 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
UniAV: Unified Audio-Visual Perception for Multi-Task Video Localization
Apr 04, 2024
Video localization tasks aim to temporally locate specific instances in videos, including temporal action localization (TAL), sound event detection (SED) and audio-visual event localization (AVEL). Existing methods over-specialize on each task, overlooking the fact that these instances often occur in the same video to form the complete video content. In this work, we present UniAV, a Unified Audio-Visual perception network, to achieve joint learning of TAL, SED and AVEL tasks for the first time. UniAV can leverage diverse data available in task-specific datasets, allowing the model to learn and share mutually beneficial knowledge across tasks and modalities. To tackle the challenges posed by substantial variations in datasets (size/domain/duration) and distinct task characteristics, we propose to uniformly encode visual and audio modalities of all videos to derive generic representations, while also designing task-specific experts to capture unique knowledge for each task. Besides, we develop a unified language-aware classifier by utilizing a pre-trained text encoder, enabling the model to flexibly detect various types of instances and previously unseen ones by simply changing prompts during inference. UniAV outperforms its single-task counterparts by a large margin with fewer parameters, achieving on-par or superior performances compared to state-of-the-art task-specific methods across ActivityNet 1.3, DESED and UnAV-100 benchmarks.
GaSpCT: Gaussian Splatting for Novel CT Projection View Synthesis
Apr 04, 2024We present GaSpCT, a novel view synthesis and 3D scene representation method used to generate novel projection views for Computer Tomography (CT) scans. We adapt the Gaussian Splatting framework to enable novel view synthesis in CT based on limited sets of 2D image projections and without the need for Structure from Motion (SfM) methodologies. Therefore, we reduce the total scanning duration and the amount of radiation dose the patient receives during the scan. We adapted the loss function to our use-case by encouraging a stronger background and foreground distinction using two sparsity promoting regularizers: a beta loss and a total variation (TV) loss. Finally, we initialize the Gaussian locations across the 3D space using a uniform prior distribution of where the brain's positioning would be expected to be within the field of view. We evaluate the performance of our model using brain CT scans from the Parkinson's Progression Markers Initiative (PPMI) dataset and demonstrate that the rendered novel views closely match the original projection views of the simulated scan, and have better performance than other implicit 3D scene representations methodologies. Furthermore, we empirically observe reduced training time compared to neural network based image synthesis for sparse-view CT image reconstruction. Finally, the memory requirements of the Gaussian Splatting representations are reduced by 17% compared to the equivalent voxel grid image representations.
How Much Data are Enough? Investigating Dataset Requirements for Patch-Based Brain MRI Segmentation Tasks
Apr 04, 2024Training deep neural networks reliably requires access to large-scale datasets. However, obtaining such datasets can be challenging, especially in the context of neuroimaging analysis tasks, where the cost associated with image acquisition and annotation can be prohibitive. To mitigate both the time and financial costs associated with model development, a clear understanding of the amount of data required to train a satisfactory model is crucial. This paper focuses on an early stage phase of deep learning research, prior to model development, and proposes a strategic framework for estimating the amount of annotated data required to train patch-based segmentation networks. This framework includes the establishment of performance expectations using a novel Minor Boundary Adjustment for Threshold (MinBAT) method, and standardizing patch selection through the ROI-based Expanded Patch Selection (REPS) method. Our experiments demonstrate that tasks involving regions of interest (ROIs) with different sizes or shapes may yield variably acceptable Dice Similarity Coefficient (DSC) scores. By setting an acceptable DSC as the target, the required amount of training data can be estimated and even predicted as data accumulates. This approach could assist researchers and engineers in estimating the cost associated with data collection and annotation when defining a new segmentation task based on deep neural networks, ultimately contributing to their efficient translation to real-world applications.
Do language models plan ahead for future tokens?
Apr 01, 2024Do transformers "think ahead" during inference at a given position? It is known transformers prepare information in the hidden states of the forward pass at $t$ that is then used in future forward passes $t+\tau$. We posit two explanations for this phenomenon: pre-caching, in which off-diagonal gradient terms present in training result in the model computing features at $t$ irrelevant to the present inference task but useful for the future, and breadcrumbs, in which features most relevant to time step $t$ are already the same as those that would most benefit inference at time $t+\tau$. We test these hypotheses by training language models without propagating gradients to past timesteps, a scheme we formalize as myopic training. In a synthetic data setting, we find clear evidence for pre-caching. In the autoregressive language modeling setting, our experiments are more suggestive of the breadcrumbs hypothesis.
CODA: A COst-efficient Test-time Domain Adaptation Mechanism for HAR
Mar 22, 2024In recent years, emerging research on mobile sensing has led to novel scenarios that enhance daily life for humans, but dynamic usage conditions often result in performance degradation when systems are deployed in real-world settings. Existing solutions typically employ one-off adaptation schemes based on neural networks, which struggle to ensure robustness against uncertain drifting conditions in human-centric sensing scenarios. In this paper, we propose CODA, a COst-efficient Domain Adaptation mechanism for mobile sensing that addresses real-time drifts from the data distribution perspective with active learning theory, ensuring cost-efficient adaptation directly on the device. By incorporating a clustering loss and importance-weighted active learning algorithm, CODA retains the relationship between different clusters during cost-effective instance-level updates, preserving meaningful structure within the data distribution. We also showcase its generalization by seamlessly integrating it with Neural Network-based solutions for Human Activity Recognition tasks. Through meticulous evaluations across diverse datasets, including phone-based, watch-based, and integrated sensor-based sensing tasks, we demonstrate the feasibility and potential of online adaptation with CODA. The promising results achieved by CODA, even without learnable parameters, also suggest the possibility of realizing unobtrusive adaptation through specific application designs with sufficient feedback.
Advancing multivariate time series similarity assessment: an integrated computational approach
Mar 16, 2024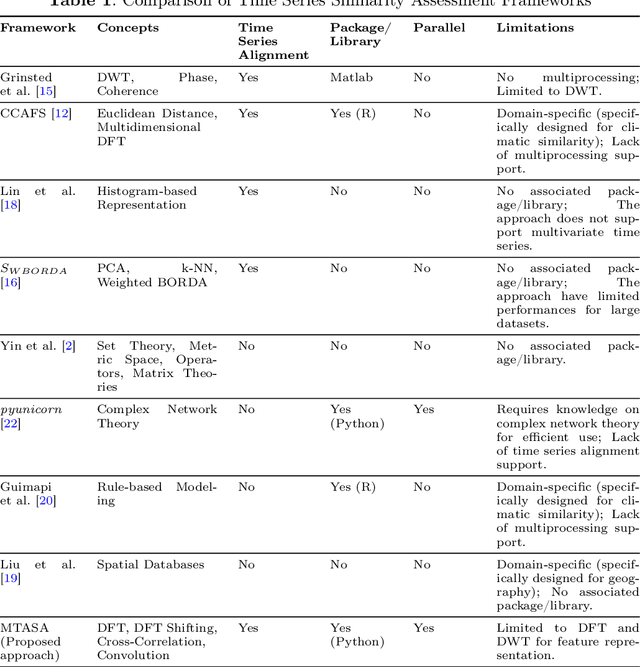
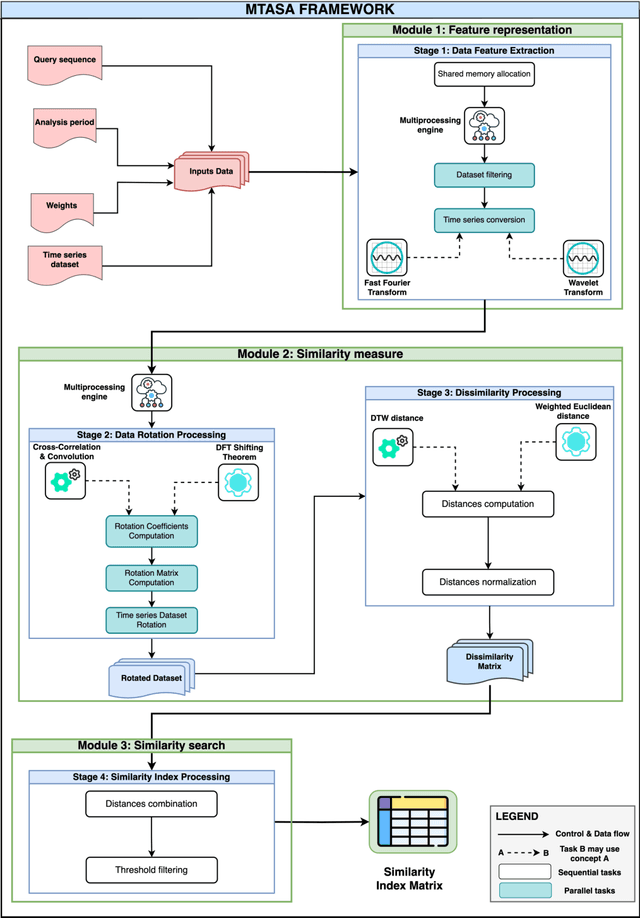
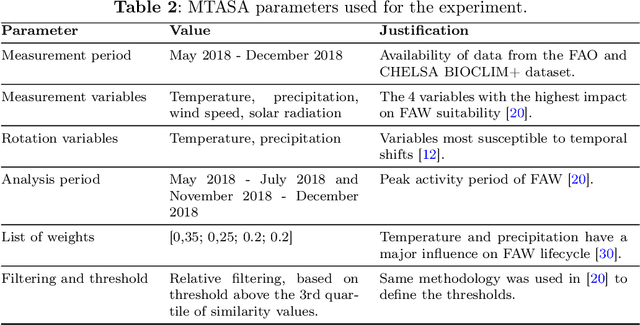
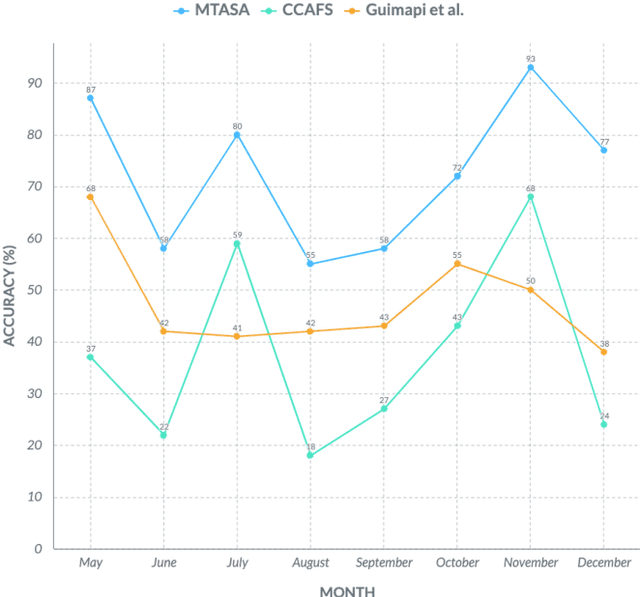
Data mining, particularly the analysis of multivariate time series data, plays a crucial role in extracting insights from complex systems and supporting informed decision-making across diverse domains. However, assessing the similarity of multivariate time series data presents several challenges, including dealing with large datasets, addressing temporal misalignments, and the need for efficient and comprehensive analytical frameworks. To address all these challenges, we propose a novel integrated computational approach known as Multivariate Time series Alignment and Similarity Assessment (MTASA). MTASA is built upon a hybrid methodology designed to optimize time series alignment, complemented by a multiprocessing engine that enhances the utilization of computational resources. This integrated approach comprises four key components, each addressing essential aspects of time series similarity assessment, thereby offering a comprehensive framework for analysis. MTASA is implemented as an open-source Python library with a user-friendly interface, making it accessible to researchers and practitioners. To evaluate the effectiveness of MTASA, we conducted an empirical study focused on assessing agroecosystem similarity using real-world environmental data. The results from this study highlight MTASA's superiority, achieving approximately 1.5 times greater accuracy and twice the speed compared to existing state-of-the-art integrated frameworks for multivariate time series similarity assessment. It is hoped that MTASA will significantly enhance the efficiency and accessibility of multivariate time series analysis, benefitting researchers and practitioners across various domains. Its capabilities in handling large datasets, addressing temporal misalignments, and delivering accurate results make MTASA a valuable tool for deriving insights and aiding decision-making processes in complex systems.
Robust Pronoun Use Fidelity with English LLMs: Are they Reasoning, Repeating, or Just Biased?
Apr 04, 2024Robust, faithful and harm-free pronoun use for individuals is an important goal for language models as their use increases, but prior work tends to study only one or two of these components at a time. To measure progress towards the combined goal, we introduce the task of pronoun use fidelity: given a context introducing a co-referring entity and pronoun, the task is to reuse the correct pronoun later, independent of potential distractors. We present a carefully-designed dataset of over 5 million instances to evaluate pronoun use fidelity in English, and we use it to evaluate 37 popular large language models across architectures (encoder-only, decoder-only and encoder-decoder) and scales (11M-70B parameters). We find that while models can mostly faithfully reuse previously-specified pronouns in the presence of no distractors, they are significantly worse at processing she/her/her, singular they and neopronouns. Additionally, models are not robustly faithful to pronouns, as they are easily distracted. With even one additional sentence containing a distractor pronoun, accuracy drops on average by 34%. With 5 distractor sentences, accuracy drops by 52% for decoder-only models and 13% for encoder-only models. We show that widely-used large language models are still brittle, with large gaps in reasoning and in processing different pronouns in a setting that is very simple for humans, and we encourage researchers in bias and reasoning to bridge them.
Site-specific Deterministic Temperature and Humidity Forecasts with Explainable and Reliable Machine Learning
Apr 04, 2024Site-specific weather forecasts are essential to accurate prediction of power demand and are consequently of great interest to energy operators. However, weather forecasts from current numerical weather prediction (NWP) models lack the fine-scale detail to capture all important characteristics of localised real-world sites. Instead they provide weather information representing a rectangular gridbox (usually kilometres in size). Even after post-processing and bias correction, area-averaged information is usually not optimal for specific sites. Prior work on site optimised forecasts has focused on linear methods, weighted consensus averaging, time-series methods, and others. Recent developments in machine learning (ML) have prompted increasing interest in applying ML as a novel approach towards this problem. In this study, we investigate the feasibility of optimising forecasts at sites by adopting the popular machine learning model gradient boosting decision tree, supported by the Python version of the XGBoost package. Regression trees have been trained with historical NWP and site observations as training data, aimed at predicting temperature and dew point at multiple site locations across Australia. We developed a working ML framework, named 'Multi-SiteBoost' and initial testing results show a significant improvement compared with gridded values from bias-corrected NWP models. The improvement from XGBoost is found to be comparable with non-ML methods reported in literature. With the insights provided by SHapley Additive exPlanations (SHAP), this study also tests various approaches to understand the ML predictions and increase the reliability of the forecasts generated by ML.
An Integrating Comprehensive Trajectory Prediction with Risk Potential Field Method for Autonomous Driving
Apr 01, 2024Due to the uncertainty of traffic participants' intentions, generating safe but not overly cautious behavior in interactive driving scenarios remains a formidable challenge for autonomous driving. In this paper, we address this issue by combining a deep learning-based trajectory prediction model with risk potential field-based motion planning. In order to comprehensively predict the possible future trajectories of other vehicles, we propose a target-region based trajectory prediction model(TRTP) which considers every region a vehicle may arrive in the future. After that, we construct a risk potential field at each future time step based on the prediction results of TRTP, and integrate risk value to the objective function of Model Predictive Contouring Control(MPCC). This enables the uncertainty of other vehicles to be taken into account during the planning process. Balancing between risk and progress along the reference path can achieve both driving safety and efficiency at the same time. We also demonstrate the security and effectiveness performance of our method in the CARLA simulator.
NVINS: Robust Visual Inertial Navigation Fused with NeRF-augmented Camera Pose Regressor and Uncertainty Quantification
Apr 01, 2024In recent years, Neural Radiance Fields (NeRF) have emerged as a powerful tool for 3D reconstruction and novel view synthesis. However, the computational cost of NeRF rendering and degradation in quality due to the presence of artifacts pose significant challenges for its application in real-time and robust robotic tasks, especially on embedded systems. This paper introduces a novel framework that integrates NeRF-derived localization information with Visual-Inertial Odometry(VIO) to provide a robust solution for robotic navigation in a real-time. By training an absolute pose regression network with augmented image data rendered from a NeRF and quantifying its uncertainty, our approach effectively counters positional drift and enhances system reliability. We also establish a mathematically sound foundation for combining visual inertial navigation with camera localization neural networks, considering uncertainty under a Bayesian framework. Experimental validation in the photorealistic simulation environment demonstrates significant improvements in accuracy compared to a conventional VIO approach.