 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Evaluating sleep-stage classification: how age and early-late sleep affects classification performance
Oct 20, 2023
Sleep stage classification is a common method used by experts to monitor the quantity and quality of sleep in humans, but it is a time-consuming and labour-intensive task with high inter- and intra-observer variability. Using Wavelets for feature extraction and Random Forest for classification, an automatic sleep-stage classification method was sought and assessed. The age of the subjects, as well as the moment of sleep (early-night and late-night), were confronted to the performance of the classifier. From this study, we observed that these variables do affect the automatic model performance, improving the classification of some sleep stages and worsening others.
Randomized Sparse Neural Galerkin Schemes for Solving Evolution Equations with Deep Networks
Oct 07, 2023Training neural networks sequentially in time to approximate solution fields of time-dependent partial differential equations can be beneficial for preserving causality and other physics properties; however, the sequential-in-time training is numerically challenging because training errors quickly accumulate and amplify over time. This work introduces Neural Galerkin schemes that update randomized sparse subsets of network parameters at each time step. The randomization avoids overfitting locally in time and so helps prevent the error from accumulating quickly over the sequential-in-time training, which is motivated by dropout that addresses a similar issue of overfitting due to neuron co-adaptation. The sparsity of the update reduces the computational costs of training without losing expressiveness because many of the network parameters are redundant locally at each time step. In numerical experiments with a wide range of evolution equations, the proposed scheme with randomized sparse updates is up to two orders of magnitude more accurate at a fixed computational budget and up to two orders of magnitude faster at a fixed accuracy than schemes with dense updates.
The Law and NLP: Bridging Disciplinary Disconnects
Oct 22, 2023Legal practice is intrinsically rooted in the fabric of language, yet legal practitioners and scholars have been slow to adopt tools from natural language processing (NLP). At the same time, the legal system is experiencing an access to justice crisis, which could be partially alleviated with NLP. In this position paper, we argue that the slow uptake of NLP in legal practice is exacerbated by a disconnect between the needs of the legal community and the focus of NLP researchers. In a review of recent trends in the legal NLP literature, we find limited overlap between the legal NLP community and legal academia. Our interpretation is that some of the most popular legal NLP tasks fail to address the needs of legal practitioners. We discuss examples of legal NLP tasks that promise to bridge disciplinary disconnects and highlight interesting areas for legal NLP research that remain underexplored.
Wonder3D: Single Image to 3D using Cross-Domain Diffusion
Oct 23, 2023In this work, we introduce Wonder3D, a novel method for efficiently generating high-fidelity textured meshes from single-view images.Recent methods based on Score Distillation Sampling (SDS) have shown the potential to recover 3D geometry from 2D diffusion priors, but they typically suffer from time-consuming per-shape optimization and inconsistent geometry. In contrast, certain works directly produce 3D information via fast network inferences, but their results are often of low quality and lack geometric details.To holistically improve the quality, consistency, and efficiency of image-to-3D tasks, we propose a cross-domain diffusion model that generates multi-view normal maps and the corresponding color images. To ensure consistency, we employ a multi-view cross-domain attention mechanism that facilitates information exchange across views and modalities. Lastly, we introduce a geometry-aware normal fusion algorithm that extracts high-quality surfaces from the multi-view 2D representations. Our extensive evaluations demonstrate that our method achieves high-quality reconstruction results, robust generalization, and reasonably good efficiency compared to prior works.
Fuel Consumption Prediction for a Passenger Ferry using Machine Learning and In-service Data: A Comparative Study
Oct 23, 2023

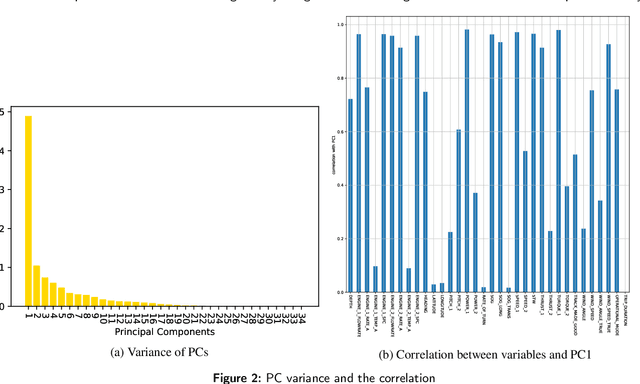
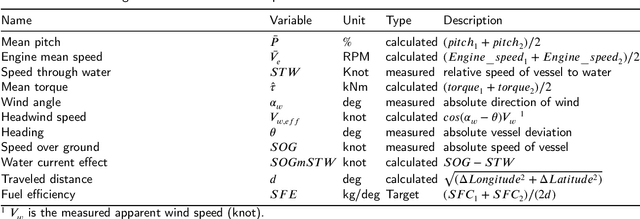
As the importance of eco-friendly transportation increases, providing an efficient approach for marine vessel operation is essential. Methods for status monitoring with consideration to the weather condition and forecasting with the use of in-service data from ships requires accurate and complete models for predicting the energy efficiency of a ship. The models need to effectively process all the operational data in real-time. This paper presents models that can predict fuel consumption using in-service data collected from a passenger ship. Statistical and domain-knowledge methods were used to select the proper input variables for the models. These methods prevent over-fitting, missing data, and multicollinearity while providing practical applicability. Prediction models that were investigated include multiple linear regression (MLR), decision tree approach (DT), an artificial neural network (ANN), and ensemble methods. The best predictive performance was from a model developed using the XGboost technique which is a boosting ensemble approach. \rvv{Our code is available on GitHub at \url{https://github.com/pagand/model_optimze_vessel/tree/OE} for future research.
* 20 pages, 11 figures, 7 tables
B^2SFL: A Bi-level Blockchained Architecture for Secure Federated Learning-based Traffic Prediction
Oct 23, 2023Federated Learning (FL) is a privacy-preserving machine learning (ML) technology that enables collaborative training and learning of a global ML model based on aggregating distributed local model updates. However, security and privacy guarantees could be compromised due to malicious participants and the centralized FL server. This article proposed a bi-level blockchained architecture for secure federated learning-based traffic prediction. The bottom and top layer blockchain store the local model and global aggregated parameters accordingly, and the distributed homomorphic-encrypted federated averaging (DHFA) scheme addresses the secure computation problems. We propose the partial private key distribution protocol and a partially homomorphic encryption/decryption scheme to achieve the distributed privacy-preserving federated averaging model. We conduct extensive experiments to measure the running time of DHFA operations, quantify the read and write performance of the blockchain network, and elucidate the impacts of varying regional group sizes and model complexities on the resulting prediction accuracy for the online traffic flow prediction task. The results indicate that the proposed system can facilitate secure and decentralized federated learning for real-world traffic prediction tasks.
Revisiting Implicit Differentiation for Learning Problems in Optimal Control
Oct 23, 2023This paper proposes a new method for differentiating through optimal trajectories arising from non-convex, constrained discrete-time optimal control (COC) problems using the implicit function theorem (IFT). Previous works solve a differential Karush-Kuhn-Tucker (KKT) system for the trajectory derivative, and achieve this efficiently by solving an auxiliary Linear Quadratic Regulator (LQR) problem. In contrast, we directly evaluate the matrix equations which arise from applying variable elimination on the Lagrange multiplier terms in the (differential) KKT system. By appropriately accounting for the structure of the terms within the resulting equations, we show that the trajectory derivatives scale linearly with the number of timesteps. Furthermore, our approach allows for easy parallelization, significantly improved scalability with model size, direct computation of vector-Jacobian products and improved numerical stability compared to prior works. As an additional contribution, we unify prior works, addressing claims that computing trajectory derivatives using IFT scales quadratically with the number of timesteps. We evaluate our method on a both synthetic benchmark and four challenging, learning from demonstration benchmarks including a 6-DoF maneuvering quadrotor and 6-DoF rocket powered landing.
DPP-TTS: Diversifying prosodic features of speech via determinantal point processes
Oct 23, 2023With the rapid advancement in deep generative models, recent neural Text-To-Speech(TTS) models have succeeded in synthesizing human-like speech. There have been some efforts to generate speech with various prosody beyond monotonous prosody patterns. However, previous works have several limitations. First, typical TTS models depend on the scaled sampling temperature for boosting the diversity of prosody. Speech samples generated at high sampling temperatures often lack perceptual prosodic diversity, which can adversely affect the naturalness of the speech. Second, the diversity among samples is neglected since the sampling procedure often focuses on a single speech sample rather than multiple ones. In this paper, we propose DPP-TTS: a text-to-speech model based on Determinantal Point Processes (DPPs) with a prosody diversifying module. Our TTS model is capable of generating speech samples that simultaneously consider perceptual diversity in each sample and among multiple samples. We demonstrate that DPP-TTS generates speech samples with more diversified prosody than baselines in the side-by-side comparison test considering the naturalness of speech at the same time.
Towards Conceptualization of "Fair Explanation": Disparate Impacts of anti-Asian Hate Speech Explanations on Content Moderators
Oct 23, 2023Recent research at the intersection of AI explainability and fairness has focused on how explanations can improve human-plus-AI task performance as assessed by fairness measures. We propose to characterize what constitutes an explanation that is itself "fair" -- an explanation that does not adversely impact specific populations. We formulate a novel evaluation method of "fair explanations" using not just accuracy and label time, but also psychological impact of explanations on different user groups across many metrics (mental discomfort, stereotype activation, and perceived workload). We apply this method in the context of content moderation of potential hate speech, and its differential impact on Asian vs. non-Asian proxy moderators, across explanation approaches (saliency map and counterfactual explanation). We find that saliency maps generally perform better and show less evidence of disparate impact (group) and individual unfairness than counterfactual explanations. Content warning: This paper contains examples of hate speech and racially discriminatory language. The authors do not support such content. Please consider your risk of discomfort carefully before continuing reading!
LC-TTFS: Towards Lossless Network Conversion for Spiking Neural Networks with TTFS Coding
Oct 23, 2023The biological neurons use precise spike times, in addition to the spike firing rate, to communicate with each other. The time-to-first-spike (TTFS) coding is inspired by such biological observation. However, there is a lack of effective solutions for training TTFS-based spiking neural network (SNN). In this paper, we put forward a simple yet effective network conversion algorithm, which is referred to as LC-TTFS, by addressing two main problems that hinder an effective conversion from a high-performance artificial neural network (ANN) to a TTFS-based SNN. We show that our algorithm can achieve a near-perfect mapping between the activation values of an ANN and the spike times of an SNN on a number of challenging AI tasks, including image classification, image reconstruction, and speech enhancement. With TTFS coding, we can achieve up to orders of magnitude saving in computation over ANN and other rate-based SNNs. The study, therefore, paves the way for deploying ultra-low-power TTFS-based SNNs on power-constrained edge computing platforms.