 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Heterogeneous Graph Learning via Random Projection
Oct 23, 2023
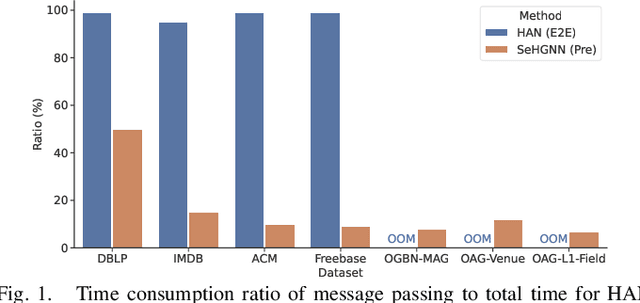
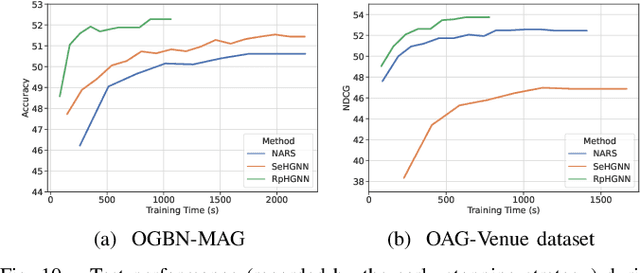
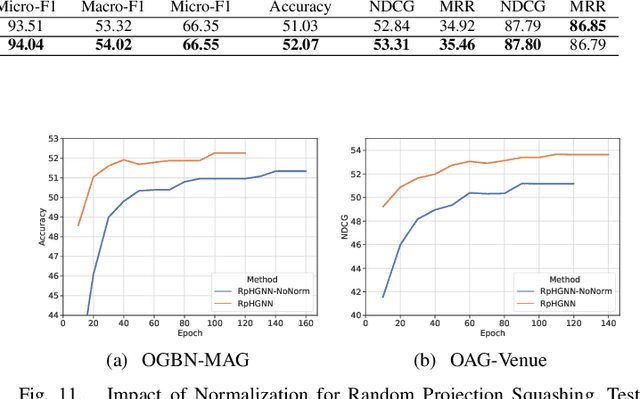
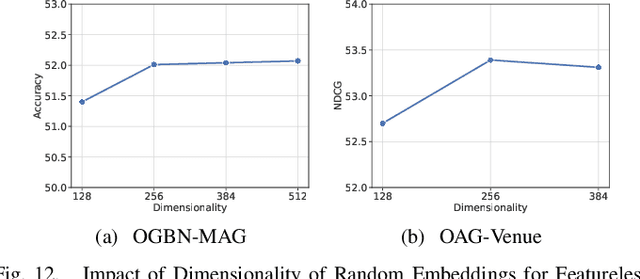
Heterogeneous Graph Neural Networks (HGNNs) are powerful tools for deep learning on heterogeneous graphs. Typical HGNNs require repetitive message passing during training, limiting efficiency for large-scale real-world graphs. Recent pre-computation-based HGNNs use one-time message passing to transform a heterogeneous graph into regular-shaped tensors, enabling efficient mini-batch training. Existing pre-computation-based HGNNs can be mainly categorized into two styles, which differ in how much information loss is allowed and efficiency. We propose a hybrid pre-computation-based HGNN, named Random Projection Heterogeneous Graph Neural Network (RpHGNN), which combines the benefits of one style's efficiency with the low information loss of the other style. To achieve efficiency, the main framework of RpHGNN consists of propagate-then-update iterations, where we introduce a Random Projection Squashing step to ensure that complexity increases only linearly. To achieve low information loss, we introduce a Relation-wise Neighbor Collection component with an Even-odd Propagation Scheme, which aims to collect information from neighbors in a finer-grained way. Experimental results indicate that our approach achieves state-of-the-art results on seven small and large benchmark datasets while also being 230% faster compared to the most effective baseline. Surprisingly, our approach not only surpasses pre-processing-based baselines but also outperforms end-to-end methods.
Test Time Embedding Normalization for Popularity Bias Mitigation
Sep 01, 2023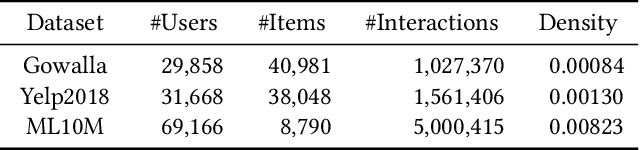
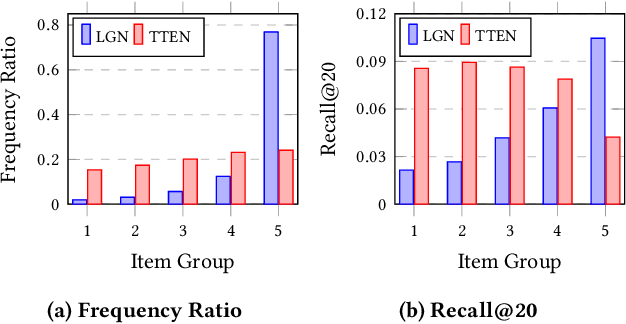
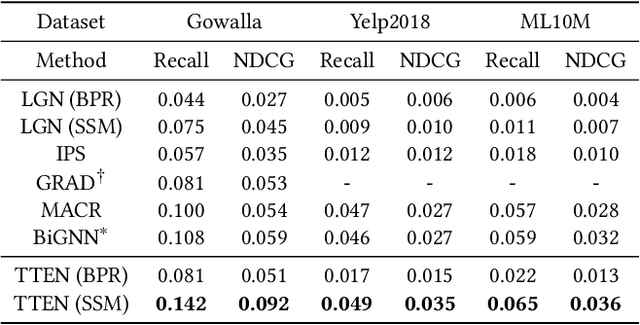
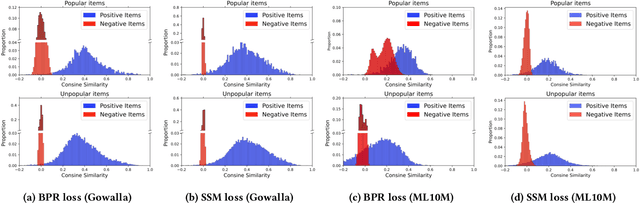
Popularity bias is a widespread problem in the field of recommender systems, where popular items tend to dominate recommendation results. In this work, we propose 'Test Time Embedding Normalization' as a simple yet effective strategy for mitigating popularity bias, which surpasses the performance of the previous mitigation approaches by a significant margin. Our approach utilizes the normalized item embedding during the inference stage to control the influence of embedding magnitude, which is highly correlated with item popularity. Through extensive experiments, we show that our method combined with the sampled softmax loss effectively reduces popularity bias compare to previous approaches for bias mitigation. We further investigate the relationship between user and item embeddings and find that the angular similarity between embeddings distinguishes preferable and non-preferable items regardless of their popularity. The analysis explains the mechanism behind the success of our approach in eliminating the impact of popularity bias. Our code is available at https://github.com/ml-postech/TTEN.
MISAR: A Multimodal Instructional System with Augmented Reality
Oct 18, 2023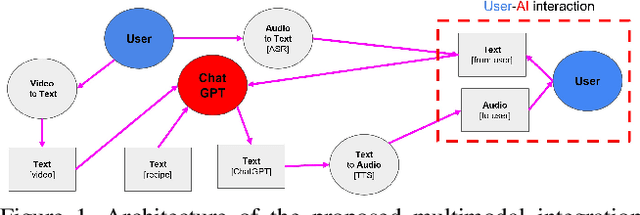
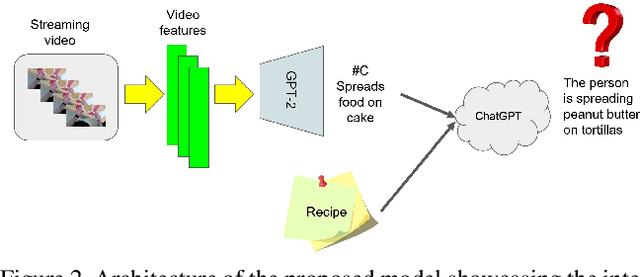
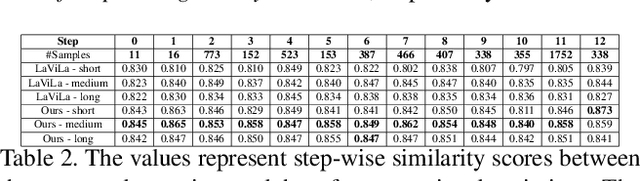
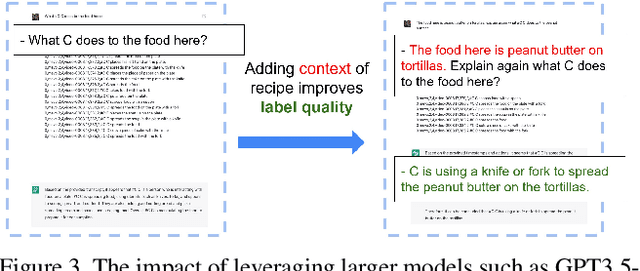
Augmented reality (AR) requires the seamless integration of visual, auditory, and linguistic channels for optimized human-computer interaction. While auditory and visual inputs facilitate real-time and contextual user guidance, the potential of large language models (LLMs) in this landscape remains largely untapped. Our study introduces an innovative method harnessing LLMs to assimilate information from visual, auditory, and contextual modalities. Focusing on the unique challenge of task performance quantification in AR, we utilize egocentric video, speech, and context analysis. The integration of LLMs facilitates enhanced state estimation, marking a step towards more adaptive AR systems. Code, dataset, and demo will be available at https://github.com/nguyennm1024/misar.
Harnessing the Power of LLMs: Evaluating Human-AI Text Co-Creation through the Lens of News Headline Generation
Oct 18, 2023To explore how humans can best leverage LLMs for writing and how interacting with these models affects feelings of ownership and trust in the writing process, we compared common human-AI interaction types (e.g., guiding system, selecting from system outputs, post-editing outputs) in the context of LLM-assisted news headline generation. While LLMs alone can generate satisfactory news headlines, on average, human control is needed to fix undesirable model outputs. Of the interaction methods, guiding and selecting model output added the most benefit with the lowest cost (in time and effort). Further, AI assistance did not harm participants' perception of control compared to freeform editing.
Time-Varying Quasi-Closed-Phase Analysis for Accurate Formant Tracking in Speech Signals
Aug 31, 2023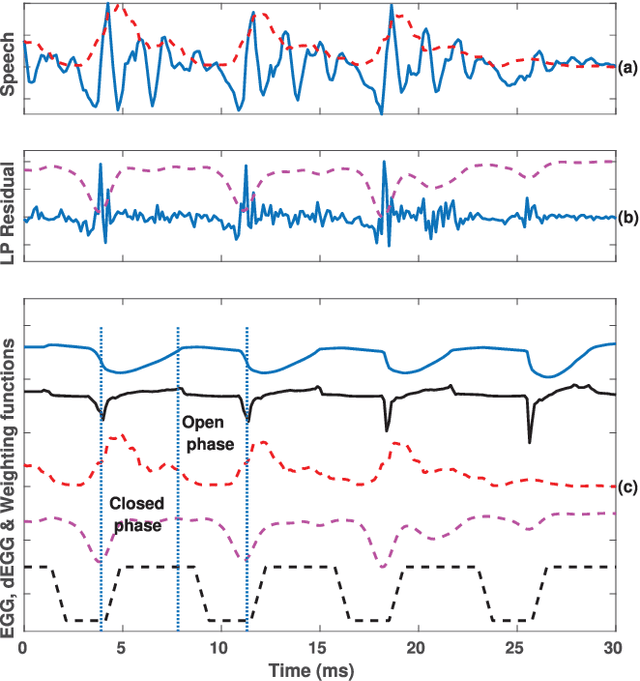
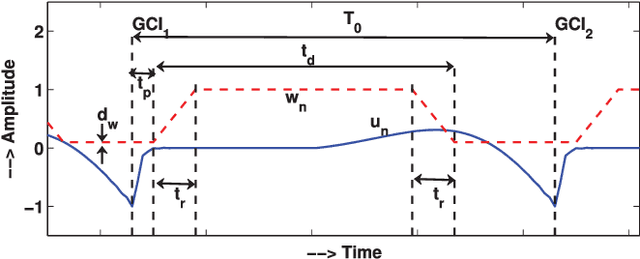
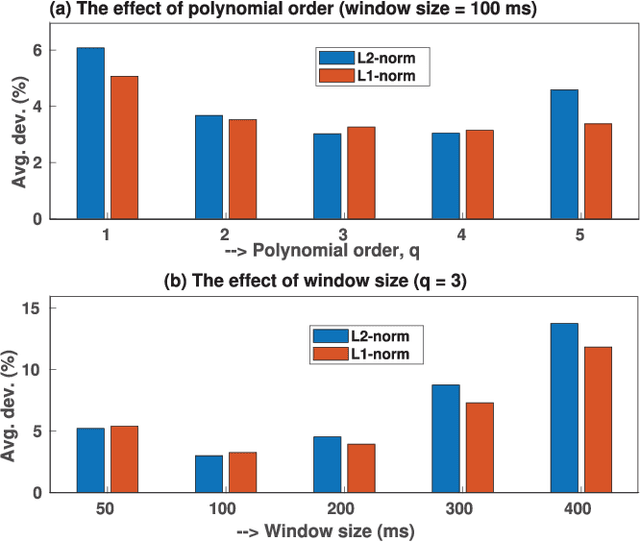
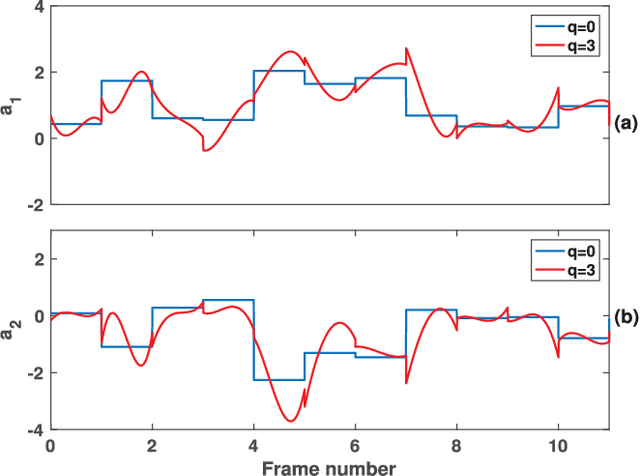
In this paper, we propose a new method for the accurate estimation and tracking of formants in speech signals using time-varying quasi-closed-phase (TVQCP) analysis. Conventional formant tracking methods typically adopt a two-stage estimate-and-track strategy wherein an initial set of formant candidates are estimated using short-time analysis (e.g., 10--50 ms), followed by a tracking stage based on dynamic programming or a linear state-space model. One of the main disadvantages of these approaches is that the tracking stage, however good it may be, cannot improve upon the formant estimation accuracy of the first stage. The proposed TVQCP method provides a single-stage formant tracking that combines the estimation and tracking stages into one. TVQCP analysis combines three approaches to improve formant estimation and tracking: (1) it uses temporally weighted quasi-closed-phase analysis to derive closed-phase estimates of the vocal tract with reduced interference from the excitation source, (2) it increases the residual sparsity by using the $L_1$ optimization and (3) it uses time-varying linear prediction analysis over long time windows (e.g., 100--200 ms) to impose a continuity constraint on the vocal tract model and hence on the formant trajectories. Formant tracking experiments with a wide variety of synthetic and natural speech signals show that the proposed TVQCP method performs better than conventional and popular formant tracking tools, such as Wavesurfer and Praat (based on dynamic programming), the KARMA algorithm (based on Kalman filtering), and DeepFormants (based on deep neural networks trained in a supervised manner). Matlab scripts for the proposed method can be found at: https://github.com/njaygowda/ftrack
V2X Sidelink Positioning in FR1: Scenarios, Algorithms, and Performance Evaluation
Oct 20, 2023In this paper, we investigate sub-6 GHz V2X sidelink positioning scenarios in 5G vehicular networks through a comprehensive end-to-end methodology encompassing ray-tracing-based channel modeling, novel theoretical performance bounds, high-resolution channel parameter estimation, and geometric positioning using a round-trip-time (RTT) protocol. We first derive a novel, approximate Cram\'er-Rao bound (CRB) on the connected road user (CRU) position, explicitly taking into account multipath interference, path merging, and the RTT protocol. Capitalizing on tensor decomposition and ESPRIT methods, we propose high-resolution channel parameter estimation algorithms specifically tailored to dense multipath V2X sidelink environments, designed to detect multipath components (MPCs) and extract line-of-sight (LoS) parameters. Finally, using realistic ray-tracing data and antenna patterns, comprehensive simulations are conducted to evaluate channel estimation and positioning performance, indicating that sub-meter accuracy can be achieved in sub-6 GHz V2X with the proposed algorithms.
Sync-NeRF: Generalizing Dynamic NeRFs to Unsynchronized Videos
Oct 20, 2023Recent advancements in 4D scene reconstruction using neural radiance fields (NeRF) have demonstrated the ability to represent dynamic scenes from multi-view videos. However, they fail to reconstruct the dynamic scenes and struggle to fit even the training views in unsynchronized settings. It happens because they employ a single latent embedding for a frame while the multi-view images at the frame were actually captured at different moments. To address this limitation, we introduce time offsets for individual unsynchronized videos and jointly optimize the offsets with NeRF. By design, our method is applicable for various baselines and improves them with large margins. Furthermore, finding the offsets naturally works as synchronizing the videos without manual effort. Experiments are conducted on the common Plenoptic Video Dataset and a newly built Unsynchronized Dynamic Blender Dataset to verify the performance of our method. Project page: https://seoha-kim.github.io/sync-nerf
Enhancing Prediction and Analysis of UK Road Traffic Accident Severity Using AI: Integration of Machine Learning, Econometric Techniques, and Time Series Forecasting in Public Health Research
Sep 23, 2023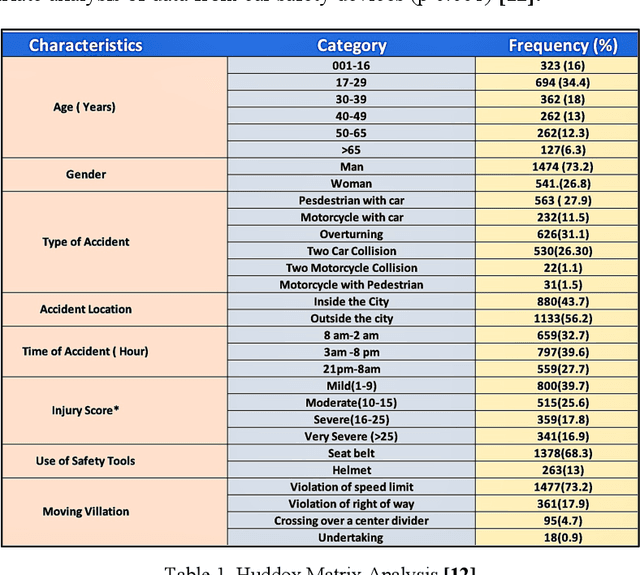
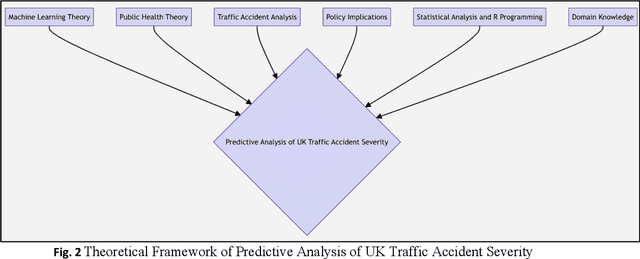
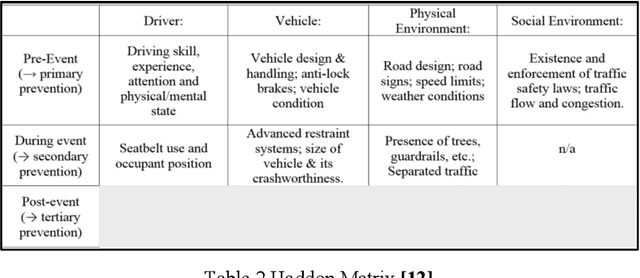
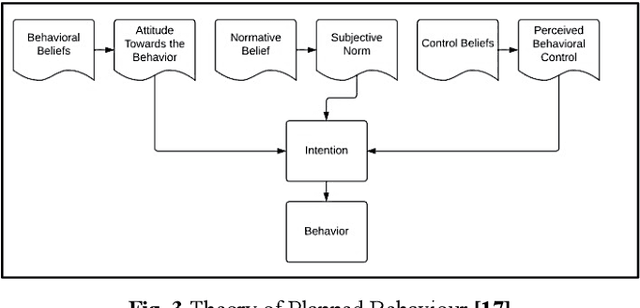
This research investigates road traffic accident severity in the UK, using a combination of machine learning, econometric, and statistical methods on historical data. We employed various techniques, including correlation analysis, regression models, GMM for error term issues, and time-series forecasting with VAR and ARIMA models. Our approach outperforms naive forecasting with an MASE of 0.800 and ME of -73.80. We also built a random forest classifier with 73% precision, 78% recall, and a 73% F1-score. Optimizing with H2O AutoML led to an XGBoost model with an RMSE of 0.176 and MAE of 0.087. Factor Analysis identified key variables, and we used SHAP for Explainable AI, highlighting influential factors like Driver_Home_Area_Type and Road_Type. Our study enhances understanding of accident severity and offers insights for evidence-based road safety policies.
Jointly Optimized Global-Local Visual Localization of UAVs
Oct 12, 2023Navigation and localization of UAVs present a challenge when global navigation satellite systems (GNSS) are disrupted and unreliable. Traditional techniques, such as simultaneous localization and mapping (SLAM) and visual odometry (VO), exhibit certain limitations in furnishing absolute coordinates and mitigating error accumulation. Existing visual localization methods achieve autonomous visual localization without error accumulation by matching with ortho satellite images. However, doing so cannot guarantee real-time performance due to the complex matching process. To address these challenges, we propose a novel Global-Local Visual Localization (GLVL) network. Our GLVL network is a two-stage visual localization approach, combining a large-scale retrieval module that finds similar regions with the UAV flight scene, and a fine-grained matching module that localizes the precise UAV coordinate, enabling real-time and precise localization. The training process is jointly optimized in an end-to-end manner to further enhance the model capability. Experiments on six UAV flight scenes encompassing both texture-rich and texture-sparse regions demonstrate the ability of our model to achieve the real-time precise localization requirements of UAVs. Particularly, our method achieves a localization error of only 2.39 meters in 0.48 seconds in a village scene with sparse texture features.
Fuzzy-NMS: Improving 3D Object Detection with Fuzzy Classification in NMS
Oct 21, 2023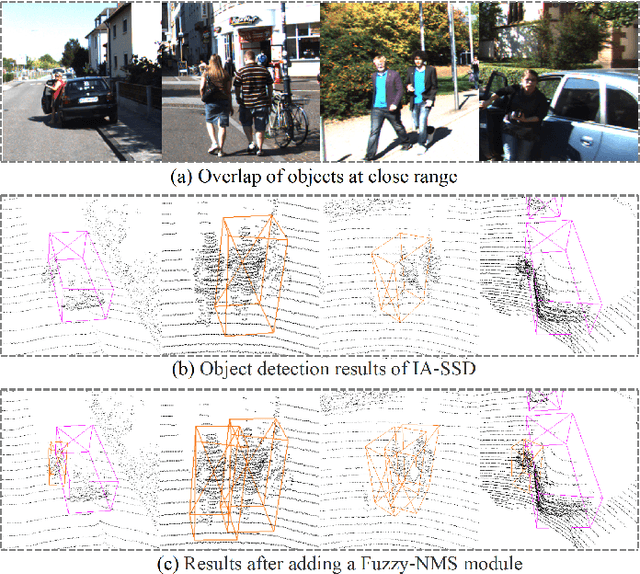
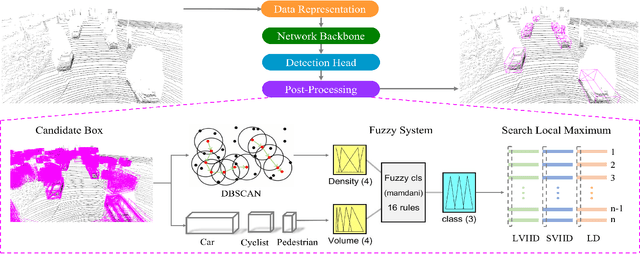
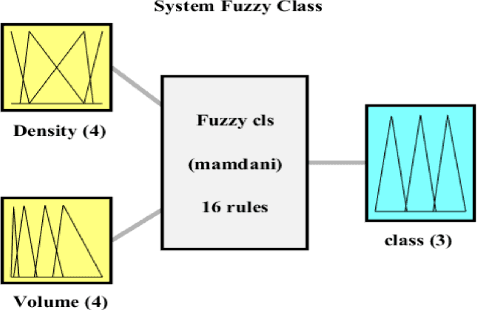
Non-maximum suppression (NMS) is an essential post-processing module used in many 3D object detection frameworks to remove overlapping candidate bounding boxes. However, an overreliance on classification scores and difficulties in determining appropriate thresholds can affect the resulting accuracy directly. To address these issues, we introduce fuzzy learning into NMS and propose a novel generalized Fuzzy-NMS module to achieve finer candidate bounding box filtering. The proposed Fuzzy-NMS module combines the volume and clustering density of candidate bounding boxes, refining them with a fuzzy classification method and optimizing the appropriate suppression thresholds to reduce uncertainty in the NMS process. Adequate validation experiments are conducted using the mainstream KITTI and large-scale Waymo 3D object detection benchmarks. The results of these tests demonstrate the proposed Fuzzy-NMS module can improve the accuracy of numerous recently NMS-based detectors significantly, including PointPillars, PV-RCNN, and IA-SSD, etc. This effect is particularly evident for small objects such as pedestrians and bicycles. As a plug-and-play module, Fuzzy-NMS does not need to be retrained and produces no obvious increases in inference time.