 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Revisiting Implicit Differentiation for Learning Problems in Optimal Control
Oct 23, 2023
This paper proposes a new method for differentiating through optimal trajectories arising from non-convex, constrained discrete-time optimal control (COC) problems using the implicit function theorem (IFT). Previous works solve a differential Karush-Kuhn-Tucker (KKT) system for the trajectory derivative, and achieve this efficiently by solving an auxiliary Linear Quadratic Regulator (LQR) problem. In contrast, we directly evaluate the matrix equations which arise from applying variable elimination on the Lagrange multiplier terms in the (differential) KKT system. By appropriately accounting for the structure of the terms within the resulting equations, we show that the trajectory derivatives scale linearly with the number of timesteps. Furthermore, our approach allows for easy parallelization, significantly improved scalability with model size, direct computation of vector-Jacobian products and improved numerical stability compared to prior works. As an additional contribution, we unify prior works, addressing claims that computing trajectory derivatives using IFT scales quadratically with the number of timesteps. We evaluate our method on a both synthetic benchmark and four challenging, learning from demonstration benchmarks including a 6-DoF maneuvering quadrotor and 6-DoF rocket powered landing.
LC-TTFS: Towards Lossless Network Conversion for Spiking Neural Networks with TTFS Coding
Oct 23, 2023The biological neurons use precise spike times, in addition to the spike firing rate, to communicate with each other. The time-to-first-spike (TTFS) coding is inspired by such biological observation. However, there is a lack of effective solutions for training TTFS-based spiking neural network (SNN). In this paper, we put forward a simple yet effective network conversion algorithm, which is referred to as LC-TTFS, by addressing two main problems that hinder an effective conversion from a high-performance artificial neural network (ANN) to a TTFS-based SNN. We show that our algorithm can achieve a near-perfect mapping between the activation values of an ANN and the spike times of an SNN on a number of challenging AI tasks, including image classification, image reconstruction, and speech enhancement. With TTFS coding, we can achieve up to orders of magnitude saving in computation over ANN and other rate-based SNNs. The study, therefore, paves the way for deploying ultra-low-power TTFS-based SNNs on power-constrained edge computing platforms.
Triple Simplex Matrix Completion for Expense Forecasting
Oct 23, 2023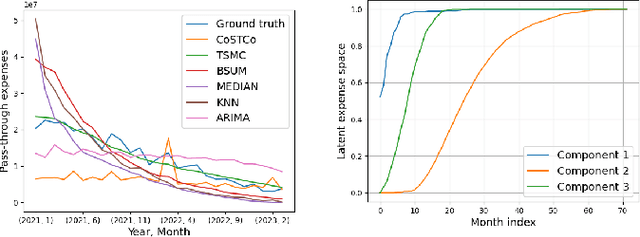
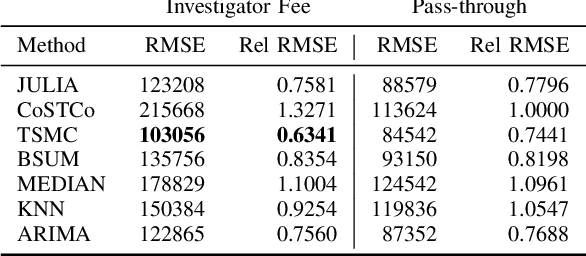
Forecasting project expenses is a crucial step for businesses to avoid budget overruns and project failures. Traditionally, this has been done by financial analysts or data science techniques such as time-series analysis. However, these approaches can be uncertain and produce results that differ from the planned budget, especially at the start of a project with limited data points. This paper proposes a constrained non-negative matrix completion model that predicts expenses by learning the likelihood of the project correlating with certain expense patterns in the latent space. The model is constrained on three probability simplexes, two of which are on the factor matrices and the third on the missing entries. Additionally, the predicted expense values are guaranteed to meet the budget constraint without the need of post-processing. An inexact alternating optimization algorithm is developed to solve the associated optimization problem and is proven to converge to a stationary point. Results from two real datasets demonstrate the effectiveness of the proposed method in comparison to state-of-the-art algorithms.
Modality Dropout for Multimodal Device Directed Speech Detection using Verbal and Non-Verbal Features
Oct 23, 2023Device-directed speech detection (DDSD) is the binary classification task of distinguishing between queries directed at a voice assistant versus side conversation or background speech. State-of-the-art DDSD systems use verbal cues, e.g acoustic, text and/or automatic speech recognition system (ASR) features, to classify speech as device-directed or otherwise, and often have to contend with one or more of these modalities being unavailable when deployed in real-world settings. In this paper, we investigate fusion schemes for DDSD systems that can be made more robust to missing modalities. Concurrently, we study the use of non-verbal cues, specifically prosody features, in addition to verbal cues for DDSD. We present different approaches to combine scores and embeddings from prosody with the corresponding verbal cues, finding that prosody improves DDSD performance by upto 8.5% in terms of false acceptance rate (FA) at a given fixed operating point via non-linear intermediate fusion, while our use of modality dropout techniques improves the performance of these models by 7.4% in terms of FA when evaluated with missing modalities during inference time.
A Historical Context for Data Streams
Oct 18, 2023Machine learning from data streams is an active and growing research area. Research on learning from streaming data typically makes strict assumptions linked to computational resource constraints, including requirements for stream mining algorithms to inspect each instance not more than once and be ready to give a prediction at any time. Here we review the historical context of data streams research placing the common assumptions used in machine learning over data streams in their historical context.
Efficiently Visualizing Large Graphs
Oct 17, 2023Most existing graph visualization methods based on dimension reduction are limited to relatively small graphs due to performance issues. In this work, we propose a novel dimension reduction method for graph visualization, called t-Distributed Stochastic Graph Neighbor Embedding (t-SGNE). t-SGNE is specifically designed to visualize cluster structures in the graph. As a variant of the standard t-SNE method, t-SGNE avoids the time-consuming computations of pairwise similarity. Instead, it uses the neighbor structures of the graph to reduce the time complexity from quadratic to linear, thus supporting larger graphs. In addition, to suit t-SGNE, we combined Laplacian Eigenmaps with the shortest path algorithm in graphs to form the graph embedding algorithm ShortestPath Laplacian Eigenmaps Embedding (SPLEE). Performing SPLEE to obtain a high-dimensional embedding of the large-scale graph and then using t-SGNE to reduce its dimension for visualization, we are able to visualize graphs with up to 300K nodes and 1M edges within 5 minutes and achieve approximately 10% improvement in visualization quality. Codes and data are available at https://github.com/Charlie-XIAO/embedding-visualization-test.
A Survey of Feature Types and Their Contributions for Camera Tampering Detection
Oct 11, 2023
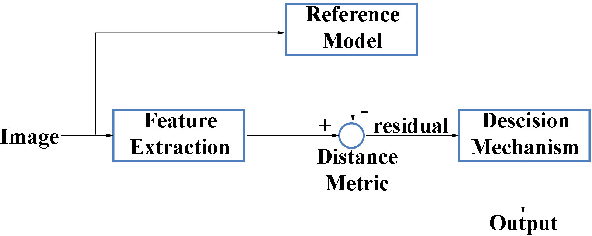


Camera tamper detection is the ability to detect unauthorized and unintentional alterations in surveillance cameras by analyzing the video. Camera tampering can occur due to natural events or it can be caused intentionally to disrupt surveillance. We cast tampering detection as a change detection problem, and perform a review of the existing literature with emphasis on feature types. We formulate tampering detection as a time series analysis problem, and design experiments to study the robustness and capability of various feature types. We compute ten features on real-world surveillance video and apply time series analysis to ascertain their predictability, and their capability to detect tampering. Finally, we quantify the performance of various time series models using each feature type to detect tampering.
Bifurcations and loss jumps in RNN training
Oct 26, 2023Recurrent neural networks (RNNs) are popular machine learning tools for modeling and forecasting sequential data and for inferring dynamical systems (DS) from observed time series. Concepts from DS theory (DST) have variously been used to further our understanding of both, how trained RNNs solve complex tasks, and the training process itself. Bifurcations are particularly important phenomena in DS, including RNNs, that refer to topological (qualitative) changes in a system's dynamical behavior as one or more of its parameters are varied. Knowing the bifurcation structure of an RNN will thus allow to deduce many of its computational and dynamical properties, like its sensitivity to parameter variations or its behavior during training. In particular, bifurcations may account for sudden loss jumps observed in RNN training that could severely impede the training process. Here we first mathematically prove for a particular class of ReLU-based RNNs that certain bifurcations are indeed associated with loss gradients tending toward infinity or zero. We then introduce a novel heuristic algorithm for detecting all fixed points and k-cycles in ReLU-based RNNs and their existence and stability regions, hence bifurcation manifolds in parameter space. In contrast to previous numerical algorithms for finding fixed points and common continuation methods, our algorithm provides exact results and returns fixed points and cycles up to high orders with surprisingly good scaling behavior. We exemplify the algorithm on the analysis of the training process of RNNs, and find that the recently introduced technique of generalized teacher forcing completely avoids certain types of bifurcations in training. Thus, besides facilitating the DST analysis of trained RNNs, our algorithm provides a powerful instrument for analyzing the training process itself.
A Mass-Conserving-Perceptron for Machine Learning-Based Modeling of Geoscientific Systems
Oct 24, 2023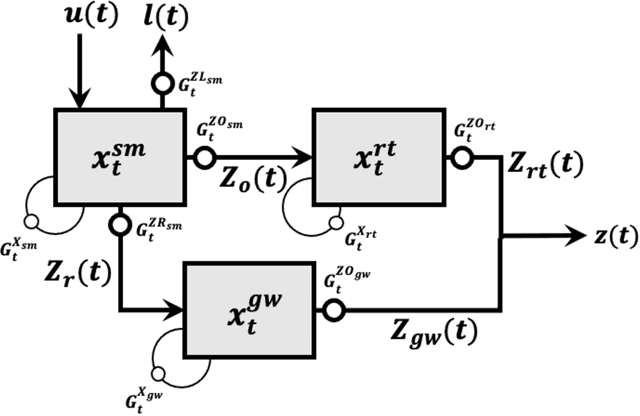
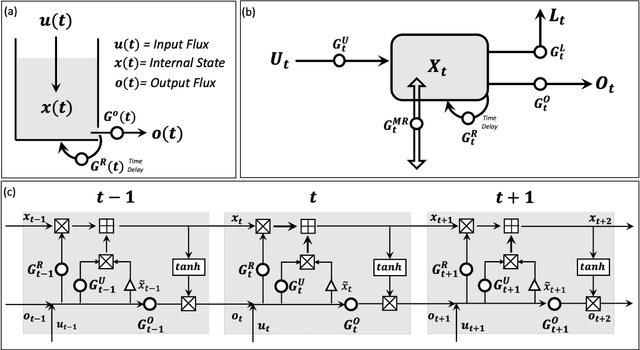
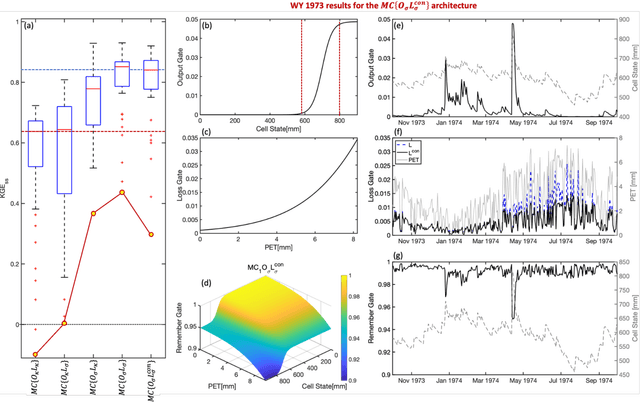
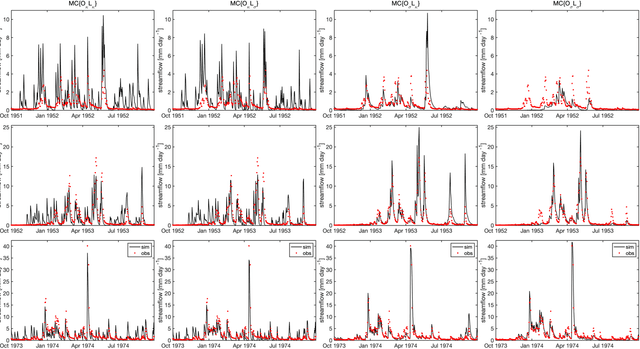
Although decades of effort have been devoted to building Physical-Conceptual (PC) models for predicting the time-series evolution of geoscientific systems, recent work shows that Machine Learning (ML) based Gated Recurrent Neural Network technology can be used to develop models that are much more accurate. However, the difficulty of extracting physical understanding from ML-based models complicates their utility for enhancing scientific knowledge regarding system structure and function. Here, we propose a physically-interpretable Mass Conserving Perceptron (MCP) as a way to bridge the gap between PC-based and ML-based modeling approaches. The MCP exploits the inherent isomorphism between the directed graph structures underlying both PC models and GRNNs to explicitly represent the mass-conserving nature of physical processes while enabling the functional nature of such processes to be directly learned (in an interpretable manner) from available data using off-the-shelf ML technology. As a proof of concept, we investigate the functional expressivity (capacity) of the MCP, explore its ability to parsimoniously represent the rainfall-runoff (RR) dynamics of the Leaf River Basin, and demonstrate its utility for scientific hypothesis testing. To conclude, we discuss extensions of the concept to enable ML-based physical-conceptual representation of the coupled nature of mass-energy-information flows through geoscientific systems.
Enhancing Traffic Prediction with Learnable Filter Module
Oct 24, 2023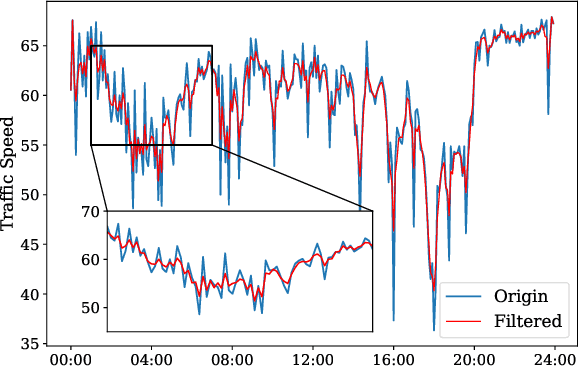

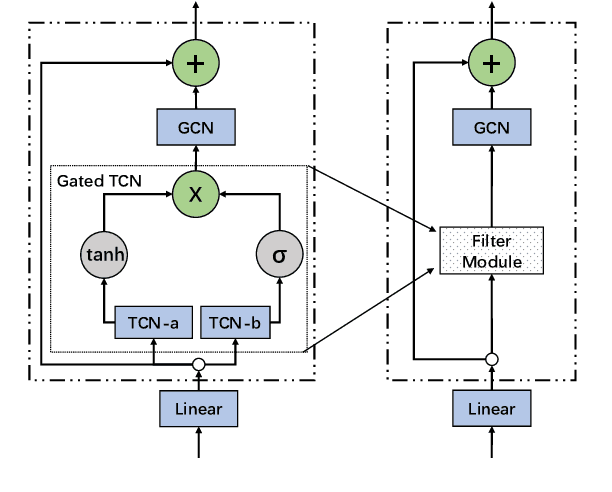
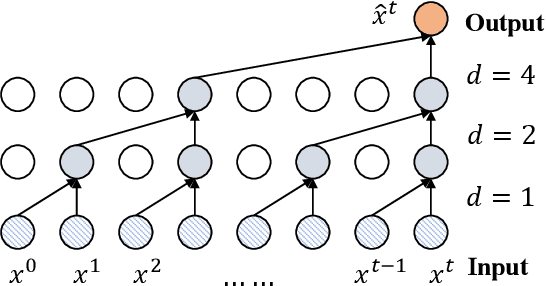
Modeling future traffic conditions often relies heavily on complex spatial-temporal neural networks to capture spatial and temporal correlations, which can overlook the inherent noise in the data. This noise, often manifesting as unexpected short-term peaks or drops in traffic observation, is typically caused by traffic accidents or inherent sensor vibration. In practice, such noise can be challenging to model due to its stochastic nature and can lead to overfitting risks if a neural network is designed to learn this behavior. To address this issue, we propose a learnable filter module to filter out noise in traffic data adaptively. This module leverages the Fourier transform to convert the data to the frequency domain, where noise is filtered based on its pattern. The denoised data is then recovered to the time domain using the inverse Fourier transform. Our approach focuses on enhancing the quality of the input data for traffic prediction models, which is a critical yet often overlooked aspect in the field. We demonstrate that the proposed module is lightweight, easy to integrate with existing models, and can significantly improve traffic prediction performance. Furthermore, we validate our approach with extensive experimental results on real-world datasets, showing that it effectively mitigates noise and enhances prediction accuracy.