 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Key Point-based Orientation Estimation of Strawberries for Robotic Fruit Picking
Oct 17, 2023
Selective robotic harvesting is a promising technological solution to address labour shortages which are affecting modern agriculture in many parts of the world. For an accurate and efficient picking process, a robotic harvester requires the precise location and orientation of the fruit to effectively plan the trajectory of the end effector. The current methods for estimating fruit orientation employ either complete 3D information which typically requires registration from multiple views or rely on fully-supervised learning techniques, which require difficult-to-obtain manual annotation of the reference orientation. In this paper, we introduce a novel key-point-based fruit orientation estimation method allowing for the prediction of 3D orientation from 2D images directly. The proposed technique can work without full 3D orientation annotations but can also exploit such information for improved accuracy. We evaluate our work on two separate datasets of strawberry images obtained from real-world data collection scenarios. Our proposed method achieves state-of-the-art performance with an average error as low as $8^{\circ}$, improving predictions by $\sim30\%$ compared to previous work presented in~\cite{wagner2021efficient}. Furthermore, our method is suited for real-time robotic applications with fast inference times of $\sim30$ms.
Leveraging Large Language Model for Automatic Evolving of Industrial Data-Centric R&D Cycle
Oct 17, 2023In the wake of relentless digital transformation, data-driven solutions are emerging as powerful tools to address multifarious industrial tasks such as forecasting, anomaly detection, planning, and even complex decision-making. Although data-centric R&D has been pivotal in harnessing these solutions, it often comes with significant costs in terms of human, computational, and time resources. This paper delves into the potential of large language models (LLMs) to expedite the evolution cycle of data-centric R&D. Assessing the foundational elements of data-centric R&D, including heterogeneous task-related data, multi-facet domain knowledge, and diverse computing-functional tools, we explore how well LLMs can understand domain-specific requirements, generate professional ideas, utilize domain-specific tools to conduct experiments, interpret results, and incorporate knowledge from past endeavors to tackle new challenges. We take quantitative investment research as a typical example of industrial data-centric R&D scenario and verified our proposed framework upon our full-stack open-sourced quantitative research platform Qlib and obtained promising results which shed light on our vision of automatic evolving of industrial data-centric R&D cycle.
Innovative Methods for Non-Destructive Inspection of Handwritten Documents
Oct 17, 2023Handwritten document analysis is an area of forensic science, with the goal of establishing authorship of documents through examination of inherent characteristics. Law enforcement agencies use standard protocols based on manual processing of handwritten documents. This method is time-consuming, is often subjective in its evaluation, and is not replicable. To overcome these limitations, in this paper we present a framework capable of extracting and analyzing intrinsic measures of manuscript documents related to text line heights, space between words, and character sizes using image processing and deep learning techniques. The final feature vector for each document involved consists of the mean and standard deviation for every type of measure collected. By quantifying the Euclidean distance between the feature vectors of the documents to be compared, authorship can be discerned. We also proposed a new and challenging dataset consisting of 362 handwritten manuscripts written on paper and digital devices by 124 different people. Our study pioneered the comparison between traditionally handwritten documents and those produced with digital tools (e.g., tablets). Experimental results demonstrate the ability of our method to objectively determine authorship in different writing media, outperforming the state of the art.
Guarantees for Self-Play in Multiplayer Games via Polymatrix Decomposability
Oct 17, 2023Self-play is a technique for machine learning in multi-agent systems where a learning algorithm learns by interacting with copies of itself. Self-play is useful for generating large quantities of data for learning, but has the drawback that the agents the learner will face post-training may have dramatically different behavior than the learner came to expect by interacting with itself. For the special case of two-player constant-sum games, self-play that reaches Nash equilibrium is guaranteed to produce strategies that perform well against any post-training opponent; however, no such guarantee exists for multi-player games. We show that in games that approximately decompose into a set of two-player constant-sum games (called polymatrix games) where global $\epsilon$-Nash equilibria are boundedly far from Nash-equilibria in each subgame, any no-external-regret algorithm that learns by self-play will produce a strategy with bounded vulnerability. For the first time, our results identify a structural property of multi-player games that enable performance guarantees for the strategies produced by a broad class of self-play algorithms. We demonstrate our findings through experiments on Leduc poker.
A Modified EXP3 and Its Adaptive Variant in Adversarial Bandits with Multi-User Delayed Feedback
Oct 17, 2023For the adversarial multi-armed bandit problem with delayed feedback, we consider that the delayed feedback results are from multiple users and are unrestricted on internal distribution. As the player picks an arm, feedback from multiple users may not be received instantly yet after an arbitrary delay of time which is unknown to the player in advance. For different users in a round, the delays in feedback have no latent correlation. Thus, we formulate an adversarial multi-armed bandit problem with multi-user delayed feedback and design a modified EXP3 algorithm named MUD-EXP3, which makes a decision at each round by considering the importance-weighted estimator of the received feedback from different users. On the premise of known terminal round index $T$, the number of users $M$, the number of arms $N$, and upper bound of delay $d_{max}$, we prove a regret of $\mathcal{O}(\sqrt{TM^2\ln{N}(N\mathrm{e}+4d_{max})})$. Furthermore, for the more common case of unknown $T$, an adaptive algorithm named AMUD-EXP3 is proposed with a sublinear regret with respect to $T$. Finally, extensive experiments are conducted to indicate the correctness and effectiveness of our algorithms.
Tree-Planner: Efficient Close-loop Task Planning with Large Language Models
Oct 12, 2023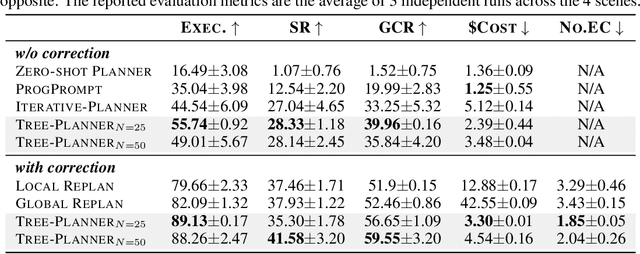
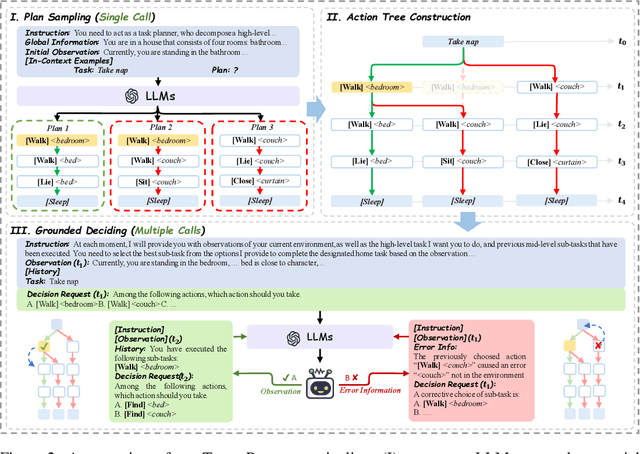
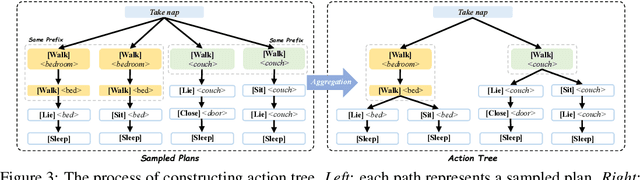

This paper studies close-loop task planning, which refers to the process of generating a sequence of skills (a plan) to accomplish a specific goal while adapting the plan based on real-time observations. Recently, prompting Large Language Models (LLMs) to generate actions iteratively has become a prevalent paradigm due to its superior performance and user-friendliness. However, this paradigm is plagued by two inefficiencies: high token consumption and redundant error correction, both of which hinder its scalability for large-scale testing and applications. To address these issues, we propose Tree-Planner, which reframes task planning with LLMs into three distinct phases: plan sampling, action tree construction, and grounded deciding. Tree-Planner starts by using an LLM to sample a set of potential plans before execution, followed by the aggregation of them to form an action tree. Finally, the LLM performs a top-down decision-making process on the tree, taking into account real-time environmental information. Experiments show that Tree-Planner achieves state-of-the-art performance while maintaining high efficiency. By decomposing LLM queries into a single plan-sampling call and multiple grounded-deciding calls, a considerable part of the prompt are less likely to be repeatedly consumed. As a result, token consumption is reduced by 92.2% compared to the previously best-performing model. Additionally, by enabling backtracking on the action tree as needed, the correction process becomes more flexible, leading to a 40.5% decrease in error corrections. Project page: https://tree-planner.github.io/
Illumination strategies for space-bandwidth-time product improvement in Fourier ptychography
Aug 26, 2023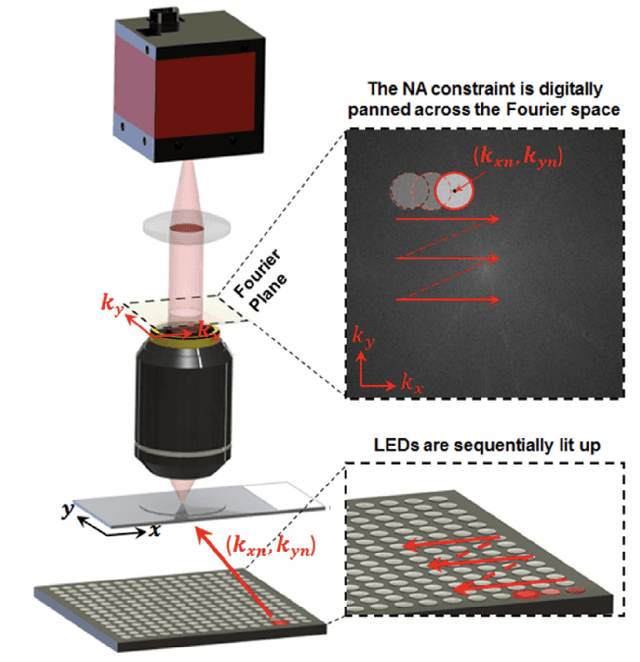
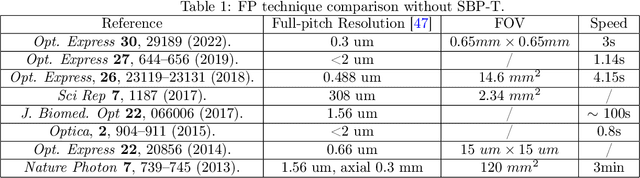
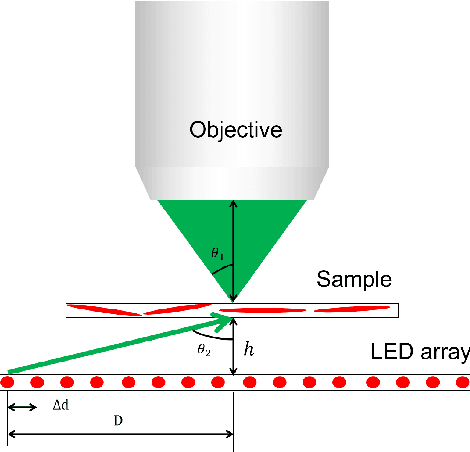
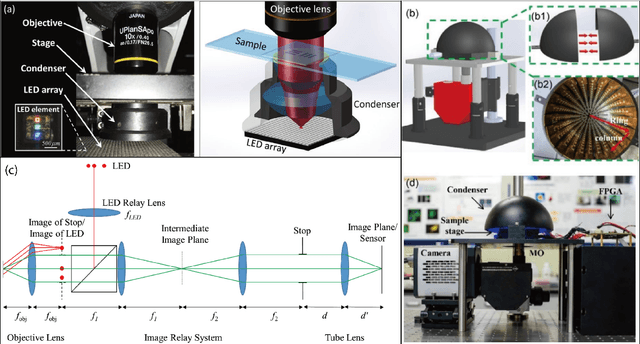
Fourier ptychography (FP) is a promising technique for high-throughput imaging. Reconstruction algorithms and illumination paradigm are two key aspects of FP. In this review, we mainly focus on illumination strategies in FP. We derive the space-bandwidth-time product (SBP-T) for the characterization of FP performance. Based on the analysis of SBP-T, we categorize the illumination strategy in FP effectively and discuss each category
A Dual-Stream Neural Network Explains the Functional Segregation of Dorsal and Ventral Visual Pathways in Human Brains
Oct 20, 2023The human visual system uses two parallel pathways for spatial processing and object recognition. In contrast, computer vision systems tend to use a single feedforward pathway, rendering them less robust, adaptive, or efficient than human vision. To bridge this gap, we developed a dual-stream vision model inspired by the human eyes and brain. At the input level, the model samples two complementary visual patterns to mimic how the human eyes use magnocellular and parvocellular retinal ganglion cells to separate retinal inputs to the brain. At the backend, the model processes the separate input patterns through two branches of convolutional neural networks (CNN) to mimic how the human brain uses the dorsal and ventral cortical pathways for parallel visual processing. The first branch (WhereCNN) samples a global view to learn spatial attention and control eye movements. The second branch (WhatCNN) samples a local view to represent the object around the fixation. Over time, the two branches interact recurrently to build a scene representation from moving fixations. We compared this model with the human brains processing the same movie and evaluated their functional alignment by linear transformation. The WhereCNN and WhatCNN branches were found to differentially match the dorsal and ventral pathways of the visual cortex, respectively, primarily due to their different learning objectives. These model-based results lead us to speculate that the distinct responses and representations of the ventral and dorsal streams are more influenced by their distinct goals in visual attention and object recognition than by their specific bias or selectivity in retinal inputs. This dual-stream model takes a further step in brain-inspired computer vision, enabling parallel neural networks to actively explore and understand the visual surroundings.
Identification of Abnormality in Maize Plants From UAV Images Using Deep Learning Approaches
Oct 20, 2023Early identification of abnormalities in plants is an important task for ensuring proper growth and achieving high yields from crops. Precision agriculture can significantly benefit from modern computer vision tools to make farming strategies addressing these issues efficient and effective. As farming lands are typically quite large, farmers have to manually check vast areas to determine the status of the plants and apply proper treatments. In this work, we consider the problem of automatically identifying abnormal regions in maize plants from images captured by a UAV. Using deep learning techniques, we have developed a methodology which can detect different levels of abnormality (i.e., low, medium, high or no abnormality) in maize plants independently of their growth stage. The primary goal is to identify anomalies at the earliest possible stage in order to maximize the effectiveness of potential treatments. At the same time, the proposed system can provide valuable information to human annotators for ground truth data collection by helping them to focus their attention on a much smaller set of images only. We have experimented with two different but complimentary approaches, the first considering abnormality detection as a classification problem and the second considering it as a regression problem. Both approaches can be generalized to different types of abnormalities and do not make any assumption about the abnormality occurring at an early plant growth stage which might be easier to detect due to the plants being smaller and easier to separate. As a case study, we have considered a publicly available data set which exhibits mostly Nitrogen deficiency in maize plants of various growth stages. We are reporting promising preliminary results with an 88.89\% detection accuracy of low abnormality and 100\% detection accuracy of no abnormality.
The Expressive Power of Transformers with Chain of Thought
Oct 18, 2023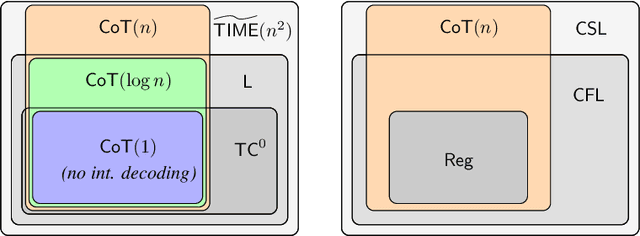
Recent theoretical work has identified surprisingly simple reasoning problems, such as checking if two nodes in a graph are connected or simulating finite-state machines, that are provably unsolvable by standard transformers that answer immediately after reading their input. However, in practice, transformers' reasoning can be improved by allowing them to use a "chain of thought" or "scratchpad", i.e., generate and condition on a sequence of intermediate tokens before answering. Motivated by this, we ask: Does such intermediate generation fundamentally extend the computational power of a decoder-only transformer? We show that the answer is yes, but the amount of increase depends crucially on the amount of intermediate generation. For instance, we find that transformer decoders with a logarithmic number of decoding steps (w.r.t. the input length) push the limits of standard transformers only slightly, while a linear number of decoding steps adds a clear new ability (under standard complexity conjectures): recognizing all regular languages. Our results also imply that linear steps keep transformer decoders within context-sensitive languages, and polynomial steps make them recognize exactly the class of polynomial-time solvable problems -- the first exact characterization of a type of transformers in terms of standard complexity classes. Together, our results provide a nuanced framework for understanding how the length of a transformer's chain of thought or scratchpad impacts its reasoning power.