 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
VQ-NeRF: Vector Quantization Enhances Implicit Neural Representations
Oct 23, 2023
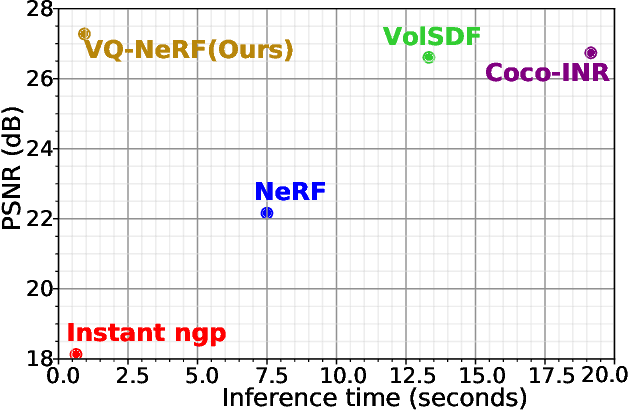

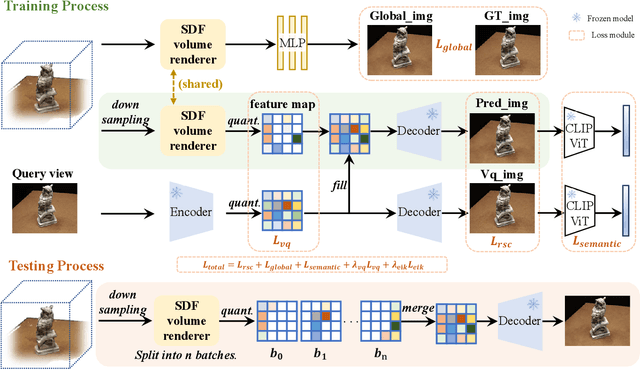
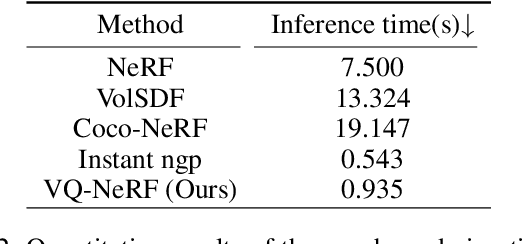
Recent advancements in implicit neural representations have contributed to high-fidelity surface reconstruction and photorealistic novel view synthesis. However, the computational complexity inherent in these methodologies presents a substantial impediment, constraining the attainable frame rates and resolutions in practical applications. In response to this predicament, we propose VQ-NeRF, an effective and efficient pipeline for enhancing implicit neural representations via vector quantization. The essence of our method involves reducing the sampling space of NeRF to a lower resolution and subsequently reinstating it to the original size utilizing a pre-trained VAE decoder, thereby effectively mitigating the sampling time bottleneck encountered during rendering. Although the codebook furnishes representative features, reconstructing fine texture details of the scene remains challenging due to high compression rates. To overcome this constraint, we design an innovative multi-scale NeRF sampling scheme that concurrently optimizes the NeRF model at both compressed and original scales to enhance the network's ability to preserve fine details. Furthermore, we incorporate a semantic loss function to improve the geometric fidelity and semantic coherence of our 3D reconstructions. Extensive experiments demonstrate the effectiveness of our model in achieving the optimal trade-off between rendering quality and efficiency. Evaluation on the DTU, BlendMVS, and H3DS datasets confirms the superior performance of our approach.
Interaction-Driven Active 3D Reconstruction with Object Interiors
Oct 23, 2023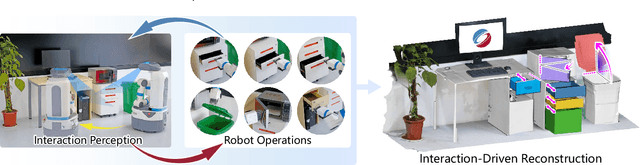
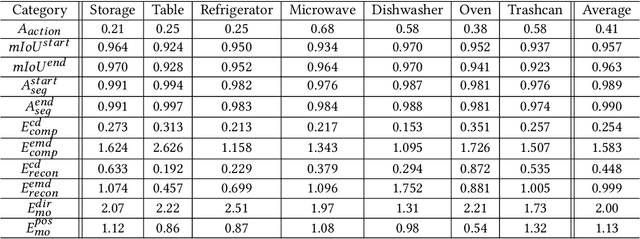
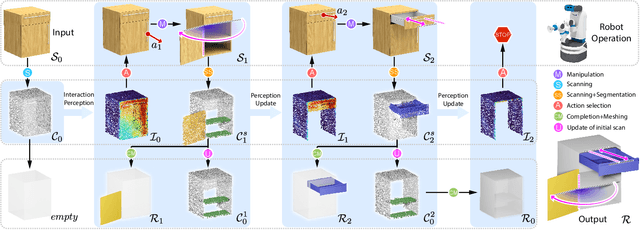
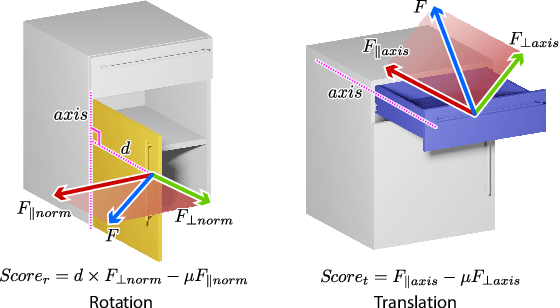
We introduce an active 3D reconstruction method which integrates visual perception, robot-object interaction, and 3D scanning to recover both the exterior and interior, i.e., unexposed, geometries of a target 3D object. Unlike other works in active vision which focus on optimizing camera viewpoints to better investigate the environment, the primary feature of our reconstruction is an analysis of the interactability of various parts of the target object and the ensuing part manipulation by a robot to enable scanning of occluded regions. As a result, an understanding of part articulations of the target object is obtained on top of complete geometry acquisition. Our method operates fully automatically by a Fetch robot with built-in RGBD sensors. It iterates between interaction analysis and interaction-driven reconstruction, scanning and reconstructing detected moveable parts one at a time, where both the articulated part detection and mesh reconstruction are carried out by neural networks. In the final step, all the remaining, non-articulated parts, including all the interior structures that had been exposed by prior part manipulations and subsequently scanned, are reconstructed to complete the acquisition. We demonstrate the performance of our method via qualitative and quantitative evaluation, ablation studies, comparisons to alternatives, as well as experiments in a real environment.
CAwa-NeRF: Instant Learning of Compression-Aware NeRF Features
Oct 23, 2023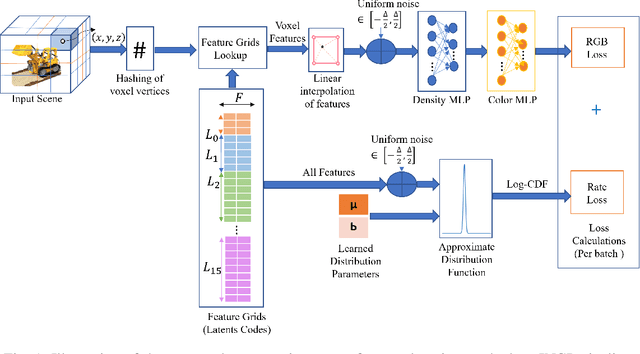
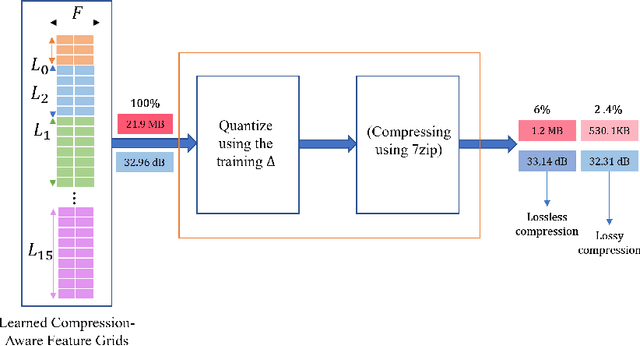
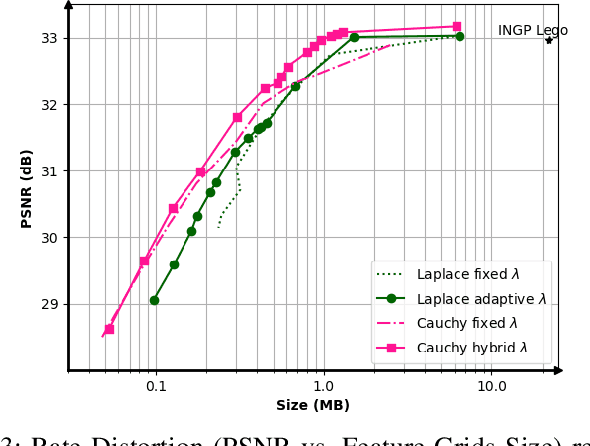
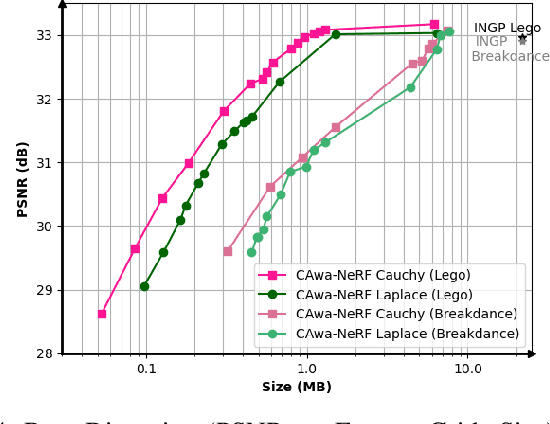
Modeling 3D scenes by volumetric feature grids is one of the promising directions of neural approximations to improve Neural Radiance Fields (NeRF). Instant-NGP (INGP) introduced multi-resolution hash encoding from a lookup table of trainable feature grids which enabled learning high-quality neural graphics primitives in a matter of seconds. However, this improvement came at the cost of higher storage size. In this paper, we address this challenge by introducing instant learning of compression-aware NeRF features (CAwa-NeRF), that allows exporting the zip compressed feature grids at the end of the model training with a negligible extra time overhead without changing neither the storage architecture nor the parameters used in the original INGP paper. Nonetheless, the proposed method is not limited to INGP but could also be adapted to any model. By means of extensive simulations, our proposed instant learning pipeline can achieve impressive results on different kinds of static scenes such as single object masked background scenes and real-life scenes captured in our studio. In particular, for single object masked background scenes CAwa-NeRF compresses the feature grids down to 6% (1.2 MB) of the original size without any loss in the PSNR (33 dB) or down to 2.4% (0.53 MB) with a slight virtual loss (32.31 dB).
Making informed decisions in cutting tool maintenance in milling: A KNN based model agnostic approach
Oct 23, 2023In machining processes, monitoring the condition of the tool is a crucial aspect to ensure high productivity and quality of the product. Using different machine learning techniques in Tool Condition Monitoring TCM enables a better analysis of the large amount of data of different signals acquired during the machining processes. The real time force signals encountered during the process were acquired by performing numerous experiments. Different tool wear conditions were considered during the experimentation. A comprehensive statistical analysis of the data and feature selection using decision trees was conducted, and the KNN algorithm was used to perform classification. Hyperparameter tuning of the model was done to improve the models performance. Much research has been done to employ machine learning approaches in tool condition monitoring systems, however, a model agnostic approach to increase the interpretability of the process and get an in depth understanding of how the decision making is done is not implemented by many. This research paper presents a KNN based white box model, which allows us to dive deep into how the model performs the classification and how it prioritizes the different features included. This approach helps in detecting why the tool is in a certain condition and allows the manufacturer to make an informed decision about the tools maintenance.
Making RL with Preference-based Feedback Efficient via Randomization
Oct 23, 2023Reinforcement Learning algorithms that learn from human feedback (RLHF) need to be efficient in terms of statistical complexity, computational complexity, and query complexity. In this work, we consider the RLHF setting where the feedback is given in the format of preferences over pairs of trajectories. In the linear MDP model, by using randomization in algorithm design, we present an algorithm that is sample efficient (i.e., has near-optimal worst-case regret bounds) and has polynomial running time (i.e., computational complexity is polynomial with respect to relevant parameters). Our algorithm further minimizes the query complexity through a novel randomized active learning procedure. In particular, our algorithm demonstrates a near-optimal tradeoff between the regret bound and the query complexity. To extend the results to more general nonlinear function approximation, we design a model-based randomized algorithm inspired by the idea of Thompson sampling. Our algorithm minimizes Bayesian regret bound and query complexity, again achieving a near-optimal tradeoff between these two quantities. Computation-wise, similar to the prior Thompson sampling algorithms under the regular RL setting, the main computation primitives of our algorithm are Bayesian supervised learning oracles which have been heavily investigated on the empirical side when applying Thompson sampling algorithms to RL benchmark problems.
Segment, Select, Correct: A Framework for Weakly-Supervised Referring Segmentation
Oct 23, 2023Referring Image Segmentation (RIS) - the problem of identifying objects in images through natural language sentences - is a challenging task currently mostly solved through supervised learning. However, while collecting referred annotation masks is a time-consuming process, the few existing weakly-supervised and zero-shot approaches fall significantly short in performance compared to fully-supervised learning ones. To bridge the performance gap without mask annotations, we propose a novel weakly-supervised framework that tackles RIS by decomposing it into three steps: obtaining instance masks for the object mentioned in the referencing instruction (segment), using zero-shot learning to select a potentially correct mask for the given instruction (select), and bootstrapping a model which allows for fixing the mistakes of zero-shot selection (correct). In our experiments, using only the first two steps (zero-shot segment and select) outperforms other zero-shot baselines by as much as 19%, while our full method improves upon this much stronger baseline and sets the new state-of-the-art for weakly-supervised RIS, reducing the gap between the weakly-supervised and fully-supervised methods in some cases from around 33% to as little as 14%. Code is available at https://github.com/fgirbal/segment-select-correct.
The WHY in Business Processes: Discovery of Causal Execution Dependencies
Oct 23, 2023A crucial element in predicting the outcomes of process interventions and making informed decisions about the process is unraveling the genuine relationships between the execution of process activities. Contemporary process discovery algorithms exploit time precedence as their main source of model derivation. Such reliance can sometimes be deceiving from a causal perspective. This calls for faithful new techniques to discover the true execution dependencies among the tasks in the process. To this end, our work offers a systematic approach to the unveiling of the true causal business process by leveraging an existing causal discovery algorithm over activity timing. In addition, this work delves into a set of conditions under which process mining discovery algorithms generate a model that is incongruent with the causal business process model, and shows how the latter model can be methodologically employed for a sound analysis of the process. Our methodology searches for such discrepancies between the two models in the context of three causal patterns, and derives a new view in which these inconsistencies are annotated over the mined process model. We demonstrate our methodology employing two open process mining algorithms, the IBM Process Mining tool, and the LiNGAM causal discovery technique. We apply it on a synthesized dataset and on two open benchmark data sets.
Strategies and impact of learning curve estimation for CNN-based image classification
Oct 12, 2023Learning curves are a measure for how the performance of machine learning models improves given a certain volume of training data. Over a wide variety of applications and models it was observed that learning curves follow -- to a large extent -- a power law behavior. This makes the performance of different models for a given task somewhat predictable and opens the opportunity to reduce the training time for practitioners, who are exploring the space of possible models and hyperparameters for the problem at hand. By estimating the learning curve of a model from training on small subsets of data only the best models need to be considered for training on the full dataset. How to choose subset sizes and how often to sample models on these to obtain estimates is however not researched. Given that the goal is to reduce overall training time strategies are needed that sample the performance in a time-efficient way and yet leads to accurate learning curve estimates. In this paper we formulate the framework for these strategies and propose several strategies. Further we evaluate the strategies for simulated learning curves and in experiments with popular datasets and models for image classification tasks.
Discovering Fatigued Movements for Virtual Character Animation
Oct 12, 2023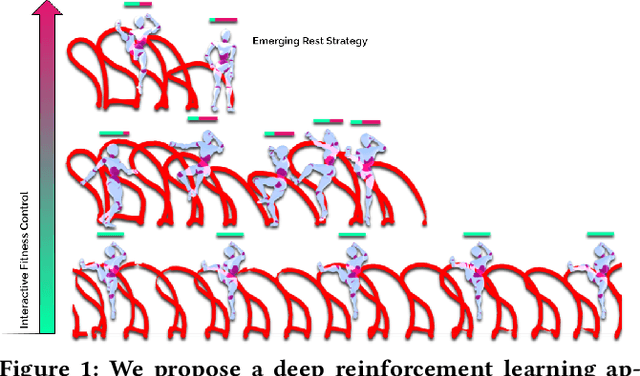
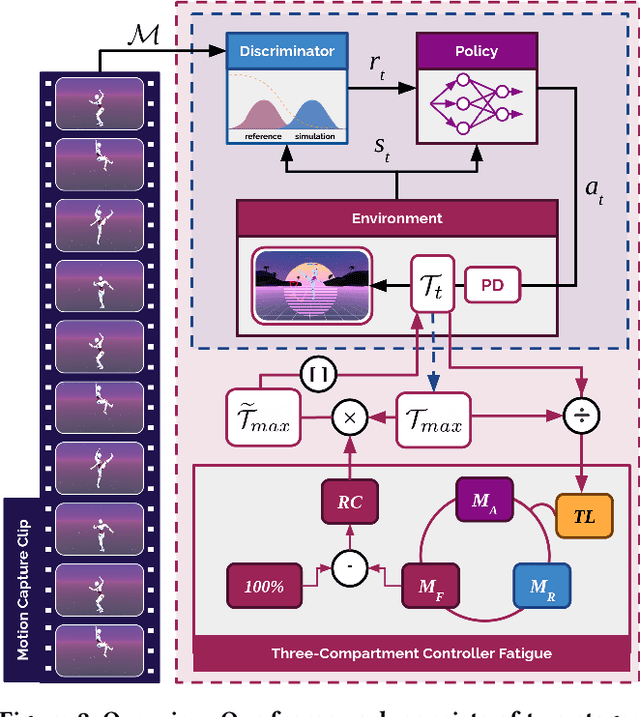

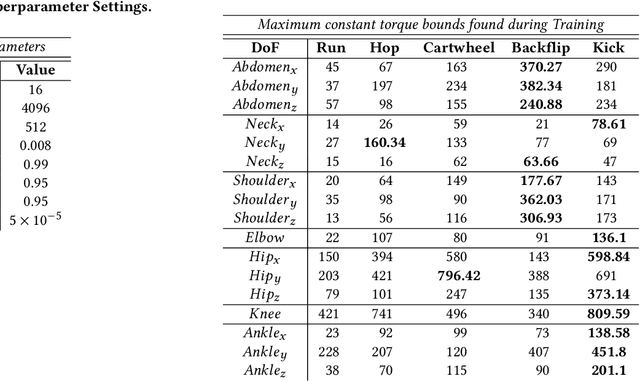
Virtual character animation and movement synthesis have advanced rapidly during recent years, especially through a combination of extensive motion capture datasets and machine learning. A remaining challenge is interactively simulating characters that fatigue when performing extended motions, which is indispensable for the realism of generated animations. However, capturing such movements is problematic, as performing movements like backflips with fatigued variations up to exhaustion raises capture cost and risk of injury. Surprisingly, little research has been done on faithful fatigue modeling. To address this, we propose a deep reinforcement learning-based approach, which -- for the first time in literature -- generates control policies for full-body physically simulated agents aware of cumulative fatigue. For this, we first leverage Generative Adversarial Imitation Learning (GAIL) to learn an expert policy for the skill; Second, we learn a fatigue policy by limiting the generated constant torque bounds based on endurance time to non-linear, state- and time-dependent limits in the joint-actuation space using a Three-Compartment Controller (3CC) model. Our results demonstrate that agents can adapt to different fatigue and rest rates interactively, and discover realistic recovery strategies without the need for any captured data of fatigued movement.
* 16 pages, 22 figures. To be published in ACM SIGGRAPH Asia Conference Papers 2023. ACM ISBN 979-8-4007-0315-7/23/12
Estimating Uncertainty in Multimodal Foundation Models using Public Internet Data
Oct 15, 2023Foundation models are trained on vast amounts of data at scale using self-supervised learning, enabling adaptation to a wide range of downstream tasks. At test time, these models exhibit zero-shot capabilities through which they can classify previously unseen (user-specified) categories. In this paper, we address the problem of quantifying uncertainty in these zero-shot predictions. We propose a heuristic approach for uncertainty estimation in zero-shot settings using conformal prediction with web data. Given a set of classes at test time, we conduct zero-shot classification with CLIP-style models using a prompt template, e.g., "an image of a <category>", and use the same template as a search query to source calibration data from the open web. Given a web-based calibration set, we apply conformal prediction with a novel conformity score that accounts for potential errors in retrieved web data. We evaluate the utility of our proposed method in Biomedical foundation models; our preliminary results show that web-based conformal prediction sets achieve the target coverage with satisfactory efficiency on a variety of biomedical datasets.