 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning an Inventory Control Policy with General Inventory Arrival Dynamics
Oct 26, 2023
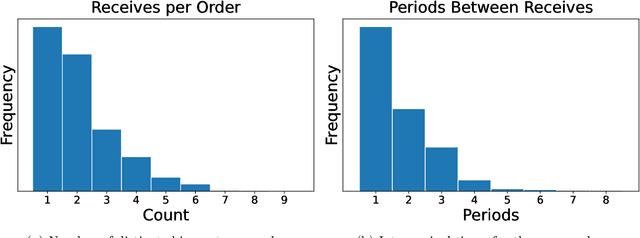
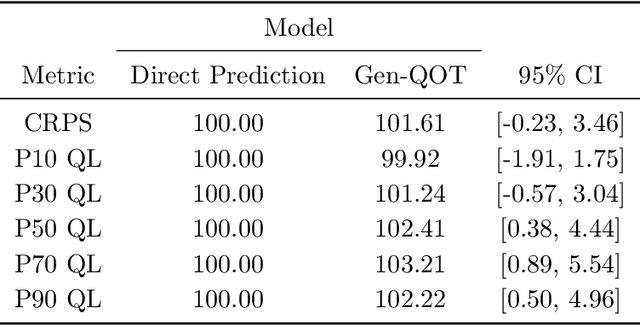
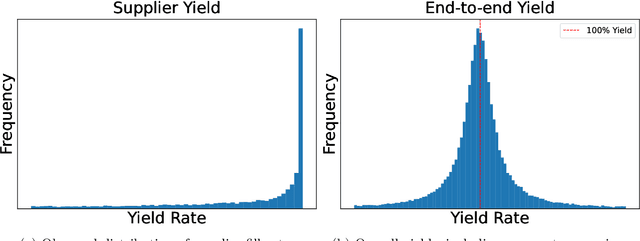
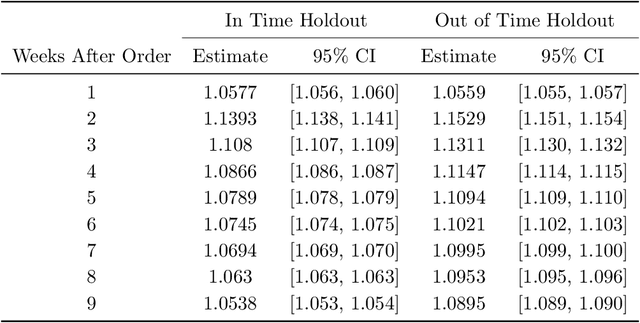
In this paper we address the problem of learning and backtesting inventory control policies in the presence of general arrival dynamics -- which we term as a quantity-over-time arrivals model (QOT). We also allow for order quantities to be modified as a post-processing step to meet vendor constraints such as order minimum and batch size constraints -- a common practice in real supply chains. To the best of our knowledge this is the first work to handle either arbitrary arrival dynamics or an arbitrary downstream post-processing of order quantities. Building upon recent work (Madeka et al., 2022) we similarly formulate the periodic review inventory control problem as an exogenous decision process, where most of the state is outside the control of the agent. Madeka et al. (2022) show how to construct a simulator that replays historic data to solve this class of problem. In our case, we incorporate a deep generative model for the arrivals process as part of the history replay. By formulating the problem as an exogenous decision process, we can apply results from Madeka et al. (2022) to obtain a reduction to supervised learning. Finally, we show via simulation studies that this approach yields statistically significant improvements in profitability over production baselines. Using data from an ongoing real-world A/B test, we show that Gen-QOT generalizes well to off-policy data.
Drive Anywhere: Generalizable End-to-end Autonomous Driving with Multi-modal Foundation Models
Oct 26, 2023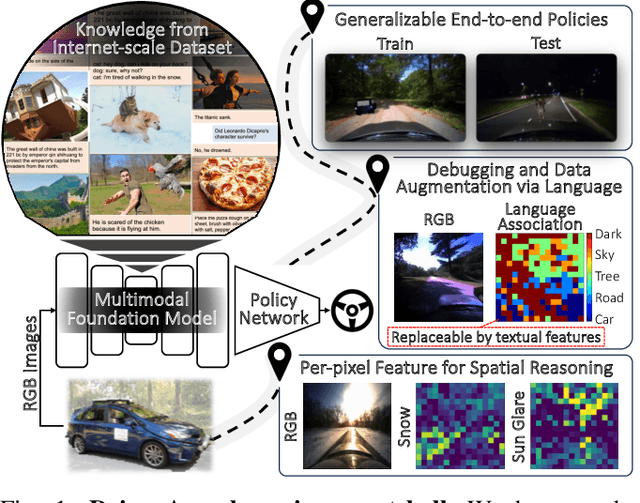
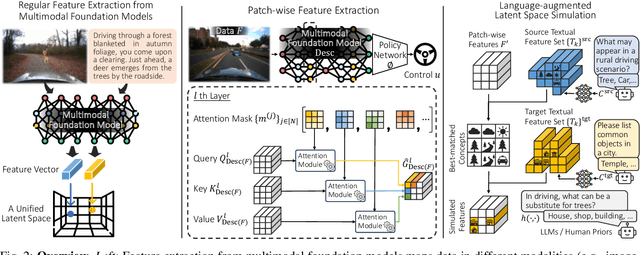
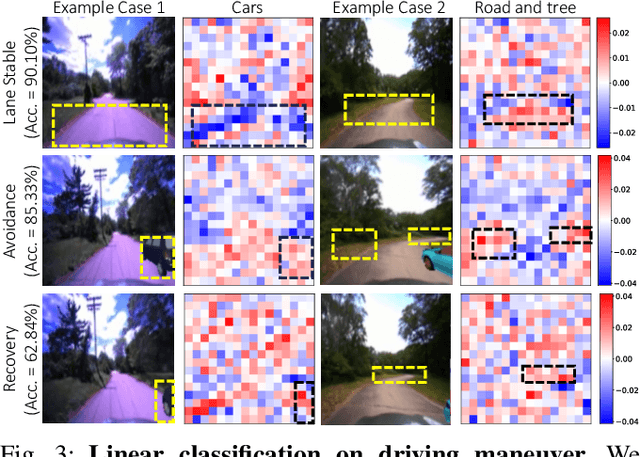
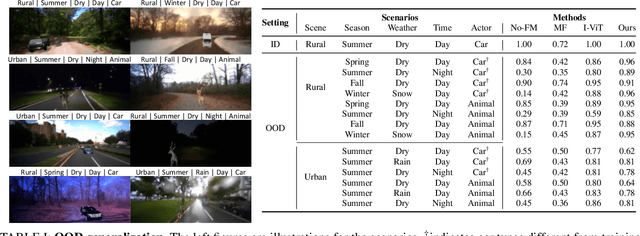
As autonomous driving technology matures, end-to-end methodologies have emerged as a leading strategy, promising seamless integration from perception to control via deep learning. However, existing systems grapple with challenges such as unexpected open set environments and the complexity of black-box models. At the same time, the evolution of deep learning introduces larger, multimodal foundational models, offering multi-modal visual and textual understanding. In this paper, we harness these multimodal foundation models to enhance the robustness and adaptability of autonomous driving systems, enabling out-of-distribution, end-to-end, multimodal, and more explainable autonomy. Specifically, we present an approach to apply end-to-end open-set (any environment/scene) autonomous driving that is capable of providing driving decisions from representations queryable by image and text. To do so, we introduce a method to extract nuanced spatial (pixel/patch-aligned) features from transformers to enable the encapsulation of both spatial and semantic features. Our approach (i) demonstrates unparalleled results in diverse tests while achieving significantly greater robustness in out-of-distribution situations, and (ii) allows the incorporation of latent space simulation (via text) for improved training (data augmentation via text) and policy debugging. We encourage the reader to check our explainer video at https://www.youtube.com/watch?v=4n-DJf8vXxo&feature=youtu.be and to view the code and demos on our project webpage at https://drive-anywhere.github.io/.
CBD: A Certified Backdoor Detector Based on Local Dominant Probability
Oct 26, 2023Backdoor attack is a common threat to deep neural networks. During testing, samples embedded with a backdoor trigger will be misclassified as an adversarial target by a backdoored model, while samples without the backdoor trigger will be correctly classified. In this paper, we present the first certified backdoor detector (CBD), which is based on a novel, adjustable conformal prediction scheme based on our proposed statistic local dominant probability. For any classifier under inspection, CBD provides 1) a detection inference, 2) the condition under which the attacks are guaranteed to be detectable for the same classification domain, and 3) a probabilistic upper bound for the false positive rate. Our theoretical results show that attacks with triggers that are more resilient to test-time noise and have smaller perturbation magnitudes are more likely to be detected with guarantees. Moreover, we conduct extensive experiments on four benchmark datasets considering various backdoor types, such as BadNet, CB, and Blend. CBD achieves comparable or even higher detection accuracy than state-of-the-art detectors, and it in addition provides detection certification. Notably, for backdoor attacks with random perturbation triggers bounded by $\ell_2\leq0.75$ which achieves more than 90\% attack success rate, CBD achieves 100\% (98\%), 100\% (84\%), 98\% (98\%), and 72\% (40\%) empirical (certified) detection true positive rates on the four benchmark datasets GTSRB, SVHN, CIFAR-10, and TinyImageNet, respectively, with low false positive rates.
Variance of ML-based software fault predictors: are we really improving fault prediction?
Oct 26, 2023Software quality assurance activities become increasingly difficult as software systems become more and more complex and continuously grow in size. Moreover, testing becomes even more expensive when dealing with large-scale systems. Thus, to effectively allocate quality assurance resources, researchers have proposed fault prediction (FP) which utilizes machine learning (ML) to predict fault-prone code areas. However, ML algorithms typically make use of stochastic elements to increase the prediction models' generalizability and efficiency of the training process. These stochastic elements, also known as nondeterminism-introducing (NI) factors, lead to variance in the training process and as a result, lead to variance in prediction accuracy and training time. This variance poses a challenge for reproducibility in research. More importantly, while fault prediction models may have shown good performance in the lab (e.g., often-times involving multiple runs and averaging outcomes), high variance of results can pose the risk that these models show low performance when applied in practice. In this work, we experimentally analyze the variance of a state-of-the-art fault prediction approach. Our experimental results indicate that NI factors can indeed cause considerable variance in the fault prediction models' accuracy. We observed a maximum variance of 10.10% in terms of the per-class accuracy metric. We thus, also discuss how to deal with such variance.
What You See Is What You Detect: Towards better Object Densification in 3D detection
Oct 27, 2023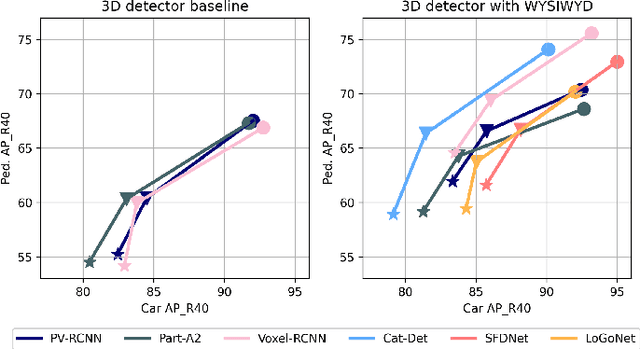
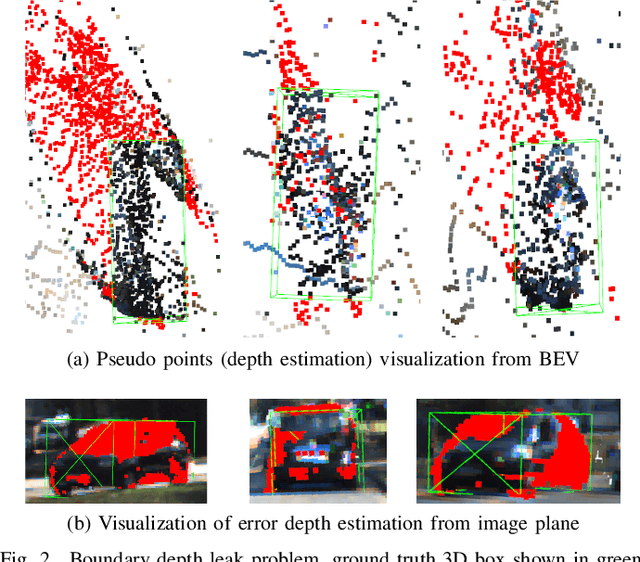

Recent works have demonstrated the importance of object completion in 3D Perception from Lidar signal. Several methods have been proposed in which modules were used to densify the point clouds produced by laser scanners, leading to better recall and more accurate results. Pursuing in that direction, we present, in this work, a counter-intuitive perspective: the widely-used full-shape completion approach actually leads to a higher error-upper bound especially for far away objects and small objects like pedestrians. Based on this observation, we introduce a visible part completion method that requires only 11.3\% of the prediction points that previous methods generate. To recover the dense representation, we propose a mesh-deformation-based method to augment the point set associated with visible foreground objects. Considering that our approach focuses only on the visible part of the foreground objects to achieve accurate 3D detection, we named our method What You See Is What You Detect (WYSIWYD). Our proposed method is thus a detector-independent model that consists of 2 parts: an Intra-Frustum Segmentation Transformer (IFST) and a Mesh Depth Completion Network(MDCNet) that predicts the foreground depth from mesh deformation. This way, our model does not require the time-consuming full-depth completion task used by most pseudo-lidar-based methods. Our experimental evaluation shows that our approach can provide up to 12.2\% performance improvements over most of the public baseline models on the KITTI and NuScenes dataset bringing the state-of-the-art to a new level. The codes will be available at \textcolor[RGB]{0,0,255}{\url{{https://github.com/Orbis36/WYSIWYD}}
A Novel Skip Orthogonal List for Dynamic Optimal Transport Problem
Oct 27, 2023Optimal transportation is a fundamental topic that has attracted a great amount of attention from machine learning community in the past decades. In this paper, we consider an interesting discrete dynamic optimal transport problem: can we efficiently update the optimal transport plan when the weights or the locations of the data points change? This problem is naturally motivated by several applications in machine learning. For example, we often need to compute the optimal transportation cost between two different data sets; if some change happens to a few data points, should we re-compute the high complexity cost function or update the cost by some efficient dynamic data structure? We are aware that several dynamic maximum flow algorithms have been proposed before, however, the research on dynamic minimum cost flow problem is still quite limited, to the best of our knowledge. We propose a novel 2D Skip Orthogonal List together with some dynamic tree techniques. Although our algorithm is based on the conventional simplex method, it can efficiently complete each pivoting operation within $O(|V|)$ time with high probability where $V$ is the set of all supply and demand nodes. Since dynamic modifications typically do not introduce significant changes, our algorithm requires only a few simplex iterations in practice. So our algorithm is more efficient than re-computing the optimal transportation cost that needs at least one traversal over all the $O(|E|) = O(|V|^2)$ variables in general cases. Our experiments demonstrate that our algorithm significantly outperforms existing algorithms in the dynamic scenarios.
$\textit{Swap and Predict}$ -- Predicting the Semantic Changes in Words across Corpora by Context Swapping
Oct 16, 2023Meanings of words change over time and across domains. Detecting the semantic changes of words is an important task for various NLP applications that must make time-sensitive predictions. We consider the problem of predicting whether a given target word, $w$, changes its meaning between two different text corpora, $\mathcal{C}_1$ and $\mathcal{C}_2$. For this purpose, we propose $\textit{Swapping-based Semantic Change Detection}$ (SSCD), an unsupervised method that randomly swaps contexts between $\mathcal{C}_1$ and $\mathcal{C}_2$ where $w$ occurs. We then look at the distribution of contextualised word embeddings of $w$, obtained from a pretrained masked language model (MLM), representing the meaning of $w$ in its occurrence contexts in $\mathcal{C}_1$ and $\mathcal{C}_2$. Intuitively, if the meaning of $w$ does not change between $\mathcal{C}_1$ and $\mathcal{C}_2$, we would expect the distributions of contextualised word embeddings of $w$ to remain the same before and after this random swapping process. Despite its simplicity, we demonstrate that even by using pretrained MLMs without any fine-tuning, our proposed context swapping method accurately predicts the semantic changes of words in four languages (English, German, Swedish, and Latin) and across different time spans (over 50 years and about five years). Moreover, our method achieves significant performance improvements compared to strong baselines for the English semantic change prediction task. Source code is available at https://github.com/a1da4/svp-swap .
Language Models Hallucinate, but May Excel at Fact Verification
Oct 23, 2023Recent progress in natural language processing (NLP) owes much to remarkable advances in large language models (LLMs). Nevertheless, LLMs frequently "hallucinate," resulting in non-factual outputs. Our carefully designed human evaluation substantiates the serious hallucination issue, revealing that even GPT-3.5 produces factual outputs less than 25% of the time. This underscores the importance of fact verifiers in order to measure and incentivize progress. Our systematic investigation affirms that LLMs can be repurposed as effective fact verifiers with strong correlations with human judgments, at least in the Wikipedia domain. Surprisingly, FLAN-T5-11B, the least factual generator in our study, performs the best as a fact verifier, even outperforming more capable LLMs like GPT3.5 and ChatGPT. Delving deeper, we analyze the reliance of these LLMs on high-quality evidence, as well as their deficiencies in robustness and generalization ability. Our study presents insights for developing trustworthy generation models.
Efficient Causal Discovery for Robotics Applications
Oct 23, 2023Using robots for automating tasks in environments shared with humans, such as warehouses, shopping centres, or hospitals, requires these robots to comprehend the fundamental physical interactions among nearby agents and objects. Specifically, creating models to represent cause-and-effect relationships among these elements can aid in predicting unforeseen human behaviours and anticipate the outcome of particular robot actions. To be suitable for robots, causal analysis must be both fast and accurate, meeting real-time demands and the limited computational resources typical in most robotics applications. In this paper, we present a practical demonstration of our approach for fast and accurate causal analysis, known as Filtered~PCMCI~(F-PCMCI), along with a real-world robotics application. The provided application illustrates how our F-PCMCI can accurately and promptly reconstruct the causal model of a human-robot interaction scenario, which can then be leveraged to enhance the quality of the interaction.
Learning spatio-temporal patterns with Neural Cellular Automata
Oct 23, 2023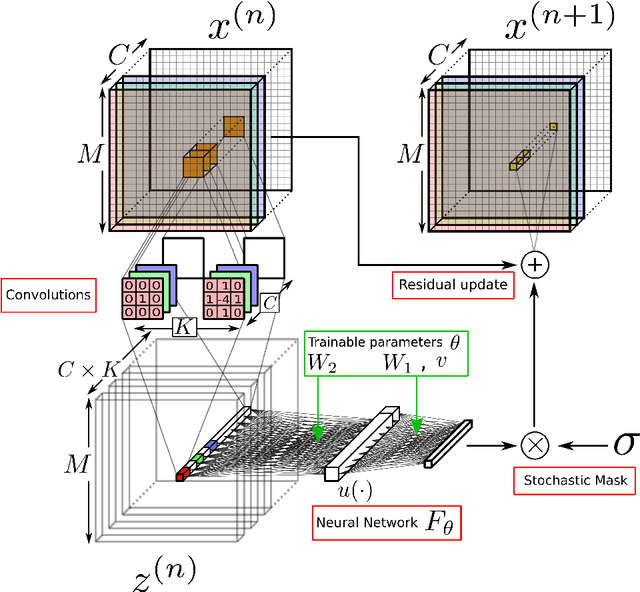
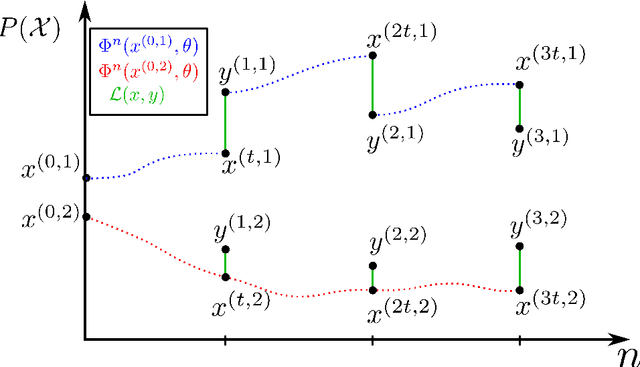
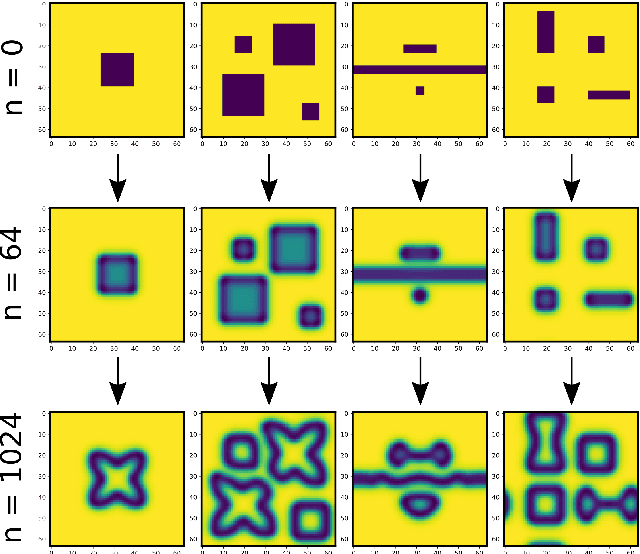
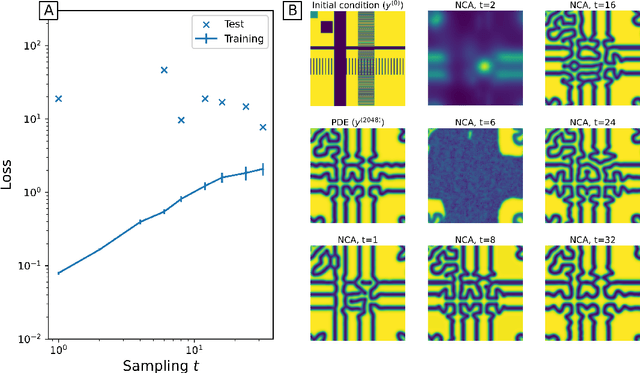
Neural Cellular Automata (NCA) are a powerful combination of machine learning and mechanistic modelling. We train NCA to learn complex dynamics from time series of images and PDE trajectories. Our method is designed to identify underlying local rules that govern large scale dynamic emergent behaviours. Previous work on NCA focuses on learning rules that give stationary emergent structures. We extend NCA to capture both transient and stable structures within the same system, as well as learning rules that capture the dynamics of Turing pattern formation in nonlinear Partial Differential Equations (PDEs). We demonstrate that NCA can generalise very well beyond their PDE training data, we show how to constrain NCA to respect given symmetries, and we explore the effects of associated hyperparameters on model performance and stability. Being able to learn arbitrary dynamics gives NCA great potential as a data driven modelling framework, especially for modelling biological pattern formation.