 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Variational Inference for SDEs Driven by Fractional Noise
Oct 19, 2023
We present a novel variational framework for performing inference in (neural) stochastic differential equations (SDEs) driven by Markov-approximate fractional Brownian motion (fBM). SDEs offer a versatile tool for modeling real-world continuous-time dynamic systems with inherent noise and randomness. Combining SDEs with the powerful inference capabilities of variational methods, enables the learning of representative function distributions through stochastic gradient descent. However, conventional SDEs typically assume the underlying noise to follow a Brownian motion (BM), which hinders their ability to capture long-term dependencies. In contrast, fractional Brownian motion (fBM) extends BM to encompass non-Markovian dynamics, but existing methods for inferring fBM parameters are either computationally demanding or statistically inefficient. In this paper, building upon the Markov approximation of fBM, we derive the evidence lower bound essential for efficient variational inference of posterior path measures, drawing from the well-established field of stochastic analysis. Additionally, we provide a closed-form expression to determine optimal approximation coefficients. Furthermore, we propose the use of neural networks to learn the drift, diffusion and control terms within our variational posterior, leading to the variational training of neural-SDEs. In this framework, we also optimize the Hurst index, governing the nature of our fractional noise. Beyond validation on synthetic data, we contribute a novel architecture for variational latent video prediction,-an approach that, to the best of our knowledge, enables the first variational neural-SDE application to video perception.
LiDAR-UDA: Self-ensembling Through Time for Unsupervised LiDAR Domain Adaptation
Sep 24, 2023We introduce LiDAR-UDA, a novel two-stage self-training-based Unsupervised Domain Adaptation (UDA) method for LiDAR segmentation. Existing self-training methods use a model trained on labeled source data to generate pseudo labels for target data and refine the predictions via fine-tuning the network on the pseudo labels. These methods suffer from domain shifts caused by different LiDAR sensor configurations in the source and target domains. We propose two techniques to reduce sensor discrepancy and improve pseudo label quality: 1) LiDAR beam subsampling, which simulates different LiDAR scanning patterns by randomly dropping beams; 2) cross-frame ensembling, which exploits temporal consistency of consecutive frames to generate more reliable pseudo labels. Our method is simple, generalizable, and does not incur any extra inference cost. We evaluate our method on several public LiDAR datasets and show that it outperforms the state-of-the-art methods by more than $3.9\%$ mIoU on average for all scenarios. Code will be available at https://github.com/JHLee0513/LiDARUDA.
Illumination strategies for space-bandwidth-time product improvement in Fourier ptychography
Aug 26, 2023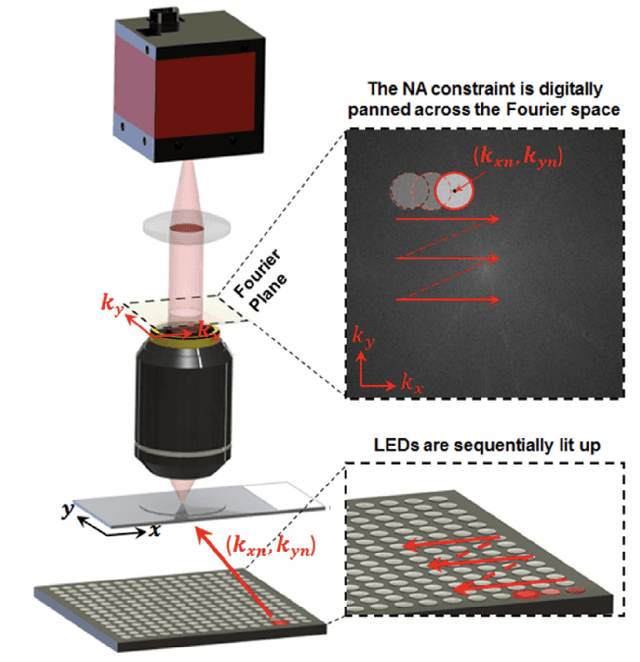
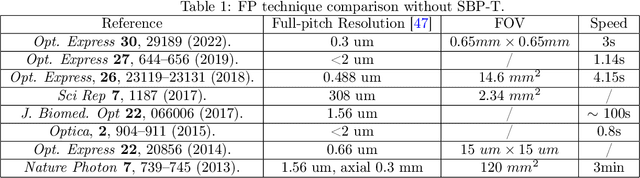
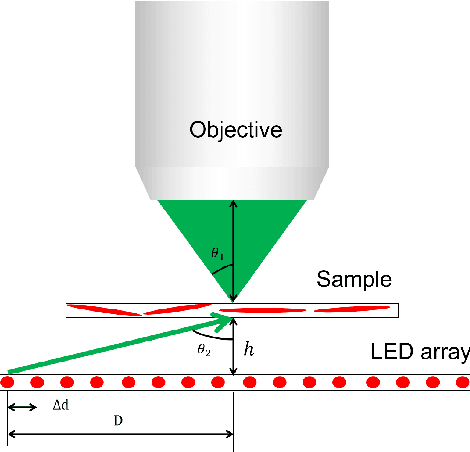
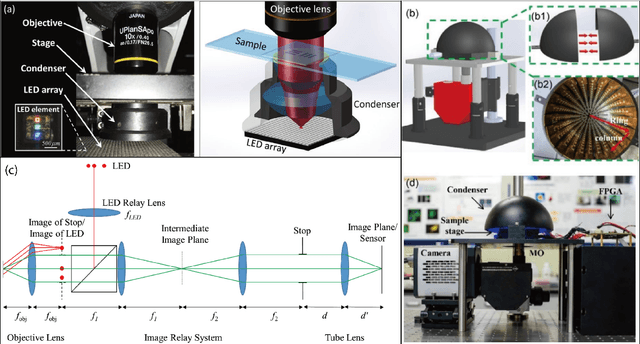
Fourier ptychography (FP) is a promising technique for high-throughput imaging. Reconstruction algorithms and illumination paradigm are two key aspects of FP. In this review, we mainly focus on illumination strategies in FP. We derive the space-bandwidth-time product (SBP-T) for the characterization of FP performance. Based on the analysis of SBP-T, we categorize the illumination strategy in FP effectively and discuss each category
Controllable Data Generation Via Iterative Data-Property Mutual Mappings
Oct 11, 2023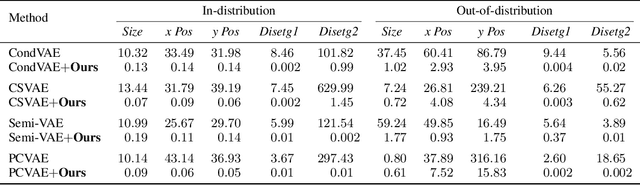
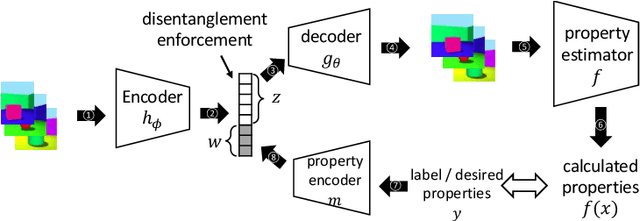
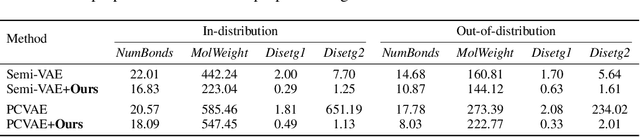
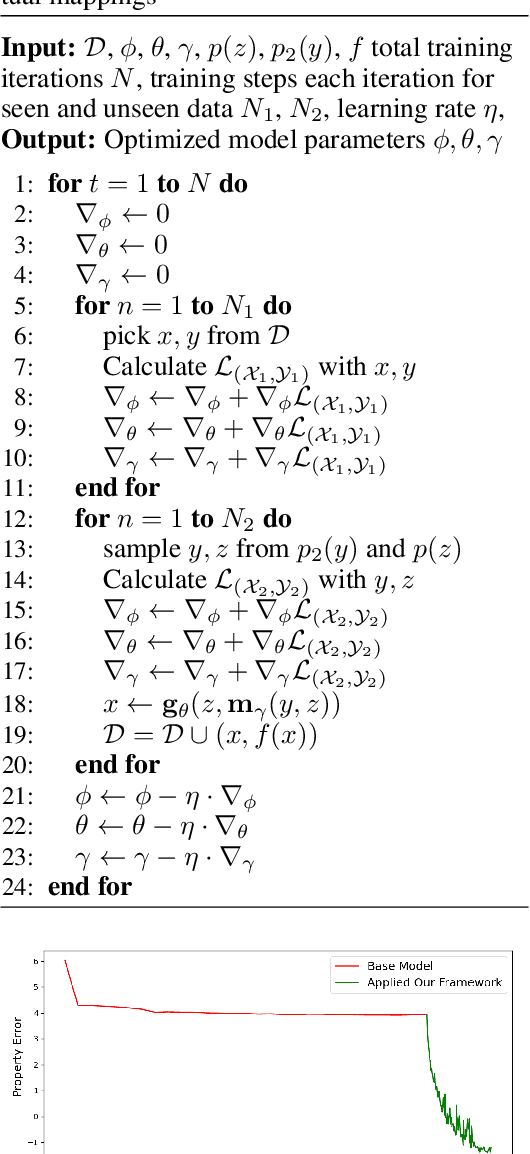
Deep generative models have been widely used for their ability to generate realistic data samples in various areas, such as images, molecules, text, and speech. One major goal of data generation is controllability, namely to generate new data with desired properties. Despite growing interest in the area of controllable generation, significant challenges still remain, including 1) disentangling desired properties with unrelated latent variables, 2) out-of-distribution property control, and 3) objective optimization for out-of-distribution property control. To address these challenges, in this paper, we propose a general framework to enhance VAE-based data generators with property controllability and ensure disentanglement. Our proposed objective can be optimized on both data seen and unseen in the training set. We propose a training procedure to train the objective in a semi-supervised manner by iteratively conducting mutual mappings between the data and properties. The proposed framework is implemented on four VAE-based controllable generators to evaluate its performance on property error, disentanglement, generation quality, and training time. The results indicate that our proposed framework enables more precise control over the properties of generated samples in a short training time, ensuring the disentanglement and keeping the validity of the generated samples.
HiCL: Hierarchical Contrastive Learning of Unsupervised Sentence Embeddings
Oct 15, 2023In this paper, we propose a hierarchical contrastive learning framework, HiCL, which considers local segment-level and global sequence-level relationships to improve training efficiency and effectiveness. Traditional methods typically encode a sequence in its entirety for contrast with others, often neglecting local representation learning, leading to challenges in generalizing to shorter texts. Conversely, HiCL improves its effectiveness by dividing the sequence into several segments and employing both local and global contrastive learning to model segment-level and sequence-level relationships. Further, considering the quadratic time complexity of transformers over input tokens, HiCL boosts training efficiency by first encoding short segments and then aggregating them to obtain the sequence representation. Extensive experiments show that HiCL enhances the prior top-performing SNCSE model across seven extensively evaluated STS tasks, with an average increase of +0.2% observed on BERT-large and +0.44% on RoBERTa-large.
FeatSense -- A Feature-based Registration Algorithm with GPU-accelerated TSDF-Mapping Backend for NVIDIA Jetson Boards
Oct 09, 2023

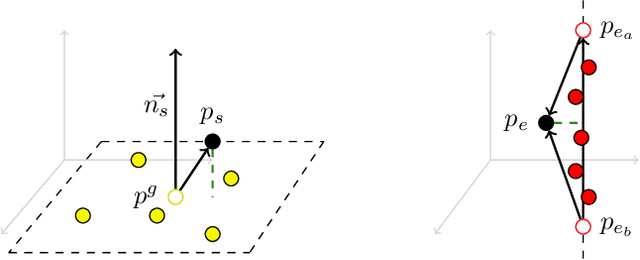

This paper presents FeatSense, a feature-based GPU-accelerated SLAM system for high resolution LiDARs, combined with a map generation algorithm for real-time generation of large Truncated Signed Distance Fields (TSDFs) on embedded hardware. FeatSense uses LiDAR point cloud features for odometry estimation and point cloud registration. The registered point clouds are integrated into a global Truncated Signed Distance Field (TSDF) representation. FeatSense is intended to run on embedded systems with integrated GPU-accelerator like NVIDIA Jetson boards. In this paper, we present a real-time capable TSDF-SLAM system specially tailored for close coupled CPU/GPU systems. The implementation is evaluated in various structured and unstructured environments and benchmarked against existing reference datasets. The main contribution of this paper is the ability to register up to 128 scan lines of an Ouster OS1-128 LiDAR at 10Hz on a NVIDIA AGX Xavier while achieving a TSDF map generation speedup by a factor of 100 compared to previous work on the same power budget.
StofNet: Super-resolution Time of Flight Network
Aug 23, 2023
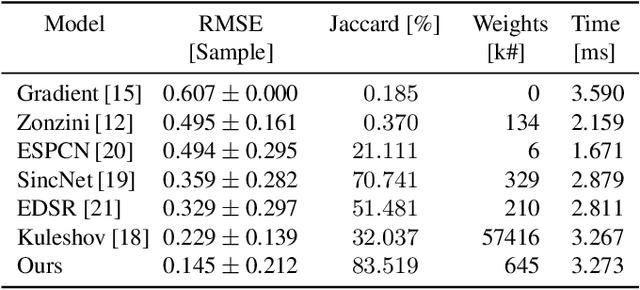
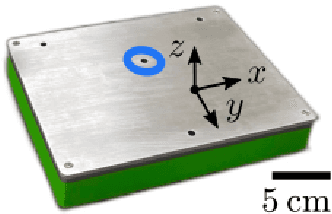
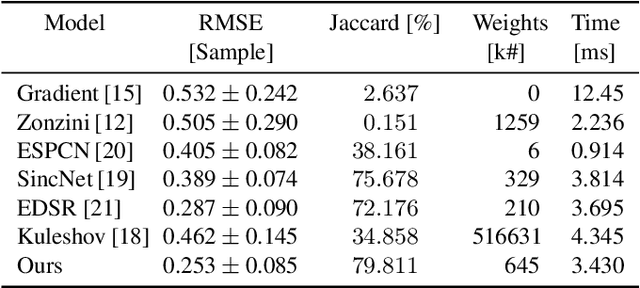
Time of Flight (ToF) is a prevalent depth sensing technology in the fields of robotics, medical imaging, and non-destructive testing. Yet, ToF sensing faces challenges from complex ambient conditions making an inverse modelling from the sparse temporal information intractable. This paper highlights the potential of modern super-resolution techniques to learn varying surroundings for a reliable and accurate ToF detection. Unlike existing models, we tailor an architecture for sub-sample precise semi-global signal localization by combining super-resolution with an efficient residual contraction block to balance between fine signal details and large scale contextual information. We consolidate research on ToF by conducting a benchmark comparison against six state-of-the-art methods for which we employ two publicly available datasets. This includes the release of our SToF-Chirp dataset captured by an airborne ultrasound transducer. Results showcase the superior performance of our proposed StofNet in terms of precision, reliability and model complexity. Our code is available at https://github.com/hahnec/stofnet.
Tree-Planner: Efficient Close-loop Task Planning with Large Language Models
Oct 12, 2023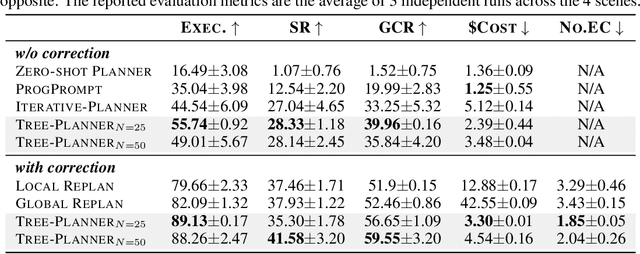
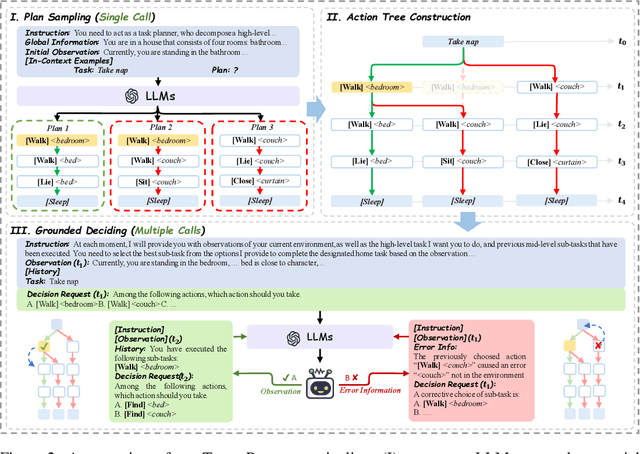
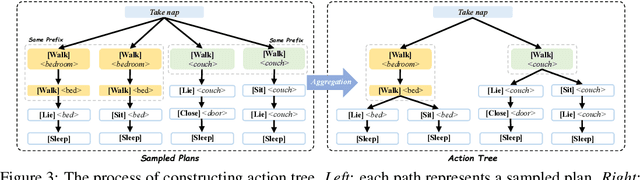

This paper studies close-loop task planning, which refers to the process of generating a sequence of skills (a plan) to accomplish a specific goal while adapting the plan based on real-time observations. Recently, prompting Large Language Models (LLMs) to generate actions iteratively has become a prevalent paradigm due to its superior performance and user-friendliness. However, this paradigm is plagued by two inefficiencies: high token consumption and redundant error correction, both of which hinder its scalability for large-scale testing and applications. To address these issues, we propose Tree-Planner, which reframes task planning with LLMs into three distinct phases: plan sampling, action tree construction, and grounded deciding. Tree-Planner starts by using an LLM to sample a set of potential plans before execution, followed by the aggregation of them to form an action tree. Finally, the LLM performs a top-down decision-making process on the tree, taking into account real-time environmental information. Experiments show that Tree-Planner achieves state-of-the-art performance while maintaining high efficiency. By decomposing LLM queries into a single plan-sampling call and multiple grounded-deciding calls, a considerable part of the prompt are less likely to be repeatedly consumed. As a result, token consumption is reduced by 92.2% compared to the previously best-performing model. Additionally, by enabling backtracking on the action tree as needed, the correction process becomes more flexible, leading to a 40.5% decrease in error corrections. Project page: https://tree-planner.github.io/
Predicting Financial Market Trends using Time Series Analysis and Natural Language Processing
Aug 31, 2023
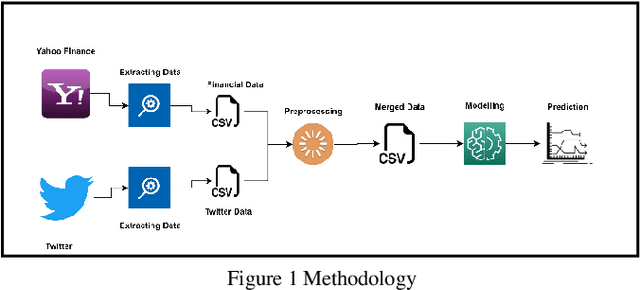
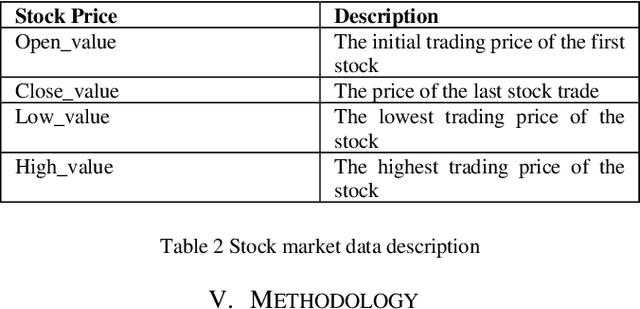
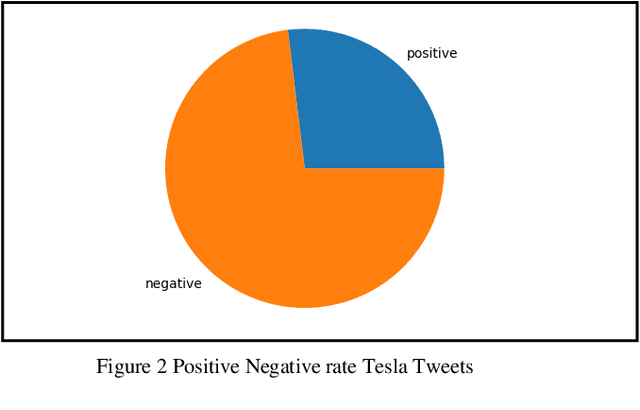
Forecasting financial market trends through time series analysis and natural language processing poses a complex and demanding undertaking, owing to the numerous variables that can influence stock prices. These variables encompass a spectrum of economic and political occurrences, as well as prevailing public attitudes. Recent research has indicated that the expression of public sentiments on social media platforms such as Twitter may have a noteworthy impact on the determination of stock prices. The objective of this study was to assess the viability of Twitter sentiments as a tool for predicting stock prices of major corporations such as Tesla, Apple. Our study has revealed a robust association between the emotions conveyed in tweets and fluctuations in stock prices. Our findings indicate that positivity, negativity, and subjectivity are the primary determinants of fluctuations in stock prices. The data was analyzed utilizing the Long-Short Term Memory neural network (LSTM) model, which is currently recognized as the leading methodology for predicting stock prices by incorporating Twitter sentiments and historical stock prices data. The models utilized in our study demonstrated a high degree of reliability and yielded precise outcomes for the designated corporations. In summary, this research emphasizes the significance of incorporating public opinions into the prediction of stock prices. The application of Time Series Analysis and Natural Language Processing methodologies can yield significant scientific findings regarding financial market patterns, thereby facilitating informed decision-making among investors. The results of our study indicate that the utilization of Twitter sentiments can serve as a potent instrument for forecasting stock prices, and ought to be factored in when formulating investment strategies.
A Modified EXP3 and Its Adaptive Variant in Adversarial Bandits with Multi-User Delayed Feedback
Oct 17, 2023For the adversarial multi-armed bandit problem with delayed feedback, we consider that the delayed feedback results are from multiple users and are unrestricted on internal distribution. As the player picks an arm, feedback from multiple users may not be received instantly yet after an arbitrary delay of time which is unknown to the player in advance. For different users in a round, the delays in feedback have no latent correlation. Thus, we formulate an adversarial multi-armed bandit problem with multi-user delayed feedback and design a modified EXP3 algorithm named MUD-EXP3, which makes a decision at each round by considering the importance-weighted estimator of the received feedback from different users. On the premise of known terminal round index $T$, the number of users $M$, the number of arms $N$, and upper bound of delay $d_{max}$, we prove a regret of $\mathcal{O}(\sqrt{TM^2\ln{N}(N\mathrm{e}+4d_{max})})$. Furthermore, for the more common case of unknown $T$, an adaptive algorithm named AMUD-EXP3 is proposed with a sublinear regret with respect to $T$. Finally, extensive experiments are conducted to indicate the correctness and effectiveness of our algorithms.