 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
pSTarC: Pseudo Source Guided Target Clustering for Fully Test-Time Adaptation
Sep 02, 2023
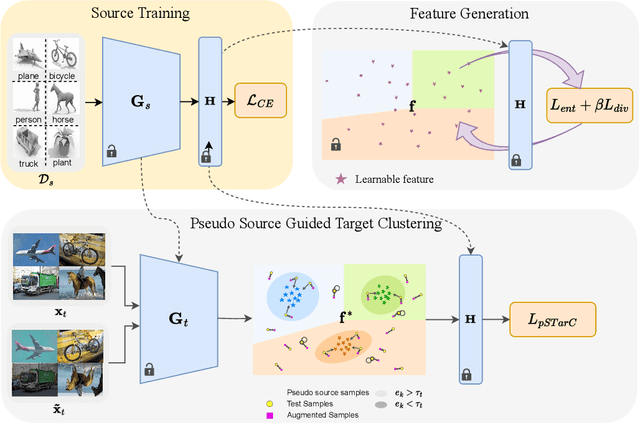
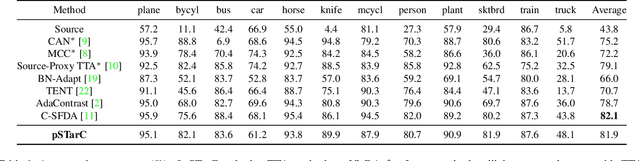

Test Time Adaptation (TTA) is a pivotal concept in machine learning, enabling models to perform well in real-world scenarios, where test data distribution differs from training. In this work, we propose a novel approach called pseudo Source guided Target Clustering (pSTarC) addressing the relatively unexplored area of TTA under real-world domain shifts. This method draws inspiration from target clustering techniques and exploits the source classifier for generating pseudo-source samples. The test samples are strategically aligned with these pseudo-source samples, facilitating their clustering and thereby enhancing TTA performance. pSTarC operates solely within the fully test-time adaptation protocol, removing the need for actual source data. Experimental validation on a variety of domain shift datasets, namely VisDA, Office-Home, DomainNet-126, CIFAR-100C verifies pSTarC's effectiveness. This method exhibits significant improvements in prediction accuracy along with efficient computational requirements. Furthermore, we also demonstrate the universality of the pSTarC framework by showing its effectiveness for the continuous TTA framework.
Analysing State-Backed Propaganda Websites: a New Dataset and Linguistic Study
Oct 21, 2023This paper analyses two hitherto unstudied sites sharing state-backed disinformation, Reliable Recent News (rrn.world) and WarOnFakes (waronfakes.com), which publish content in Arabic, Chinese, English, French, German, and Spanish. We describe our content acquisition methodology and perform cross-site unsupervised topic clustering on the resulting multilingual dataset. We also perform linguistic and temporal analysis of the web page translations and topics over time, and investigate articles with false publication dates. We make publicly available this new dataset of 14,053 articles, annotated with each language version, and additional metadata such as links and images. The main contribution of this paper for the NLP community is in the novel dataset which enables studies of disinformation networks, and the training of NLP tools for disinformation detection.
Fast Approximation of Similarity Graphs with Kernel Density Estimation
Oct 21, 2023Constructing a similarity graph from a set $X$ of data points in $\mathbb{R}^d$ is the first step of many modern clustering algorithms. However, typical constructions of a similarity graph have high time complexity, and a quadratic space dependency with respect to $|X|$. We address this limitation and present a new algorithmic framework that constructs a sparse approximation of the fully connected similarity graph while preserving its cluster structure. Our presented algorithm is based on the kernel density estimation problem, and is applicable for arbitrary kernel functions. We compare our designed algorithm with the well-known implementations from the scikit-learn library and the FAISS library, and find that our method significantly outperforms the implementation from both libraries on a variety of datasets.
Using State-of-the-Art Speech Models to Evaluate Oral Reading Fluency in Ghana
Oct 26, 2023This paper reports on a set of three recent experiments utilizing large-scale speech models to evaluate the oral reading fluency (ORF) of students in Ghana. While ORF is a well-established measure of foundational literacy, assessing it typically requires one-on-one sessions between a student and a trained evaluator, a process that is time-consuming and costly. Automating the evaluation of ORF could support better literacy instruction, particularly in education contexts where formative assessment is uncommon due to large class sizes and limited resources. To our knowledge, this research is among the first to examine the use of the most recent versions of large-scale speech models (Whisper V2 wav2vec2.0) for ORF assessment in the Global South. We find that Whisper V2 produces transcriptions of Ghanaian students reading aloud with a Word Error Rate of 13.5. This is close to the model's average WER on adult speech (12.8) and would have been considered state-of-the-art for children's speech transcription only a few years ago. We also find that when these transcriptions are used to produce fully automated ORF scores, they closely align with scores generated by expert human graders, with a correlation coefficient of 0.96. Importantly, these results were achieved on a representative dataset (i.e., students with regional accents, recordings taken in actual classrooms), using a free and publicly available speech model out of the box (i.e., no fine-tuning). This suggests that using large-scale speech models to assess ORF may be feasible to implement and scale in lower-resource, linguistically diverse educational contexts.
QMoE: Practical Sub-1-Bit Compression of Trillion-Parameter Models
Oct 25, 2023Mixture-of-Experts (MoE) architectures offer a general solution to the high inference costs of large language models (LLMs) via sparse routing, bringing faster and more accurate models, at the cost of massive parameter counts. For example, the SwitchTransformer-c2048 model has 1.6 trillion parameters, requiring 3.2TB of accelerator memory to run efficiently, which makes practical deployment challenging and expensive. In this paper, we present a solution to this memory problem, in form of a new compression and execution framework called QMoE. Specifically, QMoE consists of a scalable algorithm which accurately compresses trillion-parameter MoEs to less than 1 bit per parameter, in a custom format co-designed with bespoke GPU decoding kernels to facilitate efficient end-to-end compressed inference, with minor runtime overheads relative to uncompressed execution. Concretely, QMoE can compress the 1.6 trillion parameter SwitchTransformer-c2048 model to less than 160GB (20x compression, 0.8 bits per parameter) at only minor accuracy loss, in less than a day on a single GPU. This enables, for the first time, the execution of a trillion-parameter model on affordable commodity hardware, like a single server with 4x NVIDIA A6000 or 8x NVIDIA 3090 GPUs, at less than 5% runtime overhead relative to ideal uncompressed inference. The source code and compressed models are available at github.com/IST-DASLab/qmoe.
Tailoring Personality Traits in Large Language Models via Unsupervisedly-Built Personalized Lexicons
Oct 25, 2023Personality plays a pivotal role in shaping human expression patterns, and empowering and manipulating large language models (LLMs) with personality traits holds significant promise in enhancing the user experience of LLMs. However, prior approaches either rely on fine-tuning LLMs on a corpus enriched with personalized expressions or necessitate the manual crafting of prompts to induce LLMs to produce personalized responses. The former approaches demand substantial time and resources for collecting sufficient training examples while the latter might fail in enabling the precise manipulation of the personality traits at a fine-grained level (e.g., achieving high agreeableness while reducing openness). In this study, we introduce a novel approach for tailoring personality traits within LLMs, allowing for the incorporation of any combination of the Big Five factors (i.e., openness, conscientiousness, extraversion, agreeableness, and neuroticism) in a pluggable manner. This is achieved by employing a set of Unsupervisedly-Built Personalized Lexicons (UBPL) that are utilized to adjust the probability of the next token predicted by the original LLMs during the decoding phase. This adjustment encourages the models to generate words present in the personalized lexicons while preserving the naturalness of the generated texts. Extensive experimentation demonstrates the effectiveness of our approach in finely manipulating LLMs' personality traits. Furthermore, our method can be seamlessly integrated into other LLMs without necessitating updates to their parameters.
Improving Robustness and Reliability in Medical Image Classification with Latent-Guided Diffusion and Nested-Ensembles
Oct 25, 2023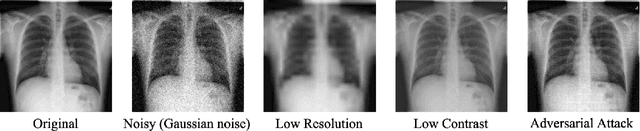
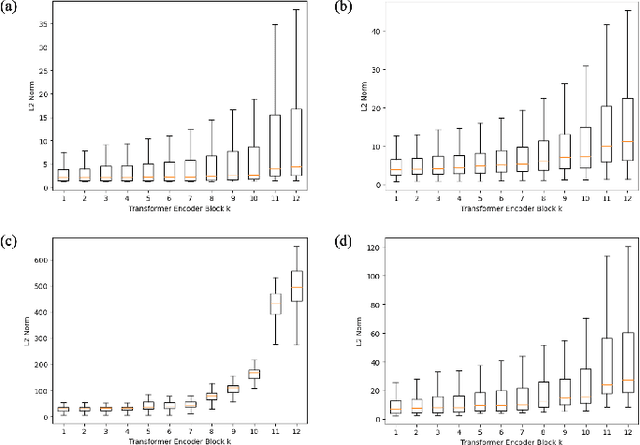
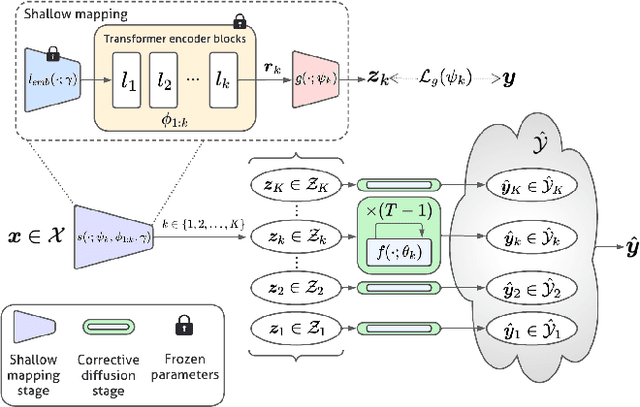
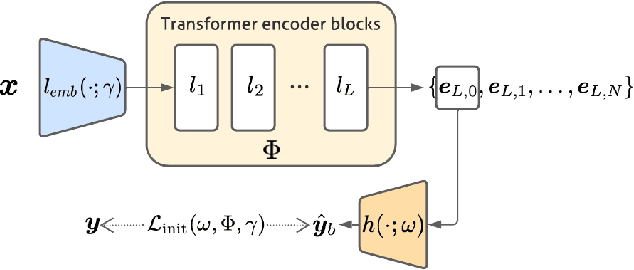
While deep learning models have achieved remarkable success across a range of medical image analysis tasks, deployment of these models in real clinical contexts requires that they be robust to variability in the acquired images. While many methods apply predefined transformations to augment the training data to enhance test-time robustness, these transformations may not ensure the model's robustness to the diverse variability seen in patient images. In this paper, we introduce a novel three-stage approach based on transformers coupled with conditional diffusion models, with the goal of improving model robustness to the kinds of imaging variability commonly encountered in practice without the need for pre-determined data augmentation strategies. To this end, multiple image encoders first learn hierarchical feature representations to build discriminative latent spaces. Next, a reverse diffusion process, guided by the latent code, acts on an informative prior and proposes prediction candidates in a generative manner. Finally, several prediction candidates are aggregated in a bi-level aggregation protocol to produce the final output. Through extensive experiments on medical imaging benchmark datasets, we show that our method improves upon state-of-the-art methods in terms of robustness and confidence calibration. Additionally, we introduce a strategy to quantify the prediction uncertainty at the instance level, increasing their trustworthiness to clinicians using them in clinical practice.
Active Sensing for Localization with Reconfigurable Intelligent Surface
Oct 19, 2023This paper addresses an uplink localization problem in which the base station (BS) aims to locate a remote user with the aid of reconfigurable intelligent surface (RIS). This paper proposes a strategy in which the user transmits pilots over multiple time frames, and the BS adaptively adjusts the RIS reflection coefficients based on the observations already received so far in order to produce an accurate estimate of the user location at the end. This is a challenging active sensing problem for which finding an optimal solution involves a search through a complicated functional space whose dimension increases with the number of measurements. In this paper, we show that the long short-term memory (LSTM) network can be used to exploit the latent temporal correlation between measurements to automatically construct scalable information vectors (called hidden state) based on the measurements. Subsequently, the state vector can be mapped to the RIS configuration for the next time frame in a codebook-free fashion via a deep neural network (DNN). After all the measurements have been received, a final DNN can be used to map the LSTM cell state to the estimated user equipment (UE) position. Numerical result shows that the proposed active RIS design results in lower localization error as compared to existing active and nonactive methods. The proposed solution produces interpretable results and is generalizable to early stopping in the sequence of sensing stages.
TransRadar: Adaptive-Directional Transformer for Real-Time Multi-View Radar Semantic Segmentation
Oct 03, 2023Scene understanding plays an essential role in enabling autonomous driving and maintaining high standards of performance and safety. To address this task, cameras and laser scanners (LiDARs) have been the most commonly used sensors, with radars being less popular. Despite that, radars remain low-cost, information-dense, and fast-sensing techniques that are resistant to adverse weather conditions. While multiple works have been previously presented for radar-based scene semantic segmentation, the nature of the radar data still poses a challenge due to the inherent noise and sparsity, as well as the disproportionate foreground and background. In this work, we propose a novel approach to the semantic segmentation of radar scenes using a multi-input fusion of radar data through a novel architecture and loss functions that are tailored to tackle the drawbacks of radar perception. Our novel architecture includes an efficient attention block that adaptively captures important feature information. Our method, TransRadar, outperforms state-of-the-art methods on the CARRADA and RADIal datasets while having smaller model sizes. https://github.com/YahiDar/TransRadar
An Anytime Algorithm for Good Arm Identification
Oct 16, 2023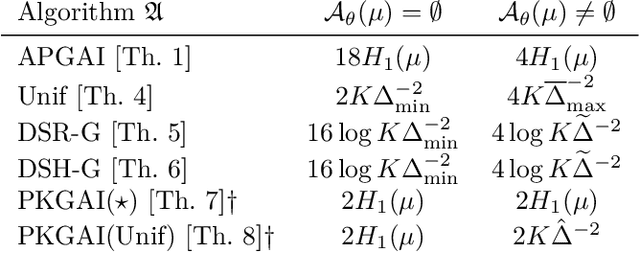
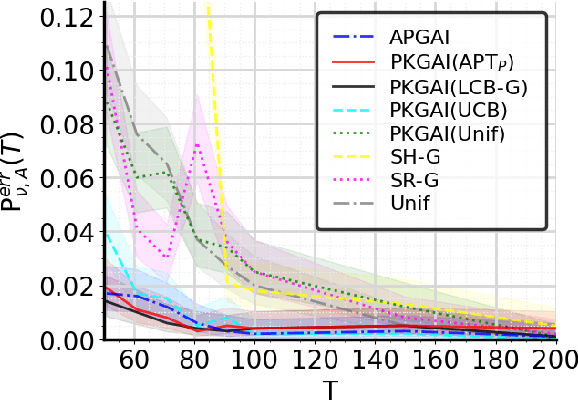

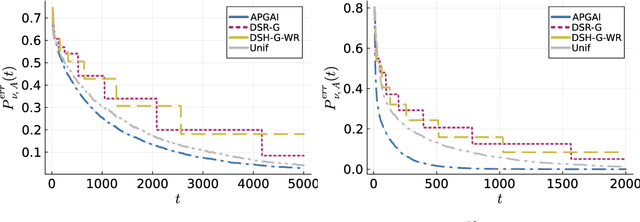
In good arm identification (GAI), the goal is to identify one arm whose average performance exceeds a given threshold, referred to as good arm, if it exists. Few works have studied GAI in the fixed-budget setting, when the sampling budget is fixed beforehand, or the anytime setting, when a recommendation can be asked at any time. We propose APGAI, an anytime and parameter-free sampling rule for GAI in stochastic bandits. APGAI can be straightforwardly used in fixed-confidence and fixed-budget settings. First, we derive upper bounds on its probability of error at any time. They show that adaptive strategies are more efficient in detecting the absence of good arms than uniform sampling. Second, when APGAI is combined with a stopping rule, we prove upper bounds on the expected sampling complexity, holding at any confidence level. Finally, we show good empirical performance of APGAI on synthetic and real-world data. Our work offers an extensive overview of the GAI problem in all settings.