 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-World Implementation of Reinforcement Learning Based Energy Coordination for a Cluster of Households
Oct 29, 2023
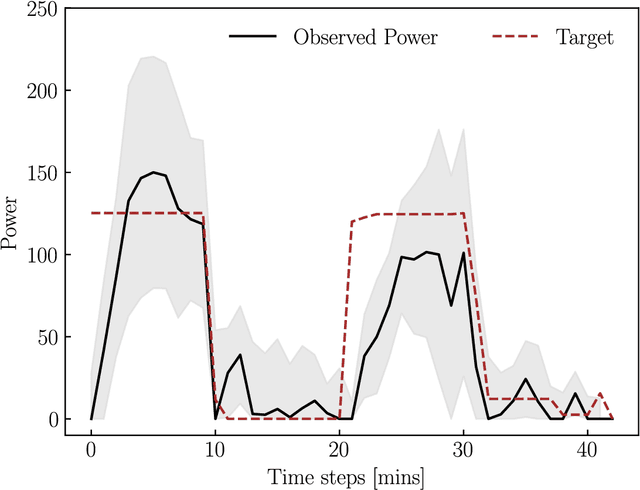

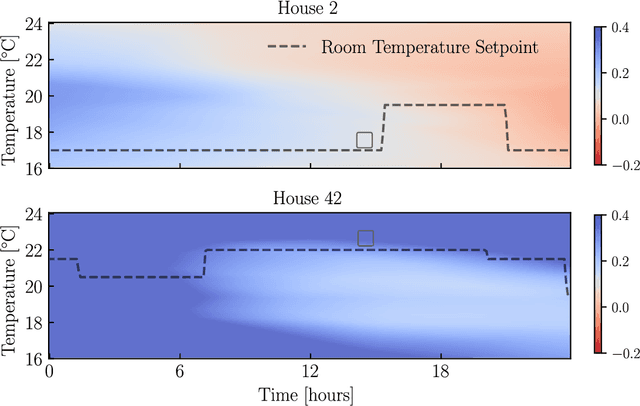
Given its substantial contribution of 40\% to global power consumption, the built environment has received increasing attention to serve as a source of flexibility to assist the modern power grid. In that respect, previous research mainly focused on energy management of individual buildings. In contrast, in this paper, we focus on aggregated control of a set of residential buildings, to provide grid supporting services, that eventually should include ancillary services. In particular, we present a real-life pilot study that studies the effectiveness of reinforcement-learning (RL) in coordinating the power consumption of 8 residential buildings to jointly track a target power signal. Our RL approach relies solely on observed data from individual households and does not require any explicit building models or simulators, making it practical to implement and easy to scale. We show the feasibility of our proposed RL-based coordination strategy in a real-world setting. In a 4-week case study, we demonstrate a hierarchical control system, relying on an RL-based ranking system to select which households to activate flex assets from, and a real-time PI control-based power dispatch mechanism to control the selected assets. Our results demonstrate satisfactory power tracking, and the effectiveness of the RL-based ranks which are learnt in a purely data-driven manner.
Design and Experimental Evaluation of a Haptic Robot-Assisted System for Femur Fracture Surgery
Oct 29, 2023
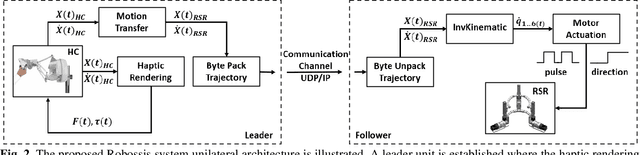
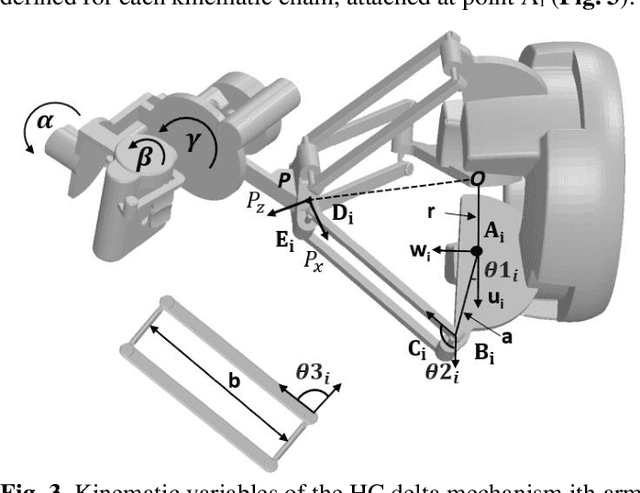
In the face of challenges encountered during femur fracture surgery, such as the high rates of malalignment and X-ray exposure to operating personnel, robot-assisted surgery has emerged as an alternative to conventional state-of-the-art surgical methods. This paper introduces the development of Robossis, a haptic system for robot-assisted femur fracture surgery. Robossis comprises a 7-DOF haptic controller and a 6-DOF surgical robot. A unilateral control architecture is developed to address the kinematic mismatch and the motion transfer between the haptic controller and the Robossis surgical robot. A real-time motion control pipeline is designed to address the motion transfer and evaluated through experimental testing. The analysis illustrates that the Robossis surgical robot can adhere to the desired trajectory from the haptic controller with an average translational error of 0.32 mm and a rotational error of 0.07 deg. Additionally, a haptic rendering pipeline is developed to resolve the kinematic mismatch by constraining the haptic controller (user hand) movement within the permissible joint limits of the Robossis surgical robot. Lastly, in a cadaveric lab test, the Robossis system assisted surgeons during a mock femur fracture surgery. The result shows that Robossis can provide an intuitive solution for surgeons to perform femur fracture surgery.
MAG-GNN: Reinforcement Learning Boosted Graph Neural Network
Oct 29, 2023While Graph Neural Networks (GNNs) recently became powerful tools in graph learning tasks, considerable efforts have been spent on improving GNNs' structural encoding ability. A particular line of work proposed subgraph GNNs that use subgraph information to improve GNNs' expressivity and achieved great success. However, such effectivity sacrifices the efficiency of GNNs by enumerating all possible subgraphs. In this paper, we analyze the necessity of complete subgraph enumeration and show that a model can achieve a comparable level of expressivity by considering a small subset of the subgraphs. We then formulate the identification of the optimal subset as a combinatorial optimization problem and propose Magnetic Graph Neural Network (MAG-GNN), a reinforcement learning (RL) boosted GNN, to solve the problem. Starting with a candidate subgraph set, MAG-GNN employs an RL agent to iteratively update the subgraphs to locate the most expressive set for prediction. This reduces the exponential complexity of subgraph enumeration to the constant complexity of a subgraph search algorithm while keeping good expressivity. We conduct extensive experiments on many datasets, showing that MAG-GNN achieves competitive performance to state-of-the-art methods and even outperforms many subgraph GNNs. We also demonstrate that MAG-GNN effectively reduces the running time of subgraph GNNs.
High Dimensional Time Series Regression Models: Applications to Statistical Learning Methods
Aug 27, 2023These lecture notes provide an overview of existing methodologies and recent developments for estimation and inference with high dimensional time series regression models. First, we present main limit theory results for high dimensional dependent data which is relevant to covariance matrix structures as well as to dependent time series sequences. Second, we present main aspects of the asymptotic theory related to time series regression models with many covariates. Third, we discuss various applications of statistical learning methodologies for time series analysis purposes.
Irregular Traffic Time Series Forecasting Based on Asynchronous Spatio-Temporal Graph Convolutional Network
Sep 01, 2023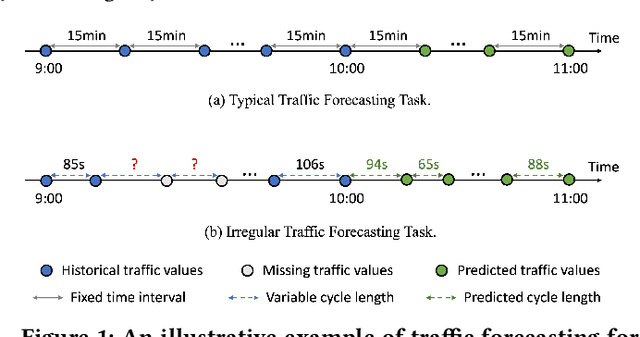
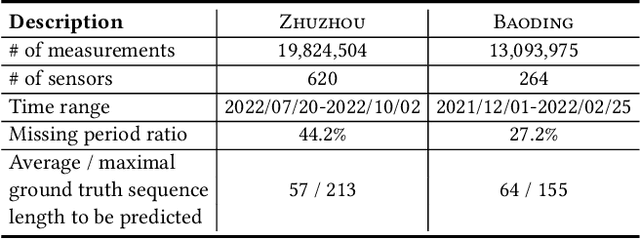
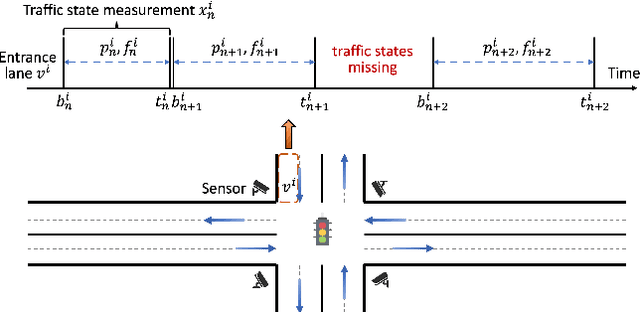
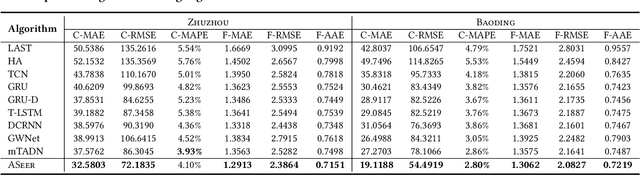
Accurate traffic forecasting at intersections governed by intelligent traffic signals is critical for the advancement of an effective intelligent traffic signal control system. However, due to the irregular traffic time series produced by intelligent intersections, the traffic forecasting task becomes much more intractable and imposes three major new challenges: 1) asynchronous spatial dependency, 2) irregular temporal dependency among traffic data, and 3) variable-length sequence to be predicted, which severely impede the performance of current traffic forecasting methods. To this end, we propose an Asynchronous Spatio-tEmporal graph convolutional nEtwoRk (ASeer) to predict the traffic states of the lanes entering intelligent intersections in a future time window. Specifically, by linking lanes via a traffic diffusion graph, we first propose an Asynchronous Graph Diffusion Network to model the asynchronous spatial dependency between the time-misaligned traffic state measurements of lanes. After that, to capture the temporal dependency within irregular traffic state sequence, a learnable personalized time encoding is devised to embed the continuous time for each lane. Then we propose a Transformable Time-aware Convolution Network that learns meta-filters to derive time-aware convolution filters with transformable filter sizes for efficient temporal convolution on the irregular sequence. Furthermore, a Semi-Autoregressive Prediction Network consisting of a state evolution unit and a semiautoregressive predictor is designed to effectively and efficiently predict variable-length traffic state sequences. Extensive experiments on two real-world datasets demonstrate the effectiveness of ASeer in six metrics.
SteloCoder: a Decoder-Only LLM for Multi-Language to Python Code Translation
Oct 24, 2023With the recent focus on Large Language Models (LLMs), both StarCoder (Li et al., 2023) and Code Llama (Rozi\`ere et al., 2023) have demonstrated remarkable performance in code generation. However, there is still a need for improvement in code translation functionality with efficient training techniques. In response to this, we introduce SteloCoder, a decoder-only StarCoder-based LLM designed specifically for multi-programming language-to-Python code translation. In particular, SteloCoder achieves C++, C#, JavaScript, Java, or PHP-to-Python code translation without specifying the input programming language. We modified StarCoder model architecture by incorporating a Mixture-of-Experts (MoE) technique featuring five experts and a gating network for multi-task handling. Experts are obtained by StarCoder fine-tuning. Specifically, we use a Low-Rank Adaptive Method (LoRA) technique, limiting each expert size as only 0.06% of number of StarCoder's parameters. At the same time, to enhance training efficiency in terms of time, we adopt curriculum learning strategy and use self-instruct data for efficient fine-tuning. As a result, each expert takes only 6 hours to train on one single 80Gb A100 HBM. With experiments on XLCoST datasets, SteloCoder achieves an average of 73.76 CodeBLEU score in multi-programming language-to-Python translation, surpassing the top performance from the leaderboard by at least 3.5. This accomplishment is attributed to only 45M extra parameters with StarCoder as the backbone and 32 hours of valid training on one 80GB A100 HBM. The source code is release here: https://github.com/sade-adrien/SteloCoder.
Dynamic Tensor Decomposition via Neural Diffusion-Reaction Processes
Oct 30, 2023Tensor decomposition is an important tool for multiway data analysis. In practice, the data is often sparse yet associated with rich temporal information. Existing methods, however, often under-use the time information and ignore the structural knowledge within the sparsely observed tensor entries. To overcome these limitations and to better capture the underlying temporal structure, we propose Dynamic EMbedIngs fOr dynamic Tensor dEcomposition (DEMOTE). We develop a neural diffusion-reaction process to estimate dynamic embeddings for the entities in each tensor mode. Specifically, based on the observed tensor entries, we build a multi-partite graph to encode the correlation between the entities. We construct a graph diffusion process to co-evolve the embedding trajectories of the correlated entities and use a neural network to construct a reaction process for each individual entity. In this way, our model can capture both the commonalities and personalities during the evolution of the embeddings for different entities. We then use a neural network to model the entry value as a nonlinear function of the embedding trajectories. For model estimation, we combine ODE solvers to develop a stochastic mini-batch learning algorithm. We propose a stratified sampling method to balance the cost of processing each mini-batch so as to improve the overall efficiency. We show the advantage of our approach in both simulation study and real-world applications. The code is available at https://github.com/wzhut/Dynamic-Tensor-Decomposition-via-Neural-Diffusion-Reaction-Processes.
SCAN-MUSIC: An Efficient Super-resolution Algorithm for Single Snapshot Wide-band Line Spectral Estimation
Oct 27, 2023We propose an efficient algorithm for reconstructing one-dimensional wide-band line spectra from their Fourier data in a bounded interval $[-\Omega,\Omega]$. While traditional subspace methods such as MUSIC achieve super-resolution for closely separated line spectra, their computational cost is high, particularly for wide-band line spectra. To address this issue, we proposed a scalable algorithm termed SCAN-MUSIC that scans the spectral domain using a fixed Gaussian window and then reconstructs the line spectra falling into the window at each time. For line spectra with cluster structure, we further refine the proposed algorithm using the annihilating filter technique. Both algorithms can significantly reduce the computational complexity of the standard MUSIC algorithm with a moderate loss of resolution. Moreover, in terms of speed, their performance is comparable to the state-of-the-art algorithms, while being more reliable for reconstructing line spectra with cluster structure. The algorithms are supplemented with theoretical analyses of error estimates, sampling complexity, computational complexity, and computational limit.
MixRep: Hidden Representation Mixup for Low-Resource Speech Recognition
Oct 27, 2023In this paper, we present MixRep, a simple and effective data augmentation strategy based on mixup for low-resource ASR. MixRep interpolates the feature dimensions of hidden representations in the neural network that can be applied to both the acoustic feature input and the output of each layer, which generalizes the previous MixSpeech method. Further, we propose to combine the mixup with a regularization along the time axis of the input, which is shown as complementary. We apply MixRep to a Conformer encoder of an E2E LAS architecture trained with a joint CTC loss. We experiment on the WSJ dataset and subsets of the SWB dataset, covering reading and telephony conversational speech. Experimental results show that MixRep consistently outperforms other regularization methods for low-resource ASR. Compared to a strong SpecAugment baseline, MixRep achieves a +6.5\% and a +6.7\% relative WER reduction on the eval92 set and the Callhome part of the eval'2000 set.
Denoising Heat-inspired Diffusion with Insulators for Collision Free Motion Planning
Oct 19, 2023Diffusion models have risen as a powerful tool in robotics due to their flexibility and multi-modality. While some of these methods effectively address complex problems, they often depend heavily on inference-time obstacle detection and require additional equipment. Addressing these challenges, we present a method that, during inference time, simultaneously generates only reachable goals and plans motions that avoid obstacles, all from a single visual input. Central to our approach is the novel use of a collision-avoiding diffusion kernel for training. Through evaluations against behavior-cloning and classical diffusion models, our framework has proven its robustness. It is particularly effective in multi-modal environments, navigating toward goals and avoiding unreachable ones blocked by obstacles, while ensuring collision avoidance.