 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Smart City Transportation: Deep Learning Ensemble Approach for Traffic Accident Detection
Oct 16, 2023
The dynamic and unpredictable nature of road traffic necessitates effective accident detection methods for enhancing safety and streamlining traffic management in smart cities. This paper offers a comprehensive exploration study of prevailing accident detection techniques, shedding light on the nuances of other state-of-the-art methodologies while providing a detailed overview of distinct traffic accident types like rear-end collisions, T-bone collisions, and frontal impact accidents. Our novel approach introduces the I3D-CONVLSTM2D model architecture, a lightweight solution tailored explicitly for accident detection in smart city traffic surveillance systems by integrating RGB frames with optical flow information. Our experimental study's empirical analysis underscores our approach's efficacy, with the I3D-CONVLSTM2D RGB + Optical-Flow (Trainable) model outperforming its counterparts, achieving an impressive 87\% Mean Average Precision (MAP). Our findings further elaborate on the challenges posed by data imbalances, particularly when working with a limited number of datasets, road structures, and traffic scenarios. Ultimately, our research illuminates the path towards a sophisticated vision-based accident detection system primed for real-time integration into edge IoT devices within smart urban infrastructures.
A Geometric Insight into Equivariant Message Passing Neural Networks on Riemannian Manifolds
Oct 16, 2023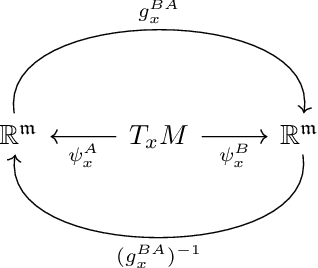
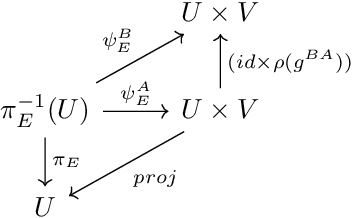
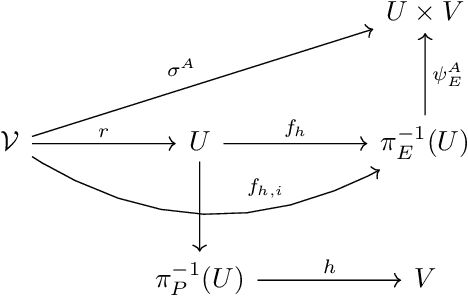
This work proposes a geometric insight into equivariant message passing on Riemannian manifolds. As previously proposed, numerical features on Riemannian manifolds are represented as coordinate-independent feature fields on the manifold. To any coordinate-independent feature field on a manifold comes attached an equivariant embedding of the principal bundle to the space of numerical features. We argue that the metric this embedding induces on the numerical feature space should optimally preserve the principal bundle's original metric. This optimality criterion leads to the minimization of a twisted form of the Polyakov action with respect to the graph of this embedding, yielding an equivariant diffusion process on the associated vector bundle. We obtain a message passing scheme on the manifold by discretizing the diffusion equation flow for a fixed time step. We propose a higher-order equivariant diffusion process equivalent to diffusion on the cartesian product of the base manifold. The discretization of the higher-order diffusion process on a graph yields a new general class of equivariant GNN, generalizing the ACE and MACE formalism to data on Riemannian manifolds.
DOMINO: Domain-invariant Hyperdimensional Classification for Multi-Sensor Time Series Data
Aug 18, 2023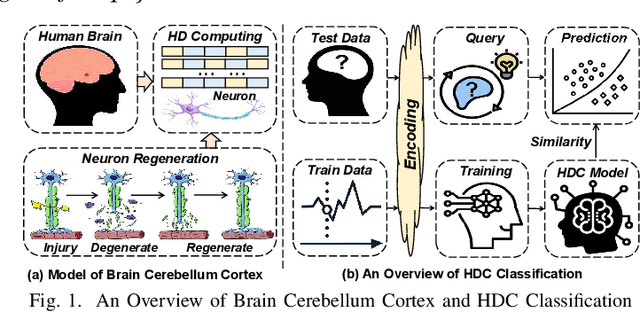
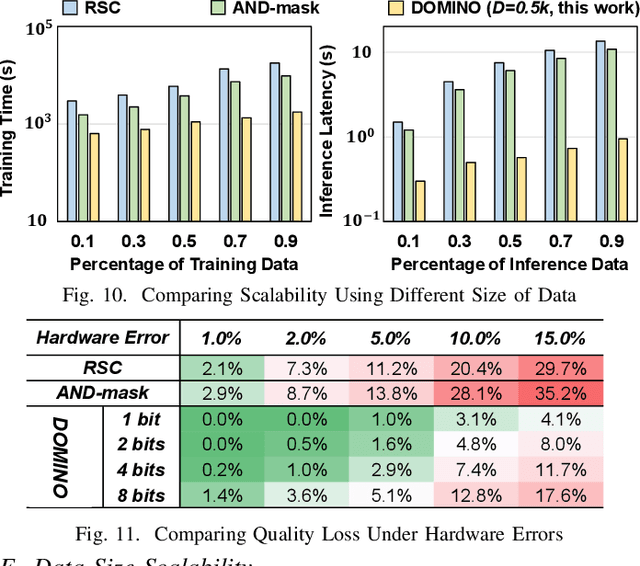
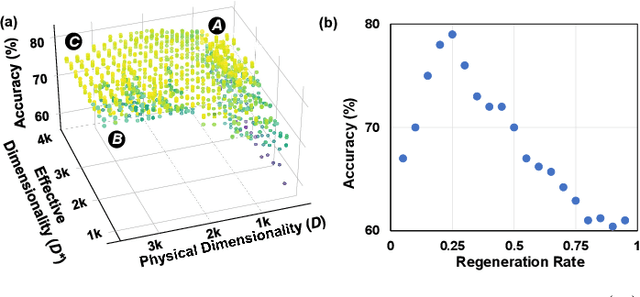
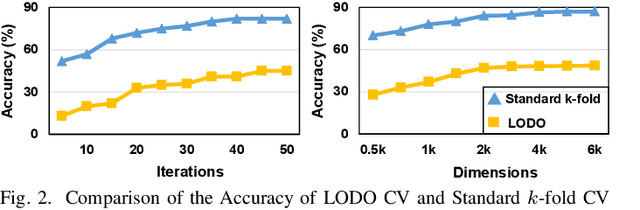
With the rapid evolution of the Internet of Things, many real-world applications utilize heterogeneously connected sensors to capture time-series information. Edge-based machine learning (ML) methodologies are often employed to analyze locally collected data. However, a fundamental issue across data-driven ML approaches is distribution shift. It occurs when a model is deployed on a data distribution different from what it was trained on, and can substantially degrade model performance. Additionally, increasingly sophisticated deep neural networks (DNNs) have been proposed to capture spatial and temporal dependencies in multi-sensor time series data, requiring intensive computational resources beyond the capacity of today's edge devices. While brain-inspired hyperdimensional computing (HDC) has been introduced as a lightweight solution for edge-based learning, existing HDCs are also vulnerable to the distribution shift challenge. In this paper, we propose DOMINO, a novel HDC learning framework addressing the distribution shift problem in noisy multi-sensor time-series data. DOMINO leverages efficient and parallel matrix operations on high-dimensional space to dynamically identify and filter out domain-variant dimensions. Our evaluation on a wide range of multi-sensor time series classification tasks shows that DOMINO achieves on average 2.04% higher accuracy than state-of-the-art (SOTA) DNN-based domain generalization techniques, and delivers 16.34x faster training and 2.89x faster inference. More importantly, DOMINO performs notably better when learning from partially labeled and highly imbalanced data, providing 10.93x higher robustness against hardware noises than SOTA DNNs.
GRU-D-Weibull: A Novel Real-Time Individualized Endpoint Prediction
Aug 14, 2023Accurate prediction models for individual-level endpoints and time-to-endpoints are crucial in clinical practice. In this study, we propose a novel approach, GRU-D-Weibull, which combines gated recurrent units with decay (GRU-D) to model the Weibull distribution. Our method enables real-time individualized endpoint prediction and population-level risk management. Using a cohort of 6,879 patients with stage 4 chronic kidney disease (CKD4), we evaluated the performance of GRU-D-Weibull in endpoint prediction. The C-index of GRU-D-Weibull was ~0.7 at the index date and increased to ~0.77 after 4.3 years of follow-up, similar to random survival forest. Our approach achieved an absolute L1-loss of ~1.1 years (SD 0.95) at the CKD4 index date and a minimum of ~0.45 years (SD0.3) at 4 years of follow-up, outperforming competing methods significantly. GRU-D-Weibull consistently constrained the predicted survival probability at the time of an event within a smaller and more fixed range compared to other models throughout the follow-up period. We observed significant correlations between the error in point estimates and missing proportions of input features at the index date (correlations from ~0.1 to ~0.3), which diminished within 1 year as more data became available. By post-training recalibration, we successfully aligned the predicted and observed survival probabilities across multiple prediction horizons at different time points during follow-up. Our findings demonstrate the considerable potential of GRU-D-Weibull as the next-generation architecture for endpoint risk management, capable of generating various endpoint estimates for real-time monitoring using clinical data.
Establishing Trustworthiness: Rethinking Tasks and Model Evaluation
Oct 09, 2023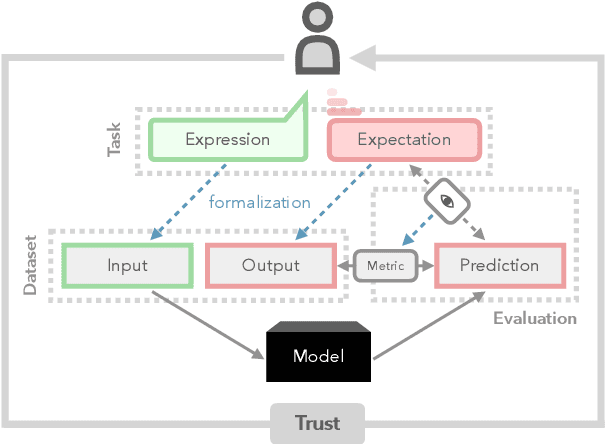
Language understanding is a multi-faceted cognitive capability, which the Natural Language Processing (NLP) community has striven to model computationally for decades. Traditionally, facets of linguistic intelligence have been compartmentalized into tasks with specialized model architectures and corresponding evaluation protocols. With the advent of large language models (LLMs) the community has witnessed a dramatic shift towards general purpose, task-agnostic approaches powered by generative models. As a consequence, the traditional compartmentalized notion of language tasks is breaking down, followed by an increasing challenge for evaluation and analysis. At the same time, LLMs are being deployed in more real-world scenarios, including previously unforeseen zero-shot setups, increasing the need for trustworthy and reliable systems. Therefore, we argue that it is time to rethink what constitutes tasks and model evaluation in NLP, and pursue a more holistic view on language, placing trustworthiness at the center. Towards this goal, we review existing compartmentalized approaches for understanding the origins of a model's functional capacity, and provide recommendations for more multi-faceted evaluation protocols.
Automatic Integration for Spatiotemporal Neural Point Processes
Oct 09, 2023Learning continuous-time point processes is essential to many discrete event forecasting tasks. However, integration poses a major challenge, particularly for spatiotemporal point processes (STPPs), as it involves calculating the likelihood through triple integrals over space and time. Existing methods for integrating STPP either assume a parametric form of the intensity function, which lacks flexibility; or approximating the intensity with Monte Carlo sampling, which introduces numerical errors. Recent work by Omi et al. [2019] proposes a dual network or AutoInt approach for efficient integration of flexible intensity function. However, the method only focuses on the 1D temporal point process. In this paper, we introduce a novel paradigm: AutoSTPP (Automatic Integration for Spatiotemporal Neural Point Processes) that extends the AutoInt approach to 3D STPP. We show that direct extension of the previous work overly constrains the intensity function, leading to poor performance. We prove consistency of AutoSTPP and validate it on synthetic data and benchmark real world datasets, showcasing its significant advantage in recovering complex intensity functions from irregular spatiotemporal events, particularly when the intensity is sharply localized.
Lion Secretly Solves Constrained Optimization: As Lyapunov Predicts
Oct 12, 2023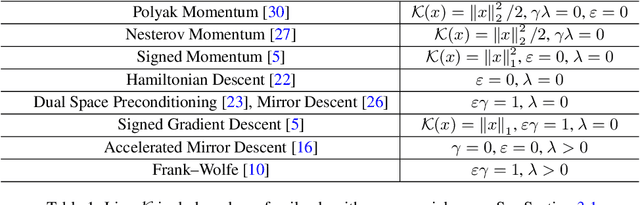
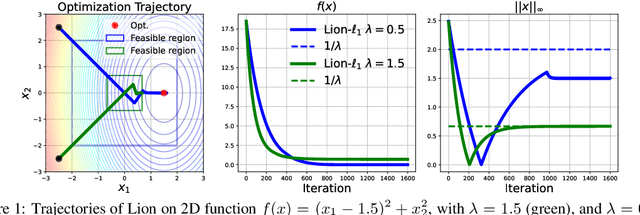


Lion (Evolved Sign Momentum), a new optimizer discovered through program search, has shown promising results in training large AI models. It performs comparably or favorably to AdamW but with greater memory efficiency. As we can expect from the results of a random search program, Lion incorporates elements from several existing algorithms, including signed momentum, decoupled weight decay, Polak, and Nesterov momentum, but does not fit into any existing category of theoretically grounded optimizers. Thus, even though Lion appears to perform well as a general-purpose optimizer for a wide range of tasks, its theoretical basis remains uncertain. This lack of theoretical clarity limits opportunities to further enhance and expand Lion's efficacy. This work aims to demystify Lion. Based on both continuous-time and discrete-time analysis, we demonstrate that Lion is a theoretically novel and principled approach for minimizing a general loss function $f(x)$ while enforcing a bound constraint $\|x\|_\infty \leq 1/\lambda$. Lion achieves this through the incorporation of decoupled weight decay, where $\lambda$ represents the weight decay coefficient. Our analysis is made possible by the development of a new Lyapunov function for the Lion updates. It applies to a broader family of Lion-$\kappa$ algorithms, where the $\text{sign}(\cdot)$ operator in Lion is replaced by the subgradient of a convex function $\kappa$, leading to the solution of a general composite optimization problem of $\min_x f(x) + \kappa^*(x)$. Our findings provide valuable insights into the dynamics of Lion and pave the way for further improvements and extensions of Lion-related algorithms.
A Fast Optimization View: Reformulating Single Layer Attention in LLM Based on Tensor and SVM Trick, and Solving It in Matrix Multiplication Time
Sep 14, 2023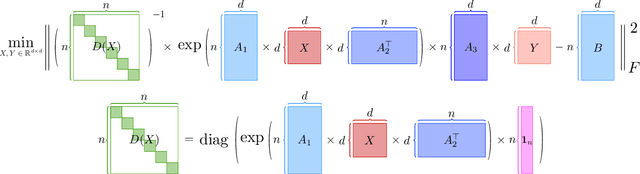

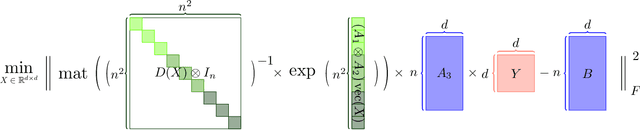
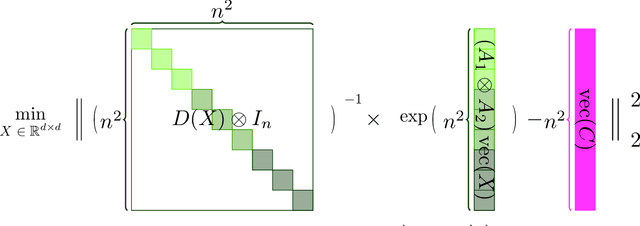
Large language models (LLMs) have played a pivotal role in revolutionizing various facets of our daily existence. Solving attention regression is a fundamental task in optimizing LLMs. In this work, we focus on giving a provable guarantee for the one-layer attention network objective function $L(X,Y) = \sum_{j_0 = 1}^n \sum_{i_0 = 1}^d ( \langle \langle \exp( \mathsf{A}_{j_0} x ) , {\bf 1}_n \rangle^{-1} \exp( \mathsf{A}_{j_0} x ), A_{3} Y_{*,i_0} \rangle - b_{j_0,i_0} )^2$. Here $\mathsf{A} \in \mathbb{R}^{n^2 \times d^2}$ is Kronecker product between $A_1 \in \mathbb{R}^{n \times d}$ and $A_2 \in \mathbb{R}^{n \times d}$. $A_3$ is a matrix in $\mathbb{R}^{n \times d}$, $\mathsf{A}_{j_0} \in \mathbb{R}^{n \times d^2}$ is the $j_0$-th block of $\mathsf{A}$. The $X, Y \in \mathbb{R}^{d \times d}$ are variables we want to learn. $B \in \mathbb{R}^{n \times d}$ and $b_{j_0,i_0} \in \mathbb{R}$ is one entry at $j_0$-th row and $i_0$-th column of $B$, $Y_{*,i_0} \in \mathbb{R}^d$ is the $i_0$-column vector of $Y$, and $x \in \mathbb{R}^{d^2}$ is the vectorization of $X$. In a multi-layer LLM network, the matrix $B \in \mathbb{R}^{n \times d}$ can be viewed as the output of a layer, and $A_1= A_2 = A_3 \in \mathbb{R}^{n \times d}$ can be viewed as the input of a layer. The matrix version of $x$ can be viewed as $QK^\top$ and $Y$ can be viewed as $V$. We provide an iterative greedy algorithm to train loss function $L(X,Y)$ up $\epsilon$ that runs in $\widetilde{O}( ({\cal T}_{\mathrm{mat}}(n,n,d) + {\cal T}_{\mathrm{mat}}(n,d,d) + d^{2\omega}) \log(1/\epsilon) )$ time. Here ${\cal T}_{\mathrm{mat}}(a,b,c)$ denotes the time of multiplying $a \times b$ matrix another $b \times c$ matrix, and $\omega\approx 2.37$ denotes the exponent of matrix multiplication.
LL-VQ-VAE: Learnable Lattice Vector-Quantization For Efficient Representations
Oct 13, 2023In this paper we introduce learnable lattice vector quantization and demonstrate its effectiveness for learning discrete representations. Our method, termed LL-VQ-VAE, replaces the vector quantization layer in VQ-VAE with lattice-based discretization. The learnable lattice imposes a structure over all discrete embeddings, acting as a deterrent against codebook collapse, leading to high codebook utilization. Compared to VQ-VAE, our method obtains lower reconstruction errors under the same training conditions, trains in a fraction of the time, and with a constant number of parameters (equal to the embedding dimension $D$), making it a very scalable approach. We demonstrate these results on the FFHQ-1024 dataset and include FashionMNIST and Celeb-A.
DentiBot: System Design and 6-DoF Hybrid Position/Force Control for Robot-Assisted Endodontic Treatment
Oct 15, 2023Robotic technologies are becoming increasingly popular in dentistry due to the high level of precision required in delicate dental procedures. Most dental robots available today are designed for implant surgery, helping dentists to accurately place implants in the desired position and depth. In this paper, we introduce the DentiBot, the first robot specifically designed for dental endodontic treatment. The DentiBot is equipped with a force and torque sensor, as well as a string-based Patient Tracking Module, allowing for real-time monitoring of endodontic file contact and patient movement. We propose a 6-DoF hybrid position/force controller that enables autonomous adjustment of the surgical path and compensation for patient movement, while also providing protection against endodontic file fracture. In addition, a file flexibility model is incorporated to compensate for file bending. Pre-clinical evaluations performed on acrylic root canal models and resin teeth confirm the feasibility of the DentiBot in assisting endodontic treatment.