 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fuel Consumption Prediction for a Passenger Ferry using Machine Learning and In-service Data: A Comparative Study
Oct 19, 2023


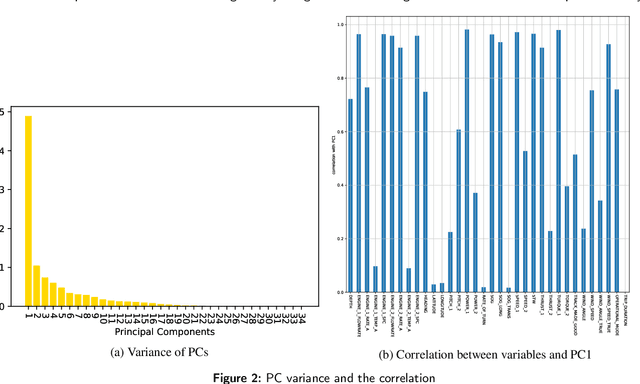
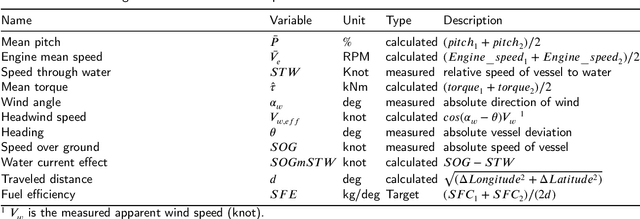
As the importance of eco-friendly transportation increases, providing an efficient approach for marine vessel operation is essential. Methods for status monitoring with consideration to the weather condition and forecasting with the use of in-service data from ships requires accurate and complete models for predicting the energy efficiency of a ship. The models need to effectively process all the operational data in real-time. This paper presents models that can predict fuel consumption using in-service data collected from a passenger ship. Statistical and domain-knowledge methods were used to select the proper input variables for the models. These methods prevent over-fitting, missing data, and multicollinearity while providing practical applicability. Prediction models that were investigated include multiple linear regression (MLR), decision tree approach (DT), an artificial neural network (ANN), and ensemble methods. The best predictive performance was from a model developed using the XGboost technique which is a boosting ensemble approach. \rvv{Our code is available on GitHub at \url{https://github.com/pagand/model_optimze_vessel/tree/OE} for future research.
* 20 pages, 11 figures, 7 tables
Mixing Histopathology Prototypes into Robust Slide-Level Representations for Cancer Subtyping
Oct 19, 2023Whole-slide image analysis via the means of computational pathology often relies on processing tessellated gigapixel images with only slide-level labels available. Applying multiple instance learning-based methods or transformer models is computationally expensive as, for each image, all instances have to be processed simultaneously. The MLP-Mixer is an under-explored alternative model to common vision transformers, especially for large-scale datasets. Due to the lack of a self-attention mechanism, they have linear computational complexity to the number of input patches but achieve comparable performance on natural image datasets. We propose a combination of feature embedding and clustering to preprocess the full whole-slide image into a reduced prototype representation which can then serve as input to a suitable MLP-Mixer architecture. Our experiments on two public benchmarks and one inhouse malignant lymphoma dataset show comparable performance to current state-of-the-art methods, while achieving lower training costs in terms of computational time and memory load. Code is publicly available at https://github.com/butkej/ProtoMixer.
* The final authenticated publication is available online at https://doi.org/10.1007/978-3-031-45676-3_12
Putting the Object Back into Video Object Segmentation
Oct 19, 2023We present Cutie, a video object segmentation (VOS) network with object-level memory reading, which puts the object representation from memory back into the video object segmentation result. Recent works on VOS employ bottom-up pixel-level memory reading which struggles due to matching noise, especially in the presence of distractors, resulting in lower performance in more challenging data. In contrast, Cutie performs top-down object-level memory reading by adapting a small set of object queries for restructuring and interacting with the bottom-up pixel features iteratively with a query-based object transformer (qt, hence Cutie). The object queries act as a high-level summary of the target object, while high-resolution feature maps are retained for accurate segmentation. Together with foreground-background masked attention, Cutie cleanly separates the semantics of the foreground object from the background. On the challenging MOSE dataset, Cutie improves by 8.7 J&F over XMem with a similar running time and improves by 4.2 J&F over DeAOT while running three times as fast. Code is available at: https://hkchengrex.github.io/Cutie
Representation Learning via Consistent Assignment of Views over Random Partitions
Oct 19, 2023We present Consistent Assignment of Views over Random Partitions (CARP), a self-supervised clustering method for representation learning of visual features. CARP learns prototypes in an end-to-end online fashion using gradient descent without additional non-differentiable modules to solve the cluster assignment problem. CARP optimizes a new pretext task based on random partitions of prototypes that regularizes the model and enforces consistency between views' assignments. Additionally, our method improves training stability and prevents collapsed solutions in joint-embedding training. Through an extensive evaluation, we demonstrate that CARP's representations are suitable for learning downstream tasks. We evaluate CARP's representations capabilities in 17 datasets across many standard protocols, including linear evaluation, few-shot classification, k-NN, k-means, image retrieval, and copy detection. We compare CARP performance to 11 existing self-supervised methods. We extensively ablate our method and demonstrate that our proposed random partition pretext task improves the quality of the learned representations by devising multiple random classification tasks. In transfer learning tasks, CARP achieves the best performance on average against many SSL methods trained for a longer time.
Spatially-resolved hyperlocal weather prediction and anomaly detection using IoT sensor networks and machine learning techniques
Oct 17, 2023Accurate and timely hyperlocal weather predictions are essential for various applications, ranging from agriculture to disaster management. In this paper, we propose a novel approach that combines hyperlocal weather prediction and anomaly detection using IoT sensor networks and advanced machine learning techniques. Our approach leverages data from multiple spatially-distributed yet relatively close locations and IoT sensors to create high-resolution weather models capable of predicting short-term, localized weather conditions such as temperature, pressure, and humidity. By monitoring changes in weather parameters across these locations, our system is able to enhance the spatial resolution of predictions and effectively detect anomalies in real-time. Additionally, our system employs unsupervised learning algorithms to identify unusual weather patterns, providing timely alerts. Our findings indicate that this system has the potential to enhance decision-making.
MacFormer: Map-Agent Coupled Transformer for Real-time and Robust Trajectory Prediction
Aug 31, 2023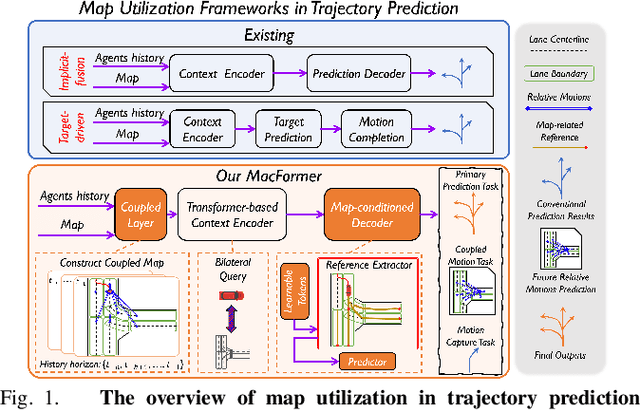
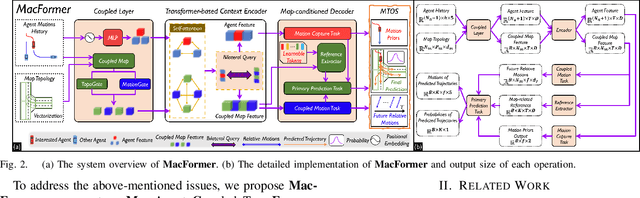
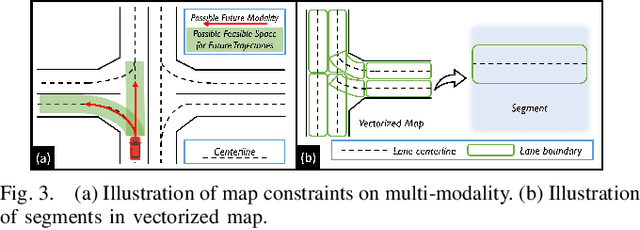
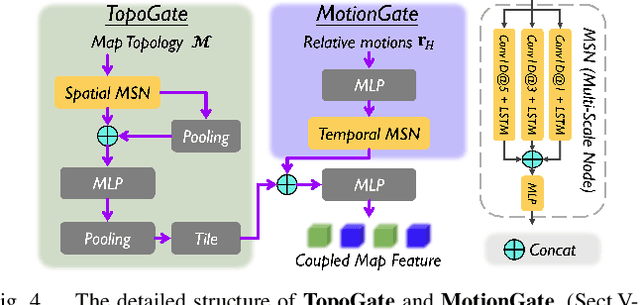
Predicting the future behavior of agents is a fundamental task in autonomous vehicle domains. Accurate prediction relies on comprehending the surrounding map, which significantly regularizes agent behaviors. However, existing methods have limitations in exploiting the map and exhibit a strong dependence on historical trajectories, which yield unsatisfactory prediction performance and robustness. Additionally, their heavy network architectures impede real-time applications. To tackle these problems, we propose Map-Agent Coupled Transformer (MacFormer) for real-time and robust trajectory prediction. Our framework explicitly incorporates map constraints into the network via two carefully designed modules named coupled map and reference extractor. A novel multi-task optimization strategy (MTOS) is presented to enhance learning of topology and rule constraints. We also devise bilateral query scheme in context fusion for a more efficient and lightweight network. We evaluated our approach on Argoverse 1, Argoverse 2, and nuScenes real-world benchmarks, where it all achieved state-of-the-art performance with the lowest inference latency and smallest model size. Experiments also demonstrate that our framework is resilient to imperfect tracklet inputs. Furthermore, we show that by combining with our proposed strategies, classical models outperform their baselines, further validating the versatility of our framework.
Attentive Multi-Layer Perceptron for Non-autoregressive Generation
Oct 14, 2023Autoregressive~(AR) generation almost dominates sequence generation for its efficacy. Recently, non-autoregressive~(NAR) generation gains increasing popularity for its efficiency and growing efficacy. However, its efficiency is still bottlenecked by quadratic complexity in sequence lengths, which is prohibitive for scaling to long sequence generation and few works have been done to mitigate this problem. In this paper, we propose a novel MLP variant, \textbf{A}ttentive \textbf{M}ulti-\textbf{L}ayer \textbf{P}erceptron~(AMLP), to produce a generation model with linear time and space complexity. Different from classic MLP with static and learnable projection matrices, AMLP leverages adaptive projections computed from inputs in an attentive mode. The sample-aware adaptive projections enable communications among tokens in a sequence, and model the measurement between the query and key space. Furthermore, we marry AMLP with popular NAR models, deriving a highly efficient NAR-AMLP architecture with linear time and space complexity. Empirical results show that such marriage architecture surpasses competitive efficient NAR models, by a significant margin on text-to-speech synthesis and machine translation. We also test AMLP's self- and cross-attention ability separately with extensive ablation experiments, and find them comparable or even superior to the other efficient models. The efficiency analysis further shows that AMLP extremely reduces the memory cost against vanilla non-autoregressive models for long sequences.
XAI for Early Crop Classification
Oct 10, 2023We propose an approach for early crop classification through identifying important timesteps with eXplainable AI (XAI) methods. Our approach consists of training a baseline crop classification model to carry out layer-wise relevance propagation (LRP) so that the salient time step can be identified. We chose a selected number of such important time indices to create the bounding region of the shortest possible classification timeframe. We identified the period 21st April 2019 to 9th August 2019 as having the best trade-off in terms of accuracy and earliness. This timeframe only suffers a 0.75% loss in accuracy as compared to using the full timeseries. We observed that the LRP-derived important timesteps also highlight small details in input values that differentiates between different classes and
Equivariant Bootstrapping for Uncertainty Quantification in Imaging Inverse Problems
Oct 20, 2023Scientific imaging problems are often severely ill-posed, and hence have significant intrinsic uncertainty. Accurately quantifying the uncertainty in the solutions to such problems is therefore critical for the rigorous interpretation of experimental results as well as for reliably using the reconstructed images as scientific evidence. Unfortunately, existing imaging methods are unable to quantify the uncertainty in the reconstructed images in a manner that is robust to experiment replications. This paper presents a new uncertainty quantification methodology based on an equivariant formulation of the parametric bootstrap algorithm that leverages symmetries and invariance properties commonly encountered in imaging problems. Additionally, the proposed methodology is general and can be easily applied with any image reconstruction technique, including unsupervised training strategies that can be trained from observed data alone, thus enabling uncertainty quantification in situations where there is no ground truth data available. We demonstrate the proposed approach with a series of numerical experiments and through comparisons with alternative uncertainty quantification strategies from the state-of-the-art, such as Bayesian strategies involving score-based diffusion models and Langevin samplers. In all our experiments, the proposed method delivers remarkably accurate high-dimensional confidence regions and outperforms the competing approaches in terms of estimation accuracy, uncertainty quantification accuracy, and computing time.
Enhancing Cross-Dataset Performance of Distracted Driving Detection With Score-Softmax Classifier
Oct 20, 2023Deep neural networks enable real-time monitoring of in-vehicle driver, facilitating the timely prediction of distractions, fatigue, and potential hazards. This technology is now integral to intelligent transportation systems. Recent research has exposed unreliable cross-dataset end-to-end driver behavior recognition due to overfitting, often referred to as ``shortcut learning", resulting from limited data samples. In this paper, we introduce the Score-Softmax classifier, which addresses this issue by enhancing inter-class independence and Intra-class uncertainty. Motivated by human rating patterns, we designed a two-dimensional supervisory matrix based on marginal Gaussian distributions to train the classifier. Gaussian distributions help amplify intra-class uncertainty while ensuring the Score-Softmax classifier learns accurate knowledge. Furthermore, leveraging the summation of independent Gaussian distributed random variables, we introduced a multi-channel information fusion method. This strategy effectively resolves the multi-information fusion challenge for the Score-Softmax classifier. Concurrently, we substantiate the necessity of transfer learning and multi-dataset combination. We conducted cross-dataset experiments using the SFD, AUCDD-V1, and 100-Driver datasets, demonstrating that Score-Softmax improves cross-dataset performance without modifying the model architecture. This provides a new approach for enhancing neural network generalization. Additionally, our information fusion approach outperforms traditional methods.