 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CBD: A Certified Backdoor Detector Based on Local Dominant Probability
Oct 26, 2023
Backdoor attack is a common threat to deep neural networks. During testing, samples embedded with a backdoor trigger will be misclassified as an adversarial target by a backdoored model, while samples without the backdoor trigger will be correctly classified. In this paper, we present the first certified backdoor detector (CBD), which is based on a novel, adjustable conformal prediction scheme based on our proposed statistic local dominant probability. For any classifier under inspection, CBD provides 1) a detection inference, 2) the condition under which the attacks are guaranteed to be detectable for the same classification domain, and 3) a probabilistic upper bound for the false positive rate. Our theoretical results show that attacks with triggers that are more resilient to test-time noise and have smaller perturbation magnitudes are more likely to be detected with guarantees. Moreover, we conduct extensive experiments on four benchmark datasets considering various backdoor types, such as BadNet, CB, and Blend. CBD achieves comparable or even higher detection accuracy than state-of-the-art detectors, and it in addition provides detection certification. Notably, for backdoor attacks with random perturbation triggers bounded by $\ell_2\leq0.75$ which achieves more than 90\% attack success rate, CBD achieves 100\% (98\%), 100\% (84\%), 98\% (98\%), and 72\% (40\%) empirical (certified) detection true positive rates on the four benchmark datasets GTSRB, SVHN, CIFAR-10, and TinyImageNet, respectively, with low false positive rates.
Variance of ML-based software fault predictors: are we really improving fault prediction?
Oct 26, 2023Software quality assurance activities become increasingly difficult as software systems become more and more complex and continuously grow in size. Moreover, testing becomes even more expensive when dealing with large-scale systems. Thus, to effectively allocate quality assurance resources, researchers have proposed fault prediction (FP) which utilizes machine learning (ML) to predict fault-prone code areas. However, ML algorithms typically make use of stochastic elements to increase the prediction models' generalizability and efficiency of the training process. These stochastic elements, also known as nondeterminism-introducing (NI) factors, lead to variance in the training process and as a result, lead to variance in prediction accuracy and training time. This variance poses a challenge for reproducibility in research. More importantly, while fault prediction models may have shown good performance in the lab (e.g., often-times involving multiple runs and averaging outcomes), high variance of results can pose the risk that these models show low performance when applied in practice. In this work, we experimentally analyze the variance of a state-of-the-art fault prediction approach. Our experimental results indicate that NI factors can indeed cause considerable variance in the fault prediction models' accuracy. We observed a maximum variance of 10.10% in terms of the per-class accuracy metric. We thus, also discuss how to deal with such variance.
Learning an Inventory Control Policy with General Inventory Arrival Dynamics
Oct 26, 2023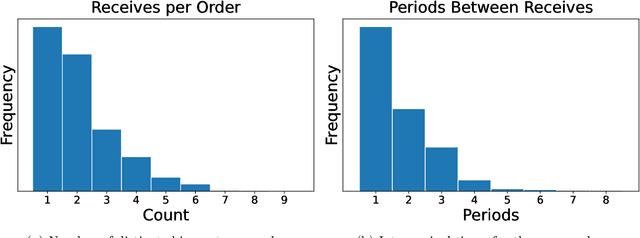
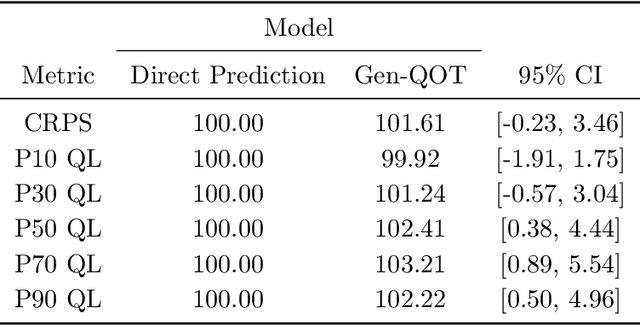
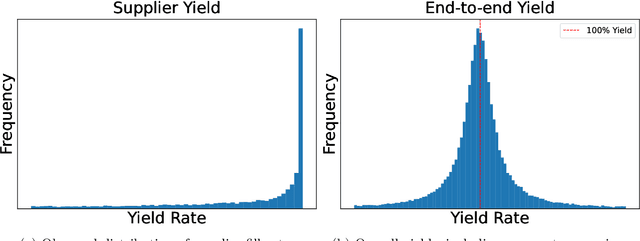
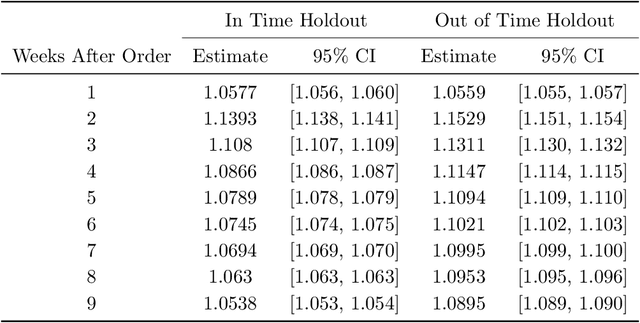
In this paper we address the problem of learning and backtesting inventory control policies in the presence of general arrival dynamics -- which we term as a quantity-over-time arrivals model (QOT). We also allow for order quantities to be modified as a post-processing step to meet vendor constraints such as order minimum and batch size constraints -- a common practice in real supply chains. To the best of our knowledge this is the first work to handle either arbitrary arrival dynamics or an arbitrary downstream post-processing of order quantities. Building upon recent work (Madeka et al., 2022) we similarly formulate the periodic review inventory control problem as an exogenous decision process, where most of the state is outside the control of the agent. Madeka et al. (2022) show how to construct a simulator that replays historic data to solve this class of problem. In our case, we incorporate a deep generative model for the arrivals process as part of the history replay. By formulating the problem as an exogenous decision process, we can apply results from Madeka et al. (2022) to obtain a reduction to supervised learning. Finally, we show via simulation studies that this approach yields statistically significant improvements in profitability over production baselines. Using data from an ongoing real-world A/B test, we show that Gen-QOT generalizes well to off-policy data.
InfoGCN++: Learning Representation by Predicting the Future for Online Human Skeleton-based Action Recognition
Oct 16, 2023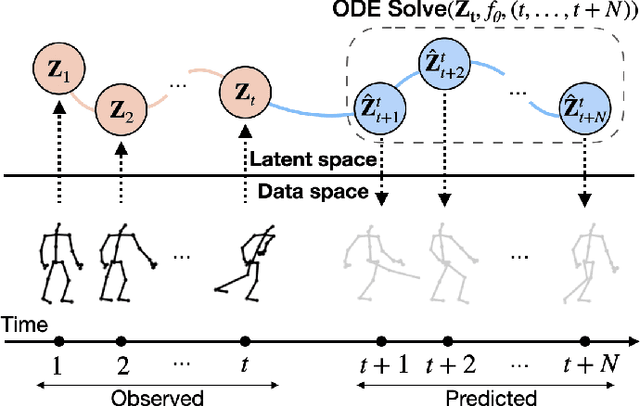
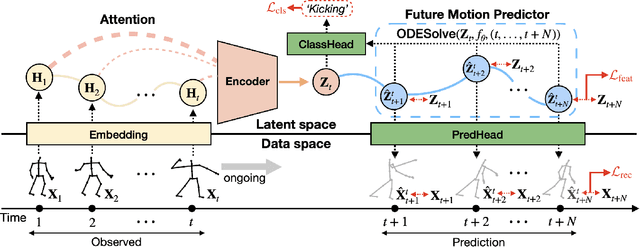
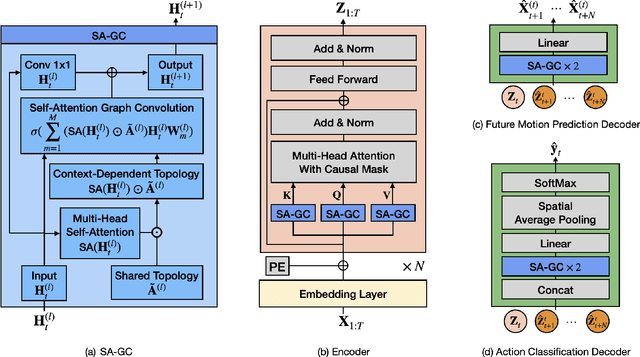
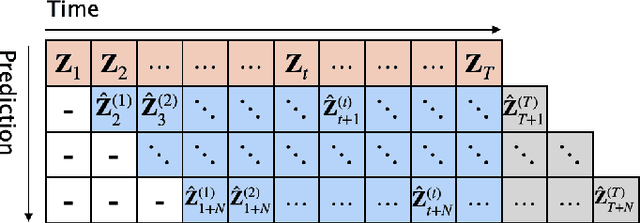
Skeleton-based action recognition has made significant advancements recently, with models like InfoGCN showcasing remarkable accuracy. However, these models exhibit a key limitation: they necessitate complete action observation prior to classification, which constrains their applicability in real-time situations such as surveillance and robotic systems. To overcome this barrier, we introduce InfoGCN++, an innovative extension of InfoGCN, explicitly developed for online skeleton-based action recognition. InfoGCN++ augments the abilities of the original InfoGCN model by allowing real-time categorization of action types, independent of the observation sequence's length. It transcends conventional approaches by learning from current and anticipated future movements, thereby creating a more thorough representation of the entire sequence. Our approach to prediction is managed as an extrapolation issue, grounded on observed actions. To enable this, InfoGCN++ incorporates Neural Ordinary Differential Equations, a concept that lets it effectively model the continuous evolution of hidden states. Following rigorous evaluations on three skeleton-based action recognition benchmarks, InfoGCN++ demonstrates exceptional performance in online action recognition. It consistently equals or exceeds existing techniques, highlighting its significant potential to reshape the landscape of real-time action recognition applications. Consequently, this work represents a major leap forward from InfoGCN, pushing the limits of what's possible in online, skeleton-based action recognition. The code for InfoGCN++ is publicly available at https://github.com/stnoah1/infogcn2 for further exploration and validation.
Hierarchical Forecasting at Scale
Oct 19, 2023Existing hierarchical forecasting techniques scale poorly when the number of time series increases. We propose to learn a coherent forecast for millions of time series with a single bottom-level forecast model by using a sparse loss function that directly optimizes the hierarchical product and/or temporal structure. The benefit of our sparse hierarchical loss function is that it provides practitioners a method of producing bottom-level forecasts that are coherent to any chosen cross-sectional or temporal hierarchy. In addition, removing the need for a post-processing step as required in traditional hierarchical forecasting techniques reduces the computational cost of the prediction phase in the forecasting pipeline. On the public M5 dataset, our sparse hierarchical loss function performs up to 10% (RMSE) better compared to the baseline loss function. We implement our sparse hierarchical loss function within an existing forecasting model at bol, a large European e-commerce platform, resulting in an improved forecasting performance of 2% at the product level. Finally, we found an increase in forecasting performance of about 5-10% when evaluating the forecasting performance across the cross-sectional hierarchies that we defined. These results demonstrate the usefulness of our sparse hierarchical loss applied to a production forecasting system at a major e-commerce platform.
Quasi Manhattan Wasserstein Distance
Oct 19, 2023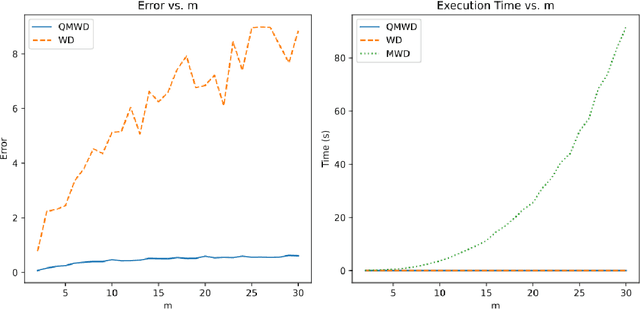
The Quasi Manhattan Wasserstein Distance (QMWD) is a metric designed to quantify the dissimilarity between two matrices by combining elements of the Wasserstein Distance with specific transformations. It offers improved time and space complexity compared to the Manhattan Wasserstein Distance (MWD) while maintaining accuracy. QMWD is particularly advantageous for large datasets or situations with limited computational resources. This article provides a detailed explanation of QMWD, its computation, complexity analysis, and comparisons with WD and MWD.
System Identification for Continuous-time Linear Dynamical Systems
Aug 23, 2023The problem of system identification for the Kalman filter, relying on the expectation-maximization (EM) procedure to learn the underlying parameters of a dynamical system, has largely been studied assuming that observations are sampled at equally-spaced time points. However, in many applications this is a restrictive and unrealistic assumption. This paper addresses system identification for the continuous-discrete filter, with the aim of generalizing learning for the Kalman filter by relying on a solution to a continuous-time It\^o stochastic differential equation (SDE) for the latent state and covariance dynamics. We introduce a novel two-filter, analytical form for the posterior with a Bayesian derivation, which yields analytical updates which do not require the forward-pass to be pre-computed. Using this analytical and efficient computation of the posterior, we provide an EM procedure which estimates the parameters of the SDE, naturally incorporating irregularly sampled measurements. Generalizing the learning of latent linear dynamical systems (LDS) to continuous-time may extend the use of the hybrid Kalman filter to data which is not regularly sampled or has intermittent missing values, and can extend the power of non-linear system identification methods such as switching LDS (SLDS), which rely on EM for the linear discrete-time Kalman filter as a sub-unit for learning locally linearized behavior of a non-linear system. We apply the method by learning the parameters of a latent, multivariate Fokker-Planck SDE representing a toggle-switch genetic circuit using biologically realistic parameters, and compare the efficacy of learning relative to the discrete-time Kalman filter as the step-size irregularity and spectral-radius of the dynamics-matrix increases.
Tree Prompting: Efficient Task Adaptation without Fine-Tuning
Oct 21, 2023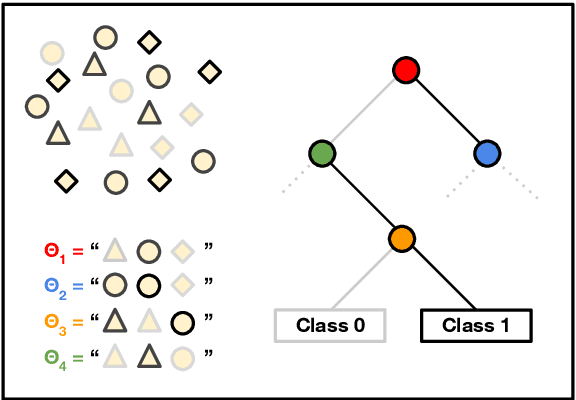
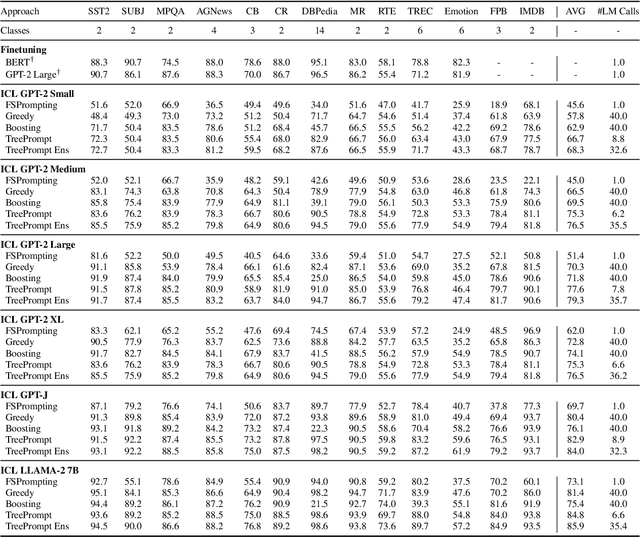
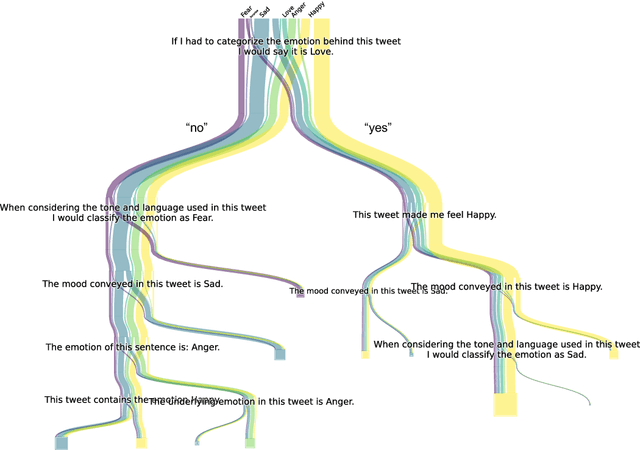

Prompting language models (LMs) is the main interface for applying them to new tasks. However, for smaller LMs, prompting provides low accuracy compared to gradient-based finetuning. Tree Prompting is an approach to prompting which builds a decision tree of prompts, linking multiple LM calls together to solve a task. At inference time, each call to the LM is determined by efficiently routing the outcome of the previous call using the tree. Experiments on classification datasets show that Tree Prompting improves accuracy over competing methods and is competitive with fine-tuning. We also show that variants of Tree Prompting allow inspection of a model's decision-making process.
Simultaneous Shape Tracking of Multiple Deformable Linear Objects with Global-Local Topology Preservation
Oct 20, 2023This work presents an algorithm for tracking the shape of multiple entangling Deformable Linear Objects (DLOs) from a sequence of RGB-D images. This algorithm runs in real-time and improves on previous single-DLO tracking approaches by enabling tracking of multiple objects. This is achieved using Global-Local Topology Preservation (GLTP). This work uses the geodesic distance in GLTP to define the distance between separate objects and the distance between different parts of the same object. Tracking multiple entangling DLOs is demonstrated experimentally. The source code is publicly released.
MorphFlow: Estimating Motion in In Situ Tests of Concrete
Oct 17, 2023

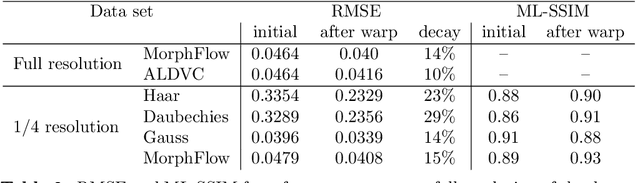
We present a novel algorithm explicitly tailored to estimate motion from time series of 3D images of concrete. Such volumetric images are usually acquired by Computed Tomography and can contain for example in situ tests, or more complex procedures like self-healing. Our algorithm is specifically designed to tackle the challenge of large scale in situ investigations of concrete. That means it cannot only cope with big images, but also with discontinuous displacement fields that often occur in in situ tests of concrete. We show the superior performance of our algorithm, especially regarding plausibility and time efficient processing. Core of the algorithm is a novel multiscale representation based on morphological wavelets. We use two examples for validation: A classical in situ test on refractory concrete and and a three point bending test on normal concrete. We show that for both applications structural changes like crack initiation can be already found at low scales -- a central achievement of our algorithm.