 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Causal Feature Selection via Transfer Entropy
Oct 17, 2023
Machine learning algorithms are designed to capture complex relationships between features. In this context, the high dimensionality of data often results in poor model performance, with the risk of overfitting. Feature selection, the process of selecting a subset of relevant and non-redundant features, is, therefore, an essential step to mitigate these issues. However, classical feature selection approaches do not inspect the causal relationship between selected features and target, which can lead to misleading results in real-world applications. Causal discovery, instead, aims to identify causal relationships between features with observational data. In this paper, we propose a novel methodology at the intersection between feature selection and causal discovery, focusing on time series. We introduce a new causal feature selection approach that relies on the forward and backward feature selection procedures and leverages transfer entropy to estimate the causal flow of information from the features to the target in time series. Our approach enables the selection of features not only in terms of mere model performance but also captures the causal information flow. In this context, we provide theoretical guarantees on the regression and classification errors for both the exact and the finite-sample cases. Finally, we present numerical validations on synthetic and real-world regression problems, showing results competitive w.r.t. the considered baselines.
Analyzing Cognitive Plausibility of Subword Tokenization
Oct 20, 2023Subword tokenization has become the de-facto standard for tokenization, although comparative evaluations of subword vocabulary quality across languages are scarce. Existing evaluation studies focus on the effect of a tokenization algorithm on the performance in downstream tasks, or on engineering criteria such as the compression rate. We present a new evaluation paradigm that focuses on the cognitive plausibility of subword tokenization. We analyze the correlation of the tokenizer output with the response time and accuracy of human performance on a lexical decision task. We compare three tokenization algorithms across several languages and vocabulary sizes. Our results indicate that the UnigramLM algorithm yields less cognitively plausible tokenization behavior and a worse coverage of derivational morphemes, in contrast with prior work.
An Automated Machine Learning Approach for Detecting Anomalous Peak Patterns in Time Series Data from a Research Watershed in the Northeastern United States Critical Zone
Sep 14, 2023This paper presents an automated machine learning framework designed to assist hydrologists in detecting anomalies in time series data generated by sensors in a research watershed in the northeastern United States critical zone. The framework specifically focuses on identifying peak-pattern anomalies, which may arise from sensor malfunctions or natural phenomena. However, the use of classification methods for anomaly detection poses challenges, such as the requirement for labeled data as ground truth and the selection of the most suitable deep learning model for the given task and dataset. To address these challenges, our framework generates labeled datasets by injecting synthetic peak patterns into synthetically generated time series data and incorporates an automated hyperparameter optimization mechanism. This mechanism generates an optimized model instance with the best architectural and training parameters from a pool of five selected models, namely Temporal Convolutional Network (TCN), InceptionTime, MiniRocket, Residual Networks (ResNet), and Long Short-Term Memory (LSTM). The selection is based on the user's preferences regarding anomaly detection accuracy and computational cost. The framework employs Time-series Generative Adversarial Networks (TimeGAN) as the synthetic dataset generator. The generated model instances are evaluated using a combination of accuracy and computational cost metrics, including training time and memory, during the anomaly detection process. Performance evaluation of the framework was conducted using a dataset from a watershed, demonstrating consistent selection of the most fitting model instance that satisfies the user's preferences.
Match-And-Deform: Time Series Domain Adaptation through Optimal Transport and Temporal Alignment
Aug 25, 2023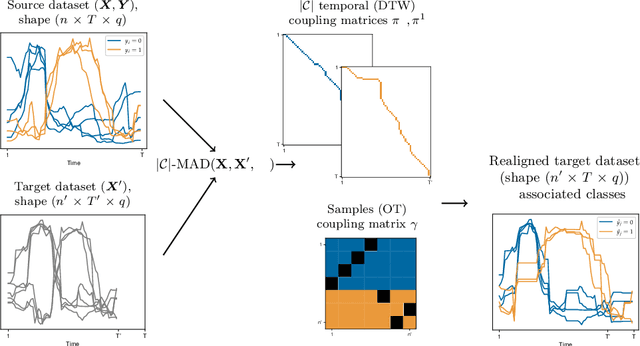
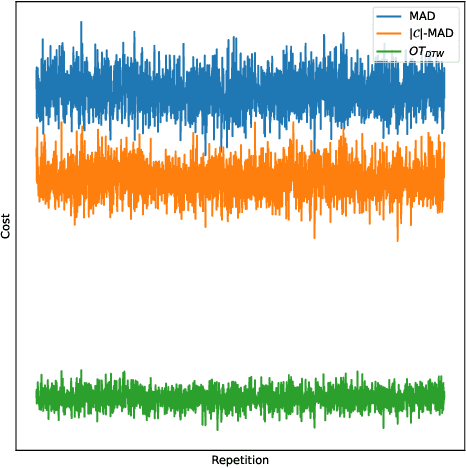
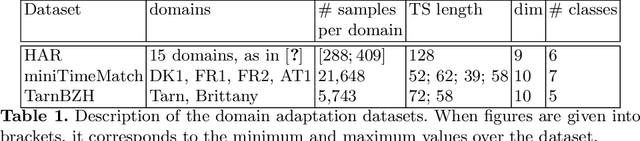
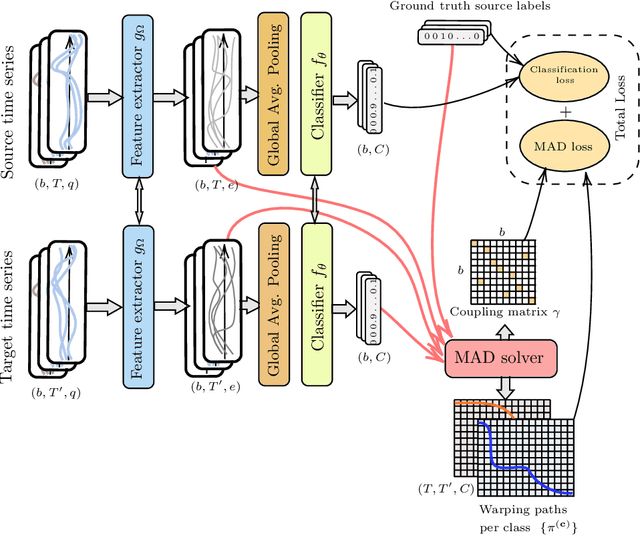
While large volumes of unlabeled data are usually available, associated labels are often scarce. The unsupervised domain adaptation problem aims at exploiting labels from a source domain to classify data from a related, yet different, target domain. When time series are at stake, new difficulties arise as temporal shifts may appear in addition to the standard feature distribution shift. In this paper, we introduce the Match-And-Deform (MAD) approach that aims at finding correspondences between the source and target time series while allowing temporal distortions. The associated optimization problem simultaneously aligns the series thanks to an optimal transport loss and the time stamps through dynamic time warping. When embedded into a deep neural network, MAD helps learning new representations of time series that both align the domains and maximize the discriminative power of the network. Empirical studies on benchmark datasets and remote sensing data demonstrate that MAD makes meaningful sample-to-sample pairing and time shift estimation, reaching similar or better classification performance than state-of-the-art deep time series domain adaptation strategies.
LLM-FP4: 4-Bit Floating-Point Quantized Transformers
Oct 25, 2023We propose LLM-FP4 for quantizing both weights and activations in large language models (LLMs) down to 4-bit floating-point values, in a post-training manner. Existing post-training quantization (PTQ) solutions are primarily integer-based and struggle with bit widths below 8 bits. Compared to integer quantization, floating-point (FP) quantization is more flexible and can better handle long-tail or bell-shaped distributions, and it has emerged as a default choice in many hardware platforms. One characteristic of FP quantization is that its performance largely depends on the choice of exponent bits and clipping range. In this regard, we construct a strong FP-PTQ baseline by searching for the optimal quantization parameters. Furthermore, we observe a high inter-channel variance and low intra-channel variance pattern in activation distributions, which adds activation quantization difficulty. We recognize this pattern to be consistent across a spectrum of transformer models designed for diverse tasks, such as LLMs, BERT, and Vision Transformer models. To tackle this, we propose per-channel activation quantization and show that these additional scaling factors can be reparameterized as exponential biases of weights, incurring a negligible cost. Our method, for the first time, can quantize both weights and activations in the LLaMA-13B to only 4-bit and achieves an average score of 63.1 on the common sense zero-shot reasoning tasks, which is only 5.8 lower than the full-precision model, significantly outperforming the previous state-of-the-art by 12.7 points. Code is available at: https://github.com/nbasyl/LLM-FP4.
Optimal Exploration is no harder than Thompson Sampling
Oct 24, 2023


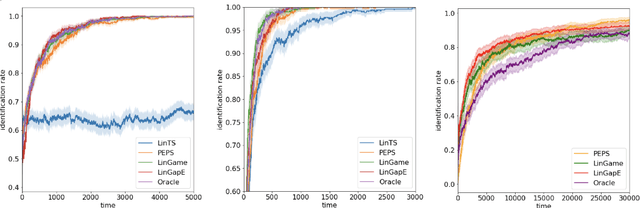
Given a set of arms $\mathcal{Z}\subset \mathbb{R}^d$ and an unknown parameter vector $\theta_\ast\in\mathbb{R}^d$, the pure exploration linear bandit problem aims to return $\arg\max_{z\in \mathcal{Z}} z^{\top}\theta_{\ast}$, with high probability through noisy measurements of $x^{\top}\theta_{\ast}$ with $x\in \mathcal{X}\subset \mathbb{R}^d$. Existing (asymptotically) optimal methods require either a) potentially costly projections for each arm $z\in \mathcal{Z}$ or b) explicitly maintaining a subset of $\mathcal{Z}$ under consideration at each time. This complexity is at odds with the popular and simple Thompson Sampling algorithm for regret minimization, which just requires access to a posterior sampling and argmax oracle, and does not need to enumerate $\mathcal{Z}$ at any point. Unfortunately, Thompson sampling is known to be sub-optimal for pure exploration. In this work, we pose a natural question: is there an algorithm that can explore optimally and only needs the same computational primitives as Thompson Sampling? We answer the question in the affirmative. We provide an algorithm that leverages only sampling and argmax oracles and achieves an exponential convergence rate, with the exponent being the optimal among all possible allocations asymptotically. In addition, we show that our algorithm can be easily implemented and performs as well empirically as existing asymptotically optimal methods.
What Makes it Ok to Set a Fire? Iterative Self-distillation of Contexts and Rationales for Disambiguating Defeasible Social and Moral Situations
Oct 24, 2023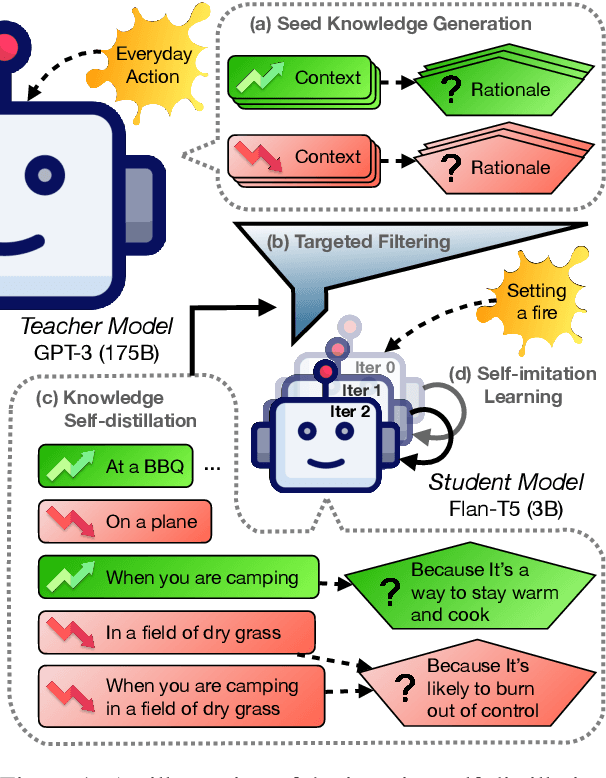
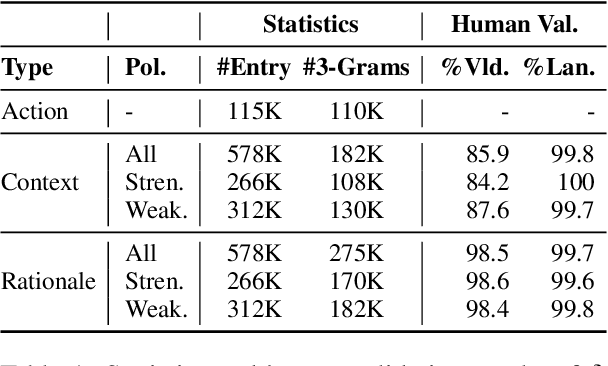
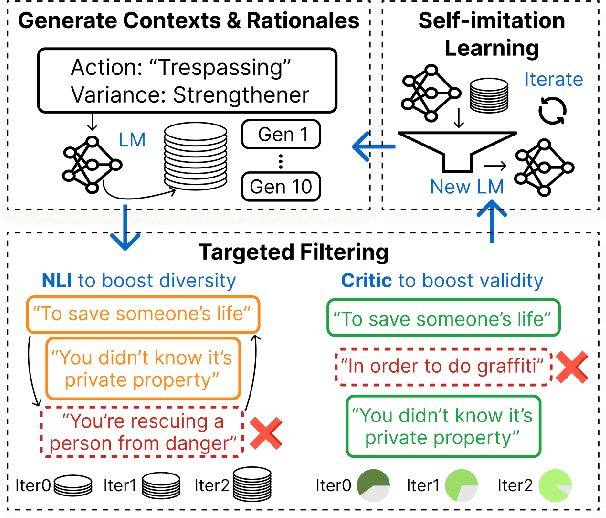
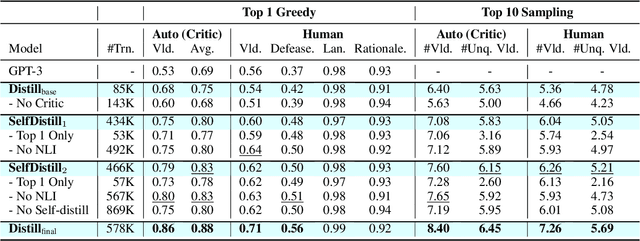
Moral or ethical judgments rely heavily on the specific contexts in which they occur. Understanding varying shades of defeasible contextualizations (i.e., additional information that strengthens or attenuates the moral acceptability of an action) is critical to accurately represent the subtlety and intricacy of grounded human moral judgment in real-life scenarios. We introduce defeasible moral reasoning: a task to provide grounded contexts that make an action more or less morally acceptable, along with commonsense rationales that justify the reasoning. To elicit high-quality task data, we take an iterative self-distillation approach that starts from a small amount of unstructured seed knowledge from GPT-3 and then alternates between (1) self-distillation from student models; (2) targeted filtering with a critic model trained by human judgment (to boost validity) and NLI (to boost diversity); (3) self-imitation learning (to amplify the desired data quality). This process yields a student model that produces defeasible contexts with improved validity, diversity, and defeasibility. From this model we distill a high-quality dataset, \delta-Rules-of-Thumb, of 1.2M entries of contextualizations and rationales for 115K defeasible moral actions rated highly by human annotators 85.9% to 99.8% of the time. Using \delta-RoT we obtain a final student model that wins over all intermediate student models by a notable margin.
ScanDL: A Diffusion Model for Generating Synthetic Scanpaths on Texts
Oct 24, 2023Eye movements in reading play a crucial role in psycholinguistic research studying the cognitive mechanisms underlying human language processing. More recently, the tight coupling between eye movements and cognition has also been leveraged for language-related machine learning tasks such as the interpretability, enhancement, and pre-training of language models, as well as the inference of reader- and text-specific properties. However, scarcity of eye movement data and its unavailability at application time poses a major challenge for this line of research. Initially, this problem was tackled by resorting to cognitive models for synthesizing eye movement data. However, for the sole purpose of generating human-like scanpaths, purely data-driven machine-learning-based methods have proven to be more suitable. Following recent advances in adapting diffusion processes to discrete data, we propose ScanDL, a novel discrete sequence-to-sequence diffusion model that generates synthetic scanpaths on texts. By leveraging pre-trained word representations and jointly embedding both the stimulus text and the fixation sequence, our model captures multi-modal interactions between the two inputs. We evaluate ScanDL within- and across-dataset and demonstrate that it significantly outperforms state-of-the-art scanpath generation methods. Finally, we provide an extensive psycholinguistic analysis that underlines the model's ability to exhibit human-like reading behavior. Our implementation is made available at https://github.com/DiLi-Lab/ScanDL.
Transformers for scientific data: a pedagogical review for astronomers
Oct 19, 2023The deep learning architecture associated with ChatGPT and related generative AI products is known as transformers. Initially applied to Natural Language Processing, transformers and the self-attention mechanism they exploit have gained widespread interest across the natural sciences. The goal of this pedagogical and informal review is to introduce transformers to scientists. The review includes the mathematics underlying the attention mechanism, a description of the original transformer architecture, and a section on applications to time series and imaging data in astronomy. We include a Frequently Asked Questions section for readers who are curious about generative AI or interested in getting started with transformers for their research problem.
Test-Time Adaptation for Point Cloud Upsampling Using Meta-Learning
Sep 01, 2023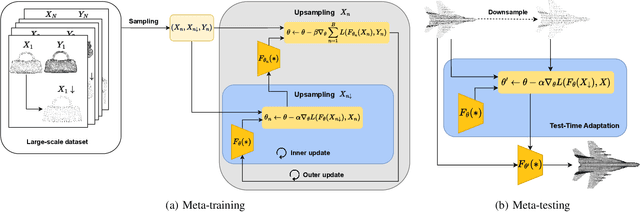
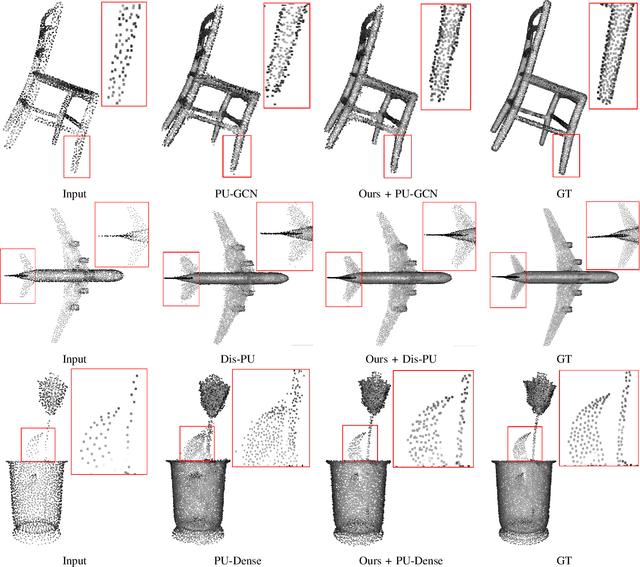
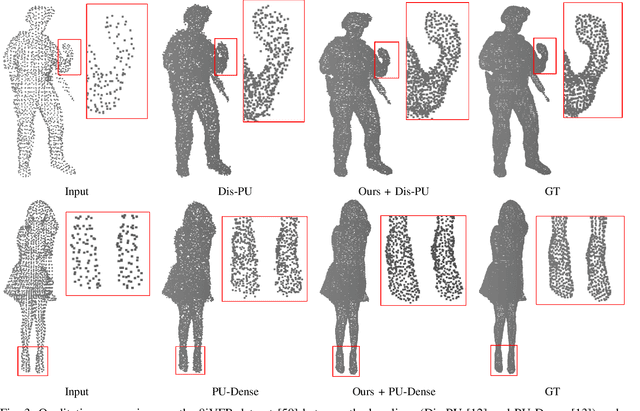
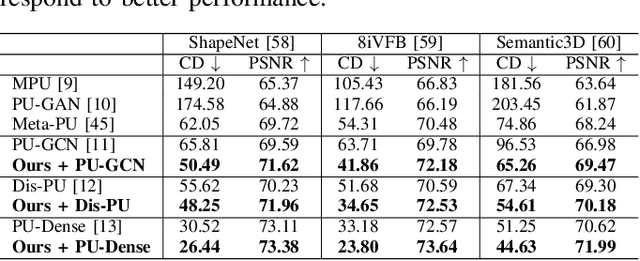
Affordable 3D scanners often produce sparse and non-uniform point clouds that negatively impact downstream applications in robotic systems. While existing point cloud upsampling architectures have demonstrated promising results on standard benchmarks, they tend to experience significant performance drops when the test data have different distributions from the training data. To address this issue, this paper proposes a test-time adaption approach to enhance model generality of point cloud upsampling. The proposed approach leverages meta-learning to explicitly learn network parameters for test-time adaption. Our method does not require any prior information about the test data. During meta-training, the model parameters are learned from a collection of instance-level tasks, each of which consists of a sparse-dense pair of point clouds from the training data. During meta-testing, the trained model is fine-tuned with a few gradient updates to produce a unique set of network parameters for each test instance. The updated model is then used for the final prediction. Our framework is generic and can be applied in a plug-and-play manner with existing backbone networks in point cloud upsampling. Extensive experiments demonstrate that our approach improves the performance of state-of-the-art models.