 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Equivariant Deep Weight Space Alignment
Oct 20, 2023
Permutation symmetries of deep networks make simple operations like model averaging and similarity estimation challenging. In many cases, aligning the weights of the networks, i.e., finding optimal permutations between their weights, is necessary. More generally, weight alignment is essential for a wide range of applications, from model merging, through exploring the optimization landscape of deep neural networks, to defining meaningful distance functions between neural networks. Unfortunately, weight alignment is an NP-hard problem. Prior research has mainly focused on solving relaxed versions of the alignment problem, leading to either time-consuming methods or sub-optimal solutions. To accelerate the alignment process and improve its quality, we propose a novel framework aimed at learning to solve the weight alignment problem, which we name Deep-Align. To that end, we first demonstrate that weight alignment adheres to two fundamental symmetries and then, propose a deep architecture that respects these symmetries. Notably, our framework does not require any labeled data. We provide a theoretical analysis of our approach and evaluate Deep-Align on several types of network architectures and learning setups. Our experimental results indicate that a feed-forward pass with Deep-Align produces better or equivalent alignments compared to those produced by current optimization algorithms. Additionally, our alignments can be used as an initialization for other methods to gain even better solutions with a significant speedup in convergence.
Prompting-based Efficient Temporal Domain Generalization
Oct 03, 2023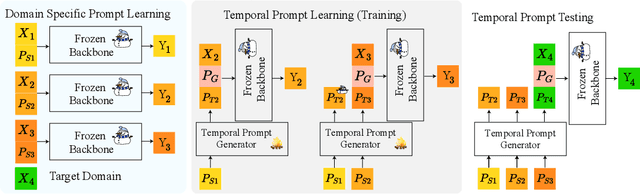
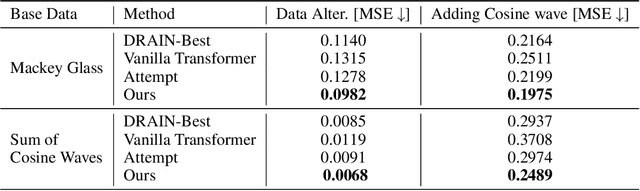
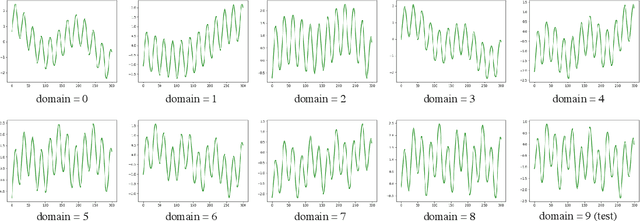
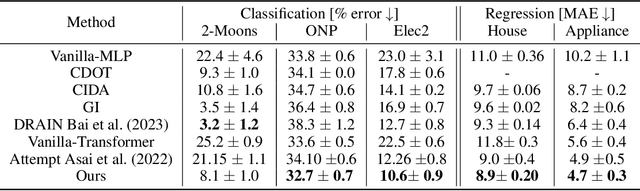
Machine learning traditionally assumes that training and testing data are distributed independently and identically. However, in many real-world settings, the data distribution can shift over time, leading to poor generalization of trained models in future time periods. Our paper presents a novel prompting-based approach to temporal domain generalization that is parameter-efficient, time-efficient, and does not require access to the target domain data (i.e., unseen future time periods) during training. Our method adapts a target pre-trained model to temporal drift by learning global prompts, domain-specific prompts, and drift-aware prompts that capture underlying temporal dynamics. It is compatible across diverse tasks, such as classification, regression, and time series forecasting, and sets a new state-of-the-art benchmark in temporal domain generalization. The code repository will be publicly shared.
Adaptive, Doubly Optimal No-Regret Learning in Strongly Monotone and Exp-Concave Games with Gradient Feedback
Oct 21, 2023Online gradient descent (OGD) is well known to be doubly optimal under strong convexity or monotonicity assumptions: (1) in the single-agent setting, it achieves an optimal regret of $\Theta(\log T)$ for strongly convex cost functions; and (2) in the multi-agent setting of strongly monotone games, with each agent employing OGD, we obtain last-iterate convergence of the joint action to a unique Nash equilibrium at an optimal rate of $\Theta(\frac{1}{T})$. While these finite-time guarantees highlight its merits, OGD has the drawback that it requires knowing the strong convexity/monotonicity parameters. In this paper, we design a fully adaptive OGD algorithm, \textsf{AdaOGD}, that does not require a priori knowledge of these parameters. In the single-agent setting, our algorithm achieves $O(\log^2(T))$ regret under strong convexity, which is optimal up to a log factor. Further, if each agent employs \textsf{AdaOGD} in strongly monotone games, the joint action converges in a last-iterate sense to a unique Nash equilibrium at a rate of $O(\frac{\log^3 T}{T})$, again optimal up to log factors. We illustrate our algorithms in a learning version of the classical newsvendor problem, where due to lost sales, only (noisy) gradient feedback can be observed. Our results immediately yield the first feasible and near-optimal algorithm for both the single-retailer and multi-retailer settings. We also extend our results to the more general setting of exp-concave cost functions and games, using the online Newton step (ONS) algorithm.
A Geometrical Approach to Evaluate the Adversarial Robustness of Deep Neural Networks
Oct 10, 2023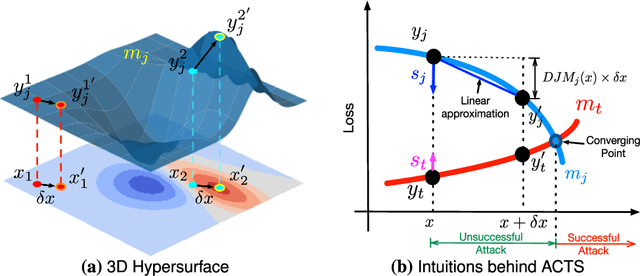
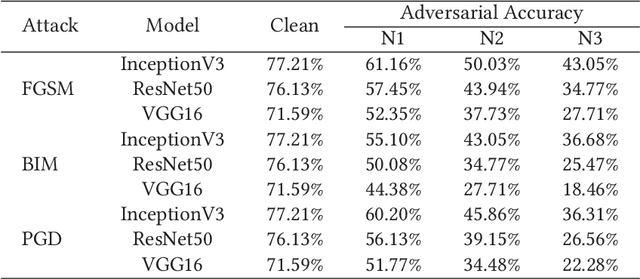
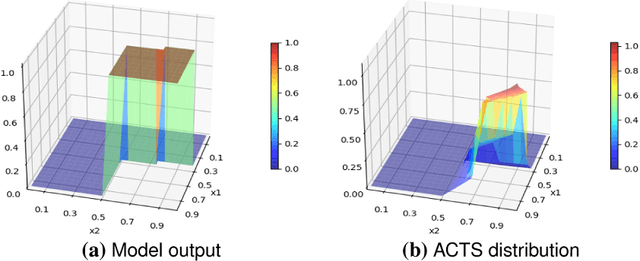
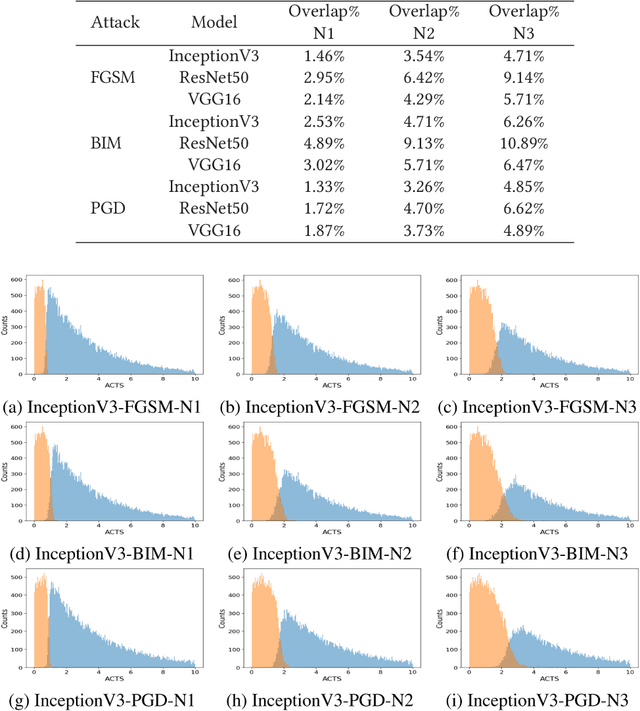
Deep Neural Networks (DNNs) are widely used for computer vision tasks. However, it has been shown that deep models are vulnerable to adversarial attacks, i.e., their performances drop when imperceptible perturbations are made to the original inputs, which may further degrade the following visual tasks or introduce new problems such as data and privacy security. Hence, metrics for evaluating the robustness of deep models against adversarial attacks are desired. However, previous metrics are mainly proposed for evaluating the adversarial robustness of shallow networks on the small-scale datasets. Although the Cross Lipschitz Extreme Value for nEtwork Robustness (CLEVER) metric has been proposed for large-scale datasets (e.g., the ImageNet dataset), it is computationally expensive and its performance relies on a tractable number of samples. In this paper, we propose the Adversarial Converging Time Score (ACTS), an attack-dependent metric that quantifies the adversarial robustness of a DNN on a specific input. Our key observation is that local neighborhoods on a DNN's output surface would have different shapes given different inputs. Hence, given different inputs, it requires different time for converging to an adversarial sample. Based on this geometry meaning, ACTS measures the converging time as an adversarial robustness metric. We validate the effectiveness and generalization of the proposed ACTS metric against different adversarial attacks on the large-scale ImageNet dataset using state-of-the-art deep networks. Extensive experiments show that our ACTS metric is an efficient and effective adversarial metric over the previous CLEVER metric.
Long-form Simultaneous Speech Translation: Thesis Proposal
Oct 17, 2023Simultaneous speech translation (SST) aims to provide real-time translation of spoken language, even before the speaker finishes their sentence. Traditionally, SST has been addressed primarily by cascaded systems that decompose the task into subtasks, including speech recognition, segmentation, and machine translation. However, the advent of deep learning has sparked significant interest in end-to-end (E2E) systems. Nevertheless, a major limitation of most approaches to E2E SST reported in the current literature is that they assume that the source speech is pre-segmented into sentences, which is a significant obstacle for practical, real-world applications. This thesis proposal addresses end-to-end simultaneous speech translation, particularly in the long-form setting, i.e., without pre-segmentation. We present a survey of the latest advancements in E2E SST, assess the primary obstacles in SST and its relevance to long-form scenarios, and suggest approaches to tackle these challenges.
DATT: Deep Adaptive Trajectory Tracking for Quadrotor Control
Oct 17, 2023Precise arbitrary trajectory tracking for quadrotors is challenging due to unknown nonlinear dynamics, trajectory infeasibility, and actuation limits. To tackle these challenges, we present Deep Adaptive Trajectory Tracking (DATT), a learning-based approach that can precisely track arbitrary, potentially infeasible trajectories in the presence of large disturbances in the real world. DATT builds on a novel feedforward-feedback-adaptive control structure trained in simulation using reinforcement learning. When deployed on real hardware, DATT is augmented with a disturbance estimator using L1 adaptive control in closed-loop, without any fine-tuning. DATT significantly outperforms competitive adaptive nonlinear and model predictive controllers for both feasible smooth and infeasible trajectories in unsteady wind fields, including challenging scenarios where baselines completely fail. Moreover, DATT can efficiently run online with an inference time less than 3.2 ms, less than 1/4 of the adaptive nonlinear model predictive control baseline
Real-time Detection of AI-Generated Speech for DeepFake Voice Conversion
Aug 24, 2023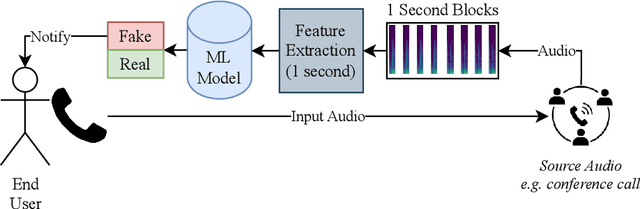

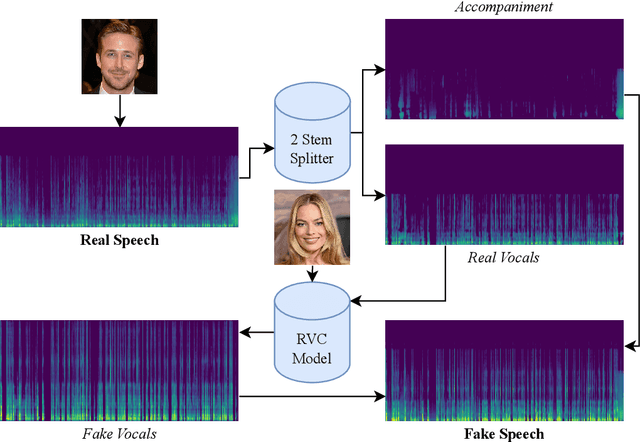
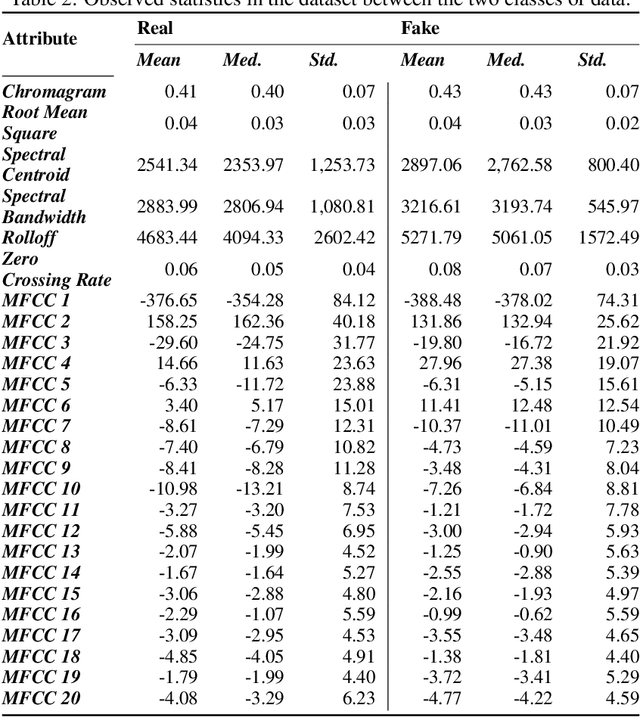
There are growing implications surrounding generative AI in the speech domain that enable voice cloning and real-time voice conversion from one individual to another. This technology poses a significant ethical threat and could lead to breaches of privacy and misrepresentation, thus there is an urgent need for real-time detection of AI-generated speech for DeepFake Voice Conversion. To address the above emerging issues, the DEEP-VOICE dataset is generated in this study, comprised of real human speech from eight well-known figures and their speech converted to one another using Retrieval-based Voice Conversion. Presenting as a binary classification problem of whether the speech is real or AI-generated, statistical analysis of temporal audio features through t-testing reveals that there are significantly different distributions. Hyperparameter optimisation is implemented for machine learning models to identify the source of speech. Following the training of 208 individual machine learning models over 10-fold cross validation, it is found that the Extreme Gradient Boosting model can achieve an average classification accuracy of 99.3% and can classify speech in real-time, at around 0.004 milliseconds given one second of speech. All data generated for this study is released publicly for future research on AI speech detection.
Multi-Scale Spatial-Temporal Recurrent Networks for Traffic Flow Prediction
Oct 12, 2023

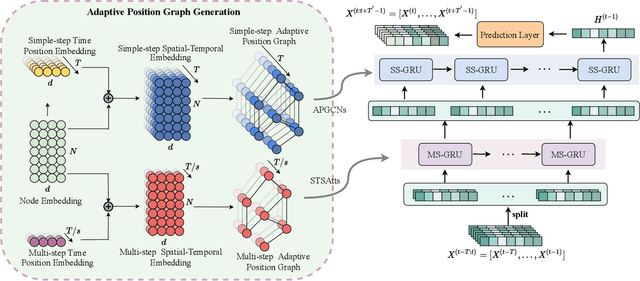
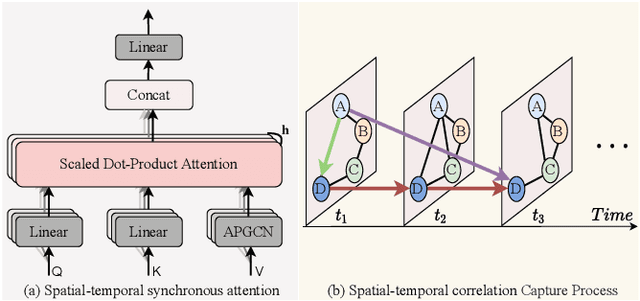
Traffic flow prediction is one of the most fundamental tasks of intelligent transportation systems. The complex and dynamic spatial-temporal dependencies make the traffic flow prediction quite challenging. Although existing spatial-temporal graph neural networks hold prominent, they often encounter challenges such as (1) ignoring the fixed graph that limits the predictive performance of the model, (2) insufficiently capturing complex spatial-temporal dependencies simultaneously, and (3) lacking attention to spatial-temporal information at different time lengths. In this paper, we propose a Multi-Scale Spatial-Temporal Recurrent Network for traffic flow prediction, namely MSSTRN, which consists of two different recurrent neural networks: the single-step gate recurrent unit and the multi-step gate recurrent unit to fully capture the complex spatial-temporal information in the traffic data under different time windows. Moreover, we propose a spatial-temporal synchronous attention mechanism that integrates adaptive position graph convolutions into the self-attention mechanism to achieve synchronous capture of spatial-temporal dependencies. We conducted extensive experiments on four real traffic datasets and demonstrated that our model achieves the best prediction accuracy with non-trivial margins compared to all the twenty baseline methods.
A Carbon Tracking Model for Federated Learning: Impact of Quantization and Sparsification
Oct 12, 2023Federated Learning (FL) methods adopt efficient communication technologies to distribute machine learning tasks across edge devices, reducing the overhead in terms of data storage and computational complexity compared to centralized solutions. Rather than moving large data volumes from producers (sensors, machines) to energy-hungry data centers, raising environmental concerns due to resource demands, FL provides an alternative solution to mitigate the energy demands of several learning tasks while enabling new Artificial Intelligence of Things (AIoT) applications. This paper proposes a framework for real-time monitoring of the energy and carbon footprint impacts of FL systems. The carbon tracking tool is evaluated for consensus (fully decentralized) and classical FL policies. For the first time, we present a quantitative evaluation of different computationally and communication efficient FL methods from the perspectives of energy consumption and carbon equivalent emissions, suggesting also general guidelines for energy-efficient design. Results indicate that consensus-driven FL implementations should be preferred for limiting carbon emissions when the energy efficiency of the communication is low (i.e., < 25 Kbit/Joule). Besides, quantization and sparsification operations are shown to strike a balance between learning performances and energy consumption, leading to sustainable FL designs.
Metrics for popularity bias in dynamic recommender systems
Oct 12, 2023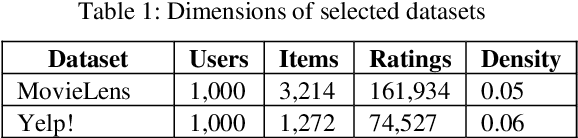
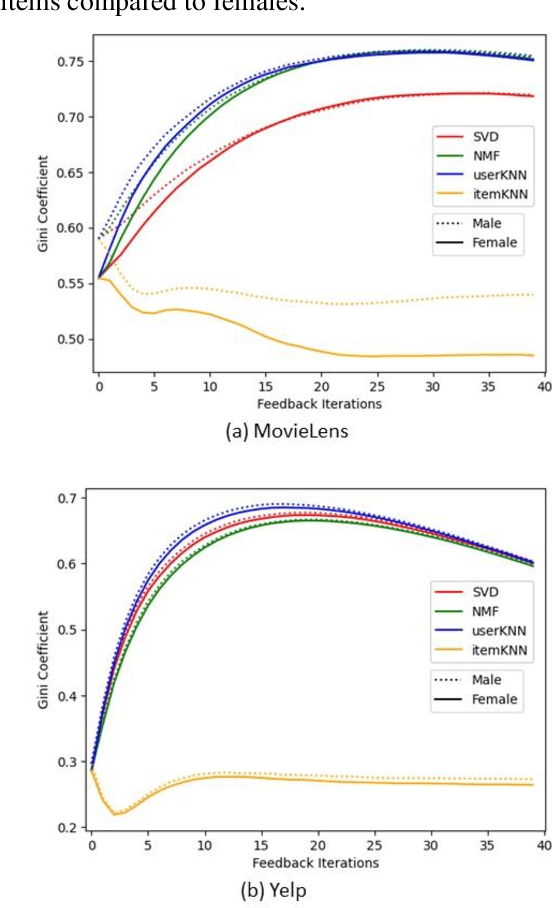
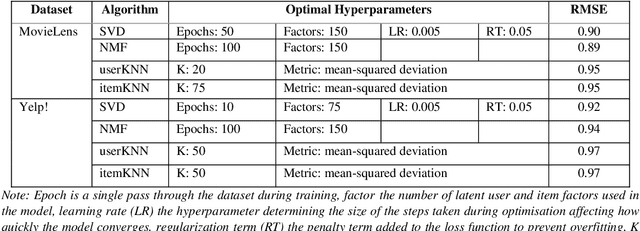
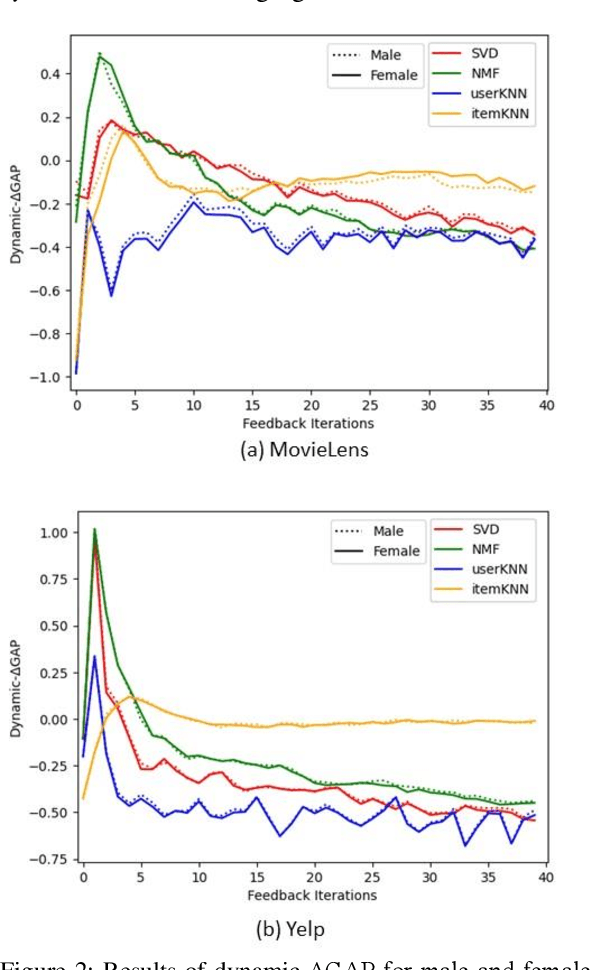
Albeit the widespread application of recommender systems (RecSys) in our daily lives, rather limited research has been done on quantifying unfairness and biases present in such systems. Prior work largely focuses on determining whether a RecSys is discriminating or not but does not compute the amount of bias present in these systems. Biased recommendations may lead to decisions that can potentially have adverse effects on individuals, sensitive user groups, and society. Hence, it is important to quantify these biases for fair and safe commercial applications of these systems. This paper focuses on quantifying popularity bias that stems directly from the output of RecSys models, leading to over recommendation of popular items that are likely to be misaligned with user preferences. Four metrics to quantify popularity bias in RescSys over time in dynamic setting across different sensitive user groups have been proposed. These metrics have been demonstrated for four collaborative filtering based RecSys algorithms trained on two commonly used benchmark datasets in the literature. Results obtained show that the metrics proposed provide a comprehensive understanding of growing disparities in treatment between sensitive groups over time when used conjointly.