 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Guarantees for Self-Play in Multiplayer Games via Polymatrix Decomposability
Oct 17, 2023
Self-play is a technique for machine learning in multi-agent systems where a learning algorithm learns by interacting with copies of itself. Self-play is useful for generating large quantities of data for learning, but has the drawback that the agents the learner will face post-training may have dramatically different behavior than the learner came to expect by interacting with itself. For the special case of two-player constant-sum games, self-play that reaches Nash equilibrium is guaranteed to produce strategies that perform well against any post-training opponent; however, no such guarantee exists for multi-player games. We show that in games that approximately decompose into a set of two-player constant-sum games (called polymatrix games) where global $\epsilon$-Nash equilibria are boundedly far from Nash-equilibria in each subgame, any no-external-regret algorithm that learns by self-play will produce a strategy with bounded vulnerability. For the first time, our results identify a structural property of multi-player games that enable performance guarantees for the strategies produced by a broad class of self-play algorithms. We demonstrate our findings through experiments on Leduc poker.
Implementation of Fuzzy Control Algorithm in Two-Wheeled Differential Drive Platform
Oct 11, 2023Designing and developing Artificial Intelligence controllers on separately dedicated chips have many advantages. This report reviews the development of a real-time fuzzy logic controller for optimizing locomotion control of a two-wheeled differential drive platform using an Arduino Uno board. Based on the Raspberry Pi board, fuzzy sets are used to optimize color recognition, enabling the color sensor to correctly recognize color at long distances, across a wide range of light intensity, and with high fault tolerance.
Learning Stackable and Skippable LEGO Bricks for Efficient, Reconfigurable, and Variable-Resolution Diffusion Modeling
Oct 10, 2023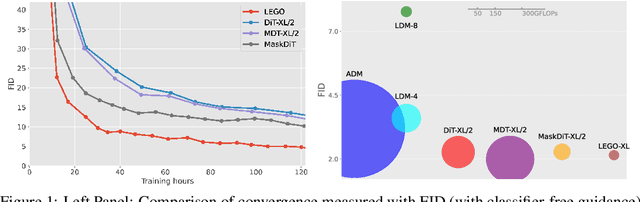


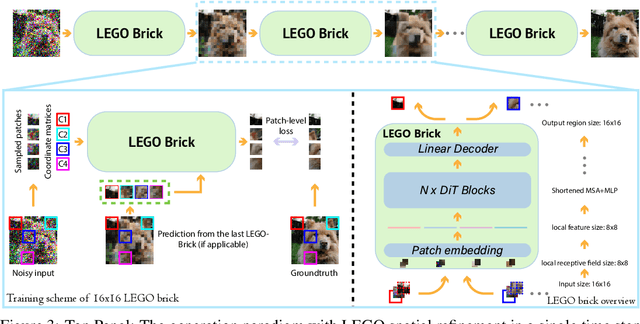
Diffusion models excel at generating photo-realistic images but come with significant computational costs in both training and sampling. While various techniques address these computational challenges, a less-explored issue is designing an efficient and adaptable network backbone for iterative refinement. Current options like U-Net and Vision Transformer often rely on resource-intensive deep networks and lack the flexibility needed for generating images at variable resolutions or with a smaller network than used in training. This study introduces LEGO bricks, which seamlessly integrate Local-feature Enrichment and Global-content Orchestration. These bricks can be stacked to create a test-time reconfigurable diffusion backbone, allowing selective skipping of bricks to reduce sampling costs and generate higher-resolution images than the training data. LEGO bricks enrich local regions with an MLP and transform them using a Transformer block while maintaining a consistent full-resolution image across all bricks. Experimental results demonstrate that LEGO bricks enhance training efficiency, expedite convergence, and facilitate variable-resolution image generation while maintaining strong generative performance. Moreover, LEGO significantly reduces sampling time compared to other methods, establishing it as a valuable enhancement for diffusion models.
Hieros: Hierarchical Imagination on Structured State Space Sequence World Models
Oct 10, 2023One of the biggest challenges to modern deep reinforcement learning (DRL) algorithms is sample efficiency. Many approaches learn a world model in order to train an agent entirely in imagination, eliminating the need for direct environment interaction during training. However, these methods often suffer from either a lack of imagination accuracy, exploration capabilities, or runtime efficiency. We propose Hieros, a hierarchical policy that learns time abstracted world representations and imagines trajectories at multiple time scales in latent space. Hieros uses an S5 layer-based world model, which predicts next world states in parallel during training and iteratively during environment interaction. Due to the special properties of S5 layers, our method can train in parallel and predict next world states iteratively during imagination. This allows for more efficient training than RNN-based world models and more efficient imagination than Transformer-based world models. We show that our approach outperforms the state of the art in terms of mean and median normalized human score on the Atari 100k benchmark, and that our proposed world model is able to predict complex dynamics very accurately. We also show that Hieros displays superior exploration capabilities compared to existing approaches.
A Dual-Stream Neural Network Explains the Functional Segregation of Dorsal and Ventral Visual Pathways in Human Brains
Oct 20, 2023The human visual system uses two parallel pathways for spatial processing and object recognition. In contrast, computer vision systems tend to use a single feedforward pathway, rendering them less robust, adaptive, or efficient than human vision. To bridge this gap, we developed a dual-stream vision model inspired by the human eyes and brain. At the input level, the model samples two complementary visual patterns to mimic how the human eyes use magnocellular and parvocellular retinal ganglion cells to separate retinal inputs to the brain. At the backend, the model processes the separate input patterns through two branches of convolutional neural networks (CNN) to mimic how the human brain uses the dorsal and ventral cortical pathways for parallel visual processing. The first branch (WhereCNN) samples a global view to learn spatial attention and control eye movements. The second branch (WhatCNN) samples a local view to represent the object around the fixation. Over time, the two branches interact recurrently to build a scene representation from moving fixations. We compared this model with the human brains processing the same movie and evaluated their functional alignment by linear transformation. The WhereCNN and WhatCNN branches were found to differentially match the dorsal and ventral pathways of the visual cortex, respectively, primarily due to their different learning objectives. These model-based results lead us to speculate that the distinct responses and representations of the ventral and dorsal streams are more influenced by their distinct goals in visual attention and object recognition than by their specific bias or selectivity in retinal inputs. This dual-stream model takes a further step in brain-inspired computer vision, enabling parallel neural networks to actively explore and understand the visual surroundings.
Identification of Abnormality in Maize Plants From UAV Images Using Deep Learning Approaches
Oct 20, 2023Early identification of abnormalities in plants is an important task for ensuring proper growth and achieving high yields from crops. Precision agriculture can significantly benefit from modern computer vision tools to make farming strategies addressing these issues efficient and effective. As farming lands are typically quite large, farmers have to manually check vast areas to determine the status of the plants and apply proper treatments. In this work, we consider the problem of automatically identifying abnormal regions in maize plants from images captured by a UAV. Using deep learning techniques, we have developed a methodology which can detect different levels of abnormality (i.e., low, medium, high or no abnormality) in maize plants independently of their growth stage. The primary goal is to identify anomalies at the earliest possible stage in order to maximize the effectiveness of potential treatments. At the same time, the proposed system can provide valuable information to human annotators for ground truth data collection by helping them to focus their attention on a much smaller set of images only. We have experimented with two different but complimentary approaches, the first considering abnormality detection as a classification problem and the second considering it as a regression problem. Both approaches can be generalized to different types of abnormalities and do not make any assumption about the abnormality occurring at an early plant growth stage which might be easier to detect due to the plants being smaller and easier to separate. As a case study, we have considered a publicly available data set which exhibits mostly Nitrogen deficiency in maize plants of various growth stages. We are reporting promising preliminary results with an 88.89\% detection accuracy of low abnormality and 100\% detection accuracy of no abnormality.
The Expressive Power of Transformers with Chain of Thought
Oct 18, 2023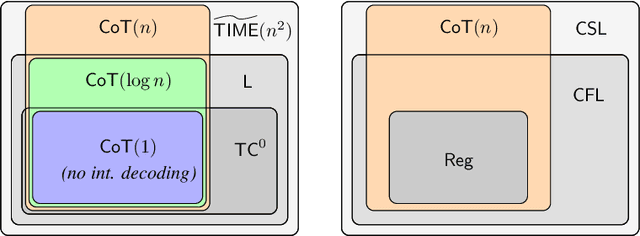
Recent theoretical work has identified surprisingly simple reasoning problems, such as checking if two nodes in a graph are connected or simulating finite-state machines, that are provably unsolvable by standard transformers that answer immediately after reading their input. However, in practice, transformers' reasoning can be improved by allowing them to use a "chain of thought" or "scratchpad", i.e., generate and condition on a sequence of intermediate tokens before answering. Motivated by this, we ask: Does such intermediate generation fundamentally extend the computational power of a decoder-only transformer? We show that the answer is yes, but the amount of increase depends crucially on the amount of intermediate generation. For instance, we find that transformer decoders with a logarithmic number of decoding steps (w.r.t. the input length) push the limits of standard transformers only slightly, while a linear number of decoding steps adds a clear new ability (under standard complexity conjectures): recognizing all regular languages. Our results also imply that linear steps keep transformer decoders within context-sensitive languages, and polynomial steps make them recognize exactly the class of polynomial-time solvable problems -- the first exact characterization of a type of transformers in terms of standard complexity classes. Together, our results provide a nuanced framework for understanding how the length of a transformer's chain of thought or scratchpad impacts its reasoning power.
DCRNN: A Deep Cross approach based on RNN for Partial Parameter Sharing in Multi-task Learning
Oct 18, 2023In recent years, DL has developed rapidly, and personalized services are exploring using DL algorithms to improve the performance of the recommendation system. For personalized services, a successful recommendation consists of two parts: attracting users to click the item and users being willing to consume the item. If both tasks need to be predicted at the same time, traditional recommendation systems generally train two independent models. This approach is cumbersome and does not effectively model the relationship between the two subtasks of "click-consumption". Therefore, in order to improve the success rate of recommendation and reduce computational costs, researchers are trying to model multi-task learning. At present, existing multi-task learning models generally adopt hard parameter sharing or soft parameter sharing architecture, but these two architectures each have certain problems. Therefore, in this work, we propose a novel recommendation model based on real recommendation scenarios, Deep Cross network based on RNN for partial parameter sharing (DCRNN). The model has three innovations: 1) It adopts the idea of cross network and uses RNN network to cross-process the features, thereby effectively improves the expressive ability of the model; 2) It innovatively proposes the structure of partial parameter sharing; 3) It can effectively capture the potential correlation between different tasks to optimize the efficiency and methods for learning different tasks.
REVAMP: Automated Simulations of Adversarial Attacks on Arbitrary Objects in Realistic Scenes
Oct 18, 2023Deep Learning models, such as those used in an autonomous vehicle are vulnerable to adversarial attacks where an attacker could place an adversarial object in the environment, leading to mis-classification. Generating these adversarial objects in the digital space has been extensively studied, however successfully transferring these attacks from the digital realm to the physical realm has proven challenging when controlling for real-world environmental factors. In response to these limitations, we introduce REVAMP, an easy-to-use Python library that is the first-of-its-kind tool for creating attack scenarios with arbitrary objects and simulating realistic environmental factors, lighting, reflection, and refraction. REVAMP enables researchers and practitioners to swiftly explore various scenarios within the digital realm by offering a wide range of configurable options for designing experiments and using differentiable rendering to reproduce physically plausible adversarial objects. We will demonstrate and invite the audience to try REVAMP to produce an adversarial texture on a chosen object while having control over various scene parameters. The audience will choose a scene, an object to attack, the desired attack class, and the number of camera positions to use. Then, in real time, we show how this altered texture causes the chosen object to be mis-classified, showcasing the potential of REVAMP in real-world scenarios. REVAMP is open-source and available at https://github.com/poloclub/revamp.
HyperBandit: Contextual Bandit with Hypernewtork for Time-Varying User Preferences in Streaming Recommendation
Aug 14, 2023
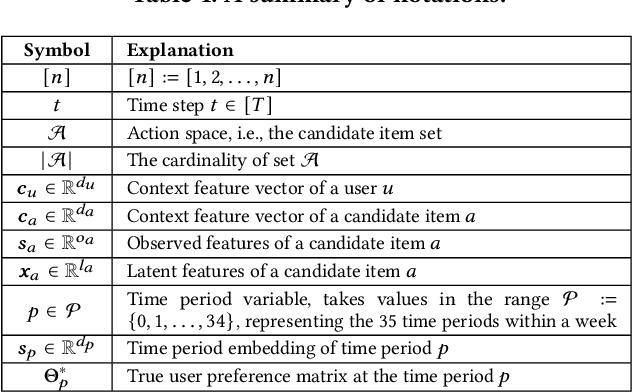
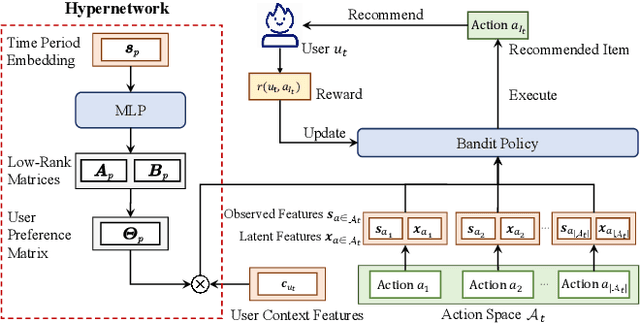
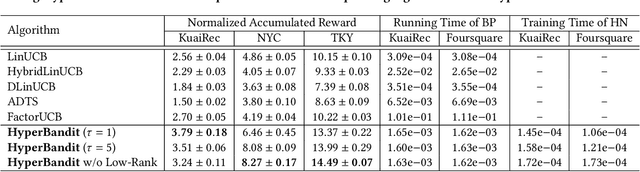
In real-world streaming recommender systems, user preferences often dynamically change over time (e.g., a user may have different preferences during weekdays and weekends). Existing bandit-based streaming recommendation models only consider time as a timestamp, without explicitly modeling the relationship between time variables and time-varying user preferences. This leads to recommendation models that cannot quickly adapt to dynamic scenarios. To address this issue, we propose a contextual bandit approach using hypernetwork, called HyperBandit, which takes time features as input and dynamically adjusts the recommendation model for time-varying user preferences. Specifically, HyperBandit maintains a neural network capable of generating the parameters for estimating time-varying rewards, taking into account the correlation between time features and user preferences. Using the estimated time-varying rewards, a bandit policy is employed to make online recommendations by learning the latent item contexts. To meet the real-time requirements in streaming recommendation scenarios, we have verified the existence of a low-rank structure in the parameter matrix and utilize low-rank factorization for efficient training. Theoretically, we demonstrate a sublinear regret upper bound against the best policy. Extensive experiments on real-world datasets show that the proposed HyperBandit consistently outperforms the state-of-the-art baselines in terms of accumulated rewards.