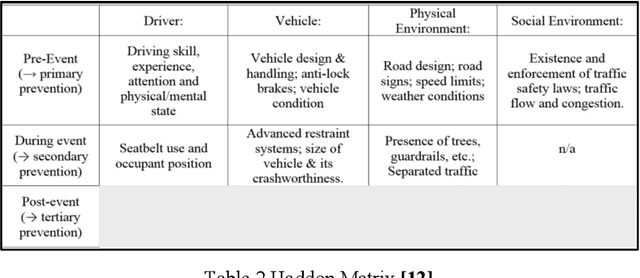
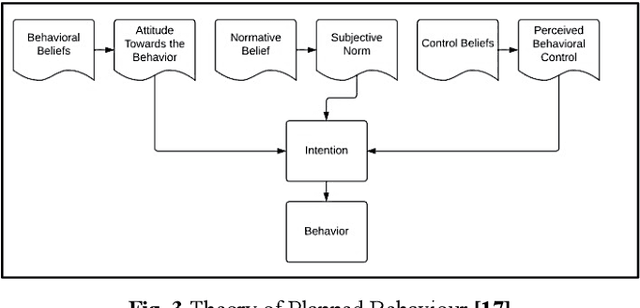
This research investigates road traffic accident severity in the UK, using a combination of machine learning, econometric, and statistical methods on historical data. We employed various techniques, including correlation analysis, regression models, GMM for error term issues, and time-series forecasting with VAR and ARIMA models. Our approach outperforms naive forecasting with an MASE of 0.800 and ME of -73.80. We also built a random forest classifier with 73% precision, 78% recall, and a 73% F1-score. Optimizing with H2O AutoML led to an XGBoost model with an RMSE of 0.176 and MAE of 0.087. Factor Analysis identified key variables, and we used SHAP for Explainable AI, highlighting influential factors like Driver_Home_Area_Type and Road_Type. Our study enhances understanding of accident severity and offers insights for evidence-based road safety policies.
Mitigate Domain Shift by Primary-Auxiliary Objectives Association for Generalizing Person ReID
Oct 24, 2023While deep learning has significantly improved ReID model accuracy under the independent and identical distribution (IID) assumption, it has also become clear that such models degrade notably when applied to an unseen novel domain due to unpredictable/unknown domain shift. Contemporary domain generalization (DG) ReID models struggle in learning domain-invariant representation solely through training on an instance classification objective. We consider that a deep learning model is heavily influenced and therefore biased towards domain-specific characteristics, e.g., background clutter, scale and viewpoint variations, limiting the generalizability of the learned model, and hypothesize that the pedestrians are domain invariant owning they share the same structural characteristics. To enable the ReID model to be less domain-specific from these pure pedestrians, we introduce a method that guides model learning of the primary ReID instance classification objective by a concurrent auxiliary learning objective on weakly labeled pedestrian saliency detection. To solve the problem of conflicting optimization criteria in the model parameter space between the two learning objectives, we introduce a Primary-Auxiliary Objectives Association (PAOA) mechanism to calibrate the loss gradients of the auxiliary task towards the primary learning task gradients. Benefiting from the harmonious multitask learning design, our model can be extended with the recent test-time diagram to form the PAOA+, which performs on-the-fly optimization against the auxiliary objective in order to maximize the model's generative capacity in the test target domain. Experiments demonstrate the superiority of the proposed PAOA model.
Neural Collapse in Multi-label Learning with Pick-all-label Loss
Oct 24, 2023We study deep neural networks for the multi-label classification (MLab) task through the lens of neural collapse (NC). Previous works have been restricted to the multi-class classification setting and discovered a prevalent NC phenomenon comprising of the following properties for the last-layer features: (i) the variability of features within every class collapses to zero, (ii) the set of feature means form an equi-angular tight frame (ETF), and (iii) the last layer classifiers collapse to the feature mean upon some scaling. We generalize the study to multi-label learning, and prove for the first time that a generalized NC phenomenon holds with the "pick-all-label'' formulation. Under the natural analog of the unconstrained feature model (UFM), we establish that the only global classifier of the pick-all-label cross entropy loss display the same ETF geometry which further collapse to multiplicity-1 feature class means. Besides, we discover a combinatorial property in generalized NC which is unique for multi-label learning that we call ``tag-wise average'' property, where the feature class-means of samples with multiple labels are scaled average of the feature class-means of single label tags. Theoretically, we establish global optimality result for the pick-all-label cross-entropy risk for the UFM. Additionally, We also provide empirical evidence to support our investigation into training deep neural networks on multi-label datasets, resulting in improved training efficiency.
Symmetry-preserving graph attention network to solve routing problems at multiple resolutions
Oct 24, 2023Travelling Salesperson Problems (TSPs) and Vehicle Routing Problems (VRPs) have achieved reasonable improvement in accuracy and computation time with the adaptation of Machine Learning (ML) methods. However, none of the previous works completely respects the symmetries arising from TSPs and VRPs including rotation, translation, permutation, and scaling. In this work, we introduce the first-ever completely equivariant model and training to solve combinatorial problems. Furthermore, it is essential to capture the multiscale structure (i.e. from local to global information) of the input graph, especially for the cases of large and long-range graphs, while previous methods are limited to extracting only local information that can lead to a local or sub-optimal solution. To tackle the above limitation, we propose a Multiresolution scheme in combination with Equivariant Graph Attention network (mEGAT) architecture, which can learn the optimal route based on low-level and high-level graph resolutions in an efficient way. In particular, our approach constructs a hierarchy of coarse-graining graphs from the input graph, in which we try to solve the routing problems on simple low-level graphs first, then utilize that knowledge for the more complex high-level graphs. Experimentally, we have shown that our model outperforms existing baselines and proved that symmetry preservation and multiresolution are important recipes for solving combinatorial problems in a data-driven manner. Our source code is publicly available at https://github.com/HySonLab/Multires-NP-hard
Solving large flexible job shop scheduling instances by generating a diverse set of scheduling policies with deep reinforcement learning
Oct 24, 2023The Flexible Job Shop Scheduling Problem (FJSSP) has been extensively studied in the literature, and multiple approaches have been proposed within the heuristic, exact, and metaheuristic methods. However, the industry's demand to be able to respond in real-time to disruptive events has generated the necessity to be able to generate new schedules within a few seconds. Among these methods, under this constraint, only dispatching rules (DRs) are capable of generating schedules, even though their quality can be improved. To improve the results, recent methods have been proposed for modeling the FJSSP as a Markov Decision Process (MDP) and employing reinforcement learning to create a policy that generates an optimal solution assigning operations to machines. Nonetheless, there is still room for improvement, particularly in the larger FJSSP instances which are common in real-world scenarios. Therefore, the objective of this paper is to propose a method capable of robustly solving large instances of the FJSSP. To achieve this, we propose a novel way of modeling the FJSSP as an MDP using graph neural networks. We also present two methods to make inference more robust: generating a diverse set of scheduling policies that can be parallelized and limiting them using DRs. We have tested our approach on synthetically generated instances and various public benchmarks and found that our approach outperforms dispatching rules and achieves better results than three other recent deep reinforcement learning methods on larger FJSSP instances.
Confounder Balancing in Adversarial Domain Adaptation for Pre-Trained Large Models Fine-Tuning
Oct 24, 2023
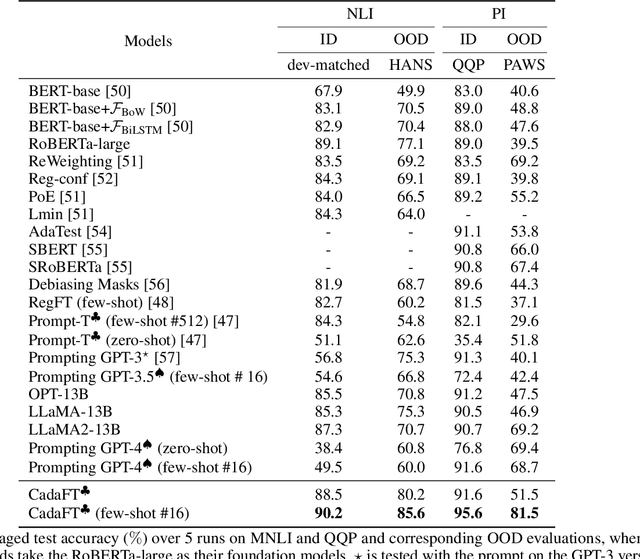

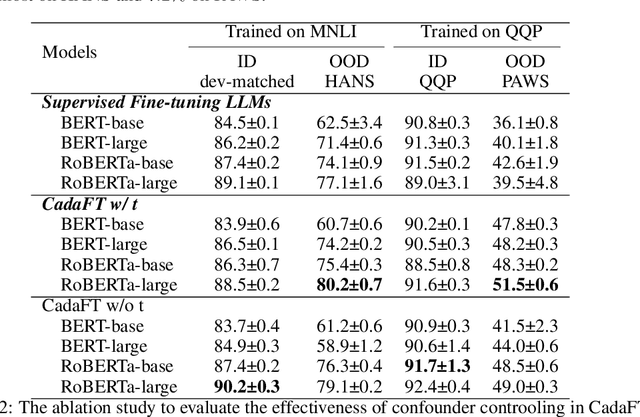
The excellent generalization, contextual learning, and emergence abilities in the pre-trained large models (PLMs) handle specific tasks without direct training data, making them the better foundation models in the adversarial domain adaptation (ADA) methods to transfer knowledge learned from the source domain to target domains. However, existing ADA methods fail to account for the confounder properly, which is the root cause of the source data distribution that differs from the target domains. This study proposes an adversarial domain adaptation with confounder balancing for PLMs fine-tuning (ADA-CBF). The ADA-CBF includes a PLM as the foundation model for a feature extractor, a domain classifier and a confounder classifier, and they are jointly trained with an adversarial loss. This loss is designed to improve the domain-invariant representation learning by diluting the discrimination in the domain classifier. At the same time, the adversarial loss also balances the confounder distribution among source and unmeasured domains in training. Compared to existing ADA methods, ADA-CBF can correctly identify confounders in domain-invariant features, thereby eliminating the confounder biases in the extracted features from PLMs. The confounder classifier in ADA-CBF is designed as a plug-and-play and can be applied in the confounder measurable, unmeasurable, or partially measurable environments. Empirical results on natural language processing and computer vision downstream tasks show that ADA-CBF outperforms the newest GPT-4, LLaMA2, ViT and ADA methods.
S4Sleep: Elucidating the design space of deep-learning-based sleep stage classification models
Oct 10, 2023Scoring sleep stages in polysomnography recordings is a time-consuming task plagued by significant inter-rater variability. Therefore, it stands to benefit from the application of machine learning algorithms. While many algorithms have been proposed for this purpose, certain critical architectural decisions have not received systematic exploration. In this study, we meticulously investigate these design choices within the broad category of encoder-predictor architectures. We identify robust architectures applicable to both time series and spectrogram input representations. These architectures incorporate structured state space models as integral components, leading to statistically significant advancements in performance on the extensive SHHS dataset. These improvements are assessed through both statistical and systematic error estimations. We anticipate that the architectural insights gained from this study will not only prove valuable for future research in sleep staging but also hold relevance for other time series annotation tasks.
A Real-Time Active Speaker Detection System Integrating an Audio-Visual Signal with a Spatial Querying Mechanism
Sep 15, 2023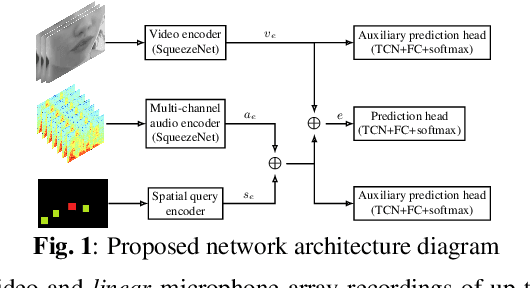


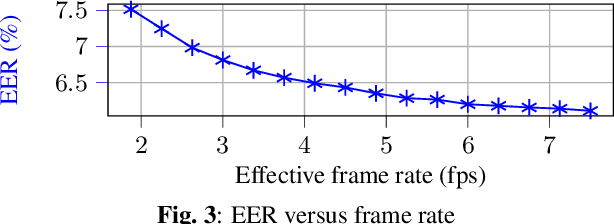
We introduce a distinctive real-time, causal, neural network-based active speaker detection system optimized for low-power edge computing. This system drives a virtual cinematography module and is deployed on a commercial device. The system uses data originating from a microphone array and a 360-degree camera. Our network requires only 127 MFLOPs per participant, for a meeting with 14 participants. Unlike previous work, we examine the error rate of our network when the computational budget is exhausted, and find that it exhibits graceful degradation, allowing the system to operate reasonably well even in this case. Departing from conventional DOA estimation approaches, our network learns to query the available acoustic data, considering the detected head locations. We train and evaluate our algorithm on a realistic meetings dataset featuring up to 14 participants in the same meeting, overlapped speech, and other challenging scenarios.
AllTogether: Investigating the Efficacy of Spliced Prompt for Web Navigation using Large Language Models
Oct 20, 2023Large Language Models (LLMs) have emerged as promising agents for web navigation tasks, interpreting objectives and interacting with web pages. However, the efficiency of spliced prompts for such tasks remains underexplored. We introduces AllTogether, a standardized prompt template that enhances task context representation, thereby improving LLMs' performance in HTML-based web navigation. We evaluate the efficacy of this approach through prompt learning and instruction finetuning based on open-source Llama-2 and API-accessible GPT models. Our results reveal that models like GPT-4 outperform smaller models in web navigation tasks. Additionally, we find that the length of HTML snippet and history trajectory significantly influence performance, and prior step-by-step instructions prove less effective than real-time environmental feedback. Overall, we believe our work provides valuable insights for future research in LLM-driven web agents.
Bridging Information-Theoretic and Geometric Compression in Language Models
Oct 20, 2023For a language model (LM) to faithfully model human language, it must compress vast, potentially infinite information into relatively few dimensions. We propose analyzing compression in (pre-trained) LMs from two points of view: geometric and information-theoretic. We demonstrate that the two views are highly correlated, such that the intrinsic geometric dimension of linguistic data predicts their coding length under the LM. We then show that, in turn, high compression of a linguistic dataset predicts rapid adaptation to that dataset, confirming that being able to compress linguistic information is an important part of successful LM performance. As a practical byproduct of our analysis, we evaluate a battery of intrinsic dimension estimators for the first time on linguistic data, showing that only some encapsulate the relationship between information-theoretic compression, geometric compression, and ease-of-adaptation.