 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Graph Neural Aggregation-diffusion with Metastability
Mar 29, 2024

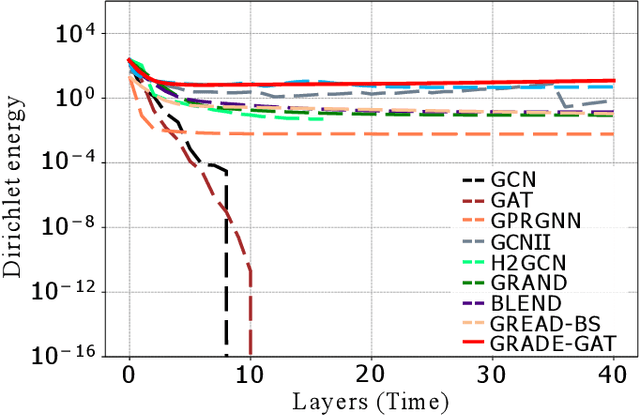
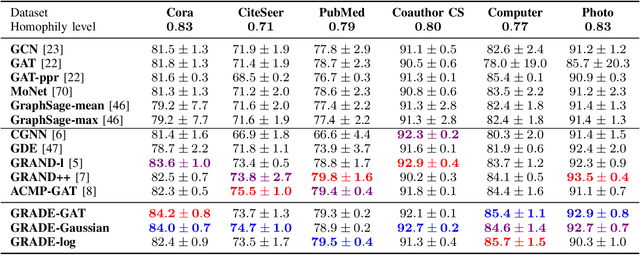
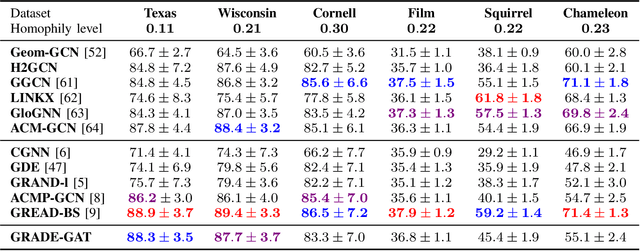
Continuous graph neural models based on differential equations have expanded the architecture of graph neural networks (GNNs). Due to the connection between graph diffusion and message passing, diffusion-based models have been widely studied. However, diffusion naturally drives the system towards an equilibrium state, leading to issues like over-smoothing. To this end, we propose GRADE inspired by graph aggregation-diffusion equations, which includes the delicate balance between nonlinear diffusion and aggregation induced by interaction potentials. The node representations obtained through aggregation-diffusion equations exhibit metastability, indicating that features can aggregate into multiple clusters. In addition, the dynamics within these clusters can persist for long time periods, offering the potential to alleviate over-smoothing effects. This nonlinear diffusion in our model generalizes existing diffusion-based models and establishes a connection with classical GNNs. We prove that GRADE achieves competitive performance across various benchmarks and alleviates the over-smoothing issue in GNNs evidenced by the enhanced Dirichlet energy.
From Chaos to Clarity: Time Series Anomaly Detection in Astronomical Observations
Mar 15, 2024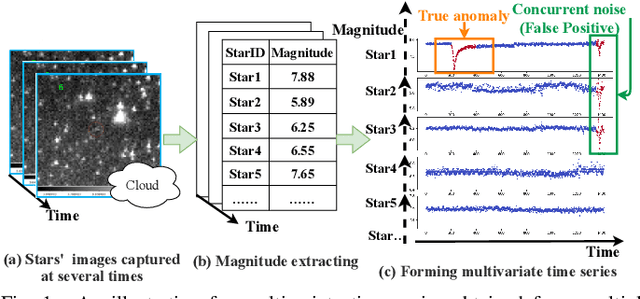
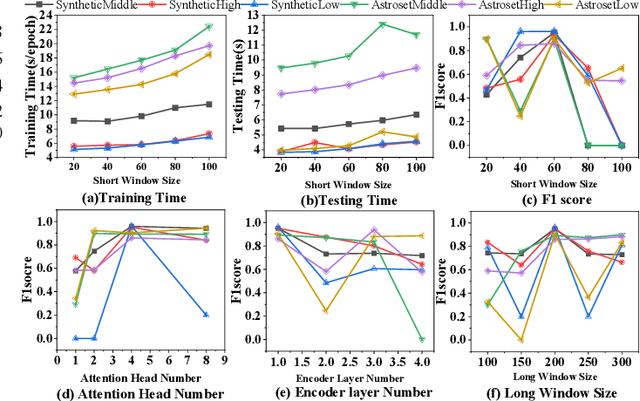
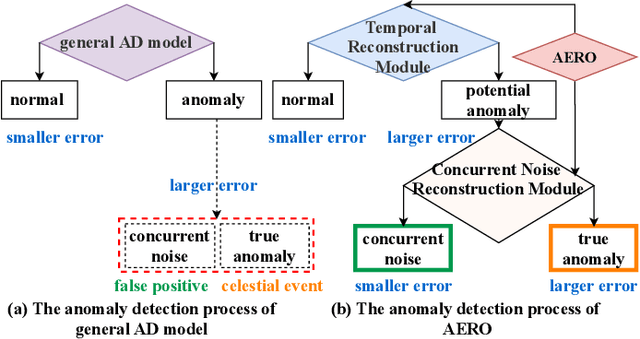
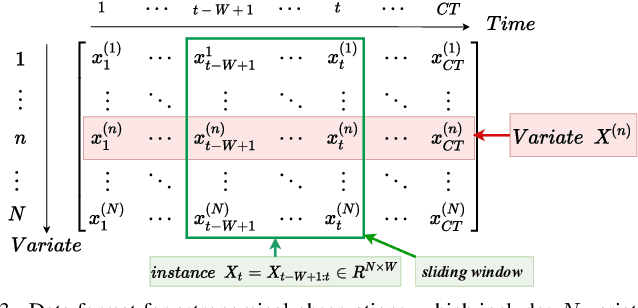
With the development of astronomical facilities, large-scale time series data observed by these facilities is being collected. Analyzing anomalies in these astronomical observations is crucial for uncovering potential celestial events and physical phenomena, thus advancing the scientific research process. However, existing time series anomaly detection methods fall short in tackling the unique characteristics of astronomical observations where each star is inherently independent but interfered by random concurrent noise, resulting in a high rate of false alarms. To overcome the challenges, we propose AERO, a novel two-stage framework tailored for unsupervised anomaly detection in astronomical observations. In the first stage, we employ a Transformer-based encoder-decoder architecture to learn the normal temporal patterns on each variate (i.e., star) in alignment with the characteristic of variate independence. In the second stage, we enhance the graph neural network with a window-wise graph structure learning to tackle the occurrence of concurrent noise characterized by spatial and temporal randomness. In this way, AERO is not only capable of distinguishing normal temporal patterns from potential anomalies but also effectively differentiating concurrent noise, thus decreasing the number of false alarms. We conducted extensive experiments on three synthetic datasets and three real-world datasets. The results demonstrate that AERO outperforms the compared baselines. Notably, compared to the state-of-the-art model, AERO improves the F1-score by up to 8.76% and 2.63% on synthetic and real-world datasets respectively.
Data-Efficient Sleep Staging with Synthetic Time Series Pretraining
Mar 13, 2024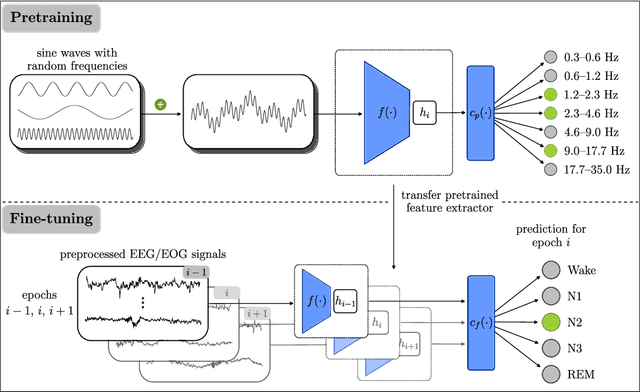
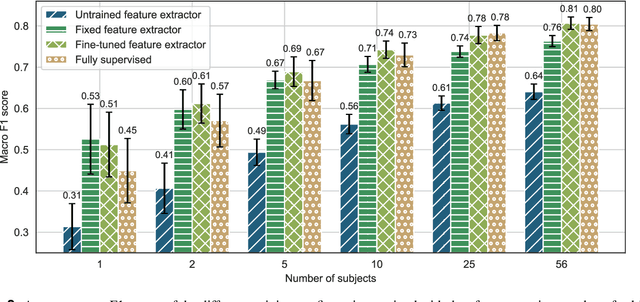
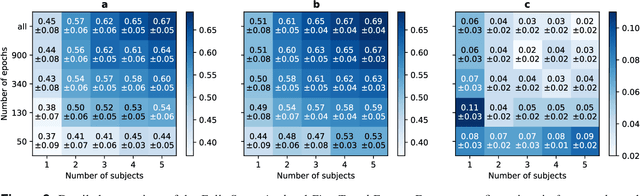
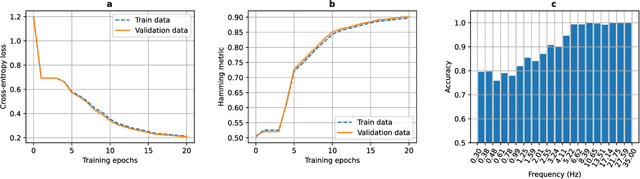
Analyzing electroencephalographic (EEG) time series can be challenging, especially with deep neural networks, due to the large variability among human subjects and often small datasets. To address these challenges, various strategies, such as self-supervised learning, have been suggested, but they typically rely on extensive empirical datasets. Inspired by recent advances in computer vision, we propose a pretraining task termed "frequency pretraining" to pretrain a neural network for sleep staging by predicting the frequency content of randomly generated synthetic time series. Our experiments demonstrate that our method surpasses fully supervised learning in scenarios with limited data and few subjects, and matches its performance in regimes with many subjects. Furthermore, our results underline the relevance of frequency information for sleep stage scoring, while also demonstrating that deep neural networks utilize information beyond frequencies to enhance sleep staging performance, which is consistent with previous research. We anticipate that our approach will be advantageous across a broad spectrum of applications where EEG data is limited or derived from a small number of subjects, including the domain of brain-computer interfaces.
Long-form factuality in large language models
Mar 27, 2024Large language models (LLMs) often generate content that contains factual errors when responding to fact-seeking prompts on open-ended topics. To benchmark a model's long-form factuality in open domains, we first use GPT-4 to generate LongFact, a prompt set comprising thousands of questions spanning 38 topics. We then propose that LLM agents can be used as automated evaluators for long-form factuality through a method which we call Search-Augmented Factuality Evaluator (SAFE). SAFE utilizes an LLM to break down a long-form response into a set of individual facts and to evaluate the accuracy of each fact using a multi-step reasoning process comprising sending search queries to Google Search and determining whether a fact is supported by the search results. Furthermore, we propose extending F1 score as an aggregated metric for long-form factuality. To do so, we balance the percentage of supported facts in a response (precision) with the percentage of provided facts relative to a hyperparameter representing a user's preferred response length (recall). Empirically, we demonstrate that LLM agents can achieve superhuman rating performance - on a set of ~16k individual facts, SAFE agrees with crowdsourced human annotators 72% of the time, and on a random subset of 100 disagreement cases, SAFE wins 76% of the time. At the same time, SAFE is more than 20 times cheaper than human annotators. We also benchmark thirteen language models on LongFact across four model families (Gemini, GPT, Claude, and PaLM-2), finding that larger language models generally achieve better long-form factuality. LongFact, SAFE, and all experimental code are available at https://github.com/google-deepmind/long-form-factuality.
SA-GS: Scale-Adaptive Gaussian Splatting for Training-Free Anti-Aliasing
Mar 28, 2024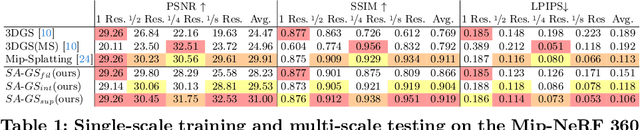
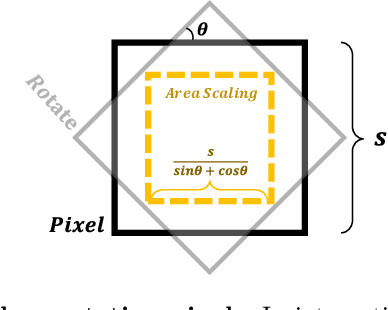

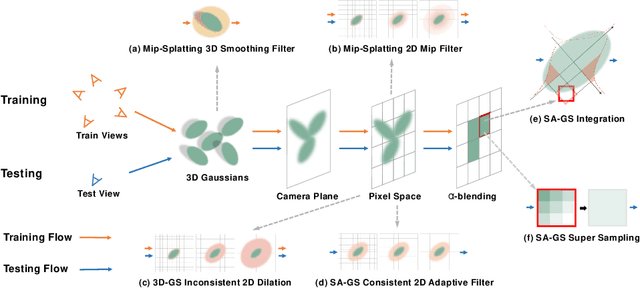
In this paper, we present a Scale-adaptive method for Anti-aliasing Gaussian Splatting (SA-GS). While the state-of-the-art method Mip-Splatting needs modifying the training procedure of Gaussian splatting, our method functions at test-time and is training-free. Specifically, SA-GS can be applied to any pretrained Gaussian splatting field as a plugin to significantly improve the field's anti-alising performance. The core technique is to apply 2D scale-adaptive filters to each Gaussian during test time. As pointed out by Mip-Splatting, observing Gaussians at different frequencies leads to mismatches between the Gaussian scales during training and testing. Mip-Splatting resolves this issue using 3D smoothing and 2D Mip filters, which are unfortunately not aware of testing frequency. In this work, we show that a 2D scale-adaptive filter that is informed of testing frequency can effectively match the Gaussian scale, thus making the Gaussian primitive distribution remain consistent across different testing frequencies. When scale inconsistency is eliminated, sampling rates smaller than the scene frequency result in conventional jaggedness, and we propose to integrate the projected 2D Gaussian within each pixel during testing. This integration is actually a limiting case of super-sampling, which significantly improves anti-aliasing performance over vanilla Gaussian Splatting. Through extensive experiments using various settings and both bounded and unbounded scenes, we show SA-GS performs comparably with or better than Mip-Splatting. Note that super-sampling and integration are only effective when our scale-adaptive filtering is activated. Our codes, data and models are available at https://github.com/zsy1987/SA-GS.
Interactive Multi-Robot Flocking with Gesture Responsiveness and Musical Accompaniment
Mar 30, 2024For decades, robotics researchers have pursued various tasks for multi-robot systems, from cooperative manipulation to search and rescue. These tasks are multi-robot extensions of classical robotic tasks and often optimized on dimensions such as speed or efficiency. As robots transition from commercial and research settings into everyday environments, social task aims such as engagement or entertainment become increasingly relevant. This work presents a compelling multi-robot task, in which the main aim is to enthrall and interest. In this task, the goal is for a human to be drawn to move alongside and participate in a dynamic, expressive robot flock. Towards this aim, the research team created algorithms for robot movements and engaging interaction modes such as gestures and sound. The contributions are as follows: (1) a novel group navigation algorithm involving human and robot agents, (2) a gesture responsive algorithm for real-time, human-robot flocking interaction, (3) a weight mode characterization system for modifying flocking behavior, and (4) a method of encoding a choreographer's preferences inside a dynamic, adaptive, learned system. An experiment was performed to understand individual human behavior while interacting with the flock under three conditions: weight modes selected by a human choreographer, a learned model, or subset list. Results from the experiment showed that the perception of the experience was not influenced by the weight mode selection. This work elucidates how differing task aims such as engagement manifest in multi-robot system design and execution, and broadens the domain of multi-robot tasks.
CoReEcho: Continuous Representation Learning for 2D+time Echocardiography Analysis
Mar 15, 2024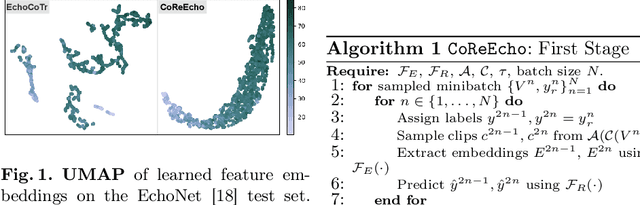
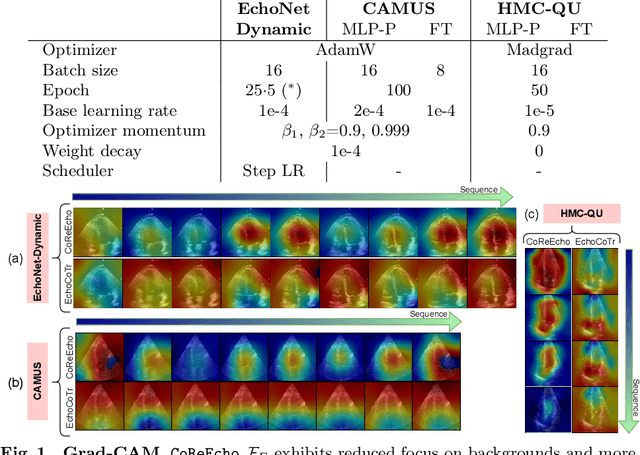
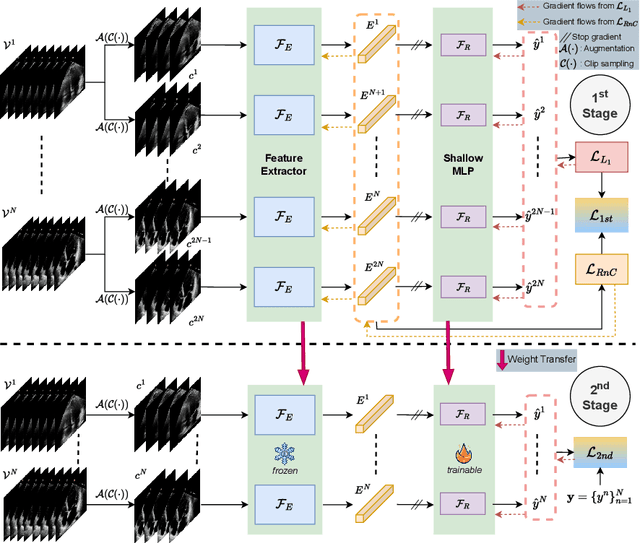

Deep learning (DL) models have been advancing automatic medical image analysis on various modalities, including echocardiography, by offering a comprehensive end-to-end training pipeline. This approach enables DL models to regress ejection fraction (EF) directly from 2D+time echocardiograms, resulting in superior performance. However, the end-to-end training pipeline makes the learned representations less explainable. The representations may also fail to capture the continuous relation among echocardiogram clips, indicating the existence of spurious correlations, which can negatively affect the generalization. To mitigate this issue, we propose CoReEcho, a novel training framework emphasizing continuous representations tailored for direct EF regression. Our extensive experiments demonstrate that CoReEcho: 1) outperforms the current state-of-the-art (SOTA) on the largest echocardiography dataset (EchoNet-Dynamic) with MAE of 3.90 & R2 of 82.44, and 2) provides robust and generalizable features that transfer more effectively in related downstream tasks. The code is publicly available at https://github.com/fadamsyah/CoReEcho.
Guessing human intentions to avoid dangerous situations in caregiving robots
Mar 26, 2024For robots to interact socially, they must interpret human intentions and anticipate their potential outcomes accurately. This is particularly important for social robots designed for human care, which may face potentially dangerous situations for people, such as unseen obstacles in their way, that should be avoided. This paper explores the Artificial Theory of Mind (ATM) approach to inferring and interpreting human intentions. We propose an algorithm that detects risky situations for humans, selecting a robot action that removes the danger in real time. We use the simulation-based approach to ATM and adopt the 'like-me' policy to assign intentions and actions to people. Using this strategy, the robot can detect and act with a high rate of success under time-constrained situations. The algorithm has been implemented as part of an existing robotics cognitive architecture and tested in simulation scenarios. Three experiments have been conducted to test the implementation's robustness, precision and real-time response, including a simulated scenario, a human-in-the-loop hybrid configuration and a real-world scenario.
Track Everything Everywhere Fast and Robustly
Mar 26, 2024We propose a novel test-time optimization approach for efficiently and robustly tracking any pixel at any time in a video. The latest state-of-the-art optimization-based tracking technique, OmniMotion, requires a prohibitively long optimization time, rendering it impractical for downstream applications. OmniMotion is sensitive to the choice of random seeds, leading to unstable convergence. To improve efficiency and robustness, we introduce a novel invertible deformation network, CaDeX++, which factorizes the function representation into a local spatial-temporal feature grid and enhances the expressivity of the coupling blocks with non-linear functions. While CaDeX++ incorporates a stronger geometric bias within its architectural design, it also takes advantage of the inductive bias provided by the vision foundation models. Our system utilizes monocular depth estimation to represent scene geometry and enhances the objective by incorporating DINOv2 long-term semantics to regulate the optimization process. Our experiments demonstrate a substantial improvement in training speed (more than \textbf{10 times} faster), robustness, and accuracy in tracking over the SoTA optimization-based method OmniMotion.
A Physics-embedded Deep Learning Framework for Cloth Simulation
Mar 27, 2024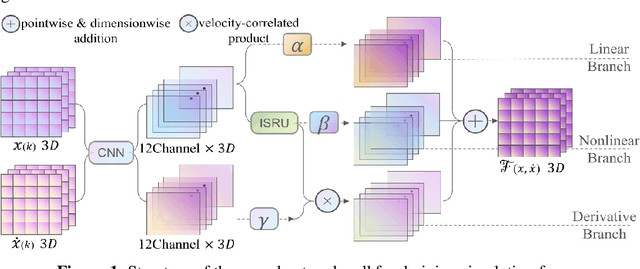

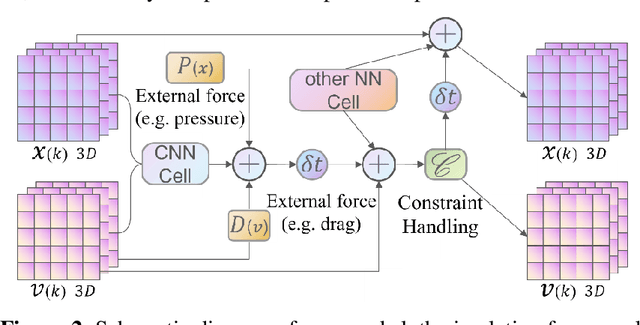

Delicate cloth simulations have long been desired in computer graphics. Various methods were proposed to improve engaged force interactions, collision handling, and numerical integrations. Deep learning has the potential to achieve fast and real-time simulation, but common neural network structures often demand many parameters to capture cloth dynamics. This paper proposes a physics-embedded learning framework that directly encodes physical features of cloth simulation. The convolutional neural network is used to represent spatial correlations of the mass-spring system, after which three branches are designed to learn linear, nonlinear, and time derivate features of cloth physics. The framework can also integrate with other external forces and collision handling through either traditional simulators or sub neural networks. The model is tested across different cloth animation cases, without training with new data. Agreement with baselines and predictive realism successfully validate its generalization ability. Inference efficiency of the proposed model also defeats traditional physics simulation. This framework is also designed to easily integrate with other visual refinement techniques like wrinkle carving, which leaves significant chances to incorporate prevailing macing learning techniques in 3D cloth amination.