 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Near-optimal Differentially Private Client Selection in Federated Settings
Oct 13, 2023
We develop an iterative differentially private algorithm for client selection in federated settings. We consider a federated network wherein clients coordinate with a central server to complete a task; however, the clients decide whether to participate or not at a time step based on their preferences -- local computation and probabilistic intent. The algorithm does not require client-to-client information exchange. The developed algorithm provides near-optimal values to the clients over long-term average participation with a certain differential privacy guarantee. Finally, we present the experimental results to check the algorithm's efficacy.
Robust Quickest Change Detection in Non-Stationary Processes
Oct 14, 2023Optimal algorithms are developed for robust detection of changes in non-stationary processes. These are processes in which the distribution of the data after change varies with time. The decision-maker does not have access to precise information on the post-change distribution. It is shown that if the post-change non-stationary family has a distribution that is least favorable in a well-defined sense, then the algorithms designed using the least favorable distributions are robust and optimal. Non-stationary processes are encountered in public health monitoring and space and military applications. The robust algorithms are applied to real and simulated data to show their effectiveness.
A Transformer-based Framework For Multi-variate Time Series: A Remaining Useful Life Prediction Use Case
Aug 29, 2023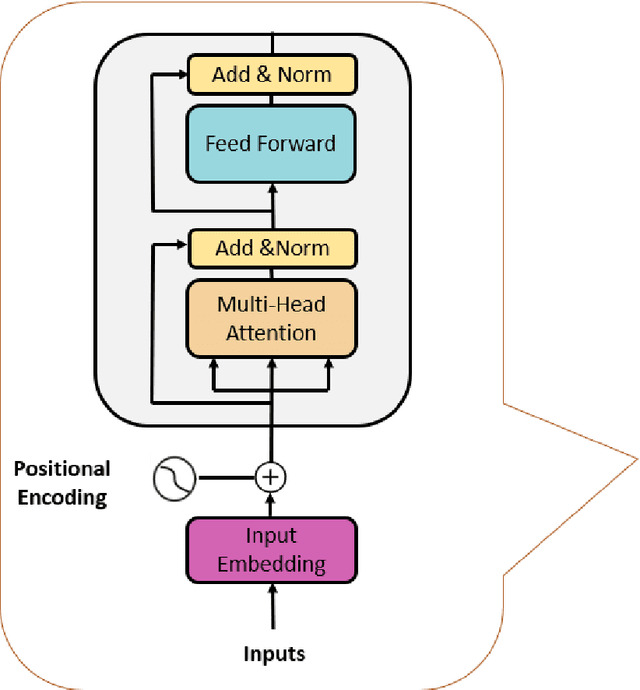

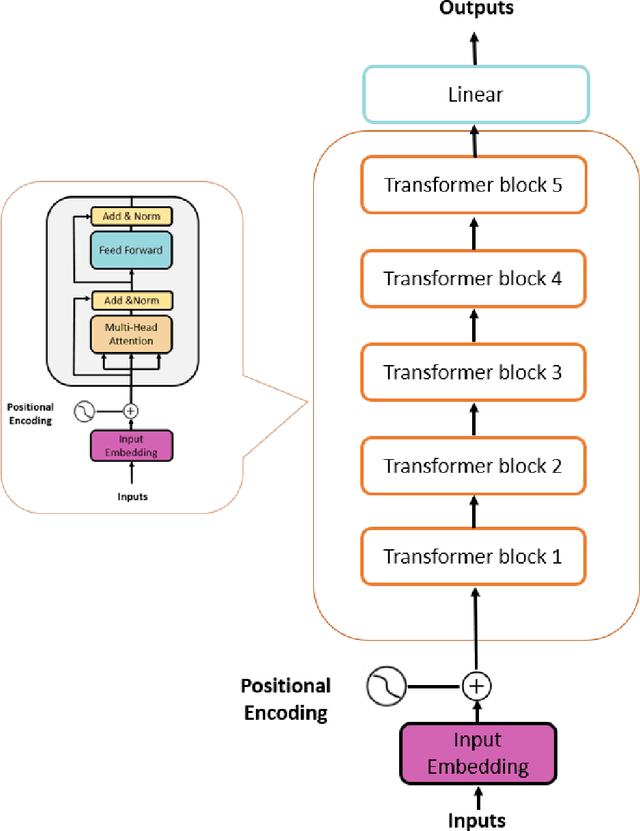

In recent times, Large Language Models (LLMs) have captured a global spotlight and revolutionized the field of Natural Language Processing. One of the factors attributed to the effectiveness of LLMs is the model architecture used for training, transformers. Transformer models excel at capturing contextual features in sequential data since time series data are sequential, transformer models can be leveraged for more efficient time series data prediction. The field of prognostics is vital to system health management and proper maintenance planning. A reliable estimation of the remaining useful life (RUL) of machines holds the potential for substantial cost savings. This includes avoiding abrupt machine failures, maximizing equipment usage, and serving as a decision support system (DSS). This work proposed an encoder-transformer architecture-based framework for multivariate time series prediction for a prognostics use case. We validated the effectiveness of the proposed framework on all four sets of the C-MAPPS benchmark dataset for the remaining useful life prediction task. To effectively transfer the knowledge and application of transformers from the natural language domain to time series, three model-specific experiments were conducted. Also, to enable the model awareness of the initial stages of the machine life and its degradation path, a novel expanding window method was proposed for the first time in this work, it was compared with the sliding window method, and it led to a large improvement in the performance of the encoder transformer model. Finally, the performance of the proposed encoder-transformer model was evaluated on the test dataset and compared with the results from 13 other state-of-the-art (SOTA) models in the literature and it outperformed them all with an average performance increase of 137.65% over the next best model across all the datasets.
FSD: Fast Self-Supervised Single RGB-D to Categorical 3D Objects
Oct 19, 2023In this work, we address the challenging task of 3D object recognition without the reliance on real-world 3D labeled data. Our goal is to predict the 3D shape, size, and 6D pose of objects within a single RGB-D image, operating at the category level and eliminating the need for CAD models during inference. While existing self-supervised methods have made strides in this field, they often suffer from inefficiencies arising from non-end-to-end processing, reliance on separate models for different object categories, and slow surface extraction during the training of implicit reconstruction models; thus hindering both the speed and real-world applicability of the 3D recognition process. Our proposed method leverages a multi-stage training pipeline, designed to efficiently transfer synthetic performance to the real-world domain. This approach is achieved through a combination of 2D and 3D supervised losses during the synthetic domain training, followed by the incorporation of 2D supervised and 3D self-supervised losses on real-world data in two additional learning stages. By adopting this comprehensive strategy, our method successfully overcomes the aforementioned limitations and outperforms existing self-supervised 6D pose and size estimation baselines on the NOCS test-set with a 16.4% absolute improvement in mAP for 6D pose estimation while running in near real-time at 5 Hz.
Can Electromagnetic Information Theory Improve Wireless Systems? A Channel Estimation Example
Oct 19, 2023Electromagnetic information theory (EIT) is an emerging interdisciplinary subject that integrates classical Maxwell electromagnetics and Shannon information theory. The goal of EIT is to uncover the information transmission mechanisms from an electromagnetic (EM) perspective in wireless systems. Existing works on EIT are mainly focused on the analysis of degrees-of-freedom (DoF), system capacity, and characteristics of the electromagnetic channel. However, these works do not clarify how EIT can improve wireless communication systems. To answer this question, in this paper, we provide a novel demonstration of the application of EIT. By integrating EM knowledge into the classical MMSE channel estimator, we observe for the first time that EIT is capable of improving the channel estimation performace. Specifically, the EM knowledge is first encoded into a spatio-temporal correlation function (STCF), which we term as the EM kernel. This EM kernel plays the role of side information to the channel estimator. Since the EM kernel takes the form of Gaussian processes (GP), we propose the EIT-based Gaussian process regression (EIT-GPR) to derive the channel estimations. In addition, since the EM kernel allows parameter tuning, we propose EM kernel learning to fit the EM kernel to channel observations. Simulation results show that the application of EIT to the channel estimator enables it to outperform traditional isotropic MMSE algorithm, thus proving the practical values of EIT.
Solving Expensive Optimization Problems in Dynamic Environments with Meta-learning
Oct 19, 2023Dynamic environments pose great challenges for expensive optimization problems, as the objective functions of these problems change over time and thus require remarkable computational resources to track the optimal solutions. Although data-driven evolutionary optimization and Bayesian optimization (BO) approaches have shown promise in solving expensive optimization problems in static environments, the attempts to develop such approaches in dynamic environments remain rarely unexplored. In this paper, we propose a simple yet effective meta-learning-based optimization framework for solving expensive dynamic optimization problems. This framework is flexible, allowing any off-the-shelf continuously differentiable surrogate model to be used in a plug-in manner, either in data-driven evolutionary optimization or BO approaches. In particular, the framework consists of two unique components: 1) the meta-learning component, in which a gradient-based meta-learning approach is adopted to learn experience (effective model parameters) across different dynamics along the optimization process. 2) the adaptation component, where the learned experience (model parameters) is used as the initial parameters for fast adaptation in the dynamic environment based on few shot samples. By doing so, the optimization process is able to quickly initiate the search in a new environment within a strictly restricted computational budget. Experiments demonstrate the effectiveness of the proposed algorithm framework compared to several state-of-the-art algorithms on common benchmark test problems under different dynamic characteristics.
DT/MARS-CycleGAN: Improved Object Detection for MARS Phenotyping Robot
Oct 19, 2023Robotic crop phenotyping has emerged as a key technology to assess crops' morphological and physiological traits at scale. These phenotypical measurements are essential for developing new crop varieties with the aim of increasing productivity and dealing with environmental challenges such as climate change. However, developing and deploying crop phenotyping robots face many challenges such as complex and variable crop shapes that complicate robotic object detection, dynamic and unstructured environments that baffle robotic control, and real-time computing and managing big data that challenge robotic hardware/software. This work specifically tackles the first challenge by proposing a novel Digital-Twin(DT)MARS-CycleGAN model for image augmentation to improve our Modular Agricultural Robotic System (MARS)'s crop object detection from complex and variable backgrounds. Our core idea is that in addition to the cycle consistency losses in the CycleGAN model, we designed and enforced a new DT-MARS loss in the deep learning model to penalize the inconsistency between real crop images captured by MARS and synthesized images sensed by DT MARS. Therefore, the generated synthesized crop images closely mimic real images in terms of realism, and they are employed to fine-tune object detectors such as YOLOv8. Extensive experiments demonstrated that our new DT/MARS-CycleGAN framework significantly boosts our MARS' crop object/row detector's performance, contributing to the field of robotic crop phenotyping.
Eureka: Human-Level Reward Design via Coding Large Language Models
Oct 19, 2023Large Language Models (LLMs) have excelled as high-level semantic planners for sequential decision-making tasks. However, harnessing them to learn complex low-level manipulation tasks, such as dexterous pen spinning, remains an open problem. We bridge this fundamental gap and present Eureka, a human-level reward design algorithm powered by LLMs. Eureka exploits the remarkable zero-shot generation, code-writing, and in-context improvement capabilities of state-of-the-art LLMs, such as GPT-4, to perform evolutionary optimization over reward code. The resulting rewards can then be used to acquire complex skills via reinforcement learning. Without any task-specific prompting or pre-defined reward templates, Eureka generates reward functions that outperform expert human-engineered rewards. In a diverse suite of 29 open-source RL environments that include 10 distinct robot morphologies, Eureka outperforms human experts on 83% of the tasks, leading to an average normalized improvement of 52%. The generality of Eureka also enables a new gradient-free in-context learning approach to reinforcement learning from human feedback (RLHF), readily incorporating human inputs to improve the quality and the safety of the generated rewards without model updating. Finally, using Eureka rewards in a curriculum learning setting, we demonstrate for the first time, a simulated Shadow Hand capable of performing pen spinning tricks, adeptly manipulating a pen in circles at rapid speed.
CylinderTag: An Accurate and Flexible Marker for Cylinder-Shape Objects Pose Estimation Based on Projective Invariants
Oct 20, 2023High-precision pose estimation based on visual markers has been a thriving research topic in the field of computer vision. However, the suitability of traditional flat markers on curved objects is limited due to the diverse shapes of curved surfaces, which hinders the development of high-precision pose estimation for curved objects. Therefore, this paper proposes a novel visual marker called CylinderTag, which is designed for developable curved surfaces such as cylindrical surfaces. CylinderTag is a cyclic marker that can be firmly attached to objects with a cylindrical shape. Leveraging the manifold assumption, the cross-ratio in projective invariance is utilized for encoding in the direction of zero curvature on the surface. Additionally, to facilitate the usage of CylinderTag, we propose a heuristic search-based marker generator and a high-performance recognizer as well. Moreover, an all-encompassing evaluation of CylinderTag properties is conducted by means of extensive experimentation, covering detection rate, detection speed, dictionary size, localization jitter, and pose estimation accuracy. CylinderTag showcases superior detection performance from varying view angles in comparison to traditional visual markers, accompanied by higher localization accuracy. Furthermore, CylinderTag boasts real-time detection capability and an extensive marker dictionary, offering enhanced versatility and practicality in a wide range of applications. Experimental results demonstrate that the CylinderTag is a highly promising visual marker for use on cylindrical-like surfaces, thus offering important guidance for future research on high-precision visual localization of cylinder-shaped objects. The code is available at: https://github.com/wsakobe/CylinderTag.
HRTF Interpolation using a Spherical Neural Process Meta-Learner
Oct 20, 2023Several individualization methods have recently been proposed to estimate a subject's Head-Related Transfer Function (HRTF) using convenient input modalities such as anthropometric measurements or pinnae photographs. There exists a need for adaptively correcting the estimation error committed by such methods using a few data point samples from the subject's HRTF, acquired using acoustic measurements or perceptual feedback. To this end, we introduce a Convolutional Conditional Neural Process meta-learner specialized in HRTF error interpolation. In particular, the model includes a Spherical Convolutional Neural Network component to accommodate the spherical geometry of HRTF data. It also exploits potential symmetries between the HRTF's left and right channels about the median axis. In this work, we evaluate the proposed model's performance purely on time-aligned spectrum interpolation grounds under a simplified setup where a generic population-mean HRTF forms the initial estimates prior to corrections instead of individualized ones. The trained model achieves up to 3 dB relative error reduction compared to state-of-the-art interpolation methods despite being trained using only 85 subjects. This improvement translates up to nearly a halving of the data point count required to achieve comparable accuracy, in particular from 50 to 28 points to reach an average of -20 dB relative error per interpolated feature. Moreover, we show that the trained model provides well-calibrated uncertainty estimates. Accordingly, such estimates can inform the sequential decision problem of acquiring as few correcting HRTF data points as needed to meet a desired level of HRTF individualization accuracy.