 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Point-TTA: Test-Time Adaptation for Point Cloud Registration Using Multitask Meta-Auxiliary Learning
Aug 31, 2023
We present Point-TTA, a novel test-time adaptation framework for point cloud registration (PCR) that improves the generalization and the performance of registration models. While learning-based approaches have achieved impressive progress, generalization to unknown testing environments remains a major challenge due to the variations in 3D scans. Existing methods typically train a generic model and the same trained model is applied on each instance during testing. This could be sub-optimal since it is difficult for the same model to handle all the variations during testing. In this paper, we propose a test-time adaptation approach for PCR. Our model can adapt to unseen distributions at test-time without requiring any prior knowledge of the test data. Concretely, we design three self-supervised auxiliary tasks that are optimized jointly with the primary PCR task. Given a test instance, we adapt our model using these auxiliary tasks and the updated model is used to perform the inference. During training, our model is trained using a meta-auxiliary learning approach, such that the adapted model via auxiliary tasks improves the accuracy of the primary task. Experimental results demonstrate the effectiveness of our approach in improving generalization of point cloud registration and outperforming other state-of-the-art approaches.
Fast Parameter Inference on Pulsar Timing Arrays with Normalizing Flows
Oct 18, 2023Pulsar timing arrays (PTAs) perform Bayesian posterior inference with expensive MCMC methods. Given a dataset of ~10-100 pulsars and O(10^3) timing residuals each, producing a posterior distribution for the stochastic gravitational wave background (SGWB) can take days to a week. The computational bottleneck arises because the likelihood evaluation required for MCMC is extremely costly when considering the dimensionality of the search space. Fortunately, generating simulated data is fast, so modern simulation-based inference techniques can be brought to bear on the problem. In this paper, we demonstrate how conditional normalizing flows trained on simulated data can be used for extremely fast and accurate estimation of the SGWB posteriors, reducing the sampling time from weeks to a matter of seconds.
An Exploration of Task-decoupling on Two-stage Neural Post Filter for Real-time Personalized Acoustic Echo Cancellation
Oct 07, 2023Deep learning based techniques have been popularly adopted in acoustic echo cancellation (AEC). Utilization of speaker representation has extended the frontier of AEC, thus attracting many researchers' interest in personalized acoustic echo cancellation (PAEC). Meanwhile, task-decoupling strategies are widely adopted in speech enhancement. To further explore the task-decoupling approach, we propose to use a two-stage task-decoupling post-filter (TDPF) in PAEC. Furthermore, a multi-scale local-global speaker representation is applied to improve speaker extraction in PAEC. Experimental results indicate that the task-decoupling model can yield better performance than a single joint network. The optimal approach is to decouple the echo cancellation from noise and interference speech suppression. Based on the task-decoupling sequence, optimal training strategies for the two-stage model are explored afterwards.
Visual Tracking Nonlinear Model Predictive Control Method for Autonomous Wind Turbine Inspection
Oct 21, 2023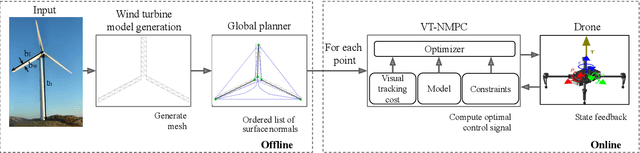
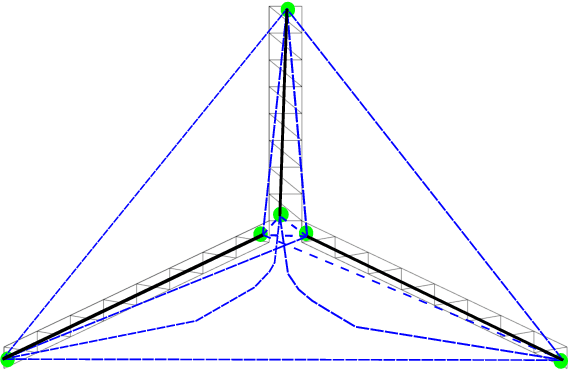
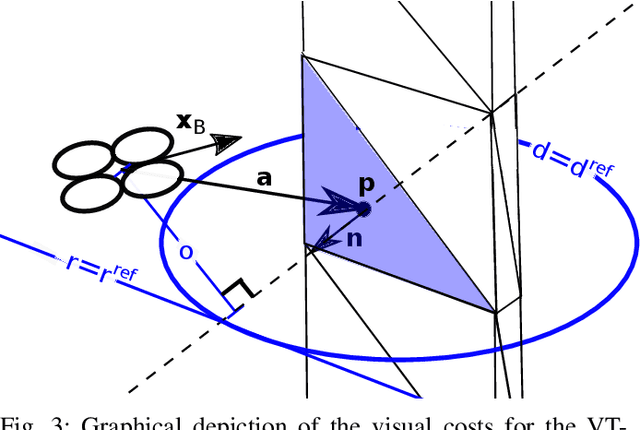
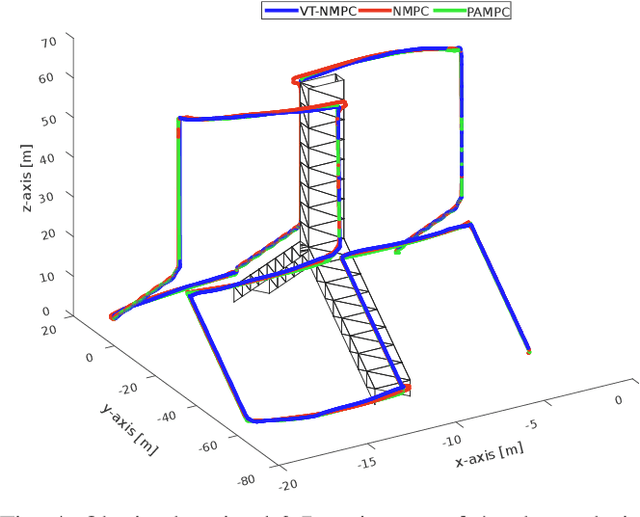
Automated visual inspection of on-and offshore wind turbines using aerial robots provides several benefits, namely, a safe working environment by circumventing the need for workers to be suspended high above the ground, reduced inspection time, preventive maintenance, and access to hard-to-reach areas. A novel nonlinear model predictive control (NMPC) framework alongside a global wind turbine path planner is proposed to achieve distance-optimal coverage for wind turbine inspection. Unlike traditional MPC formulations, visual tracking NMPC (VT-NMPC) is designed to track an inspection surface, instead of a position and heading trajectory, thereby circumventing the need to provide an accurate predefined trajectory for the drone. An additional capability of the proposed VT-NMPC method is that by incorporating inspection requirements as visual tracking costs to minimize, it naturally achieves the inspection task successfully while respecting the physical constraints of the drone. Multiple simulation runs and real-world tests demonstrate the efficiency and efficacy of the proposed automated inspection framework, which outperforms the traditional MPC designs, by providing full coverage of the target wind turbine blades as well as its robustness to changing wind conditions. The implementation codes are open-sourced.
COVIDFakeExplainer: An Explainable Machine Learning based Web Application for Detecting COVID-19 Fake News
Oct 21, 2023Fake news has emerged as a critical global issue, magnified by the COVID-19 pandemic, underscoring the need for effective preventive tools. Leveraging machine learning, including deep learning techniques, offers promise in combatting fake news. This paper goes beyond by establishing BERT as the superior model for fake news detection and demonstrates its utility as a tool to empower the general populace. We have implemented a browser extension, enhanced with explainability features, enabling real-time identification of fake news and delivering easily interpretable explanations. To achieve this, we have employed two publicly available datasets and created seven distinct data configurations to evaluate three prominent machine learning architectures. Our comprehensive experiments affirm BERT's exceptional accuracy in detecting COVID-19-related fake news. Furthermore, we have integrated an explainability component into the BERT model and deployed it as a service through Amazon's cloud API hosting (AWS). We have developed a browser extension that interfaces with the API, allowing users to select and transmit data from web pages, receiving an intelligible classification in return. This paper presents a practical end-to-end solution, highlighting the feasibility of constructing a holistic system for fake news detection, which can significantly benefit society.
Fast Diffusion GAN Model for Symbolic Music Generation Controlled by Emotions
Oct 21, 2023Diffusion models have shown promising results for a wide range of generative tasks with continuous data, such as image and audio synthesis. However, little progress has been made on using diffusion models to generate discrete symbolic music because this new class of generative models are not well suited for discrete data while its iterative sampling process is computationally expensive. In this work, we propose a diffusion model combined with a Generative Adversarial Network, aiming to (i) alleviate one of the remaining challenges in algorithmic music generation which is the control of generation towards a target emotion, and (ii) mitigate the slow sampling drawback of diffusion models applied to symbolic music generation. We first used a trained Variational Autoencoder to obtain embeddings of a symbolic music dataset with emotion labels and then used those to train a diffusion model. Our results demonstrate the successful control of our diffusion model to generate symbolic music with a desired emotion. Our model achieves several orders of magnitude improvement in computational cost, requiring merely four time steps to denoise while the steps required by current state-of-the-art diffusion models for symbolic music generation is in the order of thousands.
Beyond Accuracy: Evaluating Self-Consistency of Code Large Language Models with IdentityChain
Oct 21, 2023Code Large Language Models (Code LLMs) are being increasingly employed in real-life applications, so evaluating them is critical. While the general accuracy of Code LLMs on individual tasks has been extensively evaluated, their self-consistency across different tasks is overlooked. Intuitively, a trustworthy model should be self-consistent when generating natural language specifications for its own code and generating code for its own specifications. Failure to preserve self-consistency reveals a lack of understanding of the shared semantics underlying natural language and programming language, and therefore undermines the trustworthiness of a model. In this paper, we first formally define the self-consistency of Code LLMs and then design a framework, IdentityChain, which effectively and efficiently evaluates the self-consistency and general accuracy of a model at the same time. We study eleven Code LLMs and show that they fail to preserve self-consistency, which is indeed a distinct aspect from general accuracy. Furthermore, we show that IdentityChain can be used as a model debugging tool to expose weaknesses of Code LLMs by demonstrating three major weaknesses that we identify in current models using IdentityChain. Our code is available at https://github.com/marcusm117/IdentityChain.
Distributed Estimation with Partially Accessible Information: An IMAT Approach to LMS Diffusion
Oct 17, 2023Distributed algorithms, particularly Diffusion Least Mean Square, are widely favored for their reliability, robustness, and fast convergence in various industries. However, limited observability of the target can compromise the integrity of the algorithm. To address this issue, this paper proposes a framework for analyzing combination strategies by drawing inspiration from signal flow analysis. A thresholding-based algorithm is also presented to identify and utilize the support vector in scenarios with missing information about the target vector's support. The proposed approach is demonstrated in two combination scenarios, showcasing the effectiveness of the algorithm in situations characterized by sparse observations in the time and transform domains.
Field Robot for High-throughput and High-resolution 3D Plant Phenotyping
Oct 17, 2023With the need to feed a growing world population, the efficiency of crop production is of paramount importance. To support breeding and field management, various characteristics of the plant phenotype need to be measured -- a time-consuming process when performed manually. We present a robotic platform equipped with multiple laser and camera sensors for high-throughput, high-resolution in-field plant scanning. We create digital twins of the plants through 3D reconstruction. This allows the estimation of phenotypic traits such as leaf area, leaf angle, and plant height. We validate our system on a real field, where we reconstruct accurate point clouds and meshes of sugar beet, soybean, and maize.
Towards Design and Development of an ArUco Markers-Based Quantitative Surface Tactile Sensor
Oct 12, 2023

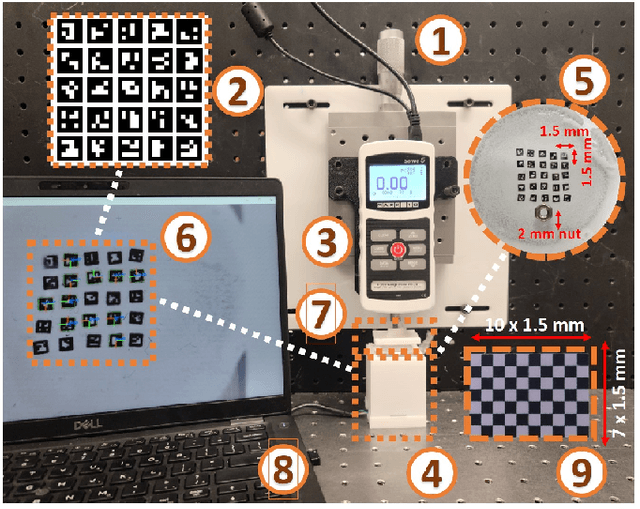
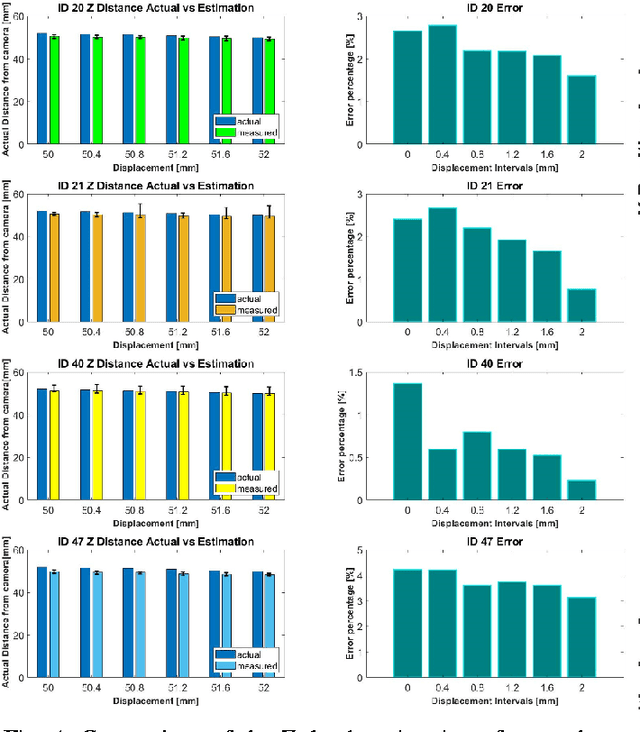
In this paper, with the goal of quantifying the qualitative image outputs of a Vision-based Tactile Sensor (VTS), we present the design, fabrication, and characterization of a novel Quantitative Surface Tactile Sensor (called QS-TS). QS-TS directly estimates the sensor's gel layer deformation in real-time enabling safe and autonomous tactile manipulation and servoing of delicate objects using robotic manipulators. The core of the proposed sensor is the utilization of miniature 1.5 mm x 1.5 mm synthetic square markers with inner binary patterns and a broad black border, called ArUco Markers. Each ArUco marker can provide real-time camera pose estimation that, in our design, is used as a quantitative measure for obtaining deformation of the QS-TS gel layer. Moreover, thanks to the use of ArUco markers, we propose a unique fabrication procedure that mitigates various challenges associated with the fabrication of the existing marker-based VTSs and offers an intuitive and less-arduous method for the construction of the VTS. Remarkably, the proposed fabrication facilitates the integration and adherence of markers with the gel layer to robustly and reliably obtain a quantitative measure of deformation in real-time regardless of the orientation of ArUco Markers. The performance and efficacy of the proposed QS-TS in estimating the deformation of the sensor's gel layer were experimentally evaluated and verified. Results demonstrate the phenomenal performance of the QS-TS in estimating the deformation of the gel layer with a relative error of <5%.