 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Cooperative Students: Navigating Unsupervised Domain Adaptation in Nighttime Object Detection
Apr 03, 2024
Unsupervised Domain Adaptation (UDA) has shown significant advancements in object detection under well-lit conditions; however, its performance degrades notably in low-visibility scenarios, especially at night, posing challenges not only for its adaptability in low signal-to-noise ratio (SNR) conditions but also for the reliability and efficiency of automated vehicles. To address this problem, we propose a \textbf{Co}operative \textbf{S}tudents (\textbf{CoS}) framework that innovatively employs global-local transformations (GLT) and a proxy-based target consistency (PTC) mechanism to capture the spatial consistency in day- and night-time scenarios effectively, and thus bridge the significant domain shift across contexts. Building upon this, we further devise an adaptive IoU-informed thresholding (AIT) module to gradually avoid overlooking potential true positives and enrich the latent information in the target domain. Comprehensive experiments show that CoS essentially enhanced UDA performance in low-visibility conditions and surpasses current state-of-the-art techniques, achieving an increase in mAP of 3.0\%, 1.9\%, and 2.5\% on BDD100K, SHIFT, and ACDC datasets, respectively. Code is available at https://github.com/jichengyuan/Cooperitive_Students.
AddSR: Accelerating Diffusion-based Blind Super-Resolution with Adversarial Diffusion Distillation
Apr 03, 2024Blind super-resolution methods based on stable diffusion showcase formidable generative capabilities in reconstructing clear high-resolution images with intricate details from low-resolution inputs. However, their practical applicability is often hampered by poor efficiency, stemming from the requirement of thousands or hundreds of sampling steps. Inspired by the efficient text-to-image approach adversarial diffusion distillation (ADD), we design AddSR to address this issue by incorporating the ideas of both distillation and ControlNet. Specifically, we first propose a prediction-based self-refinement strategy to provide high-frequency information in the student model output with marginal additional time cost. Furthermore, we refine the training process by employing HR images, rather than LR images, to regulate the teacher model, providing a more robust constraint for distillation. Second, we introduce a timestep-adapting loss to address the perception-distortion imbalance problem introduced by ADD. Extensive experiments demonstrate our AddSR generates better restoration results, while achieving faster speed than previous SD-based state-of-the-art models (e.g., 7x faster than SeeSR).
Time Series Representation Learning with Supervised Contrastive Temporal Transformer
Mar 16, 2024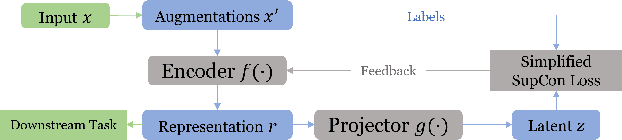
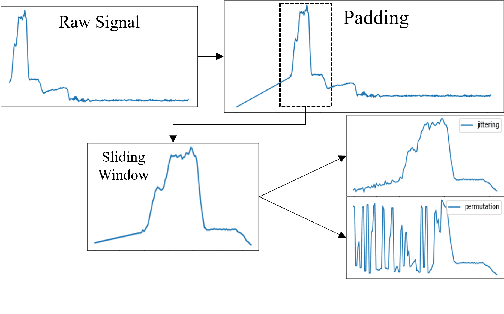
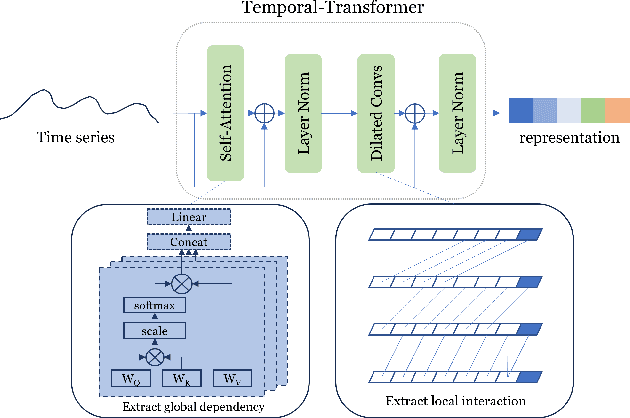
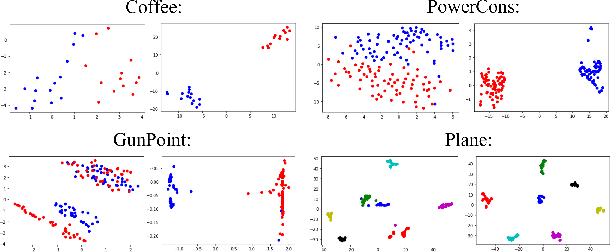
Finding effective representations for time series data is a useful but challenging task. Several works utilize self-supervised or unsupervised learning methods to address this. However, there still remains the open question of how to leverage available label information for better representations. To answer this question, we exploit pre-existing techniques in time series and representation learning domains and develop a simple, yet novel fusion model, called: \textbf{S}upervised \textbf{CO}ntrastive \textbf{T}emporal \textbf{T}ransformer (SCOTT). We first investigate suitable augmentation methods for various types of time series data to assist with learning change-invariant representations. Secondly, we combine Transformer and Temporal Convolutional Networks in a simple way to efficiently learn both global and local features. Finally, we simplify Supervised Contrastive Loss for representation learning of labelled time series data. We preliminarily evaluate SCOTT on a downstream task, Time Series Classification, using 45 datasets from the UCR archive. The results show that with the representations learnt by SCOTT, even a weak classifier can perform similar to or better than existing state-of-the-art models (best performance on 23/45 datasets and highest rank against 9 baseline models). Afterwards, we investigate SCOTT's ability to address a real-world task, online Change Point Detection (CPD), on two datasets: a human activity dataset and a surgical patient dataset. We show that the model performs with high reliability and efficiency on the online CPD problem ($\sim$98\% and $\sim$97\% area under precision-recall curve respectively). Furthermore, we demonstrate the model's potential in tackling early detection and show it performs best compared to other candidates.
To Search or to Recommend: Predicting Open-App Motivation with Neural Hawkes Process
Apr 04, 2024Incorporating Search and Recommendation (S&R) services within a singular application is prevalent in online platforms, leading to a new task termed open-app motivation prediction, which aims to predict whether users initiate the application with the specific intent of information searching, or to explore recommended content for entertainment. Studies have shown that predicting users' motivation to open an app can help to improve user engagement and enhance performance in various downstream tasks. However, accurately predicting open-app motivation is not trivial, as it is influenced by user-specific factors, search queries, clicked items, as well as their temporal occurrences. Furthermore, these activities occur sequentially and exhibit intricate temporal dependencies. Inspired by the success of the Neural Hawkes Process (NHP) in modeling temporal dependencies in sequences, this paper proposes a novel neural Hawkes process model to capture the temporal dependencies between historical user browsing and querying actions. The model, referred to as Neural Hawkes Process-based Open-App Motivation prediction model (NHP-OAM), employs a hierarchical transformer and a novel intensity function to encode multiple factors, and open-app motivation prediction layer to integrate time and user-specific information for predicting users' open-app motivations. To demonstrate the superiority of our NHP-OAM model and construct a benchmark for the Open-App Motivation Prediction task, we not only extend the public S&R dataset ZhihuRec but also construct a new real-world Open-App Motivation Dataset (OAMD). Experiments on these two datasets validate NHP-OAM's superiority over baseline models. Further downstream application experiments demonstrate NHP-OAM's effectiveness in predicting users' Open-App Motivation, highlighting the immense application value of NHP-OAM.
CBF-Based Motion Planning for Socially Responsible Robot Navigation Guaranteeing STL Specification
Mar 30, 2024In the field of control engineering, the connection between Signal Temporal Logic (STL) and time-varying Control Barrier Functions (CBF) has attracted considerable attention. CBFs have demonstrated notable success in ensuring the safety of critical applications by imposing constraints on system states, while STL allows for precisely specifying spatio-temporal constraints on the behavior of robotic systems. Leveraging these methodologies, this paper addresses the safety-critical navigation problem, in Socially Responsible Navigation (SRN) context, presenting a CBF-based STL motion planning methodology. This methodology enables task completion at any time within a specified time interval considering a dynamic system subject to velocity constraints. The proposed approach involves real-time computation of a smooth CBF, with the computation of a dynamically adjusted parameter based on the available path space and the maximum allowable velocity. A simulation study is conducted to validate the methodology, ensuring safety in the presence of static and dynamic obstacles and demonstrating its compliance with spatio-temporal constraints under non-linear velocity constraints.
Gaussian Frosting: Editable Complex Radiance Fields with Real-Time Rendering
Mar 21, 2024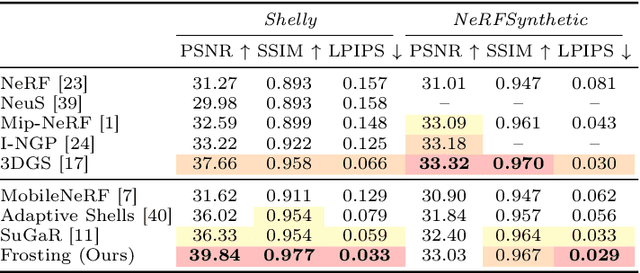
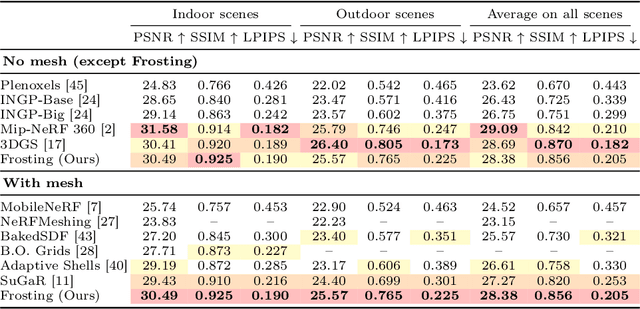
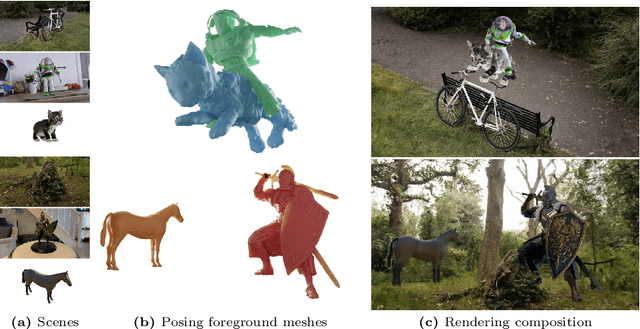
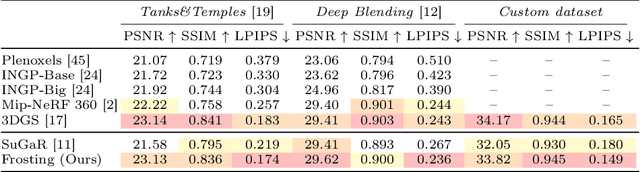
We propose Gaussian Frosting, a novel mesh-based representation for high-quality rendering and editing of complex 3D effects in real-time. Our approach builds on the recent 3D Gaussian Splatting framework, which optimizes a set of 3D Gaussians to approximate a radiance field from images. We propose first extracting a base mesh from Gaussians during optimization, then building and refining an adaptive layer of Gaussians with a variable thickness around the mesh to better capture the fine details and volumetric effects near the surface, such as hair or grass. We call this layer Gaussian Frosting, as it resembles a coating of frosting on a cake. The fuzzier the material, the thicker the frosting. We also introduce a parameterization of the Gaussians to enforce them to stay inside the frosting layer and automatically adjust their parameters when deforming, rescaling, editing or animating the mesh. Our representation allows for efficient rendering using Gaussian splatting, as well as editing and animation by modifying the base mesh. We demonstrate the effectiveness of our method on various synthetic and real scenes, and show that it outperforms existing surface-based approaches. We will release our code and a web-based viewer as additional contributions. Our project page is the following: https://anttwo.github.io/frosting/
ShadowRemovalNet: Efficient Real-Time Shadow Removal
Mar 13, 2024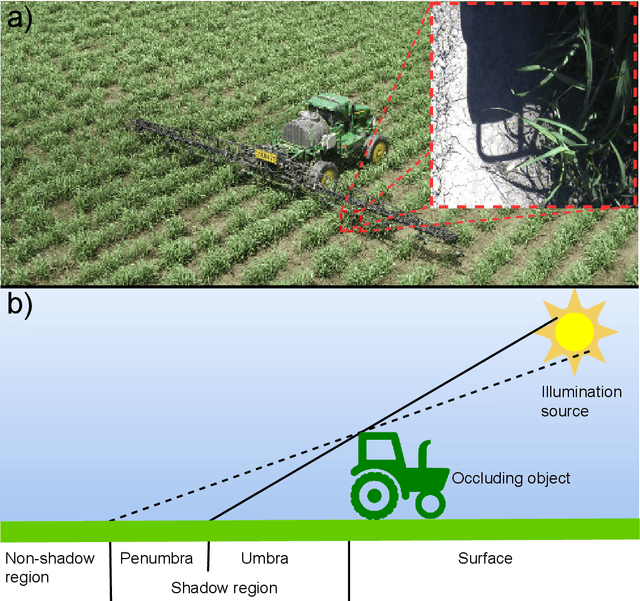
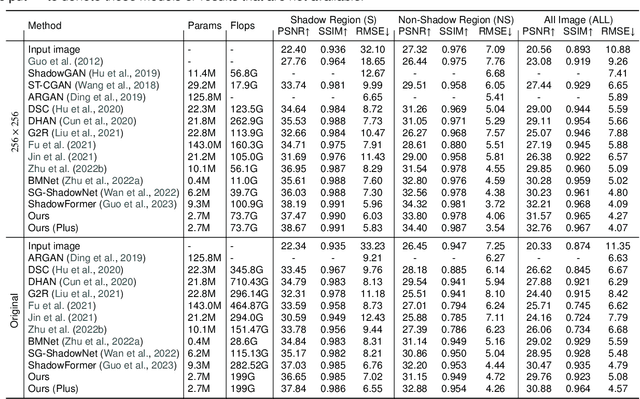
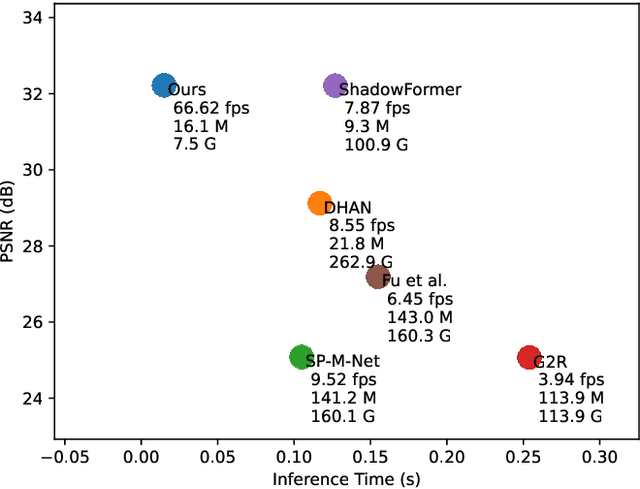
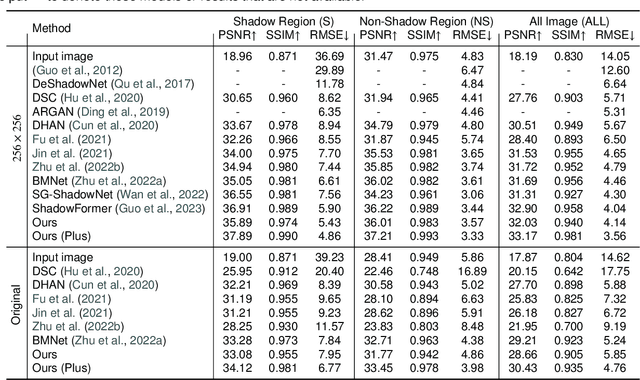
Shadows significantly impact computer vision tasks, particularly in outdoor environments. State-of-the-art shadow removal methods are typically too computationally intensive for real-time image processing on edge hardware. We propose ShadowRemovalNet, a novel method designed for real-time image processing on resource-constrained hardware. ShadowRemovalNet achieves significantly higher frame rates compared to existing methods, making it suitable for real-time computer vision pipelines like those used in field robotics. Beyond speed, ShadowRemovalNet offers advantages in efficiency and simplicity, as it does not require a separate shadow mask during inference. ShadowRemovalNet also addresses challenges associated with Generative Adversarial Networks (GANs) for shadow removal, including artefacts, inaccurate mask estimations, and inconsistent supervision between shadow and boundary pixels. To address these limitations, we introduce a novel loss function that substantially reduces shadow removal errors. ShadowRemovalNet's efficiency and straightforwardness make it a robust and effective solution for real-time shadow removal in outdoor robotics and edge computing applications.
Unified, Verifiable Neural Simulators for Electromagnetic Wave Inverse Problems
Mar 31, 2024Simulators based on neural networks offer a path to orders-of-magnitude faster electromagnetic wave simulations. Existing models, however, only address narrowly tailored classes of problems and only scale to systems of a few dozen degrees of freedom (DoFs). Here, we demonstrate a single, unified model capable of addressing scattering simulations with thousands of DoFs, of any wavelength, any illumination wavefront, and freeform materials, within broad configurable bounds. Based on an attentional multi-conditioning strategy, our method also allows non-recurrent supervision on and prediction of intermediate physical states, which provides improved generalization with no additional data-generation cost. Using this O(1)-time intermediate prediction capability, we propose and prove a rigorous, efficiently computable upper bound on prediction error, allowing accuracy guarantees at inference time for all predictions. After training solely on randomized systems, we demonstrate the unified model across a suite of challenging multi-disciplinary inverse problems, finding strong efficacy and speed improvements up to 96% for problems in optical tomography, beam shaping through volumetric random media, and freeform photonic inverse design, with no problem-specific training. Our findings demonstrate a path to universal, verifiably accurate neural surrogates for existing scattering simulators, and our conditioning and training methods are directly applicable to any PDE admitting a time-domain iterative solver.
Safe Returning FaSTrack with Robust Control Lyapunov-Value Functions
Apr 03, 2024Real-time navigation in a priori unknown environment remains a challenging task, especially when an unexpected (unmodeled) disturbance occurs. In this paper, we propose the framework Safe Returning Fast and Safe Tracking (SR-F) that merges concepts from 1) Robust Control Lyapunov-Value Functions (R-CLVF), and 2) the Fast and Safe Tracking (FaSTrack) framework. The SR-F computes an R-CLVF offline between a model of the true system and a simplified planning model. Online, a planning algorithm is used to generate a trajectory in the simplified planning space, and the R-CLVF is used to provide a tracking controller that exponentially stabilizes to the planning model. When an unexpected disturbance occurs, the proposed SR-F algorithm provides a means for the true system to recover to the planning model. We take advantage of this mechanism to induce an artificial disturbance by ``jumping'' the planning model in open environments, forcing faster navigation. Therefore, this algorithm can both reject unexpected true disturbances and accelerate navigation speed. We validate our framework using a 10D quadrotor system and show that SR-F is empirically 20\% faster than the original FaSTrack while maintaining safety.
PoCo: Point Context Cluster for RGBD Indoor Place Recognition
Apr 03, 2024We present a novel end-to-end algorithm (PoCo) for the indoor RGB-D place recognition task, aimed at identifying the most likely match for a given query frame within a reference database. The task presents inherent challenges attributed to the constrained field of view and limited range of perception sensors. We propose a new network architecture, which generalizes the recent Context of Clusters (CoCs) to extract global descriptors directly from the noisy point clouds through end-to-end learning. Moreover, we develop the architecture by integrating both color and geometric modalities into the point features to enhance the global descriptor representation. We conducted evaluations on public datasets ScanNet-PR and ARKit with 807 and 5047 scenarios, respectively. PoCo achieves SOTA performance: on ScanNet-PR, we achieve R@1 of 64.63%, a 5.7% improvement from the best-published result CGis (61.12%); on Arkit, we achieve R@1 of 45.12%, a 13.3% improvement from the best-published result CGis (39.82%). In addition, PoCo shows higher efficiency than CGis in inference time (1.75X-faster), and we demonstrate the effectiveness of PoCo in recognizing places within a real-world laboratory environment.